基于LIF的海面溢油状态识别研究
2022-07-06谢贝贝崔永强张晓丹焦慧慧
袁 丽,谢贝贝,崔永强,张晓丹,焦慧慧
1. 成都信息工程大学计算机学院,四川 成都 610225 2. 燕山大学信息科学与工程学院,河北 秦皇岛 066004
引 言
近年来随着航海事业、 海洋石油开发和沿海经济的发展,突发性海洋溢油事故隐患大大增加[1]。 溢油事故一旦发生,受风力、 浪潮和海洋漂流等的影响,会在海面上迅速扩散,给海洋环境、 海洋生物、 人类经济生活等带来极大的危害,造成不可估量的海洋生态环境损害和社会经济损失[2]。 例如美国墨西哥湾和我国渤海湾的溢油事故无疑是其中最具代表性的事件,一度成为媒体关注的焦点。 因此海洋溢油污染的治理、 改善,成为海洋环境保护工程中刻不容缓的重要工作,而对溢油污染区域准确识别并监测其动态发展变化是控制溢油污染加剧、 制定溢油清理方案的关键。
其次溢油进入海域,由于自身性质和海面环境的不断作用和影响,会经历扩散、 蒸发、 溶解、 分散、 乳化、 光氧化、 微生物降解、 对悬浮物的吸附和沉积到海底等复杂的风化过程[3]。 我们将其简单区分为未乳化、 乳化、 降解等三个主要的阶段。 而对海面上的溢油而言,主要包括未乳化与乳化两个不同阶段。 不同的海面溢油污染类型,需要采用不同的应急处理策略,如围隔围挡、 燃烧消除等[4]。
另外从溢油探测技术来看,激光诱导荧光(LIF)技术指依靠激光源发射激光到海面,海水及各种溢油成分受激发射含各种成分信息的荧光。 它是一种基于光致发光的物质成分和含量分析技术,因其能够探测到石油最主要特性,即独特的石油荧光光谱特征,被认为是目前海面溢油遥感探测的最有效手段之一。 本文基于LIF探测系统获取的未乳化与乳化溢油荧光光谱信息,分析比较得出两者光谱的差异性,并根据光谱差异对溢油状态进行分类,可为海面溢油状态的快速识别提供一种新的方法。
1 实验部分
1.1 实验系统
LIF光谱实验装置原理图如图1所示。 实验采用NDV4542激光二极管,以405 nm激光作为激发光源。 光谱仪为AvaSpec-ULS204,依据溢油荧光光谱信号的响应波段,将波段接收范围设定为420~600 nm。 光谱仪获得的荧光光谱通过计算机进行分析和处理。 电子显微镜用来观察乳化液中液滴的存在方式。

图1 LIF系统测量溢油荧光示意图Fig.1 Schematic diagram of LIF system measuringoil spill fluorescence
