PPO强化学习的多智能体对话策略学习方法
2022-07-07魏鹏飞廖文雄
魏鹏飞,曾 碧,廖文雄
(广东工业大学 计算机学院,广州510006)
1 引 言
目前市场上有许多智能语音助理,比如:苹果的Siri、阿里的天猫精灵、小米的小爱同学和腾讯的小微[1].在这些精心设计的对话系统下,人们可以通过自然语言交互来完成任务.深度学习的发展也激发了许多神经任务对话系统的研究工作[2-4].
任务对话系统由4个部分组成:自然语言理解(NLU)、对话状态追踪(DST)、对话策略学习(DPL)、自然语言生成(NLG)[5].其中,对话策略是根据当前状态来选择下一步要执行的动作,在任务对话系统中扮演着重要的角色.它的好坏直接影响着整个系统的性能,由于其具备马尔科夫性,通常被描述为强化学习问题[6],将用户作为环境的一部分进行建模,并通过与用户的交互来学习策略.
由于强化学习在训练过程中需要大量的交互,与真实的用户交互时,需要耗费大量的时间和人工成本.一种可行的方法是利用人类的对话数据训练一个用户模拟器,这使得系统代理可以通过与用户模拟器交互来学习对话策略.该模拟器可以模拟脱机场景下的人类行为而无需额外的费用,经过训练的系统可以进行部署,然后通过与真实的用户交互进行微调.但是,设计一种可靠的用户模拟器并不是一件容易的事情,而且常常具有挑战性:1)它等同于构建了一个好的对话代理;2)真实用户和数据模拟用户之间始终存在一定的差异;3)不同的用户模拟器如何影响系统性能,以及如何为不同的任务构建适当的用户模拟器,这种相互关系使整个过程称为“鸡与蛋”问题;4)尚无较好的针对用户模拟器的自动评估标准.早期研究中,基于规则的用户模拟器是借助于拥有专业化领域知识的专家来构建获得的[7].然而,随着业务场景的多样化和任务功能需求的复杂性不断增长,建立一个完全基于规则的用户模拟器,需要大量多领域的专业知识,这将是一件艰巨的工作.随着机器学习的发展,在最近的研究工作中,一些研究人员提出了基于数据驱动的用户模拟器[8,9],但是,它需要很多的手工标注数据.具体例子如表1所示,用户在一次会话中完成了两个领域任务,首先请求系统预定一个2人的房间,从周二开始住4晚,然后请求系统推荐可参观的博物馆以及门票价格.其中,Dialogue acts是对应于话语的标注,包含领域、意图和槽值对信息.
