判别性信息增强的行人再识别
2022-07-06谢明鸿李华锋谭婷婷
周 炉,谢明鸿,李华锋,谭婷婷
1(昆明理工大学 信息工程与自动化学院,昆明 650500) 2(昆明理工大学 云南省人工智能重点实验室,昆明 650500)
1 引 言
行人再识别(Person Re-identification)致力于匹配由不同摄像机捕捉到的不同场景下的行人身份.由于其在视频监控、交通安全和公共安全等很多方面有着重要的应用,最近几年受到越来越多的关注.同时,由于姿态的差异、视角的变化和摄像头间成像风格不同等因素的影响,使得在不同相机视角下,相同行人的外貌特征存在着较大的差异,不同行人的外貌特征又表现出较强的相似性,这给行人身份的匹配带来了极大挑战.
为解决摄像头间行人成像风格的差异,有的方法常通过学习一个在不同摄像头下具有不变性的判别性特征来解决上述问题.这类方法主要包括KISSME[1]、DNS(Discriminative Null Space)[2],在深度学习领域有SPReID(Semantic Parsing Re-identification)[3]、VPM(Visibility-aware Part Model)[4]等.然而,不同相机视角之间存在的域偏移降低了这些方法所提取到特征的判别性.为此,基于相机风格迁移的方法CamStyle[5]、UnityStyle[6]受到了人们的关注.这类方法往往通过将不同相机视角下的行人图像迁移到其它视角下,从而实现训练数据的扩充与风格差异的缓解.然而,这类算法虽然弥补了不同相机风格之间的差异,但由于生成的图像质量不高,很难保证特征提取网络能从生成的图像中提取到丰富且具有判别性的行人特征.因此,这类仅从生成图像中提取行人的身份特征的方法,限制了特征判别性的提升.此外,简单的全局特征提取网络,往往仅能关注到行人图像的某一局部区域,这对获取较为完整的行人图像特征是不利的.
为提升特征的判别性,让特征提取网络能够关注到行人图像不同区域的判别特征是常用的一种手段.为达到这一目的,利用图像块分割的方法,单独对行人图像的某个局部区域进行身份约束,受到了研究者的关注,并提出了一些有效的方法,包括PCB(Part-based Convolutional Baseline)[7]、MGN(Multiple Granularity Network)[8]、EANet(Enhancing Alignment Network)[9]和LHF(Local Heterogeneous Features)[10]等.这些方法通常将行人的特征图分成不同的条带,并对不同的条带进行身份约束,来迫使网络能够关注到行人图像不同区域富有判别性的特征.这类方法虽然能够一定程度上关注到局部信息,提高全局特征的判别性,但是由于遮挡、视角等问题,单张图像所能提供的行人信息是有限的,甚至会引入部分噪音,所以得到的与身份相关的判别性特征的强度不够,不能进一步提升模型的识别性能.此外,这类算法并未考虑不同视角样本图像之间的域差异,对模型性能的进一步提升也带来了限制.
为解决上述问题,本文利用CamStyle,提出了一种基于相机风格迁移的行人图像特征提取的方法(如图1所示).该方法由辅助子网络、主干子网络以及时空信息嵌入3部分构成.在辅助子网络中实现不同视角行人图像的风格转换以减少风格差异对性能的影响.为了利用图像的局部信息增强特征的判别性,将通过主干子网络的原图特征和迁移图像特征进行拼接做相似性度量,促使网络提取分块图像的细节信息.最后,引入行人的时空信息来缓解难样本对识别性能造成的影响.具体而言,首先利用CamStyle将训练集中每个相机视角下的行人图像样本迁移到其它相机视角下,使迁移后的图像与被迁移图像保持着相同的身份.不同于传统方法[5,6],其直接利用迁移图像有监督地训练模型.本文将迁移后的图像特征进行融合拼接,使网络提取更加丰富的行人信息,缓解不同相机风格产生的域偏移.为提升特征的鉴别性,本文在主干子网络中利用PCB[7]的图像分割技术,把全局特征图分割成不同的条带,并对每个条带中的特征进行身份约束,从而强迫主干子网络在关注全局具有判别性区域的同时,更多地关注行人图像的局部细节信息,以此来进一步提升特征的判别性.在时空信息嵌入中,利用时间和空间的结合剔除视觉特征相似的难样本,从而提升模型性能.