1.2 材料与数据采集
选取市售柴油、 煤油两种常见成品油作为实验用油,其中,采用加入乳化剂的方式配备溢油乳化物,在玻璃容器中先加入适量比例的混合乳化剂,再加入定量的成品油和水,用搅拌机进行搅拌,即可制备出一定油水比的溢油乳化物; 采用平铺扩散的方法来制备油膜,用滴管将不同量的油滴到玻璃容器水面上,静置一段时间,待油膜均匀扩散后,即可获得不同厚度的油膜。
在实验数据收集过程中,受背景噪声、 激发光能量波动、 荧光收集效率变化的影响,会造成光谱信号不稳定从而影响后续的分析结果,对于信噪比过低的光谱信号可以采用Savitzky-Golay滤波器[5]平滑处理。 另对于获取的光谱,将不同位置多次采集的信号求平均值,并去除背景光信号。 采集柴油油膜和煤油油膜光谱时,为了使实验更贴近实际情况,每组油膜厚度的选取均不相同。 由于乳化因水油比例的不同所呈现的荧光光谱会有差异,采集乳化柴油光谱时,制备了33种,水占比范围为1%~98%的不同油水比例的乳浊液,每个油水比例采集2组数据; 采集乳化煤油光谱时,选用与柴油相同的方法。 实验中采集乳化柴油光谱66组,乳化煤油光谱42组,柴油油膜光谱25组,煤油油膜光谱27组,共计光谱数据160组。
2 结果与讨论
2.1 荧光光谱变化规律
不同厚度的油膜为纯油分子,乳化溢油为油水混合结构,不同油水比的乳化溢油又具有不同的液滴存在方式。 通过显微镜观察配置的乳化液液滴分布,以及根据油与水在乳液中角色的不同,乳化溢油存在油包水、 油包水包油、 水包油包水、 水包油四种方式。 由于油包水包油和水包油包水没有明确的油水比例界限,将两者合称为多重状态。 所以按液滴存在方式将乳化溢油状态分为油包水、 多重、 水包油三种。 加上未乳化时的油膜,海面溢油可看作包含四种状态。 不同状态溢油由于荧光团的不同表现,在激光作用下激发出的荧光信息也会不同。 因此同一实验条件下,不同状态的海面溢油呈现出不同的荧光光谱曲线形状。
分别选取柴油、 煤油不同状态的部分数据,对其波形进行展示。 如图2、 图3所示。 其中,两图中的分图(a)中图例代表的不同厚度对应不同油滴数目,分图(b),(c)和(d)中图例均为不同含水率。
