基于极限学习机的南太平洋长鳍金枪鱼渔场预测
2022-07-07曾硕星袁红春
曾硕星,袁红春
(上海海洋大学信息学院,上海 201306)
作为一种大洋性鱼类,长鳍金枪鱼主要分布于南太平洋、印度洋等全球温带海域,洄游性强,经济价值高[1]。近年来,长鳍金枪鱼的年捕捞量呈逐年上升趋势,南太平洋长鳍金枪鱼现已成为我国远洋渔业的重要捕捞鱼种之一[2]。开展南太平洋长鳍金枪鱼渔场预测研究,提高渔场预测精度,对于提高渔业成功捕捞率,助力渔业经济效益提升有着重要价值。
为了提高长鳍金枪鱼的渔场模型预报精度,国内外学者提出了多种模型进行了研究,例如范江涛等[3]采用一元非线性回归方法,按季度建立基于环境因子的长鳍金枪鱼栖息地指数,然后运用于中心渔场的预测,得到了70%以上的模型预报准确性;Zagaglia等[4-5]也针对长鳍金枪鱼渔场预测进行了相关的研究,该研究基于广义加性模型(GAM)及广义线性模型(GLM)对渔场进行回归预测,获得了有效的预测性能;宫鹏等[6]则运用轻度量化梯度促进机(LightGBM)模型,对南太平洋长鳍金枪鱼渔场进行预测,获得了72.6%的预测精度。国内外学者对渔场的预测研究越来越深入,但是这些方法往往基于传统的机器学习方法,模型假设条件一般比较简单,不能较好地适用于具有复杂时空信息的海洋渔场数据。近期学者们发展了一些基于集成学习等机器学习或深度学习方法[6],可以较好地解决线性不可分问题,比较适合于分析渔场多维度数据,但该类模型结构往往比较复杂,计算复杂度通常较高,渔场预测综合性能也有待进一步提高。
随着渔场预测相关研究不断丰富,渔场预测相关影响因子数据规模不断增大,传统的渔场预测方法在学习效率以及准确率等方面都可能出现一定程度上的不足。极限学习机(ELM)[7]算法自2004年被提出以来,一直展现了其具有学习速率快,泛化能力好的特点。一些学者对该算法进行比较研究,均获得了较好的研究成果,如朱抗等[8]提出了一种基于极限学习机的短期风速预测技术,发现ELM相较于传统方法计算时间较快;Pappu 等[9]利用极限学习机对视网膜图像进行新生血管分类,在不同数据集上进行测试,获得98%的平均准确率,同时平均错误率小于0.005,在精度与错误率方面均优于SVM分类器。
本研究提出了一种特殊的类独热编码方法对数据进行离散化编码,同时引入ELM模型,构建了一种新型的渔场预测模型,旨在发挥ELM方法的优势,为渔场预测方法研究提供一种新的思路。
1 材料与方法
1.1 数据来源
主要选用了110°E~135°W,10°S~35°S为研究海域,对2000— 2015年的数据进行分析,主要涉及的海域示意图如下图1。