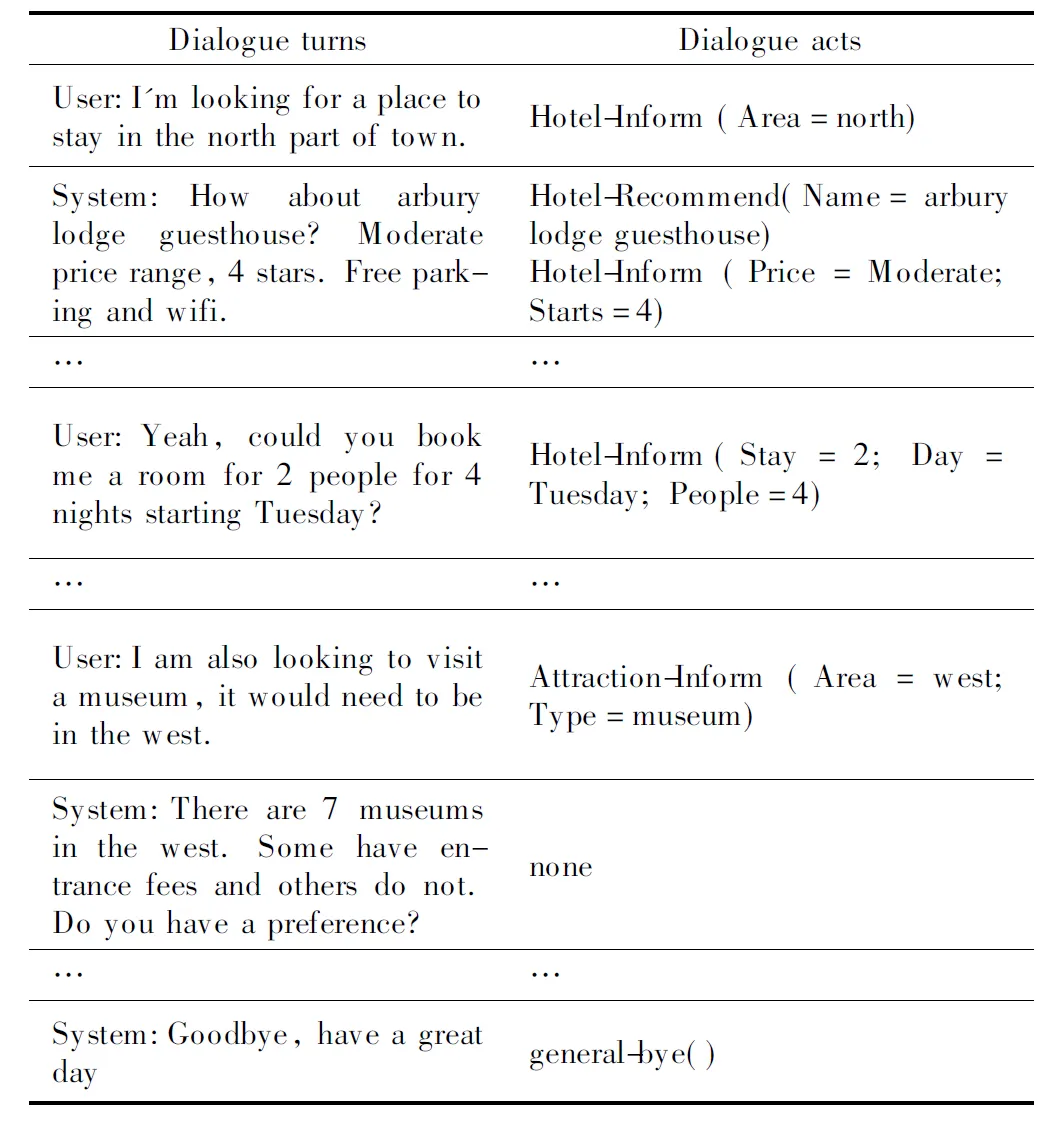
表1 MultiWOZ语料库中的一段对话及对话行为Table 1 A dialog session and dialog acts in MultiWOZ corpus
为了解决缺少可靠的用户模拟器来进行对话策略学习的挑战,本文提出了一种PPO强化学习的多智能体对话策略学习方法.其中用户也被视为智能体而不是用户模拟器.首先,在模仿学习的监督训练下直接从对话语料库中学习,从而引导基本的系统智能体和用户智能体的策略;然后,模拟两个智能体之间的面向任务的交互对话,并且通过PPO的强化学习算法优化其对话策略,来进一步提升系统性能;最后,在一个面向任务的多领域多意图的对话语料库MultiWOZ[10]上进行相关性能评估.本文的主要贡献归纳为5点:
1)提出了一种PPO强化学习的多智能体对话策略学习方法,该方法以端到端的方式同时优化用户智能体和系统智能体,避免显式地构建用户模拟器;
2)采用Actor-Critic(AC)架构的PPO算法加速学习过程;
3)设计了一种软注意力状态共享的用户-系统混合值评价网络;
4)通过实验比较了各基线模型,验证了本文方法的有效性和面对复杂任务中的可伸缩性;
5)将学到的对话策略集成到ConvLab-2平台上进行整体的效果评估,验证本文方法所学习策略的合理性.
2 相关工作
2.1 深度强化学习算法
强化学习强调智能体如何与环境进行互动,以获取最大的累计收益.强化学习算法可分成基于值函数的算法和基于策略梯度的算法.经典的值函数算法是Q-Learning算法[11].Mnih等人[12,13]首次把Q-Learning与深度神经网络(DNN)结合起来提出了深度Q网络(DQN),其中DNN用来表示动作值函数.Hasselt等人[14]使用Q网络选择行动,目标网络来估计值函数,消除DQN对值函数的过高估计问题.Wang等人[15]提出了竞争式的网络结构,分别学习状态值函数和动作优势值函数.经典的策略梯度法是REINFORCE算法[16],使用蒙特卡洛来估计累积期望回报.为了减少回报的方差,引入了Actor-Critic模式,使用Actor来选择动作,使用Critic对值函数进行估计.Schulman等人[17]进一步提出了PPO算法,简化了TRPO[18]的求解过程,并采用泛化优势函数估计来平衡优势函数计算的方差和偏差.
