基于NIR和SOM-RBF网络的兰州百合关键营养物质定量分析方法
2022-07-06廉小亲汤燊淼吴静珠吴叶兰
廉小亲,陈 群,汤燊淼,吴静珠,吴叶兰,高 超
1. 北京工商大学人工智能学院,北京 100048 2. 北京工商大学中国轻工业工业互联网与大数据重点实验室,北京 100048
引 言
兰州百合作为甘肃省兰州市特产,是中国国家地理标志产品。 其为多年生麟茎类草本植物,茎块由数十瓣鳞片相叠抱合,有百片合成之意而得名。 具有很高的食用、 药用和观赏价值,是我国卫生部首批审批通过的药食两用植物之一。 研究表明,兰州百合的地下麟茎的糖分和蛋白质含量要明显高于其他产地和品种的百合,这两种生物活性物质最能代表兰州百合的营养价值[1]。
目前常见兰州百合蛋白质和多糖的检测方法有比色测定法和凯氏定氮法,这些方法虽然精确,但缺点是样本的检测耗时长、 操作复杂繁琐、 对样本具有破坏性且需要专业的技术人员,因此需要一种快速无损、 便捷有效的检测方法[2-3]。 近红外光谱(NIRS)技术由于具有快速、 精确、 高灵敏度和绿色无污染等优点,已经成功应用于食品追溯、 石油检测、 农业产品鉴别等多方面的研究[4]。 近些年来,国内外学者建立了基于近红外光谱的灵芝、 大米、 藜麦、 马铃薯以及兰州百合等作物品质的评价模型,用以快速实现蛋白质和多糖等含量的检测。 在对各类产品蛋白质和多糖检测方面,赖长江生等[5]利用近红外分析方法构建了灵芝多糖含量快速预测模型,结果显示在5折交互检验优化参数下,最优模型的测试集相关系数为0.851 6,验证均方根差为0.023 6; 李路等[6]采用近红外光谱技术对大米蛋白质和总糖等物质进行了检测,结果表明采用BP网络方法对蛋白质的预测精度为91.2%,采用PLS法对总糖的预测精度为91.89%; 石振兴等[7]开展了藜麦的蛋白质等物质的近红外反射光谱预测建模研究,结果表明采用最佳预处理方法FD+MSC处理后所建立的蛋白质模型预测精度为95.88%; 蒙庆琰等[8]基于近红外光谱实现马铃薯蛋白质的无损检测,结果表明在最优预处理方法MSC下,采用PLSR系数法进行特征波长提取,最终所建立的蛋白质检测模型预测精度为97.79%; 廉小亲等[9]基于近红外利用OSC最佳预处理建立蛋白质和多糖的PLS模型,结果显示,蛋白质和多糖PLS模型Rp分别为0.924和0.920,RMSEP分别为0.878和1.898。 以上研究表明,近红外光谱技术结合不同的预处理和特征波长提取方法在物质的蛋白质和多糖检测方面具有较好的效果。