总的来说,本文的主要贡献和核心工作主要体现在如下3个方面:
1)提出了一种跨视角行人再识别的鲁棒特征提取方法,该方法提出利用额外的网络分支来辅助主干子网络,使其具有辅助子网络所拥有的某种特定的能力.
2)为综合不同视角下的行人特征,缓解相机视角的不同导致的域差异,利用CamStyle的方法将单个视角下的行人图像迁移到其它视角下,并聚合不同视角下相同身份的特征向量,从而达到增强行人身份特征的目的.
3)为促进主干子网络能关注到行人图像的不同区域,提出利用PCB技术,将主干子网络获得特征图进行分割,每个分割后的条带在身份一致性约束下,提升了模型对行人局部特征的关注度.最后为排除难样本对识别性能的干扰,引入了时空信息,进一步提升了模型的性能.

图1 本文方法的整体技术框架Fig.1 Overall technical framework of the method in this paper
2 相关工作
行人再识别是一个被广泛研究的课题.近些年随着深度学习的兴起,特别是深度卷积神经网络[11-14]的发展,行人再识别被推上了一个新的台阶.现有的行人再识别的研究方法主要通过卷积神经网络来进行不同摄像头间行人风格迁移的生成,并利用卷积神经网络来提取行人的判别性特征,以此来解决由不同摄像头所造成的行人风格差异问题.同时也有方法将卷积神经网络所提取的特征图进行分块,并结合行人的时空信息来解决行人再识别的问题.
2.1 基于风格迁移的行人再识别
由于视角差异、光照变化、不同摄像机的成像风格不同等问题,行人再识别任务面临了极大的挑战.为了缓解风格差异导致的识别性能下降的问题,基于风格迁移的行人再识别引起了学者们的广泛关注.受循环一致性对抗网络(Cycle-consistent Generative Adversarial Networks,CycleGAN)[15]的启发,文献[5]提出了一种相机风格(CamStyle)迁移的方法.该方法首先利用 CycleGAN将已标记的源域图像迁移到目标域的每个相机风格下,并与原始训练样本一起组成增强训练集,然后利用有监督学习算法完成模型的训练.但是由于引起域差异的因素不止一种,只对风格进行简单的迁移并不能很好的解决域差异导致的识别性能下降的问题.文献[16]通过分析不同数据之间的差异,将数据间的差异细分为光照差异、摄像头角度差异和分辨率差异,并基于这3种差异提出了一种自适应的转换网络(Adaptive Transfer Network,ATN)进行图像的风格转换,用于跨域行人再识别.但是在风格迁移的过程中,往往会因为图像风格的改变而导致原图像所携带的行人身份信息的丢失,从而降低算法的识别性能.
为了解决上述问题,文献[17]和文献[18]都考虑了要保证生成图像的前景信息,即行人身份信息的完整和不变.文献[17]提出了行人转换的生成对抗式网络(Person Transfer Generative Adversarial Networks,PTGAN).该方法利用掩码生成网络来保证前景不变的情况下只将背景转换为期望数据集的风格,这极大地保护了具有判别性的行人身份信息,提高了算法的识别性能.但是该方法需要引入格外的掩码生成网络,增加了训练的复杂性.文献[18]为了缓解复杂背景对前景特征的影响,提出了一种背景转换的生成对抗网络,用来生成背景抑制的软掩模图像,从而保证不同域图像转换后的风格具有一致性,缓解风格差异对识别性能的影响.上述两种方法都需要掩模来保留具有判别性的前景图像,但是无论是利用已有的网络生成掩模或者直接训练网络生成背景抑制的掩模图像,都会存在生成掩模不准确的问题,从而导致前景信息丢失或者背景信息冗余的情况出现.
2.2 基于分块与时空信息的行人再识别
行人图像的局部区域提供了大量具有判别性的细节信息,因此许多新的基于分块的行人再识别方法被提出,用于进一步提高所学特征的鲁棒性.常见的方法主要分为两种.