2.2 多智能体强化学习
在多智能体强化学习中,每个智能体都拥有自己的策略πi(ai|si),其中,si∈S,ai∈A.根据策略同环境进行互动,并执行相应的动作(a1,…,aN),最后获得状态转移s=(s1,…,sN)→s′=(s′1,…,s′N).与单智能体类似,每个智能体最大化自己的总折扣回报Ri=∑tγtri,t.Iqbal等人[19]采用了集中式的Critic对每个智能体进行价值估计,并引入了多头注意力(Multi-head attention)机制学习共享信息.另外,由于多个智能体在训练过程中策略不断变化,导致环境不再是稳定的,为了解决此问题,Lowe等人[20]引入了分散执行的集中训练(CTDE)架构,它允许策略使用额外的信息增强训练,但执行时仅使用本地观测到的信息.
2.3 面向任务对话的用户建模
面向任务对话的系统策略的学习是一个强化学习问题,通常需要大量的对话样本,而直接与真实的用户交互学习是不切实际的.如何针对用户进行建模也就成为了任务对话系统中急需解决的问题之一.根据以往的研究工作,用户建模大致可分为3种方法:1)基于规则的用户模拟器,其中Schatzmann等人[21]提出的基于议程的方式最受欢迎,手工制定规则并基于用户目标构建类似堆栈的议程;2)基于数据驱动的用户模拟器,Kreyssig等人[22]提出一种神经用户模拟器(NUS),从语料库中学习,并且会生成自然语言;3)基于世界模型的方法,微软在此方面做了较多研究[23,24],构建世界模型以模拟真实的用户响应,但是这种方法仍需要少量的真实用户的交互来促进世界模型的学习.
本文提出了一种PPO强化学习的多智能体对话策略学习算法.有关强化学习和任务对话策略学习更多的研究进展,可以阅读文献[25,26].
3 PPO强化学习的多智能体对话策略学习方法


图1 多智能体对话策略学习架构Fig.1 Architecture of multi-agent dialogue policy learning
3.1 用户智能体
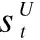
Action用户动作aU是用户智能体的策略μ根据当前状态sU所做出的决策,用于向系统智能体表达自己的约束和请求.

3.2 系统智能体

Action系统动作aS是系统智能体的策略π根据当前状态sS所做出的决策,用于向用户智能体提供合适的回复.
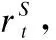
3.3 用户-系统混合值评价网络
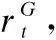
如图2所示,本文通过在编码向量上使用sigmoid函数进而设计了一种软注意力状态共享的用户-系统混合值评价网络,用于相关价值的评估,这种软注意机制的设计参考了文献[28].具体来说,首先将用户智能体状态sU和系统智能体状态sS通过一个软注意力层(Soft Attention Layer)进行计算,获得各自的编码信息向量hU、hS.公式如下:
(1)
(2)
其中,σ为sigmoid函数,f(·)为多层感知机,⊙为按元素乘法.前者表现为软注意力权重,后者表现为非线性特征变换.
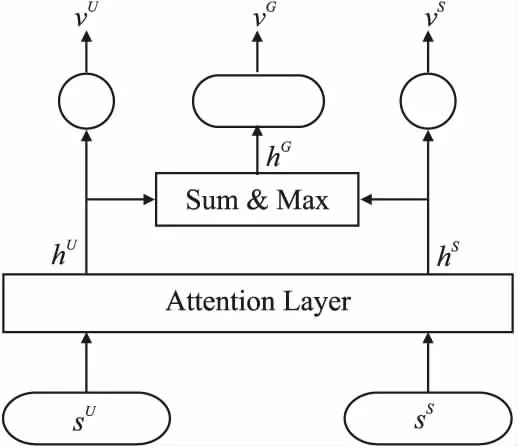
图2 用户-系统混合值评价网络Fig.2 User-system mixing value critic network
然后,对hU、hS取Sum和Max操作得到两者的融合信息向量hG.公式如下:
(3)
除了对两个智能体的编码特征进行加权平均之外,本文还对两者应用了最大池化函数,重点提取关键特征.