本研究采用近红外光谱技术采集12 000~4 000 cm-1波数范围内的兰州百合近红外光谱信息,通过光谱预处理和特征波长提取,减少光谱信息中的冗余信息,提升光谱信息的有效性。 在研究分析兰州百合关键营养物质蛋白质和多糖方面,通过利用百合光谱特征波长建立的PLSR无损检测模型,发现其预测精度未能达到预期的85%以上,且预测均方根误差未低于2.0,这在实际应用中是不可取的。
虽然在参数预测领域BP网络应用的较多,但由于BP网络自身存在易形成局部最小、 训练次数多、 收敛速度慢等缺陷,因此其应用受到一定限制。 而RBF由于其自身具有较强的泛化、 信息处理及非线性映射等能力,且算法简单,分析能力很强,在处理非线性问题方面有较为广泛的应用。 但对于RBF,其隐层节点的数目、 隐层径向基函数的中心和宽度却难以确定,这就需要一种方法来确定上述参数。 SOM以其清晰的聚类原则和简单的结构设计正好弥补了RBF自身的缺点[10]。 因此利用基于SOM改进的RBF网络,来预测兰州百合关键营养物质蛋白质和多糖的含量。 该方法在目前的近红外定量模型构建和兰州百合的关键营养物质快速预测领域还鲜有报道。 SOM-RBF法可以实现兰州百合蛋白质和多糖含量的快速预测,为研发兰州百合关键营养物质快速无损检测设备提供了技术支撑。
1 实验部分
1.1 材料
新鲜百合可食用的部分进行鳞片选料、 清洗、 焯水、 烘干等步骤,粉碎制成百合粉(过40目筛),共计获得59个样本,分别装入袋中进行编号,放置在20 ℃室温环境中,等待采集近红外光谱信息。
1.2 仪器
光谱采集用仪器为BRUKER公司生产的Vertex70型傅里叶变换近红外光谱仪,其外观如图1所示。

图1 VERTEX70型傅里叶变换近红外光谱仪Fig.1 Vertex70 Fourier transform infrared spectrometer
1.3 近红外光谱采集
光谱仪的扫描波长范围为12 000~4 000 cm-1,分辨率为8 cm-1,扫描次数为64次[11]。 将百合样本置于石英杯,采用大样品杯旋转采样方式进行光谱扫描。 通过重新加载将每个样品连续扫描3次,并将获得的3条光谱曲线的平均值作为兰州百合的最终光谱数据。
1.4 兰州百合蛋白质和多糖含量测定结果
