基于强化学习的车辆编队动态定价任务卸载策略
2022-07-07杨志和鲁凌云
杨志和 鲁凌云
(1.北京交通大学计算机与信息技术学院 北京市 100044 2.北京交通大学软件学院 北京市 100044)
1 引言
随着科学技术发展,车辆配备越来越多的智能化设备,以满足人们对驾驶和娱乐需求。因此车辆计算资源的需求越来越大。考虑到能源有限、成本问题,车辆无法承载大量的计算设备。因此当面对视频流采集分析,并实时路径规划这样计算密集,对时延敏感的任务时,无法独立完成。车辆需要将部分任务卸载到具有更多空闲计算资源的设备上。一种选择是云计算中心,但是由于它距离车辆较远,传输任务过程中带来了不可忽略的时延,不适用于对时延敏感的任务。移动边缘计算(Mobile Edge Computing,MEC)可以提供这种低时延的卸载服务。车辆可以将空闲的资源共享,与路边单元(road side unit,RSU)共同提供任务卸载服务。为了将这些资源合理的分配,有必要设计一个有效的方案,利用V2V(Vehicle to Vehicle)、V2I(Vehicle to Infrastructure)将车路进行协同,提升资源利用率和任务卸载的高效性。
在V2X(Vehicle to Everything)应用中有27个用例,其中就包括车辆编队。车辆编队是自动驾驶领域发展中关键一步,也被认为是第五代移动通讯技术中最具代表性的用例之一。在编队中使用虚拟链连接相邻车辆,并通过实时更新移动数据控制车辆,比如速度,相对距离。车辆编队中同样面临处理如自动驾驶,3D导航等计算密集型时延敏感任务的问题。本文关注于车辆编队的任务卸载激励机制,以优化计算资源的利用,提升任务卸载效率。
2 相关工作
现有一些研究车辆编队任务卸载的工作。Hu Y等人将车辆任务卸载优化建模为最小化平均能耗的问题,并采用李雅普诺夫优化确定任务卸载到车队成员、MEC服务器还是本地。Du H等人针对车辆配备大量的传感设备,及其产生的传感任务提出一种新的车辆编队协同感知体系架构,并采用最大-最小公平算法以及迭代算法进行求解。Xiao T等人以最小化系统整体能量消耗和时延为目标,将抢占式调度策略与排队论相结合,建立了具有两个抢占式优先级规则的任务卸载排队模型。Ma X等人考虑到车辆的移动性,采取重分配的任务卸载策略,并根据斯塔克伯格博弈理论利用强化学习理论求解。Yang C等人针对高速车辆提出了一种基于契约的激励机制,促使车辆形成编队,由此进行任务卸载和资源分配。以上工作仅仅考虑了边缘计算服务器和车辆编队成员作为任务卸载服务节点。
Shi J等人在车辆网中考虑一种动态定价的方案对提供任务卸载服务的车辆进行奖励,文中仅仅考虑了根据计算资源的分配量进行定价的方案。Y Yue等人,依据拍卖理论采取双向拍卖的方法进行任务卸载,但是存在多次竞拍的情况,无法满足低时延的要求。
本文提出将车辆编队可通讯范围内的车辆也作为任务卸载服务节点的任务卸载策略,并考虑到车辆的移动性。同时,为了激励车辆能提供空闲的计算资源,提出了综合车辆能源,通讯资源,计算资源的动态定价激励策略,车辆根据定价贡献相应的资源。将问题建模为一个序列决策问题,采用强化学习的方法以优化车辆的最大效用。
3 系统模型
3.1 系统概述
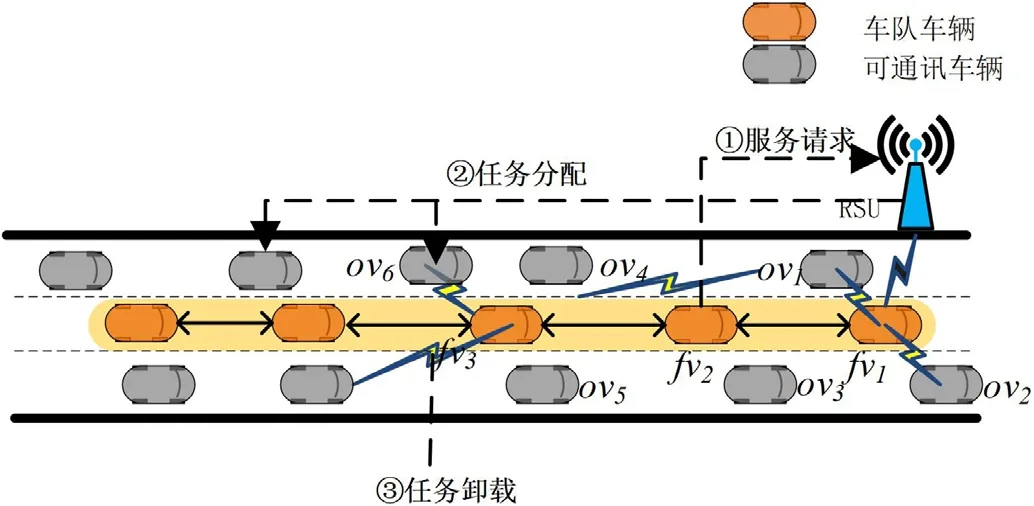
图1:系统架构
当车辆编队成员有任务要卸载时,由编队领队节点收集相关信息,包括任务信息,车辆通信资源信息,以及计算资源信息。编队领队向RSU发送任务卸载请求,RSU进行卸载决策,并确定预计支付服务节点相应的酬金,任务节点进行相应的任务卸载,服务节点执行完成并返回结果后任务节点根据任务完成情况确定最终定价并给付酬金,完成任务卸载。
3.2 任务时延描述
当任务节点进行任务卸载时,某一个服务节点的总体时延可以分为三个部分,包括任务节点到服务节点的传输时延,服务节点的计算时延,服务节点将结果传输到任务节点的传输时延。即
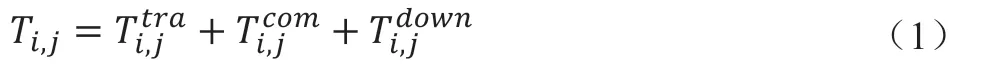
设α为输出结果与任务数据量的比例,一般情况下α<<1,因此在计算时时延可以忽略不计。
对于每个服务节点,计算任务所需的时延如下:

其中,f为服务节点为卸载的任务可分配的计算资源。传输任务所需时延如下:

其中r为数据传输速率,可表示为:


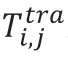
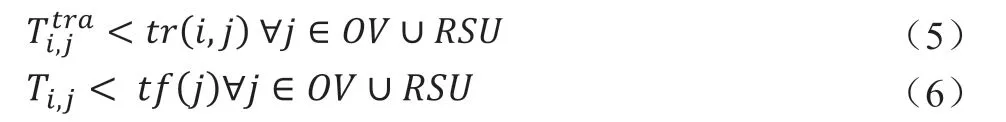
其中,tr(i,j)为车辆编队外节点与任务节点的链路失效时间,tf(j)为车辆编队外节点与车队的可通讯时间。如图2所示,根据车辆位置与速度评估出链路失效时间(Link Expiration Time ,LET)。

图2:链路失效时间计算图


其中,(x,y)、(x,y)为两辆车的位置,θ、θ为两辆车的行驶方向,v、v为两辆车的行驶速度,r为车辆的可通讯半径。由式(7-10)可得辆车相对位置(d,d)以及相对速度(v,v),由此可得:

通过化简可得:

由此可得:

当车队内外车辆行使方向一致时,可得:

对于一个任务而言,其完成时间可表示为:

3.3 任务能耗描述
任务能耗分为两个部分,即任务的传输能耗与计算能耗,表示为:

计算能耗为:


传输功耗为:

3.4 效用描述
由于车辆在提供卸载服务时需要消耗一定的资源,并且计算结果对自己并无利用价值,需要相应的激励机制来鼓励贡献出空闲资源。本文依据合同理论设计相应的方法,任务节点根据资源质量以及完成情况向提供卸载服务的节点提供相应的报酬。
根据合同理论,机制应当满足两个基本约束。
激励相容约束:服务节点更喜欢提供自己真实的能力信息,而不愿意提供虚假信息来骗取报酬。由于涉及到报酬问题,每个车辆都愿意尽力获取更高的收益,激励机制应当避免车辆提供虚假信息而获得更高的收益。
个体理性约束:服务节点相对于闲置资源,更愿意将空闲资源提供出来,供其他车辆使用。为了激励车辆更愿意提供出空闲资源,激励机制应当考虑车辆提供出资源能够获得更高的报酬,促使形成积极环境。
为了量化节点的收益与支出本文定义了任务节点和服务节点的效用函数。任务节点通过任务完成时间的描述来表达对任务完成情况的满意程度,其表示为:
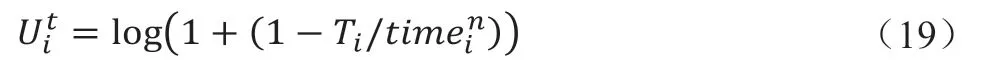
同时,任务节点需要根据提供的资源情况向服务节点支付相应报酬,包括计算资源以及能量资源。由于计算资源属于稀缺资源,需要对其单价根据供应量进行相应调整,设计算资源的基础单价为常量x,任务节点i根据提供的计算资源数量向服务节点j支付的单价为γ'。此外,根据每个节点的情况,对支付单价动态调整,包括信道状态,能源情况,剩余计算资源情况,最终确定的单价为:

其中,E为节点剩余的能量,f为节点空闲的计算资源。任务节点需向服务节点支付的计算资源报酬为:

除计算资源外,服务节点提供卸载服务需要消耗一定的能量,因此任务节点也需要为此提供相应的酬劳,设基本的用电单价为常量e。任务节点根据服务节点的剩余电量对单价进行动态调整,为:
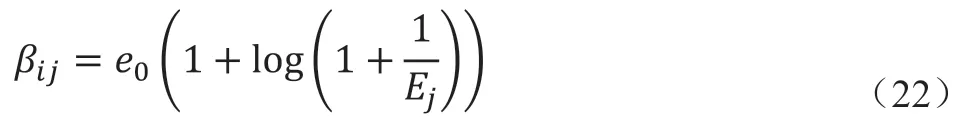
由此,任务节点向服务节点支付的能源报酬为:

任务节点的综合效用函数为:

服务节点根据边际效用递减原则,其根据任务节点的定价γ'来确定其贡献的计算资源为:

服务节点的综合效用函数为:

为约束服务节点能够提供实际的资源状况,需对服务节点执行卸载服务的效果进行评估,并对未达到承诺的节点进行相应的处罚,处罚函数定如下:
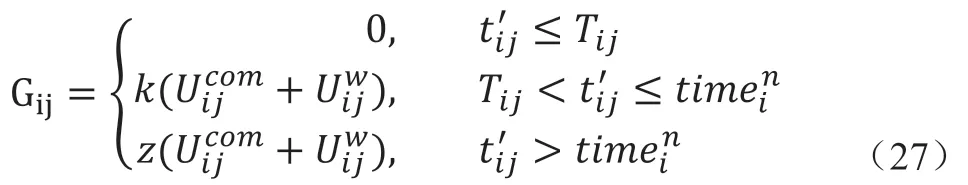
其中t'为实际任务执行所需时间,k,z为惩罚系数满足:

3.5 问题建模
当进行任务卸载决策时,系统的目标是最大化任务节点的效用函数,以达到最优效果。目标问题描述如下:
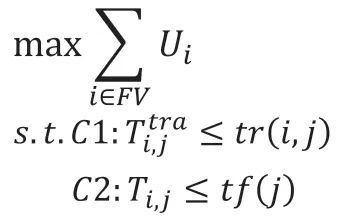