最后,将得到的用户智能体编码向量hU、系统智能体编码向量hS和两者之间的融合向量hG传入特定任务层,获得最终的价值VU、VS和VG.公式如下:
VU=fU(hU)
(4)
VS=fS(hS)
(5)
VG=fG(hG)
(6)
3.4 对话策略学习
在处理多域、复杂的对话任务时,策略的动作空间可能变得非常大,这使得对话策略几乎不可能从零开始探索学习.因此,本文通过以下两个阶段进行优化:
1)模仿学习-行为克隆,从人类真实对话数据的对话轨迹中抽取状态-动作对,把状态看作输入特征、动作看作输出标记进行分类学习,进而获取最优策略模型.本文使用逻辑回归进行策略的预训练.另外,由于单个智能体在一个对话回合中只能产生少量的对话行为,为了减轻数据的偏差,对标签加入α权重,损失函数定义如下:
L(X,Y;α)=-α·YTlogσ(X)-(I-Y)Tlog(I-σ(X))
(7)
其中,X为状态向量,Y为动作向量.
2)PPO强化学习,PPO是目前非常主流的强化学习算法,并且是基于AC架构的,包含两个网络:Actor和Critic,因此,它需要分别优化这两组参数.对于Critic来说,它的目标是最小化时序差分(TD)的TD target目标值rt+γV(st+1)和估计值V(st)之间的平方差,为Actor提供小方差的值函数.另外,为了使学习的目标值函数分段更新保持稳定,本文引入了一个固定的目标值网络[14]延迟更新,同时也可以打乱数据的相关性.最终的Critic网络的损失函数公式如下:
(8)
(9)
(10)
(11)

(12)
其中:
δt=rt+γVθ(st+1)-Vθ(st)
(13)
最终的Actor网络使用恒定的裁剪机制作为用户策略和系统策略优化的软约束,公式如下:
(14)
(15)

算法1. PPO多智能体对话策略学习
1.数据:对话行为标记的对话语料D
/* 模仿学习-行为克隆 */
2.初始化:θU,θS
3.公式(7)预训练策略μ和π
/* 多智能体强化学习 */
4.foriteration=1,2,…Ndo
5. 初始化:值网络V=(VU,VS,VG)的参数θ和目标网络参数θ-←θ
6.foractor=1,2,…Ndo
7.repeat
8. 根据μθold、πθold采样动作aU、aS
9. 执行动作并记录随后的状态s′U、s′S和立即奖励rU、rS、rG
10.utilT=1时,会话结束
12.endfor
13.formini_batch=1,2,…Ndo
/* Critic更新 */
14. 公式(11)更新混合值评价网络θ
15.C步之后,更新目标网络θ-←θ
/* Actor更新*/
17.endfor
19.end
4 实 验
4.1 数据集
本文使用MultiWOZ,这是一个面向任务的多域多意图的对话语料库,包含7个域、13个意图、10,483个对话和71,544个对话回合.单域和多域对话的平均回合数分别为8.93和15.39.在数据收集过程中,要求每个用户遵循预先设定的用户目标,并在交互过程中允许用户在会话中更改其目标,因此收集到的对话与现实世界中的对话更加接近.语料库还提供了定义外部数据库的所有实体属性的本体.
4.2 评估指标
面向任务的对话系统的评估主要包括对话成本和对话任务是否完成.本文通过计算对话回合数(dialogue turns)来反映对话成本,任务成功(task success)利用其它两个指标Inform F1和Matchrate.这两个指标都是在对话行为(dialogue acts)级别计算得到的.具体来讲,Inform F1评估是否已经告知了用户所有请求的信息(例如:门票价格、酒店电话号码).Match rate评估预定实体是否针对所有涉及的领域都符合用户指定的约束条件(例如,城镇北部的酒店).如果智能体未能在某个域中预定实体,则它将在该域上获得0分,每个域的此指标范围为[0,1],所有涉及领域的平均值代表此会话得分.最后,只有告知了所有信息(Inform F1=1),并且预定实体也被正确约束(Match rate=1),整个对话任务才被认为成功(task success=1).
