概率统计分析在深度生成模型中的应用
2022-07-06王宝丽安晓丹
王 浩,王宝丽,安晓丹
(1. 太原师范学院 计算机系,山西 晋中 030619;2. 运城学院 数学与信息技术学院,山西 运城 044000)
引言
作为一门交叉学科,人工智能不仅融合了脑认知科学、心理学等社会科学研究成果,而且离不开数学、统计学、信息科学、计算机科学等诸多学科的支持。其中,统计理论及统计应用方法在人工智能中发挥着不可或缺的作用[1,2]。近年来,深度学习作为人工智能的核心技术,已经广泛应用在各个领域,如计算机视觉[3]、自然语言处理[4]、网络数据挖掘[5]等。深度学习作为机器学习的一个工具,其依然满足机器学习的基本范式,而统计学习理论是机器学习的理论基础[6]。一方面,统计分布是决策树学习算法的核心支撑理论,用于控制分支属性的选择及分支节点作为叶子节点的终止条件[7]。另一方面,机器学习的泛化误差、逼近能力等基本理论的分析,都需要依赖严格的概率统计分析,这表明概率统计分析对于机器学习的发展起到了重要的理论支撑作用。
深度学习近年来已经成为人工智能和机器学习领域最热门的研究方向,其在很多工程上的预测精度已经超越了人类。但是,深度学习的理论研究并没有引起大家的重视,深度学习的相关理论仍然没有完善,这严重限制了深度学习的进一步发展。因此,为了更好地理解深度学习,尤其是深度生成模型背后的机理,我们将从概率统计分析的角度对变分自编码器(variational auto-encoder,VAE)[8]和生成对抗网络(Generative Adversarial Networks,GAN)分别进行数学机理分析。
1. 变分自编码器的概率统计分析
变分自编码器作为自编码器(auto-encoder,AE)的变体,其在隐空间引入了概率统计分布后,解决了自编码器无法生成新数据的缺陷。目前,变分自编码器已成为生成任务中主流的生成工具。接下来我们从概率统计的角度分析自编码器的缺陷以及变分自编码器背后的机理。
1.1 自编码器
自编码器属于无监督式的深度学习模型,模型架构如图1所示。主要由编码器(Encoder)和解码器(Decoder)两部分组成。编码器模块主要负责将输入数据x通过映射函数f转变为隐变量z:
z=f(x)
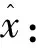
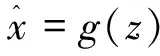
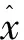
其中loss为重构损失。

图1 自编码器模型架构示意图
根据以上分析,可知编码器的本质是特征降维的过程,解码器的本质是特征重构的过程。也就是自编码器可以将一个数据降维到隐空间后再重构回其本身。同时,从自编码器的优化目标可以看出,自编码器只是对重构损失进行了约束,并没有对隐空间的性质进行约束,仅仅是得到了输入数据对应的具体隐变量。因此,模型经过训练后,只能确保训练集中的数据点能够从隐空间无误差地重构回本身,而这也意味着模型出现了过拟合现象,导致自编码器对于训练集之外的数据点无法进行有效解码,即无法生成新的数据。
1.2 引入变分推断的变分自编码器
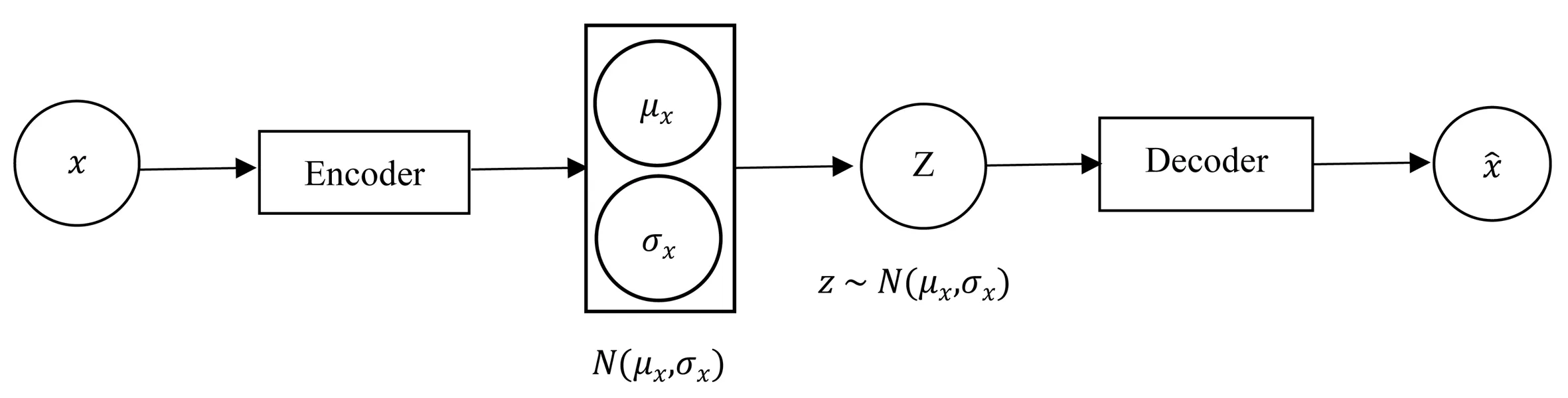
图2 变分自编码器模型架构示意图
根据贝叶斯公式,在训练阶段我们需要利用观测变量对隐空间的概率分布进行更新学习,即:
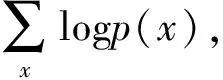
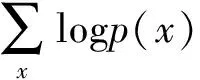
=Eq(z|x)logp(x)
=Eq(z|x)logp(x,z)-Eq(z|x)logp(z|x)
=KL(q(z|x)‖p(z|x))+ELBO
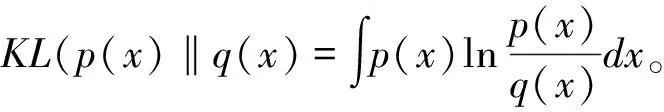
ELBO=-KL(q(z|x)‖p(z|x))+Eq(z|x)logpq(x|z),由于KL(q(z|x)‖p(x|z))≥0,因此可以得到:
=-KL(q(z|x)‖p(z))+Eq(z|x)logp(x|z)
最小化KL(q(z|x)‖p(z))也就是让概率分布q(z|x)和p(z)之间的距离最小化,为了方便计算,变分自编码器假设q(z|x)和p(z)均为正态分布,其中,q(z|x)~N(μ,σ2),p(z)~N(0,I)。可以得到:
KL(N(μ,σ2)‖N(0,1))
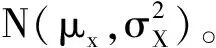
1.3 变分自编码器的损失函数
与自编码器的优化目标不同,变分自编码器的优化目标(损失函数)由两部分组成:
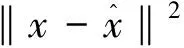
正则化损失也正是变分自编码器与自编码器的本质区别,即变分推断的引入。变分自编码器最初的目的是对自编码器进行改进从而可以用于生成数据,因此需要学习出隐空间的概率分布p,得到隐空间的概率分布后,即可在隐空间随机进行采样其他变量送入解码器,从而生成新的数据。但是,直接去求解后验概率来计算隐空间的概率分布计算量很大,实际中很难直接求解,因此变分自编码器引入变分推断的思想,通过学习易于求解的概率分布q,同时保证概率分布p和q的距离最小化,这样就可以用概率分布q来近似概率分布p。本质上来说,变分推断解决的问题可以归结为概率统计机器学习问题,很多生成模型的背后机理都用到了变分推断。也正是变分推断的引入,即概率统计分析的引入,才使得传统深度学习模型自编码器能够成功应用于生成问题,这也意味着概率统计分析对于深度学习的发展起到了至关重要的作用。
2. 生成对抗网络的概率统计分析
生成对抗网络是深度学习领域最热门的研究方向之一,是目前最成功的生成模型,已经成功应用于实际应用中,特别是在计算机视觉领域掀起了研究热潮,研究学者们相继提出了StyleGAN、DCGAN、CycleGAN等生成模型用于特定任务。接下来我们将从概率统计的角度分析生成对抗网络背后的数学机理。
生成对抗网络属于无监督模型,主要由生成器和判别器两部分组成,模型架构如图3所示。生成对抗网络本质上是一种零和博弈思想的体现,其将数据生成任务看作生成器和判别器两个模块之间的对抗博弈,即生成器根据输入的噪声(通过正态分布采样或者均匀分布采样得到)来生成新样本,而判别器用来判别样本是真实观测的还是由生成器生成的新样本。生成器的目的是生成尽可能逼近真实样本的新样本,而判别器则试图正确区分出真实样本和生成的新样本,这也正是对抗思想的体现,生成器和判别器正是在对抗迭代训练中彼此提高自己的性能,当判别器区分不出真实样本和生成的样本时,此时生成器即可生成完美的新样本。
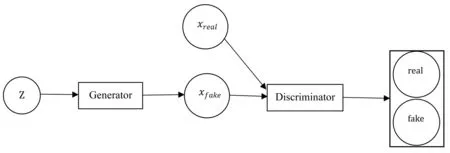
图3 生成对抗网络的模型架构示意图
上述GAN的思想可以用一个优化目标来形式化描述:
其中pdata代表观测真实数据的概率分布,p(z)表示输入的噪声分布,θg和θd分别表示生成器和判别器的参数。Gθg(z)表示生成器生成的新样本。Dθd(x)表示判别器的输出,为[0,1]之间的概率,1表示输入数据为真实样本,0表示输入数据为生成样本。
具体地,生成器Gθg(z)希望最小化目标函数,使得Dθd(Gθg(z))尽量接近于1,即使得其生成的样本尽可能逼近真实样本,即
而判别器Dθd(x)希望最大化目标函数,使得Dθd(x)接近于1,而Dθd(Gθg(z))接近于0,即:
从概率统计的角度分析,生成对抗网络的本质是利用生成器和判别器进行迭代对抗训练,学习一个从随机噪声分布p(z)到真实数据分布pdata的映射函数,然后从噪声分布p(z)中随机采样新的噪声输入该映射函数即可生成得到新的样本。
3. 结语
深度学习虽然在各个应用领域都取得了巨大的成功甚至超过了人类专家水平,然而,理论部分的欠缺严重限制了深度学习的进一步发展。文章从概率统计的角度,对深度生成模型变分自编码器和生成对抗网络背后的数学机理进行了系统的理论分析,为深度生成模型的进一步发展提供了理论支撑。
