基于YOLO的人脸口罩检测
2022-07-06王克丽景运革
王克丽,景运革
(运城学院 数学与信息技术学院,山西 运城 044000)
引言
自2020年初新冠疫情暴发以来,戴口罩成为人们出行、复工复产必备的“武器”[1]。通过戴口罩的方式来有效预防新冠病毒和降低呼吸道类病毒的感染已成为人类共识[1,2]。在此疫情影响下,经常发现在一些特定公共场所中,例如航班飞机、高铁、地铁、公共汽车、医院及学校教室等,要求佩戴口罩,但经常会出现个别人忘记佩戴口罩的现象。对于此类现象一般是由相关负责人专门进行提醒和要求,效果明显但却增加了人力成本,准确率不高,同时也增大了人与人之间的病毒传播的机会[3]。在此背景下,研究自动设备来实时准确地检测人脸是否佩戴口罩的方法意义重大[4]。
疫情期间特殊场所进行人脸口罩检测的问题实质属于目标检测任务。目标检测任务旨在让计算机自动检测出图像或视频中关注的目标对象所在的位置及种类,是计算机视觉中的一项经典任务。目前阶段比较流行的目标检测方法就是基于深度学习方法,根据检测流程的差异进一步可分为两种类型:两阶段 (Two Stage) 法和单阶段 (One Stage) 法[5,6]。顾名思义,两阶段法首先生成预选框后再进行物体分类,而单阶段法同时对物体的位置和类别进行预测。两阶段法的代表性算法有:R-CNN,Fast R-CNN,Faster R-CNN 等;单阶段法的代表性算法有:YOLOv1-v4, SSD, FPN 等[7]。两阶段法虽然在算法上先使用启发式法(selective search)或CNN网络产生Region Proposal,然后再在Region Proposal上做分类与回归,准确度高一点,但与YOLO相比,其速度较慢。YOLO模型的算法仅仅使用一个CNN网络直接预测不同目标的类别与位置,可以一目了然地查看图像,并基于图像外观预测与某些类别相关的边界框,而类别可以是任何内容,此特殊功能使YOLO脱颖而出[8]。
