融合可验证随机函数和门限签名的拜占庭容错共识算法
2022-07-06任永旺段红军王振飞
任永旺,段红军 ,王振飞,王 飞
1(郑州大学 计算机与人工智能学院,郑州 450001) 2(郑州艺术幼儿师范学校,郑州 450000)
1 引 言
2008年,Nakamoto在《比特币:一种点对点现金系统》中首次提到区块链的概念[1],区块链是一种利用共识机制来生成和更新数据、使用密码学技术来保证数据的唯一性、利用智能合约来保证合约顺利执行的一种安全的分布式基础架构和计算规范[2].其中共识机制是在缺乏中央控制和协调的分布式网络中为了达成共识所使用的规则,是区块链的底层核心技术,其决定了区块链的安全性、一致性、扩展性和交易速度,因此逐渐成为区块链的研究热点.
区块链根据开放程度不同,分为公有链、私有链和联盟链.公有链是完全开放的、去中心化的,任何节点都能参与到共识维护的分布式账本.由于完全开放的特性,大多数公有链采用如工作量证明(Proof of Work,PoW)、权益证明(Proof of Stake,PoS)等“Proof of X”类型的共识机制[3,4],还有一些使用混合“Proof of X”类型的共识机制,如授权股份证明(Delegated Proof of Stake,DPoS)[5,6].PoW是各个节点通过求解一个复杂但容易验证的数学难题,最快解决该难题的节点获得记账权,从而获得一定数量的虚拟货币作为奖励的共识机制[7].目前如比特币、以太坊、狗狗币等都使用该机制来达成共识.该机制以“算力为王”,但是共识过程中存在高耗能、高交易延迟、低吞吐量等缺点.PoS由系统中最高权益的节点获得记账权,其权益通过节点持有特定货币的数量和时间来确定[8].如未来币就是使用该共识机制,机制以“权益为王”,在一定程度上解决了PoW中的高耗能的问题,但是由于所有节点都参与竞争,所以对吞吐量要求高,会出现“富者越富、贫者越贫”的现象.DPoS是在PoS的基础上发展而来,货币持有者选举“董事会”成员,“董事会”内部按照一定的规则进行记账的共识机制.机制采用“民主集中式”共识,能够实现秒级验证,但是却弱化了去中心化.公有链由于完全去中心化的特性,导致其在监管性和隐私保护性等方面存在天然不足,因此不适用于大规模商业应用.私有链是完全封闭的、中心化的,用于企业内部的数据共享,它记录企业内部的交易信息,记账权限不公开,能够有效防止机构内部单点故障、隐瞒或者篡改数据.由于私有链的完全封闭的特性,其不适用于大型的商业活动.联盟链是半封闭的,半去中心化的,节点通过授权加入联盟网络,参与者组成利益联盟,并由联盟间共同维护的分布式账本.拥有权限可控、部分去中心化、交易速度快和可扩展等优势.联盟链所在的半封闭式网络,存在着节点的信任不对等问题,为了安全性、可用性等方面考虑,联盟链使用可容忍存在部分拜占庭节点的拜占庭容错算法来达成共识.
上述的3种区块链,公有链由于高度开放,使用户隐私无法保证、相关部门无法进行有效监督,且存在吞吐量不足、能源浪费等问题,使其不适用于大规模的商业应用;私有链由于其封闭性,仅仅适用于测试和企业内部,无法满足多个企业间大规模的商业应用;联盟链由于其半封闭、授权加入、交易速度快等特性,使其存在易于监督、权限可控等优势,相比于公有链和私有链,更适用于大规模商业运用.而且联盟链在分布式共识过程中,考虑到网络节点间存在着信任不对等,采用拜占庭容错算法来达成共识,更加符合现实中的网络环境.