根据国标法GB/T 5009.5—2016《食品安全国家标准 食品中蛋白质的测定》测定百合粉中蛋白质的含量,根据国标法DB12/T 884—2019《百合鳞茎中多糖的含量测定 紫外/可见分光光度法》测定百合粉中多糖的含量,实验重复3次取平均值。 采用K-S算法按照3∶1原则将样本划分为建模集和预测集,其中45个样本用于定量建模,14个样本用于模型预测。 兰州百合样本的基本统计值如表1所示。
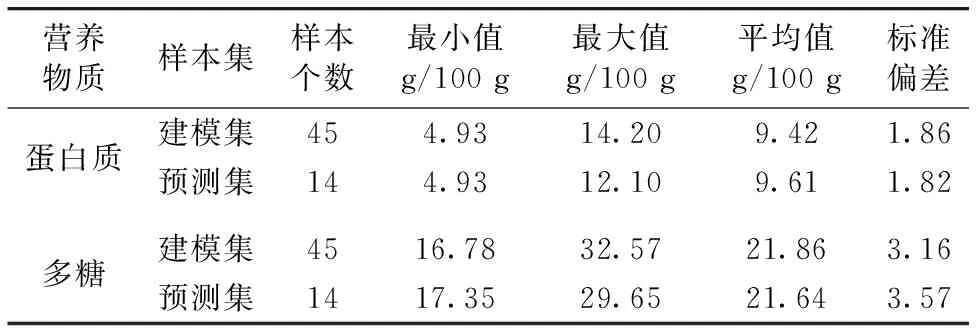
表1 兰州百合样本基本统计表Table 1 Basic statistics of Lanzhou lily samples
1.5 光谱数据预处理与建模分析
为了减少背景环境噪声、 基线漂移和样本不均匀等影响,需要对原始光谱进行预处理[12]。 使用常用的光谱预处理方法包括卷积平滑(S-G)、 归一化(Normalize)、 标准正态变换(SNV)、 多元散射校正(MSC)、 去趋势(Detrend)、 正交信号校正(OSC)以及这几种方法与一阶微分(FD)的组合方法对原始光谱进行预处理,以选出最合适的预处理方法。 进一步采用竞争性自适应重加权采样(CARS)法、 连续投影法[13-15](SPA)和主成分分析(PCA)分别进行特征波长筛选,去除全光谱中冗余和无用的信息,降低模型复杂度,提高建模效率。 最后应用PLSR和SOM-RBF网络法分别对兰州百合关键营养物质蛋白质和多糖的含量进行建模分析。
1.6 模型评价
在确定最佳预处理方法和最优特征波长提取方法中,通过建立PLSR模型,根据训练集相关系数(correlation coefficient of calibration,Rc)、 训练集交叉验证相关系数(correlation coefficient of cross validation,Rv)、 预测集相关系数(correlation coefficient of prediction,Rp)、 建模均方根误差(root mean squared error of calibration,RMSEC)、 预测均方根误差(root mean squared error of prediction,RMSEP)和交叉验证均方根误差(root mean squared error of cross calibration,RMSECV)等模型的评价系数确定最佳预处理方法和特征波长提取方法。 相关系数R和均方根误差RMSEC的计算如式(1)和式(2)所示
(1)
(2)