4.3 实验设置
在本文的实验中,代码编写采用Facebook的PyTorch(1)https://pytorch.org/深度学习框架,版本为2.3.0,语言为Python.实验环境采用了GoogleColab提供的GPU.本文使用验证集进行模型选择,实验中超参数的设置和调整是根据实验的精度和损失手动调整的.通过广泛的超参数调优,实验的超参数如表2所示.
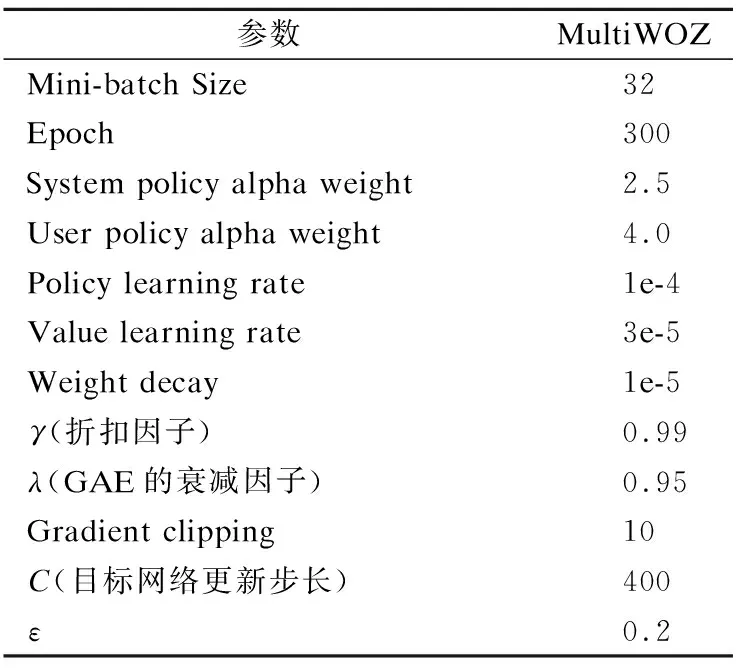
表2 实验参数Table 2 Experimental parameters
4.4 基准模型
为了更好的进行实验比较分析,本文参考了文献[27]设计了以下基准模型进行比较:
1)SL:采用模仿学习中的行为克隆方法直接训练用户智能体和系统智能体,与本文的预训练阶段一致.
2)RL:在模仿学习的基础上进行独立的强化学习.具体来说,通过固定一个智能体的策略,来学习另一个智能体的对话策略.

4)IterDPL:文献[29]首先从对话语料库中学习基本的对话策略,然后通过深度强化学习迭代优化其策略,从而进一步改进它们.其中,对话代理和用户模拟器都设计有可以端到端训练的神经网络模型.
5)MADPL:文献[27]提出了一种面向任务的多智能体对话策略学习方法,并设计了一种角色感知的混合价值网络.
4.5 实验结果及分析
实验过程中,本文采用了1000个用户目标进行自动评估.表3展示了用户目标具体的领域分布情况,其中,Restaurant域最多,为455个.Police域最少,为22个.用户目标最多包含3个域,2个域的占比50%.由于多域的存在,每个域的用户目标的统计量会重复计算.当对话启动时,两个智能体根据给定的用户目标彼此交互.