其中,约束C1保证任务传出过程中不会因两个节点超出可通讯时间而中断,C2保证任务整个卸载过程能在车辆与车队可通讯时间内完成,C3、C4保证任务能够被完全分配,C5、C6保证服务节点分配出的计算资源不超过其空闲资源。
4 基于A3C的任务卸载策略
4.1 环境模型
在提出的算法中,路边单元作为智能体用于任务卸载决策。当车辆之间进入可通讯范围时假设可以自动及时建立拓扑连接。因此,车队领队节点可以实时掌握车队通讯范围内车辆的状态以及整个拓扑图,其中状态包括位置,速度,可利用的计算资源,能量状况等。当领队车辆获取它们的状态后,上传至路边单元,由路边单元评估其信道状态,并计算该拓扑可持续的时间,以此进行卸载决策。基本的环境模型如下。
4.1.1 系统状态

假设任务节点能够将卸载任务分配到各个服务节点。除此之外,在任务卸载期间,每个服务节点的其他任务对计算资源的需求不会增加,使得每个服务节点的相关状态不变。当任务节点采取行动,将一定比例的任务卸载到服务节点时,服务节点的计算资源情况也随之改变。同时SNR和车辆之间的链路过期时间也由于车辆的移动发生改变,因此当前状态转移到下一个状态。
4.1.2 动作

p为任务节点i分配给节点j的比例p∈[0,1],假设任务是可以进行划分的,γ为对应预支付的计算资源单价。
4.1.3 奖励
依据优化目标(30),设定相应的奖励函数,目的是降低任务的时延同时考虑能耗,在当前状态s(t)下,执行a(t)决策所获得的奖励为:

该奖励函数的设立目的是降低任务时延,降低任务总功耗,g(x)为设置的惩罚函数,对节点传输时间超出链路失效时间,节点总时间超出与车队通讯的时间的情况进行惩罚。
由于动态的车辆环境,随时变化的通讯链路,节点的可利用资源是很难预测的,因此,很难给出精确的状态转移概率。而Model-free的强化学习,可以解决这样的问题。
4.2 基于A3C的任务卸载算法
为了解决这个问题,本文采用Model-free的A3C方法。目的是在一个时期内最小化任务节点的任务时延,能耗等,因此需要获取最优策略来最大化任务节点的累计回报期望。
策略π(a|s;θ),其参数为θ,根据目前环境状态s,选择合适的动作a,获取到奖励r,环境状态变为s,直至任务完成,最终的奖励和为R。由此形成一个由状态,动作组成的序列τ有:

该序列具马尔科夫性,则其发生的概率为:
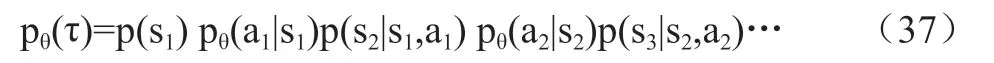
序列τ所获得的奖励和为R(τ),而在策略π的情况下,其期望为:
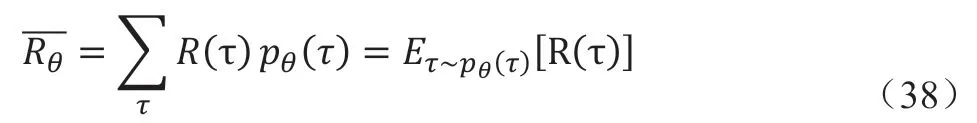
之后定义状态价值函数,即从状态s开始遵循策略π的预期回报:

通过神经网络对其拟合估计值为V(s;θ),其中θ为网络参数。定义优势函数为:
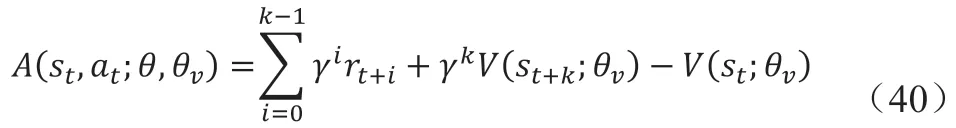
其中γ为折扣因子γ∈[0,1]。目的是在某一个状态下,使其具有越高的优势函数值的动作,策略π选中它的概率越高。
如图3所示,考虑到强化学习需要经过多次的训练才能达到预期的效果,本文采用多个智能体并行学习的方式以提升训练效率,其中全局网络由路边单元维护,并向本地网络提供最新网络参数,本地网络由每一个在路边单元通讯范围内的任务车辆维护,可拉取全局网络参数,并训练更新,向全局网络推送。
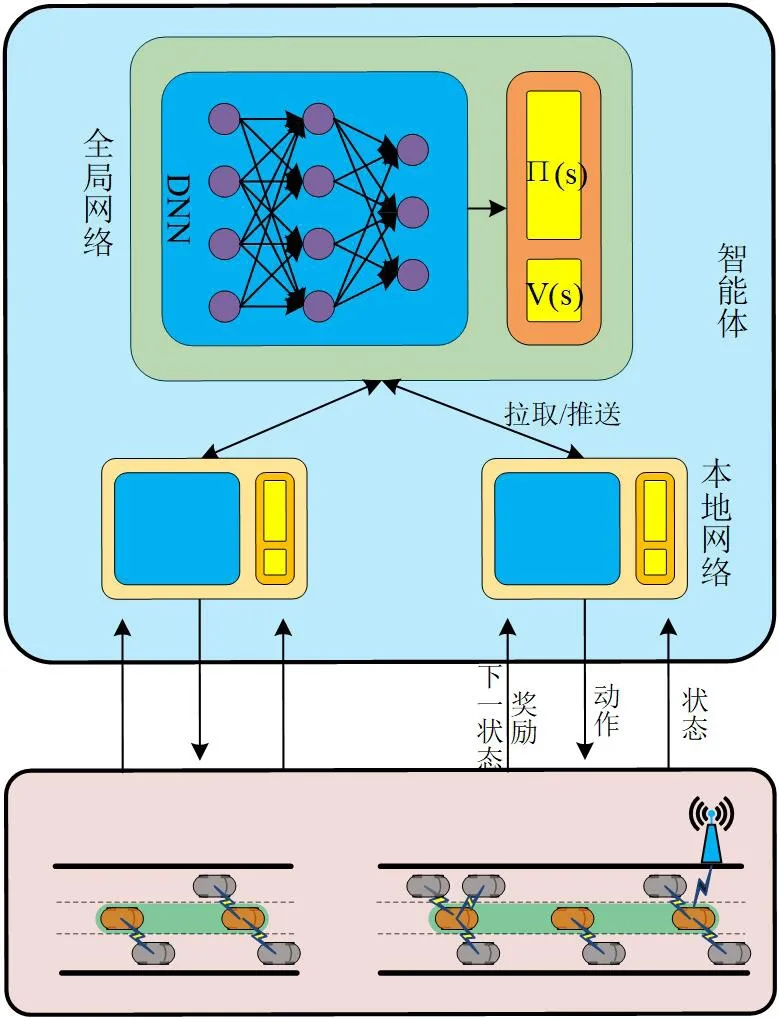
图3:基于A3C协同任务卸载算法架构
智能体中分为两个子网络Actor网络和Critic网络,Actor网络用于训练策略π,Critic网络用于对网络提出的任务分配策略进行评判。在每一轮训练中,智能体先从全局网络拉取参数到本地网络,收集初始的车辆状态s,然后在每一步中,依据策略π选择任务分配策略,依据策略进行任务卸载比例分配,服务节点根据任务分配进行计算,并反馈结果,智能体计算奖励值r,车辆状态由当前状态转入下一个状态s,并将经历(s,a,r,s)存储起来。当到达一定步数时,智能体更新Actor网络和Critic网络参数,并异步更新到全局网络。具体的算法如下。
算法1 基于A3C的任务卸载算法
1./*假设全局共享参数向量为θ和θ*/
2./*假设本地参数向量为θ'和θ'*/;
3.初始化本地计数器t←1
4.repeat
5.梯度清零dθ←0
6.依据全局共享参数同步本地参数θ'=θ且
7.θ'=θ
8.t=t 获取初始车辆节点状态s
9.repeat
10.依据策略π(a|s;θ')获取任务分配策略a
11.并执行,依据任务的时延及资源消耗情况
12.计算奖励r
13.节点状态由s转变为s
14.t←t+1,T←T+1
15.R=V(s,θ')
16.for i∈{t-1,…,t} do
17.R←r+γR
18.dθ←dθ+
19.∇logπ(a|s;θ')(R‐V(s;θ')
20.dθ←dθ+∂(R‐V(s;θ'))/∂θ'
21.end for
22.依据dθ,dθ异步更新θ和θ
23.until 任务完成计算
24.until T>T
5 仿真结果
在该节中,将展示仿真结果来评估本文提出方案的性能。具体的仿真参数如表1所示。为了对比,本文提供了另两个任务卸载算法,定义如下。