第1种方法通过提取多尺度特征来解决身体局部非对齐的问题[8,19-21],通过从粗略分割的多尺度图像块中提取局部特征,同时联合不同尺度下的行人特征来提高所学特征的判别性.文献[8]通过区域分割得到不同粒度下的特征,然后对行人的整体信息和有区分度的多粒度细节信息进行融合.不同于简单的局部特征融合方法,文献[20]还建立了全局特征和局部特征以及局部特征之间的图关系,然后利用图卷积神经网络对多尺度特征进行了融合.但是不同图像中的行人位置、大小等都存在差异,直接进行粗略的分块会影响所学局部特征的判别性.局部检测的方法可以一定程度上缓解这个问题带来的缺陷.
另一种方法通过现有检测工具的辅助,对行人身体部位进行更为精确的局部检测[22-25].文献[22]利用DeeperCut[26]对行人关键点进行检测,然后根据关键点位置对身体部位所在区域作进一步估计.而文献[23]和文献[24]则是通过注意力网络直接对特征图进行局部区域的推断.检测工具或者注意力的引入能够更精确的捕捉局部区域,但是由于遮挡以及视角变化等问题,这类方法可能会引入噪音,阻碍局部信息的提取.
为了缓解单张图像所包含判别性信息的局限性,除了对单张图像空间上细节信息的关注,图像序列的时空信息被用作辅助信息也为行人再识别提供了一个新思路.现有的利用时空信息的方法可以分为两种:一种是直接利用图像序列中丰富的时空信息,提取更全面有效的行人特征进行最后的行人匹配[27,28];另外一种是将这些时空信息作为约束项对候选行人中不相关的行人进行筛选排除[29-31].文献[27]通过提取所有帧中的有用信息来对抗图像中的遮挡和不对齐的问题,并且通过空间注意力关注身体的不同部位.该方法能够使得网络自动地使用序列中最好帧中的面部、躯干等身体的局部信息.除了视觉特征的学习外,文献[31]建立了时空模式,通过时空信息判断不同摄像机捕获的目标是否为同一行人.视觉特征挖掘了每张图像上的判别性信息,而图像序列的时空信息能进一步帮助网络筛选行人身份,一定程度上排除错误的行人匹配.为了学习判别性特征并提高行人匹配的效率,本文的方法也结合了视觉特征和时空信息.
3 方法实现
如图1所示,提出的行人判别性信息增强的方法包含辅助子网络模块,主干子网络模块以及时空信息嵌入模块.其中,辅助子网络模块首先对不同相机视角下的行人图像进行风格迁移,再对迁移后的图像提取特征并进行拼接,从而增强特征的判别性,并一定程度上缓解了不同相机视角之间存在的域偏移.主干子网络引入PCB,并通过对局部特征的身份约束迫使网络关注到行人的局部判别性信息.时空信息嵌入模块结合行人图像的相机和视频帧信息进行统计建模,排除难样本的干扰,从而进一步提升识别率.接下来将详细介绍这3个模块,并对算法实现进行阐述.
3.1 辅助子网络模块

(f1,f2,…,fc)=E1(x1,x2,…,xc)
(1)
其中,E1是辅助子网络中的特征编码器.对每一个特征,利用交叉熵损失对其进行身份约束以保证特征的判别性,损失函数如公式(2)所示:
(2)
其中,K代表行人的数量,y是身份标签,1[·]是一个指示函数.为进一步增强特征中行人的判别性信息,将迁移后图像的特征进行拼接并进行全局平均池化操作,如公式(3)所示:
f′=GAP(Concat(f1,f2,…,fc))
(3)
同理,为保证拼接后特征的判别性,同样用身份标签来对其进行约束,有:
(4)
经过上述操作,一方面,提取的特征包含所有的相机风格信息,因此一定程度上能够缓解相机视角间的域偏移.另一方面,拼接后的特征能够增强特征中行人的判别性信息,因此具有更强的鲁棒性.
3.2 主干子网络模块
在这一模块中,设计了一个“教师-学生”网络以增强原始图像特征中的判别性.具体来说,将辅助子网络中的特征提取器E1视作教师流,同时在主干子网络模块中引入特征提取器E2作为学生流.首先,利用E2提取原始图像的全局特征,即:
f=E2(x)
(5)
该特征同样满足身份约束:
(6)
为迫使主干子网络也能提取到类似辅助子网络的特征,再对教师流网络中提取并拼接的特征和学生流网络中提取的特征进行一致性约束,损失函数如公式(7)所示:
(7)
其中,‖‖2表示2范数.此外,全局特征关注的是行人的整体结构,忽略了一些重要的局部细粒度信息,从而造成行人身份的误判.受PCB思想的启发,在主干子网络中,除了全局特征之外,还对提取到的特征图进行水平分块,并利用平均池化对每一块特征进行操作以得到局部特征.通过对局部特征进行身份约束就能够一定程度上保证主干子网络关注行人的局部信息,从而进一步提升全局特征的判别性.