图1 海域渔场范围示意图Fig.1 Schematic diagram of the sea areafishing ground range
南太平洋金枪鱼的延绳钓数据来源于中西太平洋渔业委员会(WCPFC)。该数据包括作业时间、地理坐标位置(经纬度)、延绳钓钩数、捕获量(渔获尾数)。其中捕捞数据以月为时间分辨率进行记录,产量以5°×5°空间分辨率进行汇总。本研究将利用延绳钓钩数与捕获量(渔获尾数)计算的单位捕捞努力量渔获量(CPUE)[10],并进一步根据单位捕捞努力量渔获量(CPUE)的三分位数,对渔场的产量水平进行等级划分。
温度、海面高度、叶绿素a浓度、溶氧浓度等多种因子都会对金枪鱼的分布产生影响[11-12]。根据现有学者研究,本研究主要选用了对于长鳍金枪鱼分布具有较高影响性的3个环境因子构建预测模型[13],包括来源于美国国家海洋和大气管理局(NOAA)环境数据库的海面温度(SST)数据和叶绿素a浓度(Chla)数据,以及来源于哥白尼海洋环境监测服务中心(CMEMS)的海面高度(SSH)数据。该组数据与作业数据空间分辨率上并不一致,为了使数据保持时空分辨率统一,研究中的环境数据归并于5°×5°空间分辨率。
1.2 数据处理
1.2.1 CPUE计算
单位捕捞努力量渔获量CPUE通常被渔业作业中用来评估渔业资源的丰度水平[14],计算公式如下:
(1)
式中:CCPUE表示一定渔区范围内的单位捕捞努力量渔获量(尾/千钩),f表示该渔区内渔获尾数(单位为尾),h对应渔区钓钩数(千钩)。
通常将渔区按照CPUE的大小使用三分位数分为若干个等级。本研究去除CPUE零值对应的部分样本,按各月CPUE样本总数的上三分位点(33.3%)为分界点,将渔区划分为中心渔场与非中心渔场两类[15-16],获得中心渔场渔区样本总数为3178个,非中心渔场渔区样本总数为5883个。
1.2.2 环境数据处理
基于独热编码技术,本研究提出了一种新型的类独热编码方法。将2000—2015年的空间因子与环境因子数据映射为n×d的二维矩阵。其中n为影响因子数目,本研究中为6,即包括月份、经度、纬度、海表温度、海面高度及叶绿素a浓度等6种影响因子;d=25,表示通过类独热编码方法,将每种影响因子由大到小映射到25个等级。
然后,对样本数据的影响因子进行编码转换。分别把各类影响因子由小到大划分为25个有序等级范围,并确定各样本中各影响因子所属的等级。下一步,为每个样本的各种影响因子分别建立25维特征向量ei(i表示第i个影响因子),其中,若某样本的该影响因子的观测值处于第j个等级,则令该特征向量ei的第j个分量为1,第j±1个分量为0.5,第j±2个分量为0.2,而其他值则为0,形成诸如“0-0.2-0.5-1-0.5-0.2-0”的编码形式。
最后,将上述各样本的所有影响因子特征向量按顺序组合为二维矩阵F=[e1,e2,...,en],形成该样本的影响因子特征矩阵,示意图参见图2。

图2 编码示意图Fig.2 Coding diagram
1.2.3 预测精度检验方法
渔场预测结果与真实捕捞数据的符合程度表现了渔场预测的效果。因为通过CPUE预测分类的渔场,并不能完全代表渔场水平,因此本文将借用参考文献中应用的检验方法,采用渔场总体预测准确率作为评估标准,同时选用各渔场(中心渔场与非中心渔场)预测召回率、渔场预测精确率、F1 Score作为辅助参考[17-18],来验证各种预测模型的性能,具体计算方法如下:
单一渔场预测召回率:
(2)
单一渔场预测精确率:
(3)
渔场总体预测准确率:
(4)

F1 Score的计算公式为:
(5)
式中:P为预测总体精确率;R为总体召回率。
(6)
(7)
式中:r,p计算过程见公式(2)、公式(3);N代表渔场的种类数目;i与上文一致(i=0表示为中心渔场,i=1表示为非中心渔场)。
将测试集数据代入预测模型,重复试验K次,将获得总体预测准确率求取平均值,作为模型最终预测精度。本次试验中,选取试验次数K为100。
1.3 极限学习机
极限学习机(ELM)是Huang等[7]提出的一种新型的前反馈神经网络。有别于传统的SLFN训练算法,极限学习机[19-20]在训练中随机选取输入层和隐藏层偏置,训练过程中,只需要设定隐藏层神经元个数并选择合适的激活函数,其余参数无需调整。最终的输出层权重则是通过广义逆矩阵计算得出,试验操作过程便捷。示意图参见图3[21-22]:

图3 极限学习机网络模型示意图Fig.3 Extreme learning machine network model diagram
假设xi代表第i个数据集,ti代表第i个数据对应的标签,{xi,ti|xi∈Rn,ti∈Rm,i=1,2,...,N},隐藏层神经元节点数为L,单隐层神经网络可以表示为:
(8)
式中:g(x)为激活函数,wj为输入权重;bj是第j个隐层神经元的偏置;βj为输出权重。由于SLFN算法是以oi无限趋近于ti为目的,因此存在:
(9)
设H表示隐层输出,T为样本标签,可以得矩阵表示公式:
Hβ=T
(10)
因为输入权重值以及隐层神经元偏置已经确定,输出矩阵不会发生变化,因此唯一最优解β*可以通过最小二乘法得到,输出权重最优解:
β*=H+T
(11)
式中:H+代表矩阵H的广义逆矩阵。
1.4 算法步骤与试验设计
输入:训练集为2000—2014年环境因子数据和CPUE;测试集为2015年的环境因子数据和CPUE。
输出:标签集为等级分类,包含中心渔场与非中心渔场两类。
具体操作流程如下图4。