表1:仿真参数
贪心算法(GA):对于每个任务,任务节点均选择空闲计算资源最多的服务节点,并且选择使得效用函数最大的定价支付酬劳。
随机算法(SA):对于每个任务,任务节点,随机选择服务节点进行任务卸载,同样选择使效用函数最大的定价支付酬劳。
在仿真中,共有30个卸载任务,并且车队由5辆车组成,车间距为10m,与车队可通讯的车辆数为5至50辆,其与车队内可直接通讯的距离范围为[-50,50]m。车队的行使速度保持在90km/h,其他车辆与车队的相对速度范围是[-10,10]km/h。
如图4所示,对比了在车队外车辆数不同时,任务车辆的平均效用的变化。可以注意到提出的基于A3C的任务卸载算法,任务车辆的平均效用高于其他两种算法。一方面,提出的任务卸载算法可以将任务分配到多个服务节点进行计算,另一方面A3C算法并不是只考虑当前状态提出策略,而是会考虑到未来状态的影响,从而会有更好的效果。
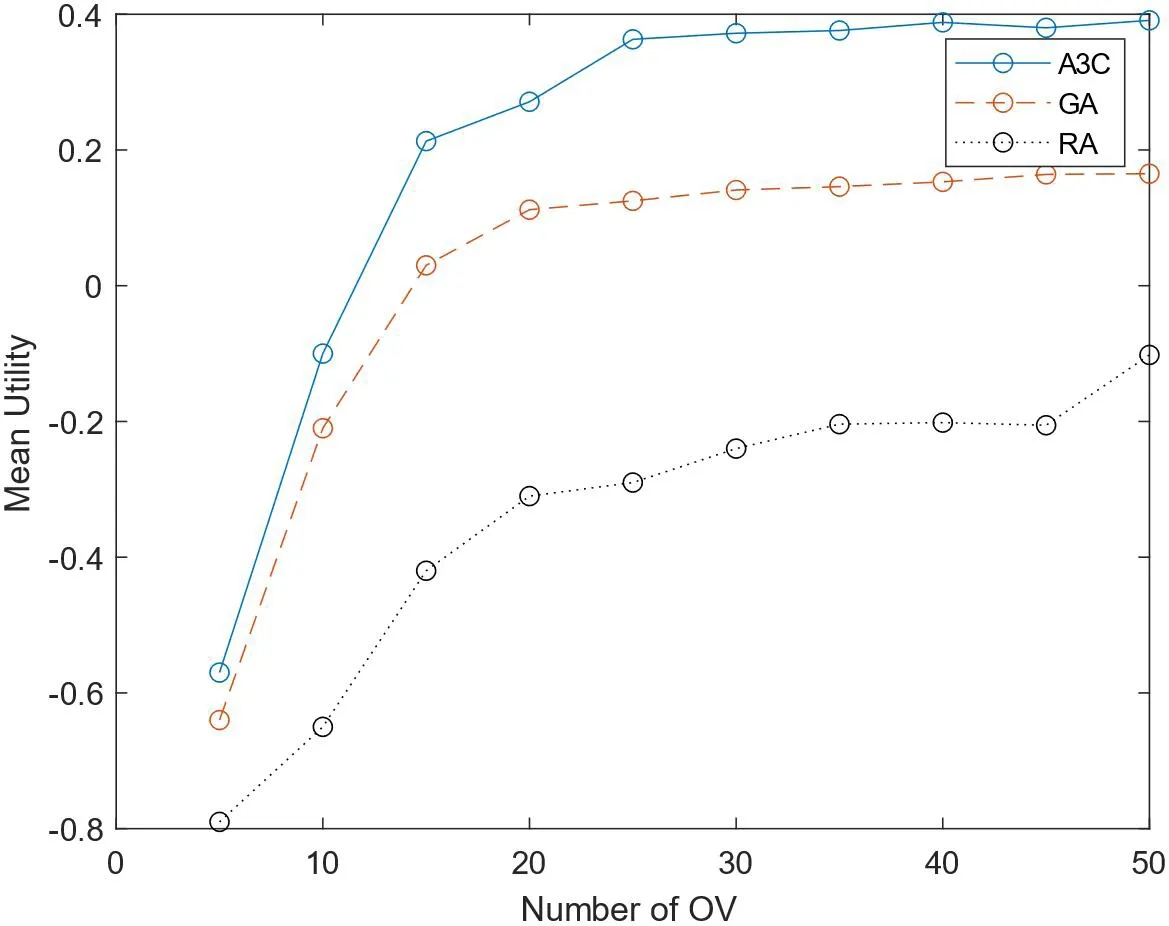
图4:平均效用对比
如图5所示,对比了三种算法随车队外车辆数目变化任务时延占任务最大可容忍时延比例的变化,基于A3C的任务卸载算法整体上会随服务节点数的增加而减小,这是由于任务有更多的节点可以卸载,提高了任务的并行度。而基于贪心的算法只选择具有高计算能力的节点卸载,并不会随服务节点的数量增加而明显减少。
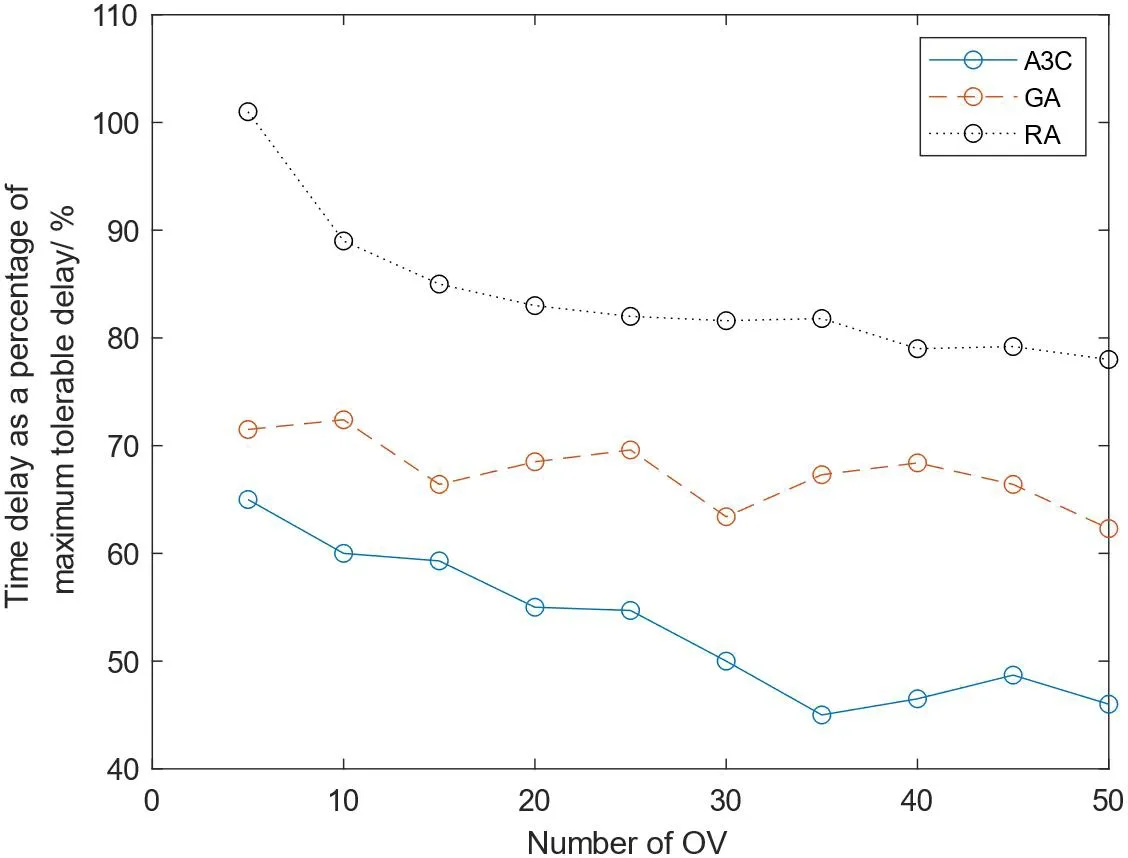