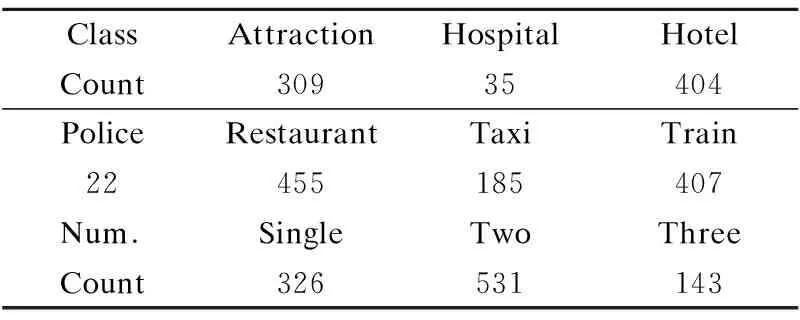
表3 自动评估中用户目标的领域分布Table 3 Domain distribution of user goals in the automatic evaluation
表4展示了在MultiWOZ数据集上的实验结果,其中,用户智能体和系统智能体的策略是根据一定的条件训练得到.具体来讲,SL/SL是通过有监督的模仿学习直接训练得到的,它的task success最差,只有50%,这表明单纯的从训练数据
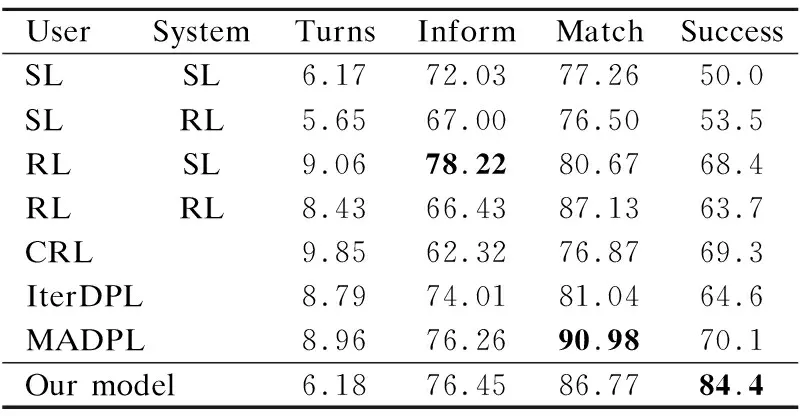
表4 MultiWOZ数据集上的实验结果Table 4 Experimental results on MultiWOZ dataset
集上学习到的策略,难以很好的泛化到新的用户目标上.单个RL的策略(表4中2-4行)是通过固定一方智能体来训练另一方智能体的策略.它们的task success比SL/SL分别高出3.5%、18.4%、13.7%,这是由于强化学习的加入使得训练模型可以在复杂环境中互动得到策略性能的提升,也体现出了强化学习在此任务上的有效性.RL/SL的用户智能体通过强化学习训练能更好的适应系统智能体,Inform F1最高为78.22%.多RL的策略(表4中5-8行)比单个RL策略训练得到的性能要好.CRL通过使用相同的优势值对两个智能体同时进行更新,它的task success为69.3%,比IterDPL高出4.7%,表明了CTDE架构在多智能体训练任务上的有效性.MADPL的Match rate最高为90.98%,task success与CRL相当为70.1%.相比于表中的其它模型,本文提出的模型在性能上得到的极大的提升,其task success达到了84.4%,比MADPL高出14.3%.另外,对话回合数为6.18,对话成本更低.我们将其原因归结为:1)在模仿学习的基础上对两个智能体进一步进行强化学习的训练,缩短了一定的训练时间,更加高效;2)在一个动态的环境中,两个智能体同时进行交替训练,能够适应复杂环境;3)基于软注意力状态共享的用户-系统混合值评价网络学习到的价值估计,能更好的引导策略梯度的更新;4)使用恒定的裁剪机制的PPO更新方法,样本使用率更高,还能更好约束策略的更新范围.
4.6 消融分析
1)w/o soft attention:Our model去除了软注意力机制,采用与MADPL中相同的值评价网络,则公式(1)-公式(3)分别被替换为:hU=tanh(fU(sU))、hS=tanh(fS(sS))和hG=[hU;hS].
2)w/o PPO:Our model去除PPO,采用与MADPL中相同的Advantage Actor Critic(A2C)算法,则公式(14)和公式(15)分别被替换为:Jπ(φ)=logπφ(aS|sS)[AS(sS)+AG(s)]和Jμ(ω)=logμω(aU|sU)[AU(sU)+AG(s)].
表5展示了在MultiWOZ数据集上的消融实验结果,我们发现以上两种变体在task success上远远优于MADPL模型.具体来讲,w/o soft attention与MADPL采用相同的值评价网络,而强化学习策略采用具有恒定裁剪机制的PPO算法,实验结果task success比MADPL高8.2%.w/o PPO与MADPL采用相同的强化学习策略A2C,而值评价网络采用软注意力机制,实验结果task success比MADPL高10.4%.以上实验结果表明本文模型能够学到更优的对话策略,验证了本文方法的有效性.