在人脸口罩检测任务中,感兴趣的目标实体有两类:戴口罩的人脸和不戴口罩的人脸。因此,人脸口罩检测任务可以简单定义如下:给定一张图片,输出该图片中所有人脸所在的位置坐标 (x_min, y_min,
x_max, y_max) 以及有无戴口罩 (0:未戴口罩,1:戴口罩)。
因为人脸口罩检测任务属于目标检测任务,所以主流的一些基于深度学习的目标检测方法均可应用于人脸口罩检测任务中,有些文献尝试使用SSD模型检测人脸口罩,将戴口罩或未戴口罩的人脸为感兴趣的目标,经过足够的训练之后,便可以较好地完成人脸口罩检测任务[9,10]。针对口罩检测任务主要做了两方面的工作:(1)围绕YOLO系列模型构建了三种人脸口罩检测模型:YOLOv1,YOLOv2,YOLOv3;(2)在预处理后的 AIZOO 数据集上对三种模型从零进行训练和测试,并进行了基本的性能比较和案例分析。
1. 人脸口罩检测
1.1 数据整理
人脸口罩检测任务选用的数据集为AIZOO以及少量真实口罩遮挡人脸识别数据集RMFD(Real-World Masked Face Dataset)。
AIZOO数据集开源了7959张人脸标注图片,该数据集来自WIDER Face和MAFA数据集, 并重新修改了标注和校验[11]。对于开源的AIZOO数据集,通过预处理将其原始地标注文件转化为了YOLO 模型可读取的标注文件,具体格式为:每张图像对应一个后缀替换为.txt 的标注文件,标注文件里的每行对应一个目标实体 (戴口罩的人脸或未戴口罩的人脸),具体格式为 (class, x_center, y_center, width, height)。对于RMFD数据集,使用 lableImg 工具标注了少量样本,格式与AIZOO一致。