在建立PLSR和SOM-RBF网络模型中,根据Rp和RMSEP,来评价模型的预测精度。 评价依据为: 当Rp越接近1且RMSEC、 RMSEP、 RMSECV越接近于0,表明所建模型的预测精度越高[10]。 兰州百合光谱数据的预处理工作在The Unscrambler X 10.4软件中进行,特征波长的筛选和模型的建立在MATLAB R2017a中进行。
2 结果与讨论
2.1 光谱数据预处理
将近红外光谱仪测得的兰州百合光谱数据导入软件The Unscrambler X 10.4中进行分析,得到兰州百合的近红外光谱原始图谱。 由于原始光谱中不仅包含有用信息,还包含噪声信号,同时还可能存在基线平移和漂移等问题,为了消除这些干扰,对原始光谱采用SG、 Normalize、 SNV、 MSC、 Detrend、 OSC、 SG+1D、 SG+Normalize、 SG+SNV和SG+Detrend十种方法进行预处理。 为了研究不同预处理方法对建模的影响,分别对全波段下预处理的光谱曲线建立蛋白质和多糖含量的PLSR模型,建模结果如表2和表3所示。
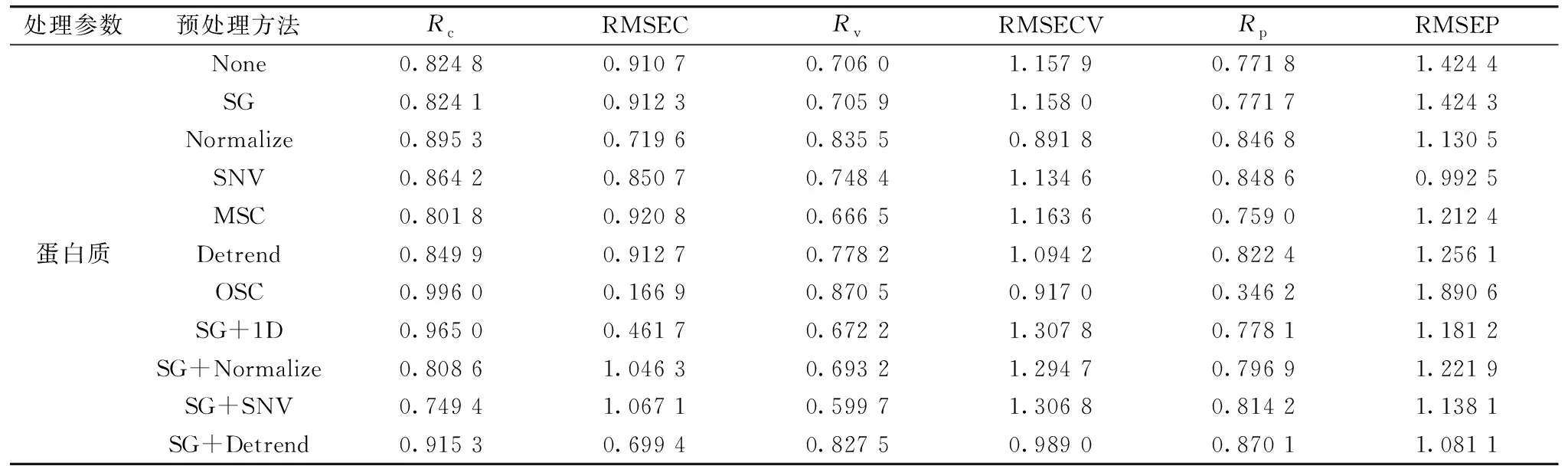
表2 不同光谱预处理的兰州百合蛋白质的PLSR建模结果Table 2 PLSR modeling results of Lanzhou lily protein using the spectra pretreated by different methods

表3 不同光谱预处理的兰州百合多糖的PLSR建模结果Table 3 PLSR modeling results of Lanzhou lily polysaccharide using the spectra pretreated by different methods
由表2和表3可知,不同的光谱预处理方法对模型的建立有明显的影响。 蛋白质和多糖建立的PLSR模型中,蛋白质含量模型的最佳预处理方法为SG+Detrend,其Rc=0.915 3,RMSEC=0.699 4,Rv=0.827 5,RMSECV=0.989 0,Rp=0.870 1,RMSEP=1.081 1; 多糖含量模型的最佳预处理方法为Detrend,其Rc=0.966 7,RMSEC=0.697 3,Rv=0.903 1,RMSECV=1.171 7,Rp=0.921 6,RMSEP=1.692 1。 因此,采用SG+Detrend作为蛋白质含量模型的预处理方法,Detrend作为多糖含量模型的预处理方法,后续特征波长以及预测模型的建立都是基于这两种最优预处理之上。 59组原始光谱经SG+Detrend和Detrend预处理后得到的光谱如图2和图3所示。 可以看到经SG+Detrend和Detrend处理的光谱信息在保留原有光谱主要信息的同时,有效的消除了噪声和漂移的影响。