在之前的研究工作中[6],我们已经总结过溢油乳化物荧光特性变化规律,详细论述了含水与不含水以及不同含水下的光谱区别和产生的原因。 分析不同状态溢油光谱曲线图,也可看出,不管是柴油油膜与乳化柴油的对比,还是煤油油膜与乳化煤油的对比,曲线形状的不同均表现为: 荧光峰个数、 强度以及峰位的不同。 这种差异有利于运用特征参量化+聚类分析法进行区分识别。

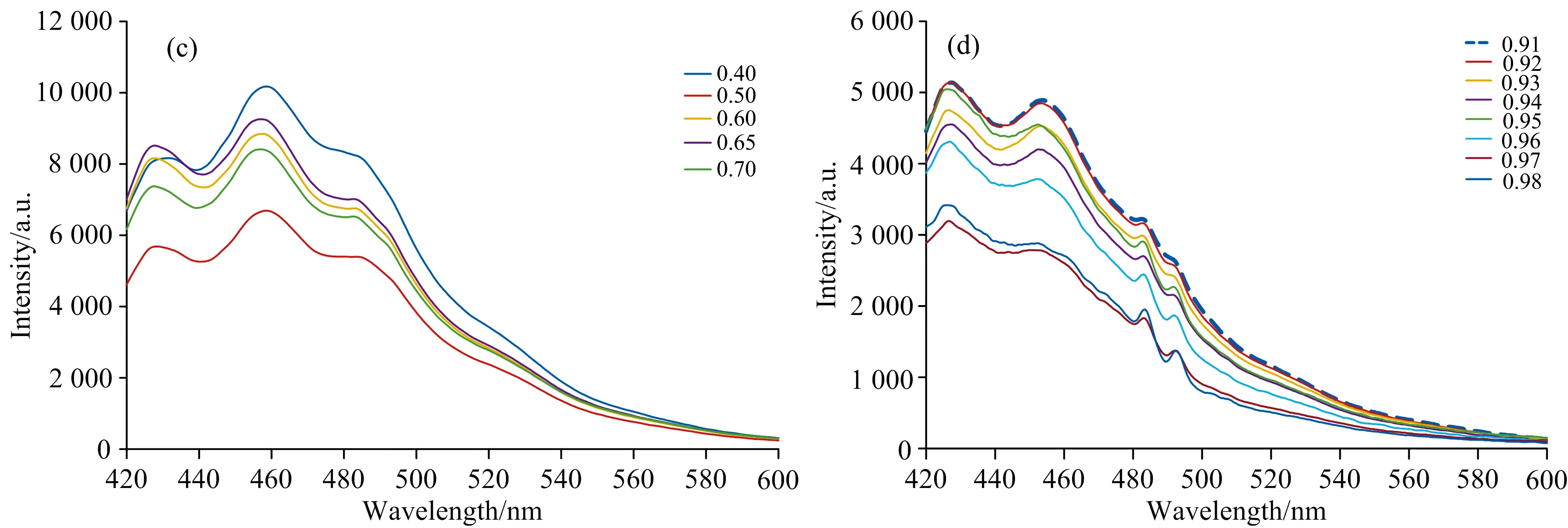
图2 柴油不同状态光谱曲线图(a): 柴油油膜; (b): 油包水型乳化柴油; (c): 多重型乳化柴油; (d): 水包油型乳化柴油Fig.2 Spectrum curves of diesel oil in different states(a): Diesel oil film; (b): Water in oil emulsified diesel oil;(c): Multi heavy emulsified diesel; (d): Oil in water emulsified diesel oil
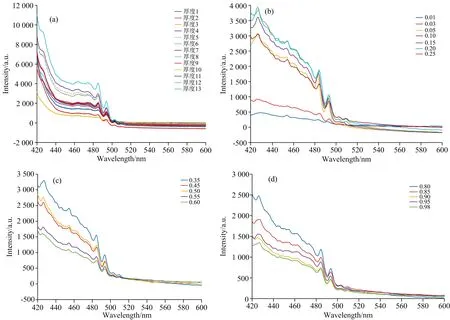
图3 煤油不同状态光谱曲线图(a): 煤油油膜; (b): 油包水型乳化煤油; (c): 多重型乳化煤油; (d): 水包油型乳化煤油Fig.3 Spectrum curves of kerosene in different states(a): Kerosene film; (b): Water in oil emulsified kerosene;(c): Multi heavy emulsified kerosene; (d): Oil in water emulsified kerosene
2.2 溢油状态识别
2.2.1 特征参量化
前面研究得出的光谱变化规律可以构成溢油状态的识别依据。 但由于这些特征属于光谱总体直观形状的描述,需要先进行参数化,将描述性特征用具体数据表示出来,即实现形态空间到数据空间的转换。
将乳化溢油荧光光谱外观形态进行参数化的过程,主要包括荧光峰数,荧光峰值,荧光峰位等几个相关特征进行数据化表示的过程。
首先,选择光谱的平均值和标准差来表示光谱曲线的一般形状,其中
平均值: 表示了荧光光谱的平均能量强度,反映数据的集中趋势。 计算公式为
(1)
标准差: 代表谱值的离散化程度,计算公式为
(2)
选择峰度系数来表示光谱曲线上荧光峰的形态特点,正态分布的峰度为0,其他分布的峰度是以正态分布为标准描述该分布密度形状为陡峭或平坦的数字特征。 计算公式为