2 相关工作
拜占庭容错算法(Byzantine Fault Tolerance,BFT)是应用复制技术解决分布式系统中拜占庭错误的通用方案,时间复杂度是指数级的[9].其中,拜占庭错误是敌手节点恶意错发或者补发消息造成的错误,其中的恶意节点被称为拜占庭节点.1999年Castro与Liskov提出实用拜占庭容错算法(Practical Byzantine Fault Tolerant,PBFT)[10],算法采用预准备(Pre-prepare)、准备(Prepare)和提交(Commit)3阶段协议,来保证副本间的状态复制.在Prepare阶段和Commit阶段,节点间采用两两交互的方式保证副本状态机的一致,如果总节点数为3f+1,则每次交互都至少需要2f+1个副本节点收集2f+1个投票才能满足系统一致性需求,在这两个阶段的交互过程中,PBFT的通信复杂度为O(n2).PBFT把BFT达成共识的难度由指数级降低到多项式级别,因此在联盟链中得到广泛应用.由于网络传输的不可靠性和网络关系的复杂性,PBFT在数据交换过程中,很容易造成网络拥堵,降低共识效率.之后一系列改进的拜占庭容错方案被提出.Zyzzyva采用投机技术避免执行三阶段提交[11],由客户端和副本直接进行交互,并且由客户端决定是否达成共识,但是这种投机行为导致错误恢复成本较高.拜占庭委托容错(Delegated Byzantine fault tolerance,DBFT)是一种改进的拜占庭容错算法[12],算法按照节点的信誉度(Trust)来选出记账节点,记账节点使用拜占庭容错算法来达成共识,由于算法采用代理记账节点,使得安全性降低,易造成事实上的中心.HoneyBadgerBFT采用分割交易来缓解主节点的带宽瓶颈[13],并结合随机交易块和门限加密来提升交易吞吐量,但是在网络节点较少的情况下(如8个节点),性能低于PBFT.文献[14]引入门限签名来降低通信复杂度,但是其主节点身份是暴露的,不能抵抗自适应攻击.此外,运用PBFT和“Proof of X”等机制相结合的混合共识算法相继被提出[15,16],如Tendermint、ByzCoin等.这些混合共识算法运用公有链的共识机制来选取一定数量节点组成委员会,并在委员会内部运用PBFT算法来达成共识.
综上所述,对于BFT算法的当前研究方向主要是降低通信复杂度、改变主节点的选取方式和提高吞吐量.然而大部分的方案都使用固定排序的主节点,每一轮主节点的身份都在排序完成后就确定了,然后根据排序依次来提交提案,这些提前暴露主节点的方案很容易受到敌手的分布式拒绝服务攻击(Distributed Denial of Service,DDoS)[17],导致主节点无法正常提案,从而影响系统活性.为了抵抗DDoS攻击,Micali提出了Algorand共识机制[18],采用BA★算法来达成共识,BA★算法的每一轮的提案者和每一步的验证者都是随机产生的,从而使该算法能够抵挡DDoS攻击.其中提案者就是下文所说的主节点(Leader),验证者就是下文所说的备份节点(BackUp).然而此算法的停止时间不固定,且由于每一步都重新选举验证者,使得系统负担增加.文献[19]提出一种健壮拜占庭容错共识算法(Robust Byzantine Fault Tolerance,RBFT),其通过环形签名来匿名选取提案者,并通过门限签名来达成共识,该方案提出的匿名提案者能够抵抗DDoS攻击,并且门限签名降低了达成共识过程中的网络负担.
针对大部分拜占庭容错算法难以抵抗自适应攻击、扩展性不足等问题,本文以区块链在高校学生信息存储中的应用为假设背景,提出一种融合可验证随机函数和门限签名方法的拜占庭容错共识算法(VRF_TS_BFT).算法首先利用VRF来对下一任候选主节点进行提案,运用VRF的随机性和零知识证明来达到隐藏主节点身份的目的;然后运用能够代表指定数量节点意愿的门限签名机制进行投票,选举出主节点和达成共识,从而减轻主节点选取和达成共识过程中的网络压力.分析表明,本文所提方案能够在系统减少开销的同时,提升系统的鲁棒性、可扩展性和抗DDoS攻击的能力,为BFT系统在高校学生信息存储和管理系统中的应用提供高可用性的支持.
3 成果论述
3.1 系统模型
VRF_TS_BFT共识算法能够像PBFT共识算法一样,契合联盟链的应用场景,在联盟链中维护全网一致的分布式账本.如图1所示,在高校基于联盟链进行学生信息存储和管理的应用场景中,分布在不同地理位置的记账节点(监督部门A、高校B、高校C、高校D、教育局E和劳务部门F)通过以太网连接在一起,每个节点在加入联盟时都已获得联盟链网络的授权,所有节点共同组成高校联盟,联盟成员间通过VRF_TS_BFT算法来维护全网一致的分布式账本.

图1 联盟链应用场景Fig.1 Alliance chain application scenario
VRF_TS_BFT算法共分为基于可验证随机函数的随机选主算法和基于门限签名的拜占庭容错共识算法两部分.本文提出的共识算法是针对高校学生信息存储和管理的,参与的各节点都是各高校、政府监督部门和教育相关职能部门,在以高校自身信誉为背景的前提下,由监督方和各职能部门通过选举指定一些高校节点作为潜在提案者(Potential Proposer,PP),潜在提案者负责收集交易信息.然后VRF_TS_BFT算法通过可验证随机函数在潜在提案者中随机选择一些节点作为候选主节点(Candidate Leader,CL),PP通过门限签名依据一定的规则对CL进行投票,从CL中选取一个节点作为主节点(Primary).主节点负责把收集到的交易数据打包成区块和发起新一轮的提案,主节点在提案发出之后,自动退化为备份节点(BackUp).然后,备份节点根据门限签名机制来对提案进行投票,任一BackUp收集到的投票数达到了门限值,则根据投票信息合成门限签名并广播该门限签名信息,共识达成.