图2 SG+Detrend方法处理的近红外光谱图Fig.2 NIR spectra of the SG+Detrend method
2.2 波长的确定
近红外光谱主要由有机分子中含氢官能团的倍频和合频吸收峰组成,但是由于这些吸收峰强度低、 灵敏性弱、 吸收带较宽、 重叠区较为严重,因此利用全波段建模会引入冗余信息和共线性变量[14]。 通过对全波段的特征提取,不仅可以降低模型复杂度,提高模型的运行速度,节省时间,还可以用最少的有用信息表征全波段信息,从而提高模型的预测精度。
图3 Detrend方法处理的近红外光谱图Fig.3 NIR spectra of the Detrend method
目前常用的特征波长提取方法有CARS、 SPA、 PCA、 无信息变量消除法(UVE)、 随机蛙跳法(RF)等。 CARS是近些年来提出的新型特征信息筛选方法,该方法是通过自适应重加权采样技术筛选出PLS模型中回归系数绝对值大的波长点,去除权重小的波长点,交叉验证得到均方根误差RMSECV最小的最优波段子集。 SPA是一种前向循环选择方法,是从一个波长开始,每次循环计算它在未选入波长上的投影,将投影向量最大的波长引入到波长组合,直到循环N次,它通过选择含有最少冗余信息的波长变量组合以最小化信息重复叠加[15]。 PCA是用原数据在主元空间上的映射来表示原数据矩阵,因为在主元空间上可以用更少的量来表示,从而实现了数据的降维,消除随机噪声,保留了主要信息。 利用CARS、 SPA和PCA方法分别提取经过相同预处理的光谱特征波段,然后对所提取的特征波长建立PLSR模型,结果如表4所示。
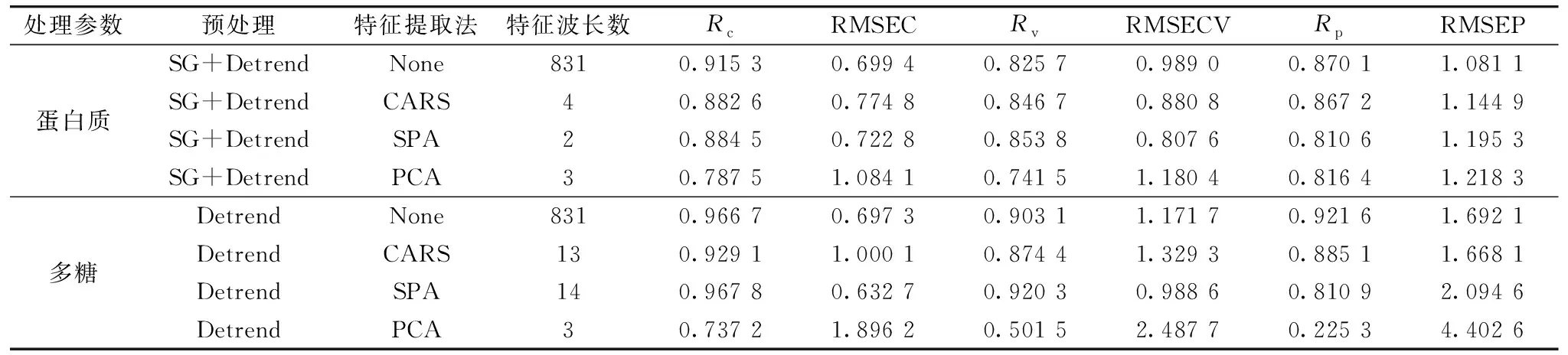
表4 基于CARS、 SPA和PCA方法的PLSR建模结果对比Table 4 Comparison of PLSR modeling results based on CARS, SPA and PCA methods