(3)
其次,荧光峰数用光谱的曲线斜率来表示,即通过相邻波长差范围内斜率的乘积为负数,且两个斜率是正负次序来确定。
荧光峰位用谱线宽度来表示,谱线宽度指的是光谱曲线最大强度的一半处所对应的两个波长之差,也称为半宽度,此处选用的参数为最大峰高度的半宽度。
荧光峰强: 确定好荧光峰位后,对应的荧光强度值。 此处涉及的参量记为最高峰高度。
最后借助matlab工具,对光谱进行特征参数化,其中,平均值所用函数为M=mean(A, dim),标准差也就是方差的算术平方根,这里计算方差所用函数为V=var(A,w, dim) ; 峰度系数计算函数为k=kurtosis(X, flag); 最高峰高度、 最大峰高度的半宽度几个参数计算所用函数为 [PKS, LOCS, W, P]=findpeaks(Y); 求曲线斜率采用插值后差分代微分的方法,根据斜率值判断荧光峰数。
2.2.2 聚类分析
聚类分析是以样品或指标之间的相近程度为依据对研究对象进行分类的统计分析技术,可对各种类型的数据进行分类分析。 聚类分析不需要进行样本训练,是一种无指导学习的分类方法[7-8]。
其基本原理为: 根据研究对象指标(变量)或者研究的样本(网点)之间存在的不同程度的相似性(相似程度-用样品或者变量之间的距离度量),对于一批分析样品的多个具体观测指标或者样品本身,通过研究找出一些可以用来衡量指标或者样本之间亲疏关系的统计量,将这些统计量作为组划分或类划分的输入依据。 在一定的阈值指标下,将相似程度较大的一部分变量(或样本)聚合为一类,而将另外一部分变量(或样本)根据相似程度聚合成另一类。 逐步进行下去,直到最后,所有的变量(或样本)都处于某一类中。
对描述性特征进行参数化后,将转换后的数据再次进行标准化处理,即可作为聚类分析的输入参量。
本文实现样本聚类,综合考虑各种方法的利弊后,确定采用分层聚类[9]实现。 样本之间的相似性度量,经过反复尝试之后采用欧几里得距离[10]作为样本之间相似性度量,实际分析中两个样本如果同属于一类,则其特征参量相似性越高,欧几里得距离值应该越小,即分类方法采用最短距离法。
2.2.3 识别结果
利用matlab编写相应的算法对荧光光谱数据进行计算,对应的相关特征参数如表1所示。 编号1—66为乳化柴油相关数据,67—91号为柴油油膜相关数据; 92—133号为乳化煤油相关数据,134—160号为煤油油膜相关数据。