图2为VRF_TS_BFT的算法示意图,算法分为Pre-prepare、Prepare和Commit 3个阶段.为了更好的表示,在图中设定Primary0为主节点,BackUp3为无法正常通信的节点,其他节点为能够正常通信的BackUp节点.客户首先在请求阶段(Request)把交易请求发送给主节点.在Pre-prepare阶段,Primary依据一定的规则,把客户的交易信息组装成区块B,并把该区块B、主节点投票信息和主节点验证信息组装成PRE_PREPARE消息,然后把该消息广播给所有的BackUp节点,消息发送完成后Primary自动退化为BackUp节点.在Prepare阶段,BackUp节点收到主节点发来的信息,首先验证该信息是不是主节点所发,如果是再验证区块的合法性,如果区块合法,则用部分门限签名合成自己的投票信息,再把投票信息和签名信息等合成PREPARE消息,并广播PREPARE消息,与此同时收集其他BackUp的投票信息,如果某个BackUp收集到足够的投票信息,如图2中的BackUp2,则根据投票信息合成门限签名(ThresholdSig).在Commit阶段,然后把门限签名信息合成COMMIT消息,并广播COMMIT信息.其他节点收到该COMMIT消息,只需验证门限签名的正确性,如果通过,就不再需要收集其它节点的发送的对该区块的投票信息,直接认定区块合法,把区块加入到自己维护的区块链中,并把共识达成的消息发送出去,共识完成.

图2 VRF_TS_BFT算法示意图Fig.2 Schematic diagram of VRF_TS_BFT algorithm
本文算法在Commit阶段,根据门限签名的易验证性,弱化PBFT中的Commit阶段的信息交换频率和数据包的大小.在Commit阶段,任意一个节点如果收集到满足门限值的部分门限签名信息,可以合成门限签名,并把确认信息发送给其他节点.其它节点只需通过门限签名就能确认达成共识,从而减少主节点的网络负担和BackUp的签名验证的次数.分析表明,本方案在减少系统和网络开销的同时,保障系统的活性和安全性,增加共识过程的鲁棒性,为高可用拜占庭系统提供支持.
3.2 相关假设和定义

假设2.在联盟链中,由于存在一定数量的拜占庭节点,且节点之间通过异步网络进行连接,如果系统中的Primary发布虚假消息或者临时崩溃时,为了保证系统的活性,在一定延时MaxDelay内如果不能达成共识,防止副本节点无限期地等待接收请求去执行,PP启动视图转换.其中PP等待时间delay=CurrentT-StartT,每轮共识结束,PP节点都会启动一个计时器,StartT表示计时器启动时间,CurrentT表示当前计时器时间,当PP等待时间delay的值超过MaxDelay的话,则会启动视图转换协议.
定义1.备份节点.备份节点(BackUp)参与共识的三阶段流程,并把达成共识的区块数据保存到本地区块链中,共识节点根据职责不同,有4种不同的叫法:普通备份节点、PP、CL和Leader,其中普通备份节点下面统称为备份节点或者BackUp节点;PP是一些指定的负责收集交易信息,可以通过选举成为主节点的BackUp节点;CL是PP通过VRF发现自己是主节点候选人的时候的称呼,是PP到Primary的一个过渡阶段;Primary是一种特殊的BackUp节点,是由PP转换而来,Primary负责打包区块并对打包区块进行提案,发布完消息后,Primary退化为BackUp节点.BackUp负责对提案进行投票,以确定是否达成共识,并可以转发满足门限签名条件的确认信息.
定义2.签名.签名分为部分门限签名,门限签名和节点签名3种.其中部分门限签名(PartSig),是各BackUp节点根据保存的部分门限签名的私钥对消息进行签名,该签名表示对消息进行投票,如
定义3.消息.副本之间通过预准备消息(PRE_PREPARE),准备消息(PREPARE)和确认消息(COMMIT)来达成共识.
预准备消息(PRE_PREPARE)指Primary用于发布提案的消息,具体格式为
准备消息(PREPARE)除主节点外的所有备份节点对该PRE_PREPARE消息进行投票,其具体格式为
确认消息(COMMIT)是对提案信息的投票结果进行确认,其具体格式为
3.3 可验证随机函数
可验证随机函数是Silvio Micali等人于1999提出的一类具有可验证功能的伪随机函数[20].对于一个输入Seed和私钥(Secret Key,SK),VRF会产生一组随机数r和r的证明proof,验证者可以通过公钥(Public Key,PK)、r、Seed和proof验证出r是否由PK的持有人根据Seed所产生的.VRF的流程如下:
1)使用者通过非对称加密算法生成一组公私钥对(PK,SK),其中PK为公钥,SK为私钥.