为了便于理解,从数据集中挑选了若干已标注的样例图像进行可视化展示:如图 1所示,对于每张图片,标注文件中包含所有人脸的位置坐标以及是否戴口罩 (0:未戴口罩,1:戴口罩)。

图1 标注图像样例
1.2 模型设计
在模型设计中选择了三种YOLO系列的模型:YOLOv1、YOLOv2和 YOLOv3。对于每种模型,都从随机初始化开始训练,并对其进行了基本的性能比较。
相比于两阶段目标检测算法,YOLO系列模型没有显示提取候选框 (region proposal) 的过程,因此模型更简单,速度更快,随之而来的缺点是物体位置识别精度较差,召回率较低。YOLOv1-v3的改进过程总结如下:YOLOv1 使用改进后的 GoogleNet 作为 backbone网络,输入分辨率固定为 448x448,相比 Faster R-CNN 速度有很大提升,但精度不够高;YOLOv2 在YOLOv1中的backbone网络基础上借鉴了VGG 网络中的卷积方式,利用多个小卷积核替代大卷积核,并且利用1x1卷积核代替全连接层,另外还引入了Batch Normalization 操作以及改为预测anchor box的修正量,相对于YOLOv1不仅参数量更少速度更快,而且性能也有所提升;YOLOv3使用了Darknet-53作为backbone网络,该网络使用了残差模块,同时支持多尺度输出,解决了YOLO颗粒度粗的问题,这对小尺度目标检测效果有较大提升。
2. 实验设计及结果
2.1 数据集划分
基于上述数据整理阶段获得的数据,按照近似 3 ∶1∶1的比例划分为训练集、验证集和测试集,每种数据集等比例包含WIDER源图像和MAFA源图像,这三类数据集的图像数量如表1所示。

表1 数据集划分 单位:张
2.2 模型训练