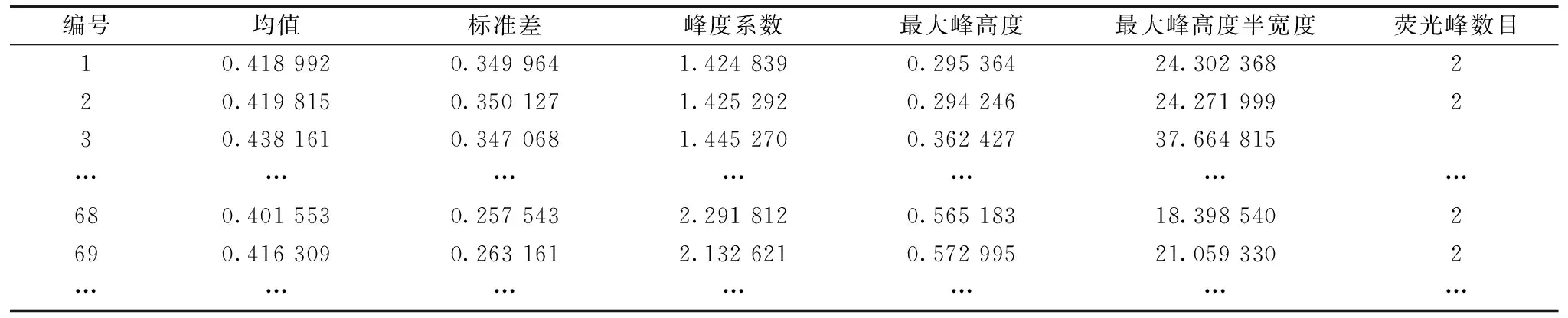
表1 特征参数表Table 1 Characteristic parameter table
接下来利用SPSS软件的系统聚类,将均值、 标准差、 峰度系数、 最大峰高度、 荧光峰数、 最大峰高度半宽度几个参数作为输入参量,对柴油数据和煤油数据分别进行分类,实现数据空间到对象空间的转换。 结果如图4和图5所示。
图4横轴为不同的柴油数据(91组),纵轴为类别相对距离,从上往下的竖线代表不同相对距离下柴油状态的类别。
图5横轴代表不同的煤油数据(69组),纵轴为类别相对距离,从上往下的竖线代表不同相对距离下煤油状态的类别。
根据分类树状图的结果,如果二分类,为乳化与未乳化的区分; 如果四分类,为油包水、 多重、 水包油、 油膜四种状态的区分,区分具体结果如表2和表3所示。
通过表中结果的对照,可以看出,对于柴油和煤油,乳化与未乳化的分类,该方法与实际状态是完全一致的,即能完全识别乳化与未乳化; 划分四个类别时,多重状态有个别归为油包水或水包油,考虑原因为多重状态本身的界定并没有十分准确的一个油水比值,而实验数据是连续间隔选取的油水比,物质成分是十分相近的,所以出现多重状态里的个别划分不准,是允许存在的。 总的说来,该方法可以很好实现对溢油不同状态的划分。
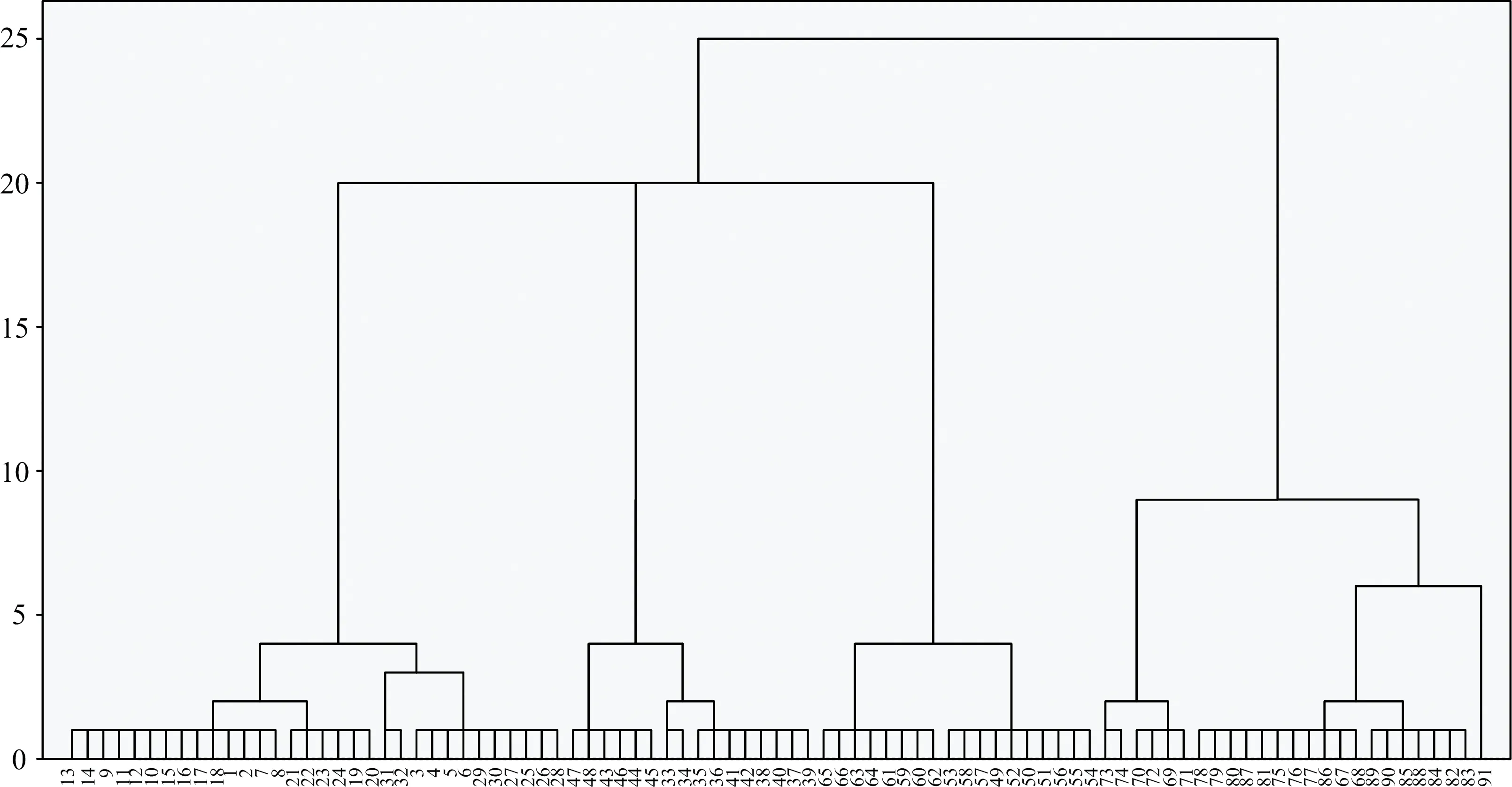
图4 柴油状态分类树状图Fig.4 Tree diagram of diesel status classification

表2 二分类结果对照表Table 2 Comparison table of two classification results

表3 四分类结果对照表Table 3 Comparison table of four classification results
3 结 论
荧光光谱的形状取决于物质的分子结构,基于此,论文从光谱形状的不同出发,利用统计特征和波形特征,找到描述乳化与未乳化,以及不同类型乳化的光谱不同形状的数据化参量,并使用聚类分析的方法,最终实现已知油种前提下的海面溢油不同状态的区分和识别。 当前关于油种识别已见相关算法,后续可结合油种的识别方法,进行更深入全面的研究,以期实现不同油种不同溢油状态的识别。