2)输入Seed和SK,VRF会生成一个r和一个可以实现对r进行零知识证明的proof,如公式(1)所示:
Seed+SK→r+proof
(1)
3)通过r和proof可以验证它们是否是一起产生的,如果是则为true.
VRFverify(r,proof)==true
(2)
否则为false.
4)通过输入Seed、PK和proof,可以验证该proof是不是PK的持有人根据Seed所产生的,如果是则为true.
PubVerify(proof,Seed,PK)==true
(3)
否则为false.
VRF具有可验证性、确定性和随机性:
1)可验证性:在只知道proof、Seed、PK和r的情况下,证明r是否为PK的持有者根据Seed所生成.
2)确定性:如果输入的Seed和SK相同,则得到的r一定是相同的.
3)随机性:在未给定proof的情况下,r和一个随机数对于敌手来说是不可区分的.
3.4 门限签名
(t,n)门限签名(Threshold Signature,TS)是指由n名成员组成一个签名群体[21],该群体有一对群体签名公钥和私钥,群体的签名私钥被n个成员以门限的方式共享,只有群体内大于等于门限值t个诚实的成员才能代表群体用群体签名私钥进行签名,且任何人都很容易通过群体公钥来验证签名.门限签名的这些特性,使其可以用于BFT共识过程中,以减少共识过程中的网络负担.本文所用门限签名的流程如下所示:
1)公钥和群成员私钥的生成:输入安全参数s,门限值t和成员数N,返回每个成员部分签名所用的私钥PartSigSKi(i=1,2,…,N),私钥每个成员保存一个,用于生成部分门限签名,PK用于验证门限签名,如公式(4)所示:
s+t+N→PK+L
(4)
其中(L={PartSig1,PartSig2,… ,PartSigN}).
2)生成部分门限签名:输入消息msg以及成员私钥PartSigSKi,产生部分签名PartSigi,如公式(5)所示:
msg+PartSigSKi→PartSigi
(5)
3)合成门限签名:如果某个成员收集到的有效部分签名PartSigi达到门限值t,则可以用这些PartSigi合成门限签名ThresholdSig.
4)验证门限签名:输入消息msg、公钥PK和门限签名ThresholdSig,返回判断结果true和false,其中true表示验证通过,false表示未通过验证,如公式(6)所示:
verify(msd,PK,ThresholdSig)→trueorfalse
(6)
4 改进的拜占庭容错共识算法
4.1 基于可验证随机函数的主节点选举和视图转换
主节点选举是从PP节点中根据主节点选举规则选举出发起下一轮提案的主节点.基于可验证随机函数的Leader的选举过程如下,一个PP节点,在接收到当前主节点发送的PRE_PREPARE息后,根据里面的信息算出seednext来确定自己是不是下一轮次的主节点的候选人.确定一个PP节点是不是候选主节点的具体过程如下:
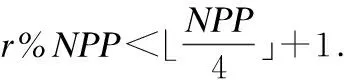
视图转换协议的目的是为了防止BackUp节点无限制的等待接收执行消息,保证共识机制的活性,主动更换Leader.在如下所示的3种条件下会触发视图转换:
1)系统中Primary节点为拜占庭节点发布虚假信息;
2)系统中Primary节点的崩溃而无法进行正常提案;
3)当BackUp等待接收执行消息超过一定时限.
在本文算法中,由于每一轮提案结束后,主节点退化为BackUp节点,而且每轮只选举出唯一一个主节点,所以当一轮共识达成,开启下一轮共识的时候,会进行主节点选举和视图转换,也就是说主节点选举和视图转换是融合在一起同时完成的.而且为了减少主节点选举和视图转换过程中的网络压力,主节点选举和视图转换过程都只需潜在提案者PP进行参与,然后转换成功后把新一轮视图转换和Leader选举成功的消息广播给所有BackUp节点.
如果当前协议达成或者等待超时,且提案者PP通过计算确定自己有可能成为下一轮的Leader,则立刻启动视图转换,视图转换协议的具体过程如算法流程1所示.