图4 试验设计流程图Fig.4 Flow chart of the test design
试验在数据进行预处理时,发现采用传统的独热编码方法时,数据可能过于稀疏,因此采用一种独特的类独热编码方式(见1.2.2节)进行特征离散化编码,以此降低数据的稀疏程度,避免单一因素过多地影响总体预测性能。同时使用F1 Score作为分类性能指标,并与其他传统模型预测结果进行比较,探究模型可行性。
设计多组试验组,探究不同隐藏层节点个数对模型预测性能可能会产生的影响,并进一步研究不同月份该预测模型的总体预测准确率。
2 结果
2.1 隐藏层神经元个数
在相同条件下,本研究设计多组试验,对ELM渔场预测模型的隐层神经元数量进行了K次试验(K=100)。试验发现,当隐藏神经元个数在900左右时,预测性能可能较好,而当隐藏神经元个数大于1000时,渔场预测性能显著逐渐降低,如图5所示。

图5 隐藏层神经元个数对模型预测准确率影响Fig.5 Influence of number of hidden layer neuronson prediction accuracy of model
表1给出了多种隐藏神经元下的渔场预测性能。可以看出,本试验中,在参数选择为860时,所获得的预测结果方差值较小,预测性能较稳定。由此,本试验研究最终选取860,作为隐层神经元的参数个数,来进行模型建立。

表1 参数表Tab.1 The parameter list
2.2 预测精度研究
试验时发现,在对环境因子数据进行编码预处理时,相对于传统的独热编码方式,发现当采用1.22中“0-0.2-0.5-1-0.5-0.2-0”的类独热编码方式进行编码时,可以降低特征矩阵的稀疏程度,总体上可能提高渔场的预测准确率。具体试验结果如表2所示。

表2 渔场预测模型精度Tab.2 Accuracy of fishery prediction model
表3是本模型的预测性能,并参照BP神经网络以及朴素贝叶斯模型的预测性能[6],进行比较的结果。由该表可以看出,ELM模型的预测性能较高,F1 Score可达80.9%。