由表4可知,与全波段的建模比较发现,经过特征提取之后所建立的蛋白质和多糖模型,预测集相关系数和预测均方根误差与全光谱建模相差并不大。 但由于全波段的建模包含了更多的冗余信息,数据处理较慢,运行较为耗时,而特征波长提取的方法可有效的去除这些冗余信息,使模型的性能得到优化。 通过比较CARS、 SPA和PCA三种方法可以发现,SPA无论是在相关系数,还是均方根误差均优于其他两种方法。 对于蛋白质而言,Rc=0.884 5,RMSEC=0.722 8,Rv=0.853 8,RMSECV=0.807 6,Rp=0.810 6,RMSEP=1.195 3,选择的特征波长数为2个; 对于多糖而言,Rc=0.967 8,RMSEC=0.632 7,Rv=0.920 3,RMSECV=0.988 6,Rp=0.810 9,RMSEP=2.094 6,选择的特征波长数为14个。 故选用SPA作为特征波长提取方法。
2.3 预测模型的建立与比较
利用所建立的PLSR和SOM-RBF模型预测测试集中的14份兰州百合样品的蛋白质和多糖含量,同时与用标准方法测定的蛋白质和多糖的标准理化值进行比较,以此验证兰州百合关键营养物质蛋白质和多糖预测模型的精度。
2.3.1 PLSR预测模型的建立
首先利用PLSR分别建立SG+Detrend_SPA_PLSR蛋白质模型和Detrend_SPA_PLSR多糖模型。 蛋白质和多糖含量的建模结果对比如表4所示,预测结果如图4和图5所示。 蛋白质和多糖的相关系数R分别为0.810 6和0.810 9。 预测均方根误差RMSEP分别为1.195 3和2.094 6。
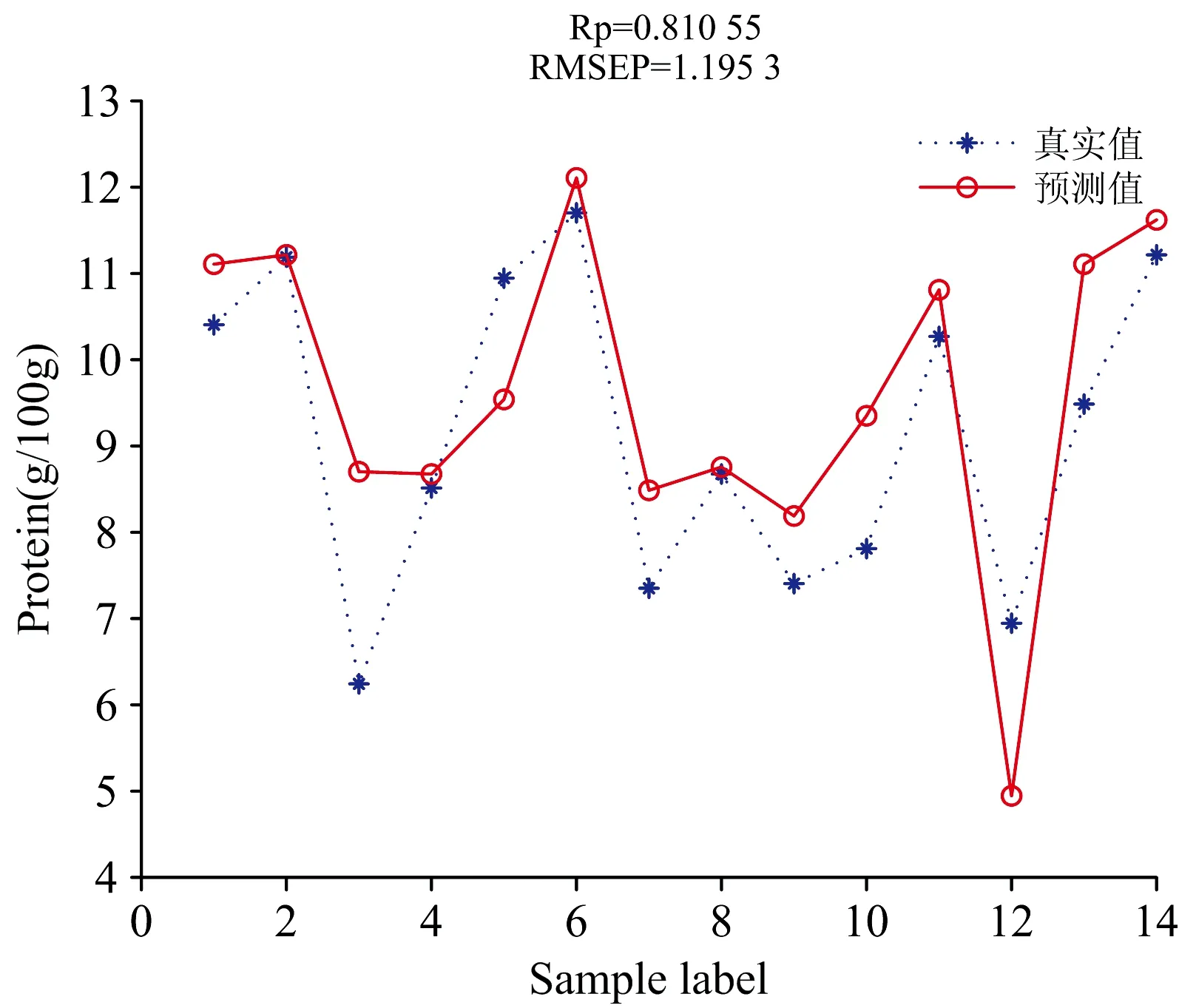
图4 SG+Detrend_SPA_PLSR法对蛋白质的预测结果图Fig.4 SG+Detrend_SPA_PLSR method for theprediction results of protein
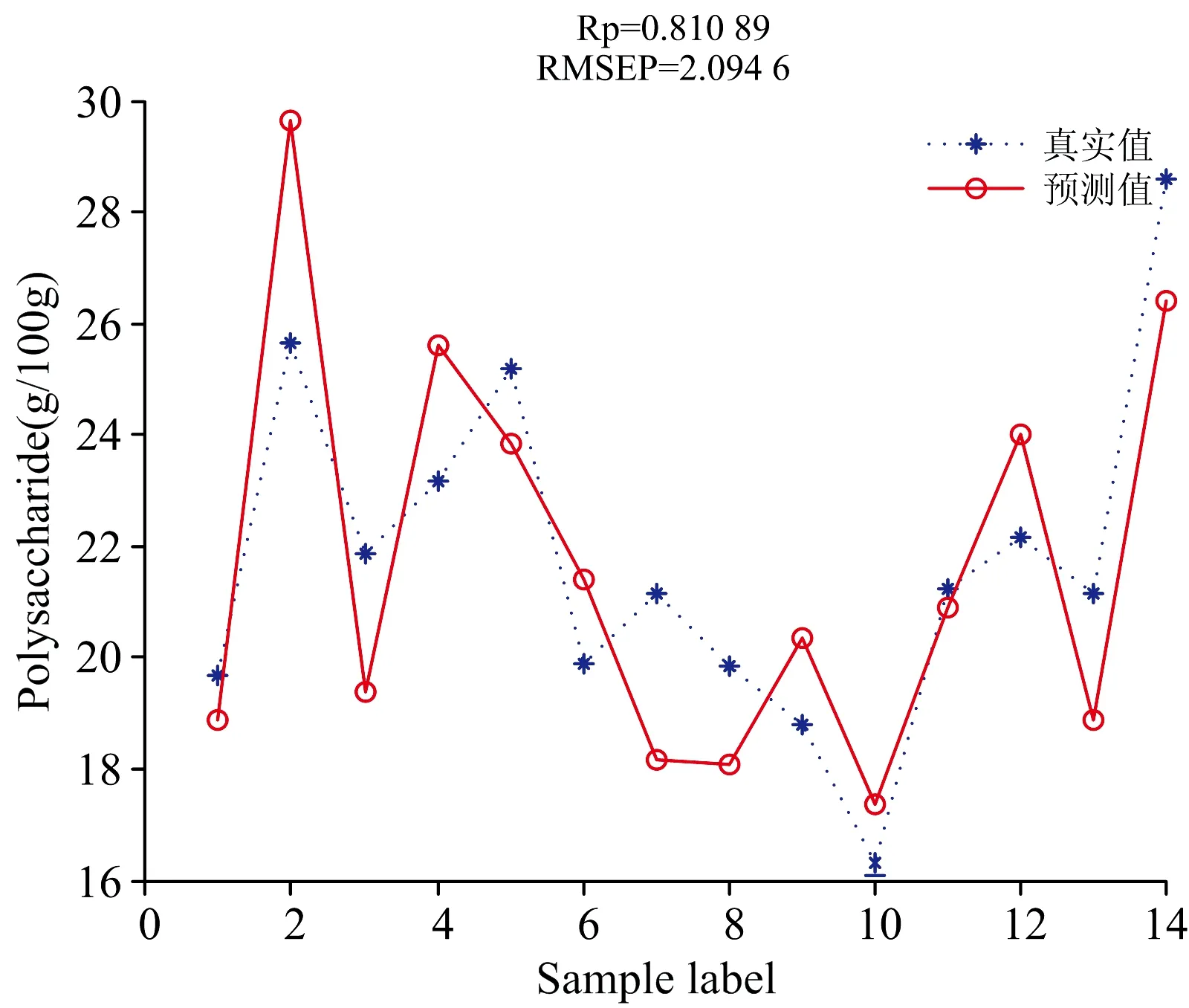
图5 Detrend_SPA_PLSR法对多糖的预测结果图Fig.5 Detrend_SPA_PLSR method for the predictionresults of polysaccharide
2.3.2 SOM-RBF预测模型的建立
利用SOM自组织聚类的特点以及RBF非线性逼近能力,设计SOM-RBF网络模型用于建立兰州百合的SG+Detrend_SPA_SOM-RBF蛋白质模型和Detrend_SPA_SOM-RBF多糖模型。 模型建立主要分为两个步骤:
首先,利用SOM网络分别对提取特征波长后的蛋白质和多糖样本进行聚类训练,确定出聚类类别数,即聚类中心的个数。 同时得到聚类中心向量,即各获胜神经元节点与样本输入节点相连的权值向量,亦称神经元获胜节点的内星权向量。 然后计算各获胜神经元的内星权向量和映射到该获胜神经元的所有样本之间的欧式距离,将其中最小欧式距离判定为SOM网络聚类中心的半径。 蛋白质和多糖的SOM神经网络结构拓扑图如图6所示。
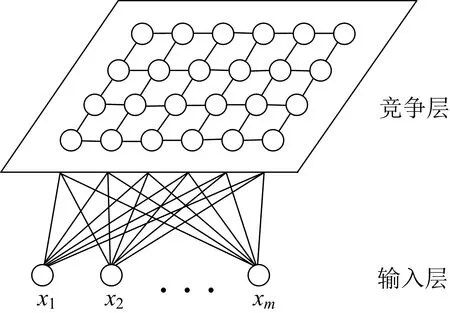
图6 蛋白质和多糖的SOM神经网络结构Fig.6 SOM neural network structure of proteinand polysaccharide
其次,待SOM网络训练完成后,将得到的聚类中心个数作为RBF网络隐层节点的个数; 将得到的各聚类中心向量作为RBF网络隐层节点的中心向量; 并将计算出的各聚类中心半径作为隐层节点中心的宽度。 蛋白质和多糖的RBF网络结构拓扑图如图7所示。 其中输入样本与SOM网络相同; RBF网络隐层节点的径向基函数采用最常用的高斯函数; 输出层节点采用线性函数; 输出即为预测的蛋白质或多糖值。
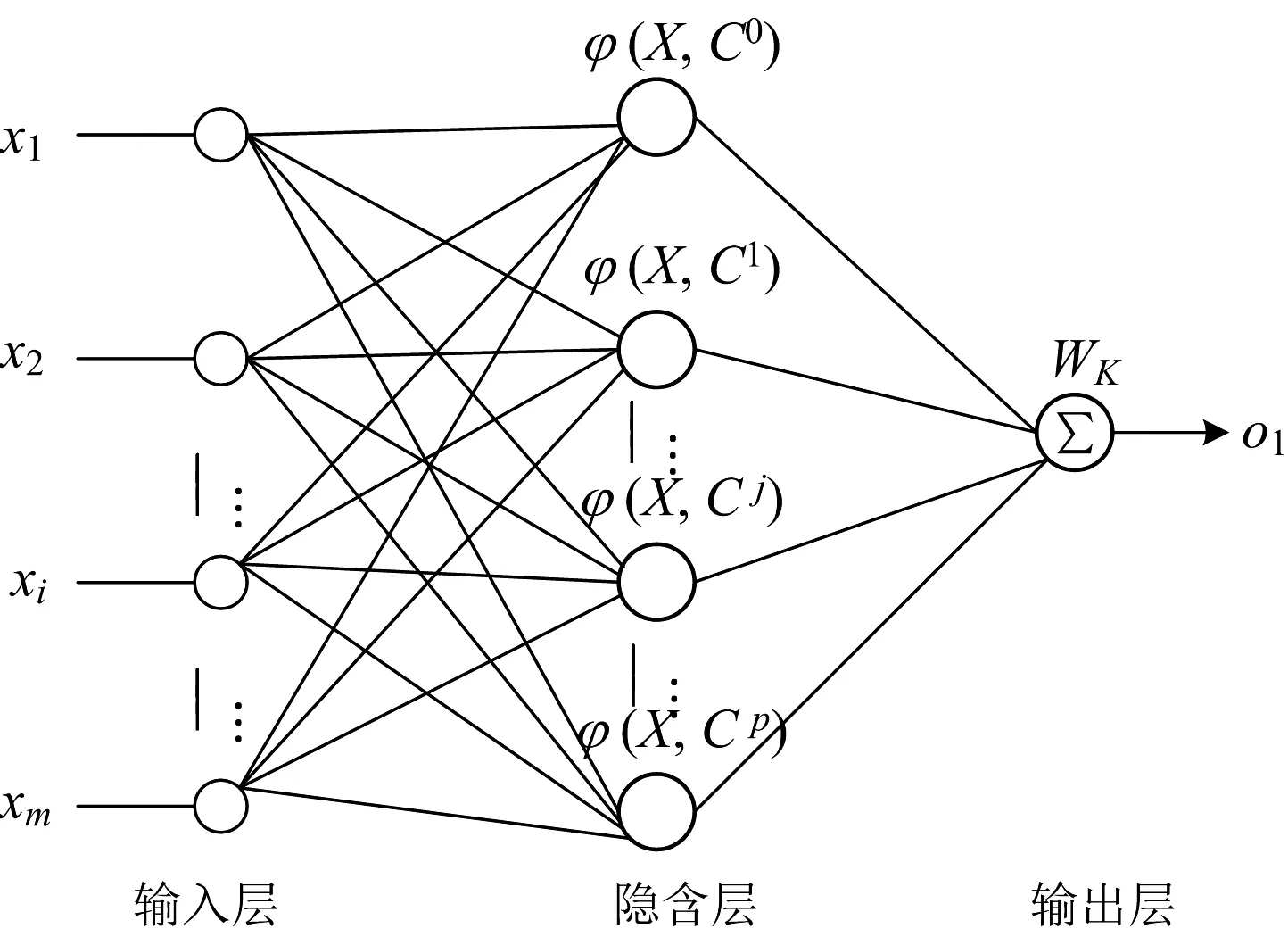
图7 蛋白质和多糖的RBF网络拓扑结构Fig.7 RBF network topology of protein and polysaccharide

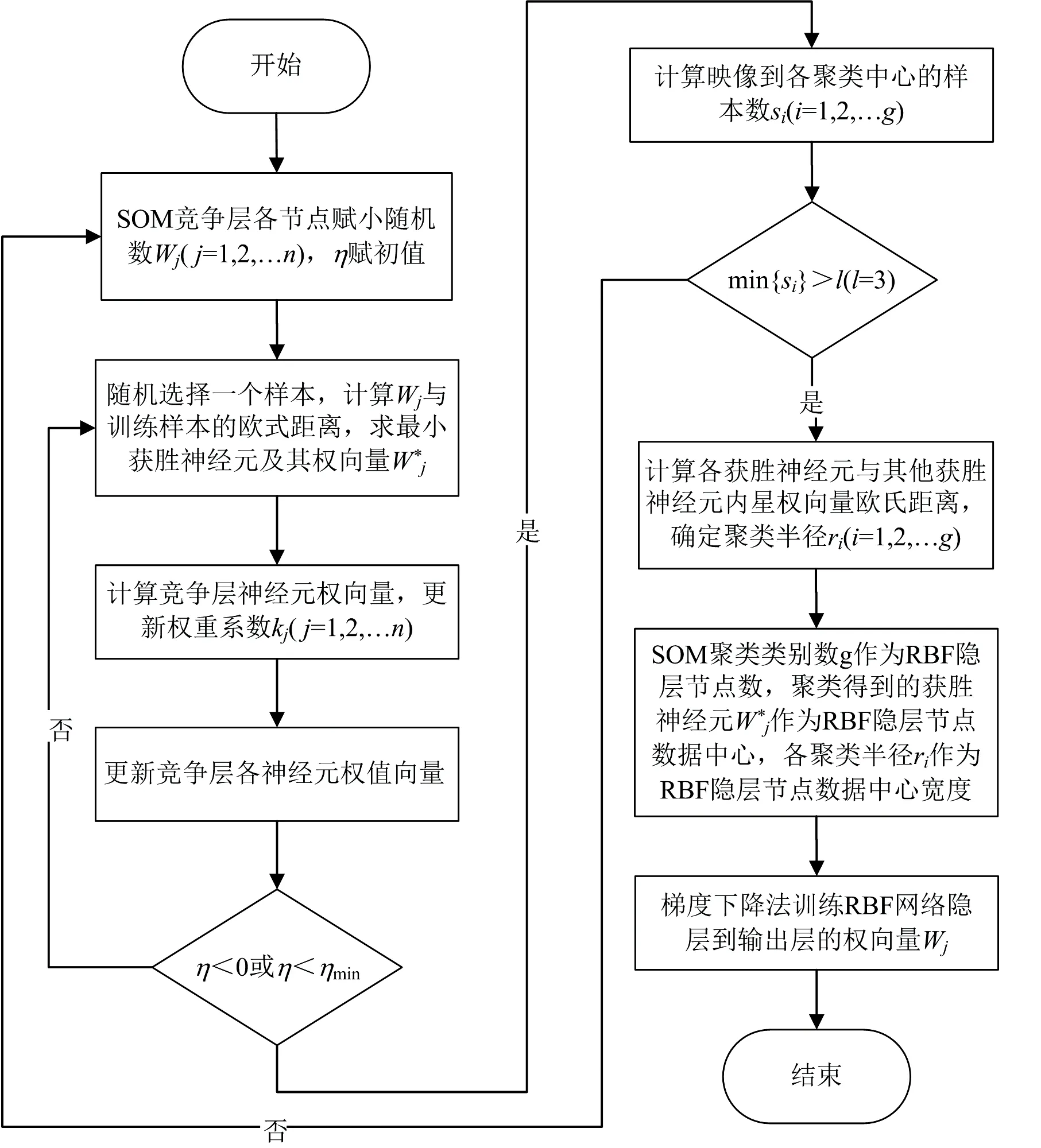
图8 蛋白质和多糖的SOM-RBF预测算法流程图[10]Fig.8 SOM-RBF prediction algorithm flow chartfor protein and polysaccharide[10]
SOM-RBF神经网络对兰州百合关键物质蛋白质和多糖进行预测,得到的结果如图9和图10所示。 蛋白质和多糖的相关系数R分别为0.866 6和0.868 1。 预测均方根误差RMSEP分别为1.038 5和1.799 4。 比较可得出,SOM-RBF的预测能力要优于PLSR。
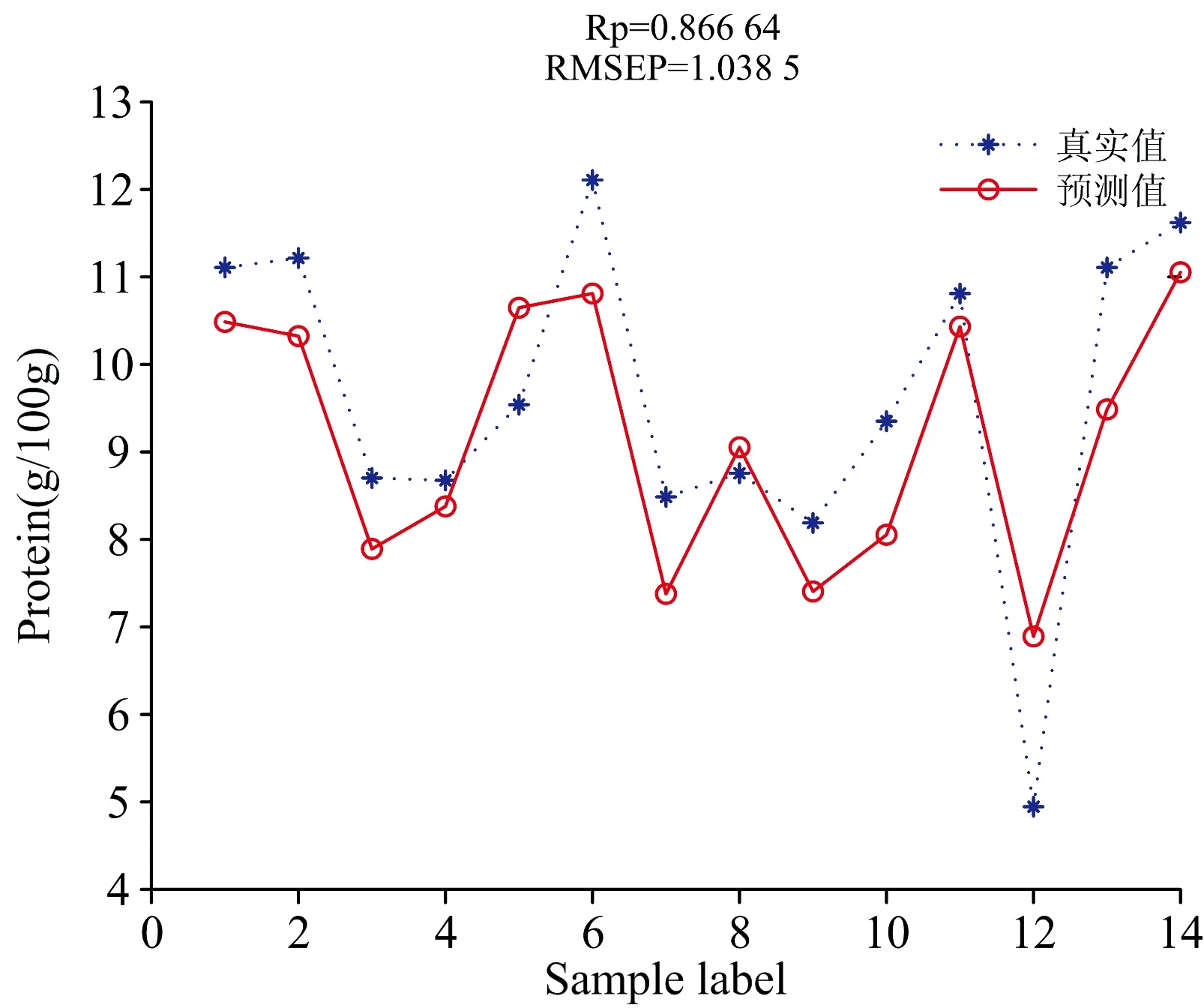
图9 SOM-RBF网络对蛋白质的预测结果图Fig.9 SOM-RBF network prediction results of protein