算法1.基于可验证随机函数的主节点选举和视图转换
输入:视图转换消息
输出:新的主节点和全局一致的新的视图信息
1. IFBackUpis notPPTHEN
2. RETURN
3. WHILE true THEN
4. IFVerify(COMMIT)is OK ||PPiis TIMEOUT THEN
5. IFverify(isProtentialLeader)THEN
6. BroadCastVIEW_CHANGE
7. IF(TIMEOUT)THEN
8.minMSGis the minimalVIEW_CHANGE
9. IFminMSG== null THEN
10.num++
11. continue
12. ELSE THEN
13. GenerateVOTE_MSG
14. BroadCaseVOTE_MSG
15.voteMSGs(incomingSig.iterator()
16.counts←{}
17. WHILE true THEN
18.vmsg←voteMSGs.next()
19. IF((vmsg.ThresholdSigis existence)&&verfiy(vmsg.ThresholdSig))THEN
20. IF is Primary THEN
21. BroadCastNEW_VIEWk
22. RETURN
23. ELSE IFverify(vmsg.PartSig)THEN
24. ++counts[CLk]
25. IF(counts[CLk]>=t)THEN
26. GenerateThresholdSig
27. IF is not Primary THEN
28. SendThresholdSigtoPrimary
29. ELSE THEN
30. BroadCastNEW_VIEWk
31. RETURN
32. ELSE THEN
33. BroadCastNEW_BLOCKk
主节点选举和视图转换的流程:
1)如果等待时间耗尽或者上一个区块已经达成共识,且PPi是CL,则启动视图转换协议.首先让视图编号加1,然后发送视图转换消息VIEW_CHANGEi.VIEW_CHANGEi是指PPi发送的视图转换消息,其具体内容是
2)在一定时间内,所有PP节点收集其他PP节点发送过来的视图转换消息.时间到后,根据查找主节点的方法,找到自己认为的主节点信息,然后对其进行投票.minMSG如果为null,表示本轮没有产生CL,num++之后,根据VRF产生的随机值,继续查找CL;如果minMSG不为空,则对下一任Leader进行投票,发出投票信息VOTE_MSG.VOTE_MSG的具体内容为
3)PP接收投票信息,对投票信息进行如下3种判断:
① 如果下一任Leader收到的投票信息中含有合法的对新视图投票的ThresholdSig,则认为当前视图转换完成,并其广播视图转换完成的消息NEW_VIEWk给所有的BackUp节点,表示视图转换完成.PP收到视图转换完成的消息后不再接收其他视图转换的消息.
② 如果投票信息中,只包含对潜在新Leader的投票,则对投票数量进行统计,当某个PP接收到的投票数量达到门限值,并成功合成门限签名后ThresholdSig,则认为已经选出了下一轮的Leader.如果ThresholdSig就是下一任Leader自身合成的,则直接广播NEW_VIEWk消息,表示视图转换完成;如果不是下一任Leader合成的,这把门限签名信息,发送给下一任Leader.
③ 如果PP收到的消息既不包含合法的ThresholdSig,也不包含对新视图的投票信息,则选择广播新的提案消息NEW_BLOCKk给所有BackUp节点,新提案的具体内容为
如果BackUp节点收到NEW_VIEW消息,则认为主节点和视图转换已经完成;如果BackUp节点收到NEW_BLOCK消息,则对其中包含的新提案blocknew进行投票,其具体过程与基于门限签名的拜占庭容错共识算法的流程保持一致.
4.2 基于门限签名的拜占庭容错共识算法
在PBFT的Prepare阶段和Commit阶段,都需要所有BackUp节点间进行信息交换,但是由于各个BackUp所在的地理位置的分散性以及网络传输的不可靠行,大量的数据交换容易造成网络拥堵,从而导致节点间难以达成共识.本文通过引入门限签名机制,在Commit阶段,当任一节点收集到的合法签名人数到达门限值t的时候,就可以合成门限签名并广播该门限签名,其他尚未合成门限签名的人,只需验证一条合法的门限签名,就停止接收该区块的投票信息,并确认区块得到验证.这样就降低了Commit阶段达成共识所需要的条件,减少了Commit阶段的验证次数,使得Commit阶段在不稳定网络环境中达成共识的成功率更高.具体过程如算法流程2所示.
算法2.基于门限签名的拜占庭容错共识算法.