图5:时延对比
如图6所示,基于A3C的卸载算法能量消耗高于基于贪心的算法和随机算法,这是由于为了提升任务节点的总体效用值,对于能耗的关注度较少,为了分配更合理的计算资源提升任务时延,需要消耗稍多的能量。
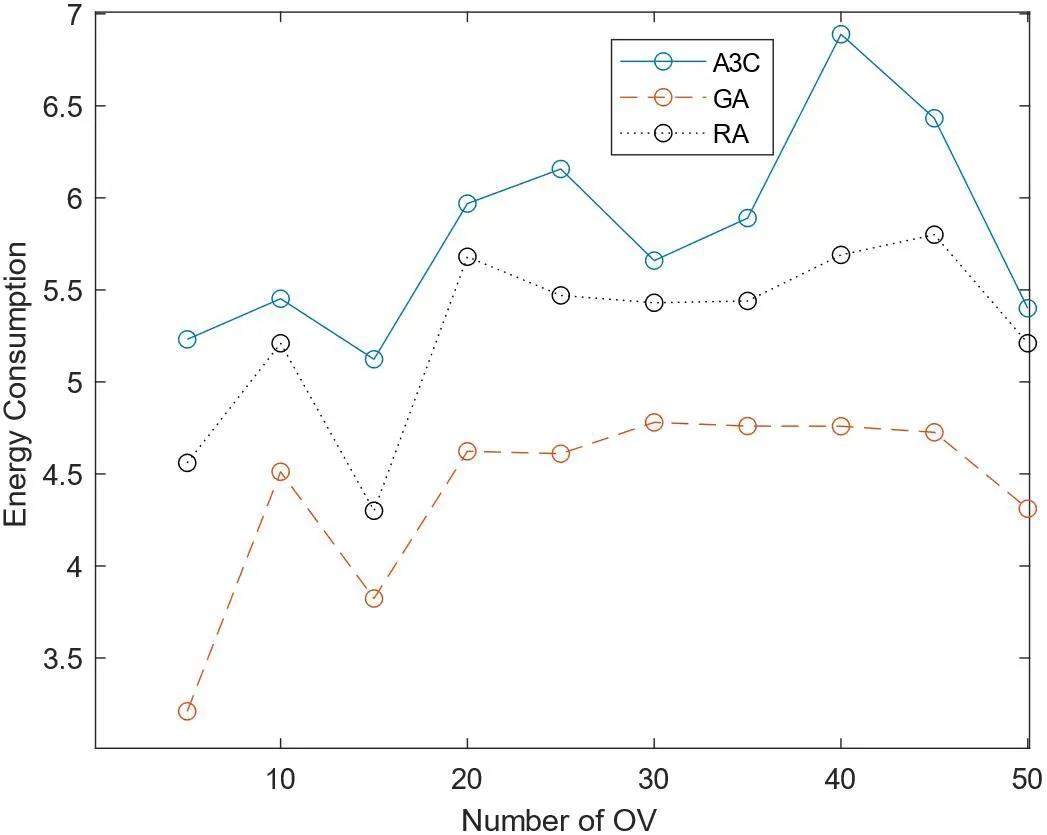
图6:能耗对比
6 结束语
本文研究了车联网中车队场景下分布式任务卸载问题。将任务卸载问题构建为一个顺序决策问题。基于A3C算法,本文提出一个基于服务节点综合能力的动态定价激励方案,并进行任务卸载决策。仿真结果证明了本文提出的方案与其他常规方案相比有更好的性能。未来会考虑多个车队同场景且跨越路边单元的任务卸载问题。