对于每个模型,从随机初始化开始训练,batch大小为16,迭代次数设为80,各模型在训练集上的损失变化见图2。可以看出,三个模型均在80次迭代以内趋于收敛,但是YOLOv2和YOLOv3的损失曲线更平滑,是由于这两个模型中引入了批量标准化(Batch Normalization)等使得神经网络损失(loss landscape)更平滑的策略导致的;同时可以看到YOLOv3相比YOLOv2收敛速度更快,收敛后的损失值也更低,从一定程度上说明YOLOv3相较于YOLOv2在性能上的提升。
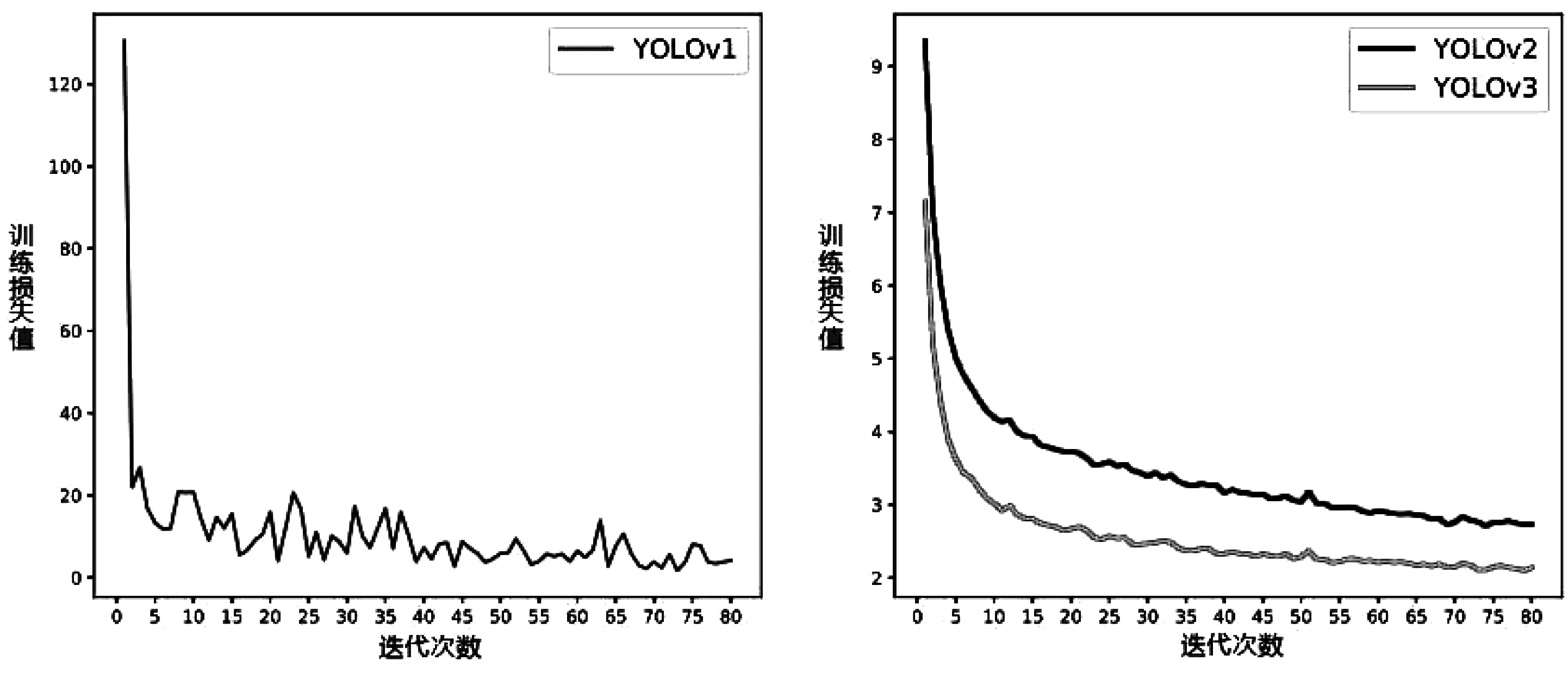
图2 训练损失变化曲线
2.3 平均精度均值
平均精度均值(mAP, meanAveragePrecision),即AP(AveragePrecision)的平均值,它是目标检测的主要评估指标,mAP值越高,表示在所选数据集中对于口罩检测的检测效果越好。三个模型在mAP@.5/mAP@.7/mAP@.9/mAP@[.5:.95] 各指标下关于未戴口罩,戴口罩和平均类别的性能如表2所示。从表2的数据可以总结出出,YOLOv3 在各指标上的性能都为最高,戴口罩类别的mAP@.5值达到了0.947,在一定程度上可以投入实际应用;其次是YOLOv2,戴口罩类别的mAP@.5值为0.939;性能最差的是YOLOv1,戴口罩类别的mAP@.5值仅为0.386。从上述可以得出YOLO系列模型的迭代在性能上不断提升。
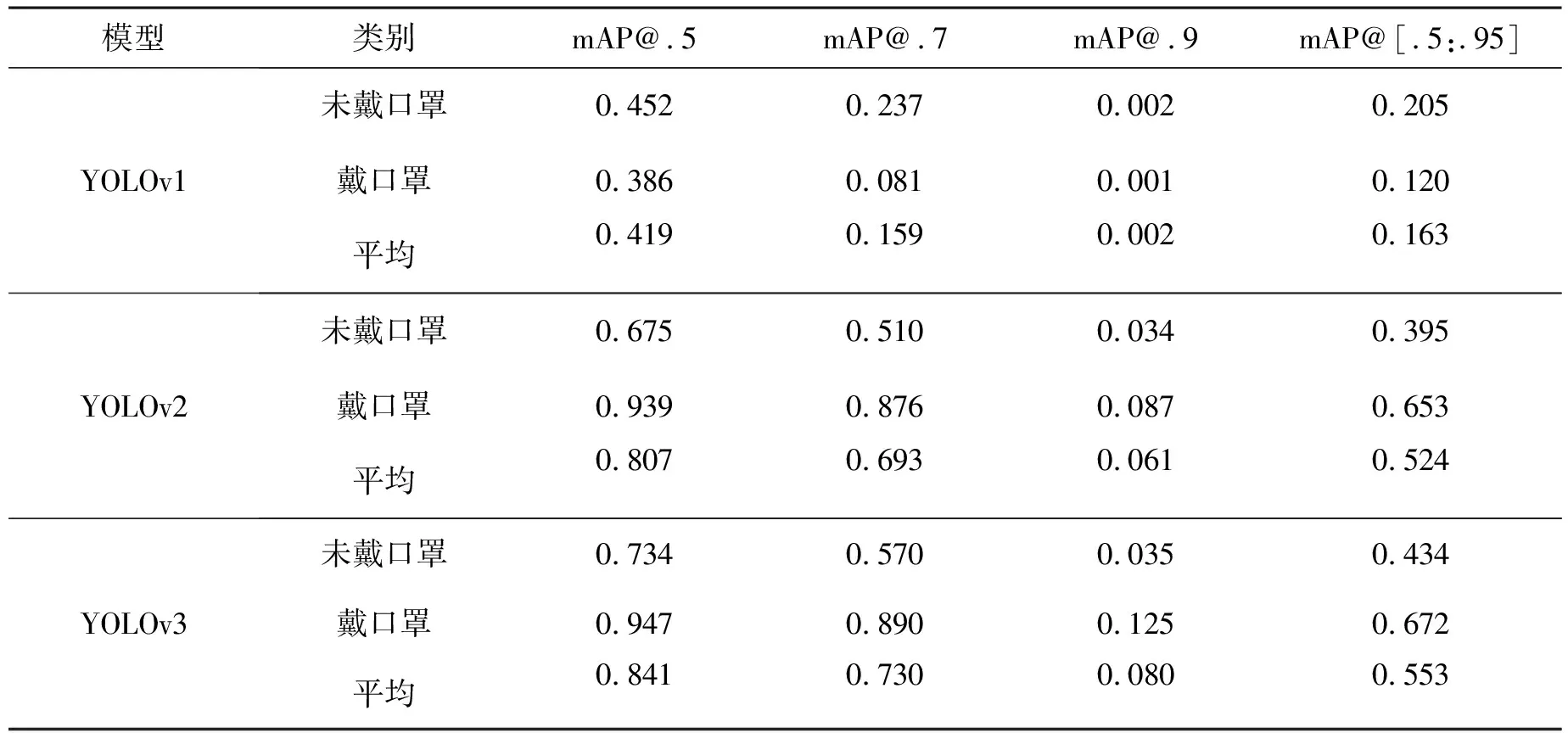
表2 YOLOv1-v3 各指标性能
2.4 准确率和召回率
YOLOv1-v3在IoU阈值分别取0.5、0.7和0.9时每类的准确率和召回率(PR,Precision and Recall)曲线如图3,图4,图5所示。根据PR曲线可以得到以下两个结论:
(1)对于每个模型,IoU阈值越大,模型的性能越差 (根据PR曲线下方的面积),这是由于IoU阈值越大,对模型预测位置的精度要求越高。
(2)对于相同类别和相同IoU阈值的PR曲线,YOLOv3的性能最好,其次为YOLOv2,最差的为YOLOv1。
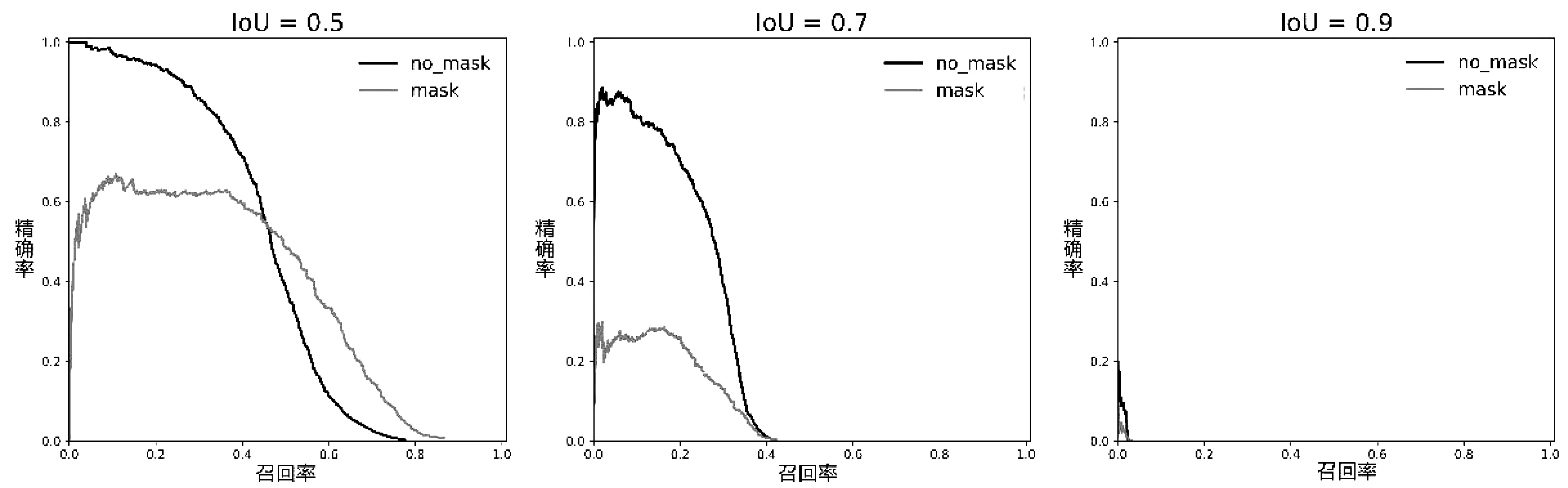
图3 YOLOv1模型的不同IoUs阈值PR曲线
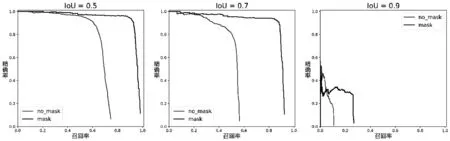
图4 YOLOv2模型的不同IoUs阈值PR曲线
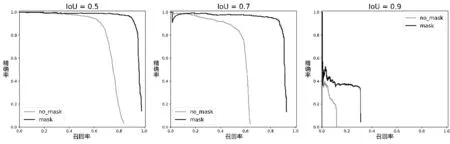
图5 YOLOv2模型的不同IoUs阈值PR曲线
3. 实验结果分析
针对 YOLOv3,我们挑选了若干测试样例对其进行人脸口罩检测,结果如图 6所示。从图中可以看出,红色方框标出了两个检测结果较好的测试样本,尽管图像中的人脸较小,但YOLOv3模型依然检测出了所有人脸并正确识别了是否带有口罩,这得益于YOLOv3在多尺度目标检测上的优化。红色椭圆框标出了两个检测结果较差的测试样本,模型未检测出人脸,经过分析所检测结果,发现这两张图片中的人脸均为侧脸,且图中第4行第3列的图像光线较暗,这从一定程度上反映了YOLOv3 模型可能在侧脸和弱光线环境下检测性能会下降。

图6 测试样例可视化
4. 结论
针对人脸口罩检测任务,尝试构建了三种基于深度学习的人脸口罩检测模型:YOLOv1、YOLOv2和 YOLOv3,并对三个模型的特点和差异进行了详细介绍。对于实验部分,是在预处理后的AIZOO数据集上,对各个模型进行训练和测试,根据实验结果显示YOLOv3模型在各个评价指标(mAP、PR等)上的性能均为最优,排除在个别情况下检测效果不理想,YOLOv3 在大部分情况下都能完成较好的人脸口罩检测,应用前景良好。