输入:交易信息
输出:全局一致账本
1.StartT←Time()
2. IF(Leader)THEN
3. Prepareblock
4. IFTime()-StartT 5. GeneratePRE_PREPARE 6. BroadCastPRE_PREPARE 7. ELSE THEN 8. RETURN TIMEOUT 9. ELSE THEN 10. ReceivedPRE_PREPARE 11. IF(Verify(PRE_PREPARE)&&Time()-StartT 12. GeneratePREPARE 13. BroadCastPREPARE 14. ELSE THEN 15. RETURN TIMEOUT 16.partSigMsgs←incomingPartSig.iterator 17.thresholdSigMsgs←incomingThresholdSig.iterator 18.counts←{} 19. WHILE true THEN 20. IF(time()-StartT>=MaxDelay)THEN 21. RETURN TIMEOUT 22.ThresholdSig←thresholdSigMsgs.next() 23. IF(verfy(ThresholdSig)==true)THEN 24. Committedblockon the local blockchain 25. BroadCastCOMMIT 26. RETURN 27.PartSig←partSigMsgs.next() 28. IF(verify(PartSig)==false)THEN 29. CONTINUE 30. ELSE THEN 31. ++counts[block] 32. IF(count[block] >=t&&Time()-StartT 33.GenerateCOMMIT 34.BroadCastCOMMIT 35. Committedblockon the local blockchain 36. RETURN 把每一轮的开始时间记录到开始时间StartT,VRF_TS_BFT的算法流程如下: 1)如果节点是Leader的话,则把交易信息打包到区块block,然后把block、投票信息、签名信息等打包成PRE_PREPARE消息,如果未超时间限制,则把PRE_PREPARE广播给其他BackUp节点. 2)如果不是Leader,则等待接收Leader发送来的PRE_PREPARE消息,收到该消息后,对消息进行验证,如果验证通过,则广播含有自身投票信息的PREPARE消息,对区块进行投票. 3)所有BackUp节点都收集别的BackUp节点发送的PREPARE消息和含有门限签名ThresholdSig的COMMIT消息.如果收到门限签名,并通过verfy(thresholdSig)验证,则提交该区块进入本地维护的账本,本区块的验证结束,并把COMMIT消息广播出去,后续不再接收该区块的投票信息和门限签名消息. 4)在未收到某个区块的ThresholdSig之前,收集到的PREPARE中的部分门限签名消息超过门限值t的话,则合成门限签名ThresholdSig,并广播含有门限签名的COMMIT消息,同时把区块信息添加到本地区块链,本区块的验证结束,此后不再接收该区块的投票信息和门限签名信息. 系统安全性是指所有的诚实副本都按照一致次序处理请求,每次达成共识需要系统中大多数诚实节点做出一致承诺. 在同一区块高度h,两个不同的Leader节点发出的不同的区块信息,如果这两个区块都达成共识,则会在高度h上出现一个临时性的分叉.假设系统中在高度h上有两个不同的块block1和block2同时达成共识,则block1为达到门限值所获得的由部分门限签名构成的投票数t1≥2f+1,block2对应的投票数t2≥2f+1,两式相加可得t1+t2≥4f+2.由于副本数共有3f+1个,假定副本中拜占庭节点数为最大值f,则诚实节点数为2f+1,因为诚实节点对区块链上同一个高度的区块只能投票一次,所以诚实节点只能对block1或者block2其中之一进行投票,也就是在高度h诚实节点的票数最多为2f+1票,因为N-f=2f+1.如果所有的拜占庭节点间已经组成了联盟,由于拜占庭节点可以作弊,所以假设所有拜占庭节点都分别对block1和block2进行了投票,这时候对block1和block2的投票中,拜占庭节点投票数最多是2f票.因为拜占庭节点投票数最多为2f票,诚实节点投票数最多是2f+1票,所以t1和t2总票数最大值为4f+1,即max(t1+t2)=2f+(2f+1)=4f+1.把t1+t2=4f+1带入t1+t2≥4f+2可得4f+1≥4f+2,解该不等式得1>2,出现矛盾.所以系统在高度h上不可能有两个不同的块block1和block2同时达成共识. 系统活性是指请求最终能够被诚实节点正确执行,本文VRF_TS_BFT共识算法能够在提案过程中始终保持系统活性. 5.3.1 基于可验证随机函数的选主算法系统活性 采用固定顺序轮流选主的方式是当前主流的选主方式,在备份节点成为主节点的顺序固定的情况下,主节点很容易遭受敌手的DDoS攻击,破坏系统活性.