表3 不同模型试验结果对比Tab.3 Comparison of different model test results
2.3 影响渔场预测的因子
本试验研究了在2015年各月的总体预测准确率,预测结果按月份依次为86.7%、85%、67.2%、62.2%、81.9%、93%、93%、87.6%、75.4%、91.9%、88.7%和89.3%。试验发现,4月的预测准确率最低,为62.2%;6月、7月的预测准确率最高可以达到90%,部分月份渔场预测结果如图6所示。
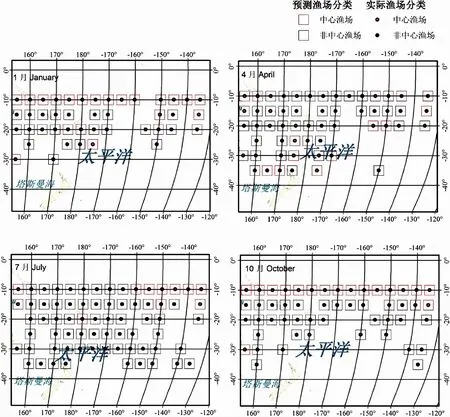
图6 2015年部分实际渔场与预测渔场对比图Fig.6 Comparison chart of the actual fisheries and the predicted fisheries in 2015
基于上述研究结果,本研究进一步探究了相关影响因子对于该模型预测精度影响的相关性。主要试验过程为仅选取单一影响因子来构建预测模型,然后分别获得相应的预测精度。根据试验结果,影响相关性按照从强到弱的顺序可能是经度、纬度、海面温度、海面高度、叶绿素a浓度以及月份,其总体预测准确率分别为81.2%、69.2%、68.1%、67.2%、66.5%和66%。本研究主要选取了特定经纬度范围内的渔场数据。在常规的环境因素中,海面温度可能对于本模型的影响性相对较高,海面高度次之,与侯娟等[17]的研究结果基本一致。
3 讨论
3.1 渔场分类的局限性
本研究主要依据2000—2015年各月渔场累计样本数据计算得出的单位捕捞努力量渔获量数据,对渔场进行了中心渔场与非中心渔场分类,但是鱼类的洄游性与海洋环境的多变性,可能都会影响实际预测中渔场的分类,导致部分中心渔场可能被误分类为非中心渔场,从而在测试中,发现中心渔场的渔场预测召回率略低。 同时,由于添加的环境影响因子仅有3种,且以月为研究单位,对于中心渔场与非中心渔场影响因子区别程度可能不高。因此,可以尝试后续试验中加入更多的环境影响因子,提高中心渔场的渔场预测召回率。
3.2 不同模型预测性能比较
本研究同时参照了BP神经网络与朴素贝叶斯预测模型的试验结果[6],与本模型的预测精度进行对比。BP神经网络[23]通过反向调节调整权值,同时由于缺少确定参数的高效方法,模型不稳定;而朴素贝叶斯模型[24]则是预先通过贝叶斯公式数学模型,计算得出不同可能性的概率值,然后进行预测,但是由于其预先设定了各类特征的独立性,因而可能在分类精度方面会存在一定欠缺[25]。极限学习机模型的算法核心是通过计算获得最优的输出权重,同时输入权重与隐藏层偏置都是随机设定而不需要反向调整,因而相较于BP算法模型来说,ELM训练速度通常较快;同时由于其结构简单,不需要影响因子的预先独立性设定,相较于朴素贝叶斯模型,模型应用便捷。当然,由图5可以看出,在应用极限学习机模型中,该模型的隐藏层神经元个数对模型预测准确率可能有一定的影响,本研究主要是通过多次试验来确定最终的隐藏层神经元个数。可以在后续研究中,进一步发展一些自适应方法来优化模型,提高ELM模型预测的综合性能。
参考相关文献[18]使用的模型评估方法,本试验也采用F1 Score对模型性能进行比较评估。作为评估分类性能的一个常用指标,F1 Score的数值表现了精确率与召回率之间的关系。在试验结果中,本模型的F1 Score值较高,具有较好的渔场预测性能。
3.3 不同影响因子的相关性讨论
研究了在2015年各月的总体预测准确率,预测结果与闫敏等[26-27]研究得出的CPUE周次影响结果一致。本研究主要选取了特定经纬度范围内的渔场数据。在对渔场预测的影响因子中,因为环境因子的形成与所处地理位置经纬度以及所处月份息息相关,在单独采用一种环境因子作为模型构建因子时,研究发现渔场的经纬度可能对本模型预测具有较高的影响,而环境因素次之。
在环境因子中,海面温度对于模型预测精度的影响性可能较大。长鳍金枪鱼作为一种长居于温带海域的鱼种,对于海面温度有一定的依赖性[29]。温度有可能会影响到海水内鱼类集群,同时温度变化亦有可能受到洋流,汛期或者是风力的影响,从而可能影响长鳍金枪鱼的分布,因而可以理解它在本预测模型中占据较高的影响性。
海面高度与海面温度发生协同作用,受海洋涡旋影响,涡旋可能会带动太平洋冷水流与暖水流交汇,带给鱼类更多的浮游生物等饵料,同时影响着长鳍金枪鱼的存活率与分布,进而影响渔场形成[29-30 ]。叶绿素a浓度可能对海洋植物有着较大影响,因而影响相关食物链的浮游生物与鱼群,长鳍金枪鱼的数量也可能随之受到影响。此外,太平洋海域的厄尔尼诺现象,海水盐度,风速等也可能会影响长鳍金枪鱼的分布,但是本研究仅基于三种海洋表层影响因子,需要在后续研究中加入更多环境因子,以期获得更好的预测性能。
4 结论
本研究提出基于极限学习机的渔场预测模型,相较于传统的算法,该模型具有较好的泛化能力,而且训练速度快、处理方便,为面对复杂的海洋环境数据分析提供了一种新的研究思路。但是由于本次研究建立的预测模型所列入的影响因子并不算多,作为一种高度洄游性鱼种,长鳍金枪鱼也会受到不同季节时空性的变化影响。今后可以在模型结构与算法优化的基础上,将更多相关的时空因子融入模型中,进一步提升模型的预测综合性能。
□