表5 MultiWOZ数据集上的消融实验结果Table 5 Ablation experimental results on MultiWOZ dataset
4.7 复杂任务的可伸缩性
为了进一步分析本文提出的模型在复杂任务上的可伸缩性,我们做了一些实验使用了采样得到的1000个用户目标.图3展示了在不同类别或数量的领域中,两个对话智能体交互的性能结果.就领域类别来讲,在Restaurant、Hotel和Train域上,分别有7、10和6个可告知的槽位需要被跟踪.CRL在Restaurant和Hotel域上有较低的Inform F1和Match rate,但是在Train域上有较高的Match rate和task success.在Hotel域上,本文的模型与IterDPL的3个评价指标相当,稍低于MADPL.但是,在Restaurant和Train域上,本文的模型表现优异,其中Match rate和task success都接近100%.而对于不同的领域数量来讲,task success随着领域数量的增加而大大降低.在单域目标中,RL/RL、MADPL和Our model都有比较高的Match rate和task success,其性能指标值接近100%.当目标中有3个域时,SL/RL的Match rate和task success最低,RL/SL的Inform F1较高,但Match rate较低,IterDPL的Match rate较高,但Inform F1较低.而本文提出的模型仍然可以保持较高的Inform F1、Match rate和task success.总的来讲,所有的结果表明本文的模型在多域复杂的对话任务上具有良好的可伸缩性.

图3 根据对话中域的不同类别(左)或数量(右)执行对话代理的性能Fig.3 Performance of the dialog agent according to the different class (left) or number (right) of domains in the dialog
4.8 ConvLab-2上的效果分析
ConvLab-2[30]是一个开放源代码工具包,使研究人员能够使用最新模型构建面向任务的对话系统,进行端到端的整体评估.为了进一步验证本文方法的合理性,我们将本文模型与ConvLab-2平台集成做了一些实验,如表6所示.我们固定了NLU、DST和NLG的模型分别为BERTNLU、RuleDST和TemplateNLG,只变换策略模型进行评估.本文的模型比MLEPolicy、PGPolicy和GDPLPolicy在性能上都有较大提升.其中,比GDPLPolicy在Inform F1、Match rate和task success上分别高出2.76%、16.45%和10.6%.MLEPolicy是在已标注的语料上通过模仿学习训练得到的,而PGPolicy和GDPLPolicy是通过强化学习训练得到的.但是,与RulePolicy相比,我们的模型及以上3种模型性能指标都不理想.其中,RulePolicy是专家规则,比本文模型在Inform F1、Match rate和task success上分别高出了17.87%、47.95%、24.9%.这表明专家规则RulePolicy比目前所设计的策略学习方法更加有效.但是,在复杂任务上,它仍需要专家具备丰富的跨领域的知识,时间和人工成本较高.总的来讲,本文提出的策略学习方法在ConvLab-2平台上效果显著,验证其合理性.

表6 与ConvLab-2集成的实验结果Table 6 Experimental results integrated with ConvLab-2
5 结束语
本文提出了一种PPO强化学习的多智能体对话策略学习方法,该方法避免了显式地构建用户模拟器,可以同时训练用户策略和系统策略.首先利用对话行为标注的对话语料进行有监督的模仿学习,获得初始的对话策略.然后让两个智能体进行面向任务的对话,并通过PPO进一步优化其策略.实验表明,本文提出的模型在多域多意图的MultiWOZ数据集上获得了最好的效果,泛化能力强,并验证了在复杂任务上的可伸缩性.
在未来的工作中,我们将在更复杂的对话语料中应用本文提出的方法.此外,由于奖励稀疏问题,手工设计的奖励可能并不适合.随着系统处理跨多个领域的复杂任务的需求不断增长,需要设计更复杂的奖励功能,这给手动权衡这些不同的因素带来了严峻的挑战.因此,能否自动地推断出激励人的行为和互动的奖励,仍需进一步探索.