本文基于VRF的随机选主算法,所有潜在提案者,在选主之前,都不知道其他节点是否为候选主节点,主节点也不能提前知道哪个备份节点将成为候选主节点,成为候选主节点的过程完全随机.在投票阶段,根据可验证随机函数的可验证性,所有节点都可以很容易的验证某个节点是否为候选主节点,然后根据主节点选举算法,选举出下一轮的主节点.基于可验证随机函数的选主过程,由于其随机性和零知识证明的特性,可以有效的防止DDoS攻击,保证系统的活性. 5.3.2 基于视图转换的活性 VRF_TS_BFT算法候选主节点CL会根据超时机制或在协议成功达成共识时触发视图转换来保证系统活性.当触发视图转换协议时,CL节点会自动广播视图转换消息VIEW_CHANGE;然后所有PP节点都发送VOTE_MSG对CL进行投票,并依据门限签名选出下一任主节点.任一PP节点根据部分门限签名PartSig成功合成ThresholdSig,都会将门限签名信息发送给下一任主节点.下一任主节点在收到或合成ThresholdSig后,都会就会向所有BackUp节点广播NEW_VIEW消息宣告视图转换成功. 视图转换的消息在CL节点等待超时或上一轮共识已经达成共识时提出,新视图生成的消息可有任一成功合成门限消息的PP节点生成并发送给当选主节点的PP节点,由主节点宣布视图转换完成.由于CL产生的随机性,可以防止敌手在视图转换中发起的DDoS攻击. 综上所述,VRF_TS_BFT能够在选主过程和视图轮换过程中保证系统的活性. 系统的可用性是指系统在面对网络异常时可以正确提供服务的能力.由于联盟链中节点众多、各节点间位置分散和网络连接状态不确定等问题,本文所提出的VRF_TS_BFT能够保证只要任一节点能够根据部分门限签名PartSig合成门限签名ThresholdSig,并把该ThresholdSig传递出去,则系统状态就能达成一致.其在最小信息交换的情况下,达成共识的流程如图2中的带箭头的实线所示,图中Request阶段主节点Primary接收客户端发送的交易信息. 1)Pre-prepare阶段Primary把交易信息打包成PRE_PREPARE消息并把该信息广播给其他备份节点; 2)Prepare阶段,所有BackUp节点对收到的PRE_PREPARE中的区块信息进行投票,假设由于网络波动,只有BackUp2集齐了超过门限值t的部分门限签名,其就能根据PartSig合成门限签名ThresholdSig; 3)Commit阶段,BackUp2把确认信息广播给所有BackUp节点,其他BackUp节点收到BackUp2发送的确认消息,只要门限签名验证通过,就能认定该提案区块达成了一致性共识,然后把共识达成的消息广播出去.当至少有f+1个节点成功达成一致性共识,则认定协议完成. 从概率角度对系统可用性进行分析,假设每个BackUp网络完全独立且在有限时间范围内收到法定人数投票的概率为p,则n个BackUp节点组成的共识算法网络中,k个BackUp节点收到法定投票人数的概率服从二项分布,其概率如公式(7)所示: (7) 在PBFT中,因为Prepare阶段和Commit阶段这两个阶段,每个节点都至少要收到2f+1个确认信息才能保证提案得到通过,这两个阶段中,每个阶段提案成功的概率如公式(8)所示: (8) 在VRF_TS_BFT中,需要Prepare阶段有任一诚实节点收集够2f+1个确认信息就能够保证提案通过,因此为了保证存在一个诚实节点能够传达共识结果,至少需要f+1个共识单元.VRF_TS_BFT算法提案成功的概率公式(9)所示: (9) 图3中(a),(b),(c),(d),(e),(f)分别表示n取7,16,22,28,46,61时无拜占庭节点的情况下PBFT和VRF_TS_BFT成功提案的概率分布对比图,PBFT在不同节点下的成功提案的概率分布图为图3(g),VRF_TS_BFT在不同节点下的成功提案的概率分布图为图3(h),其中横轴为每个副本节点在有效时间内收到法定人数投票的概率,纵轴为成功提案的概率.从图3中可以看出,随着法定人数投票成功的概率P的增加提案成功概率呈现上升趋势,且VRF_TS_BFT比PBFT上升的快;同等投票成功的概率P的情况下,VRF_TS_BFT算法大于等于PBFT算法提案成功的概率,且VRF_TS_BFT比PBFT提案成功的概率更快的趋近于1.对比PBFT和VRF_TS_BFT在不同节点数下的成功提案概率分布图,可以看出,PBFT在P≥0.8时候,提案成功的概率才趋近于1,而VRF_TS_BFT在P≥0.6的时候,成功提案的概率就已经趋近于1;PBFT在P<0.6时,提案成功的概率可以忽略不计,而VRF_TS_BFT在P≥0.4时,提案成功的概率大于60%.通过对比可知,在相同投票成功的概率的情况下,VRF_TS_BFT 图3 状态一致性概率曲线Fig.3 State consistency probability curve 提案成功的概率更高;在相同提案成功率的情况下,VRF_TS_BFT对投票成功的概率要求更低.