图10 SOM-RBF网络对多糖的预测结果图Fig.10 SOM-RBF network prediction resultsof polysaccharide
2.3.3 预测模型的比较
为了便于将经典的PLSR法和提出的SOM-RBF神经网络方法进行比较,将这两种预测模型的结果汇总如表5所示。
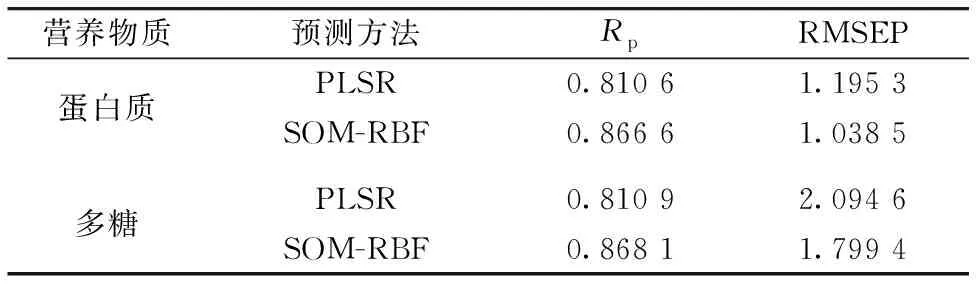
表5 PLSR和SOM-RBF预测模型建模结果比较Table 5 Comparison of modeling results between PLSRand SOM-RBF prediction models
由表5中可得,对于蛋白质而言,采用SOM-RBF法要比PLSR法的Rp高出5.6%、 RMSEP低0.156 8; 对于多糖而言,采用SOM-RBF法要比PLSR法的Rp高出5.72%、 RMSEP低0.295 2,因此提出的SOM-RBF神经网络预测模型在本研究中是可行的。
3 结 论
利用近红外光谱技术在12 000~4 000 cm-1波段范围内对兰州百合关键营养物质蛋白质和多糖含量进行无损检测研究。 建立了基于近红外光谱技术的蛋白质和多糖含量检测方法和模型。 首先利用10种不同预处理方法对原光谱进行处理,确定出蛋白质最佳预处理方法为SG+Detrend,多糖最佳预处理方法为Detrend; 然后利用特征波长提取方法SPA提取原光谱的特征波长; 最后利用PLSR法和SOM-RBF法构建了蛋白质和多糖含量的预测模型。 通过比较得出,PLSR法对蛋白质含量预测中Rp和RMSEP分别为0.810 6和1.195 3; 对多糖含量预测中Rp和RMSEP分别为0.810 9和2.094 6; SOM-RBF法对蛋白质含量预测中Rp和RMSEP分别为0.866 6和1.038 5; 对多糖含量预测中Rp和RMSEP分别为0.868 1和1.799 4。
实验结果表明,采用SOM-RBF预测模型具有较高的预测精度和较低的预测均方根误差,该方法可以实现对兰州百合内部关键营养物质蛋白质和多糖的快速无损预测,为快速检测兰州百合内部营养物质含量提供新思路。 但由于目前对百合样本的获取需经过采集、 风干、 碾碎和营养物质的理化分析等一系列操作,蛋白质和多糖理化值的测量周期较长,因此所获得的样本数量较少,品种也不多,并且模型的精度有限,在后续的研究中将会尽力扩大样本数量并研究新模型以期获得更高的预测精度。