可见在相同的环境下,VRF_TS_BFT对投票成功的概率要求没有PBFT的高,且在同等投票成功率的情况下,VRF_TS_BFT更容易达成共识,所以相较于PBFT,VRF_TS_BFT的鲁棒性更强. P{X=NPP}=(1-p)NPP (10) 图4表示在不同个PP节点的情况下,1次到4次内能够成功找到候选主节点的概率,从图中可以看出:当只有4个PP节点的时候,一次能找到候选主节点的概率最低,约为94%,两次能找到候选主节点的概率就约等于100%了;当有10个主节点的情况下,一次找到候选主节点的概率约为99%,两次的概率接近100%;而且随着PP节点数的增加,一次能找到CL的概率就会越来越高,当节点数超过16的时候,一次成功的概率就接近100%.由此可以看出,在做Leader选举和视图转换的时候,本文提出的方法,在一个时间段内,能够确保主节点选举和视图转换成功. 图4 存在候选主节点的概率Fig.4 Probability of candidate master nodes 为了测试PBFT和VRF_TS_BFT在不同网络环境中的吞吐量,以此来比较这两种算法的优劣.使用GoLang语言,分别模拟PBFT和VRF_TS_BFT实现过程.实验采用4核的Intel Core i5处理器(8个逻辑内核),8G内存的硬件平台,采用GoLang语言中的多进程和多线程模拟1个客户端和7个BackUp节点的拓扑网络,VRF_TS_BFT所用的门限签名是根据shamir秘密共享方案改进而来[22],PBFT和VRF_TS_BFT的拓扑结构如图5所示,其中每次试验客户端发送100组交易数据给指定的主节点Primary0.在节点间达成共识的过程中,为了模拟网络延时,在Pre_prepare阶段和Prepare阶段每个节点发送数据的时候,都会随机延时1-5ms的时间,同时为了模拟网络丢包现象,使用随机数,按设定的百分比使得数据传输失败;如果在400ms内共识没有达成,共识失败,启动视图轮换,开始重新发送数据. 图5 网络拓扑图Fig.5 Network topology 实验结果和实验数据如图6和表1所示,图6是对表1的数据的图形化展示.在图6中,每个子图都对应表1中PBFT和VRF_TS_BFT相同宕机节点数的数据,如图6(b)对应了表一中宕机节点数为1的PBFT和VRF_TS_BFT的数据;X轴表示数据发送成功率(%);Y轴表示时间(s);Z轴表示成功数.在图6的图标中:PTSR表示PBFT数据传输成功率,如PTSR 100%表示数据传输成功率为100%;VTSR表示VRF_TS_BFT数据传输成功率,如VTSR 80%表示数据传输成功率为80%.图6(a)中7个BackUp节点都可以正常工作,对应于表1中的宕机节点数为0的数据;图6(b)中7个BackUp节点有一个节点宕机,对应于表1中的宕机节点数为1的数据;图6(c)中7个BackUp节点有两个节点宕机,对应于表1中的宕机节点数为2的数据;图6(d)为3种数据混合显示.从图6(a)可以看出,在所有BackUp都正常工作的情况下,VRF_TS_BFT在VTSR 70%的情况下,达成共识的概率是100%,而PBFT对数据传输成功率就特别敏感,在PTSR 70%的情况时,达成共识的概率只有55%左右.从图6(b)可以看出,在一个BackUp节点宕机的情况下,VRF_TS_BFT在VTSR 70%的情况下,达成共识的概率接近100%,而PBFT在PTSR 90%的情况下,达成共识的概率约为85%.图6(c)中当节点宕机数达到最大值,此时,双方虽然对数据传输成功率表现都很敏感,但是VRF_TS_BFT在各方面表现都比PBFT好,VRF_TS_BFT在VTSR 80%的情况下,达成共识的概率也为95%,而PBFT在PTSR 90%的情况下,达成共识的概率只有10%左右.通过实验数据可以看出,在相同数据传输成功率的前提下,VRF_TS_BFT表现出更强的鲁棒性.而且在达成共识的时候,能够更快的转入下一区块的生成,不需要等待时间超时,更换视图重新提出提案,所以,在处理同等数量的提案,VRF_TS_BFT所用时间往往会比PBFT更少.也就是说,通过实验数据表明,在相同条件下,相比PBFT,本文VRF_TS_BFT速度更快、鲁棒性更强. 图6 不稳定环境下节点达成共识数据对比Fig.6 Comparison of consensus data between nodes in unstable environment 表1 不稳定环境下节点达成共识数据对比Table 1 Comparison of consensus data between nodes in unstable environment 本文针对拜占庭容错算法难以抵抗DDoS攻击、共识速度慢、鲁棒性差等问题,利用可验证随机函数的随机性和零知识证明特性,以及门限签名只有达到门限值才能达成共识的特性,设计一种可用于联盟链的改进拜占庭容错共识算法VRF_TS_BFT.算法能够随机选取候选主节点,使主节点选举过程避免遭遇敌手DDoS攻击;同时,利用门限签名可以增强对不稳定网络的适应能力,提高在极端网络环境下达成共识的概率.分析表明,本方案能够在提升达成共识速度的同时,提升达成共识的几率,具有更强的鲁棒性.5 实验分析验证
5.1 系统安全性证明

5.2 不可临时分叉性证明
5.3 活性证明
5.4 可用性分析
5.5 概率学角度分析成功达成共识的概率

5.6 随机选主算法成功找到候选主节点的概率


5.7 比较PBFT和VRF_TS_BFT的吞吐量和成功率



6 结 论