(8)
这里的m表示局部块,且M=6,即将行人的全局特征图水平分为6块,分别得到6个局部特征.
进一步地,利用全局-局部特征一致性约束来保证提取的全局特征能够包含丰富的局部细粒度信息,有:
(9)
值得注意的是,不同于PCB利用拼接后的局部特征进行距离度量,在本文的方法中,可以直接利用全局特征进行度量,从而有效避免时间以及内存的消耗.
3.3 时空信息嵌入模块
同一行人不可能在同一时间段出现在不同的相机视角下,如果能充分利用这种先验信息,在测试过程中排除一些视觉特征相似的难样本,就能进一步提升识别率.时空信息嵌入模块如图2所示,图中虚线框表示识别错误,其余的表示识别正确.传统的行人再识别只是利用视觉特征进行距离度量,当存在外观相同时则可能判断错误.加上时空信息约束的话,就可以大幅度提高识别的准确率.因此,引入行人图像的时空信息,并利用相机标签以及视频帧进行统计建模.
首先,创建一个粗略的时空概率分布直方图:
(10)

图2 时空信息嵌入模块Fig.2 Module of spatial-temporal information embedding


(11)
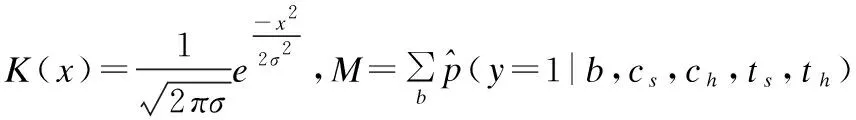
得到时空概率分布直方图后,就可以利用联合度量的思想.在得到特征的相似性度量排序之后,引入时空概率以排除一些外貌相似却不可能出现在该相机下的难样本.另外,和大多数方法一样,本文也采取重排序的策略,进一步提升识别率.
3.4 算法描述
综上,总的损失函数如公式(12)所示:
Ltotal=Lid+λ1Lc+λ2Lgl
(12)
式中Lid=Lid1+Lid2+Lid3+Lid4,即身份约束,λ1和λ2是两个超参数,分别用于权衡Lc和Lgl的重要性.为了更好的理解上述过程,我们对本文方法的算法进行描述,如表1所示.

表1 判别性信息增强的行人再识别方法Table 1 Person re-identification method based on discriminative information enhancement
4 实验分析
4.1 数据集和评价指标
Market-1501[32]是一个由6个不同摄像头拍摄到的32668张样本组成的数据集.该数据集含有1501个被标记的行人,其中训练集包含751个行人的12936张图像,测试集有750个行人的19732张图像;DukeMTMC-reID[33]包含8个摄像头拍摄到的1812个行人,其训练集包含了702个人的16522张图像,测试集由2228个查询图像和17661张搜索图像组成.
在本实验中使用累计匹配曲线(CMC曲线)和平均精度(mAP)去评估实验性能.对于每个查询样本,CMC表示的是行人检索的准确率,采用Rank-1,Rank-5和Rank-10来表示.
4.2 实验参数设置
本文提取原始图像特征和生成图像特征的网络相同,网络的主干部分采用改良池化后的ResNet-50提取视觉特征向量,并且额外增加了1个池化卷积层,6个1x1的卷积层和6个全连接层.训练数据集是由经过CamStyle风格转换生成的图像和原始数据集组成的新数据集.将所有训练图像剪裁为384x192作为网络的输入,训练批次的大小设为24.使用随机梯度下降法对网络参数来进行优化,其中权重衰减因子设为0.0005,动量设为0.9.训练迭代次数(epoch)设为60.初始的学习率设为0.001,每20个epoch之后学习率衰减为当前值的0.1倍.主干网络ResNet-50的初始参数是在ImageNet[34]上预训练得到的.对于空间-时间信息约束,将时间间隔Δt设为100帧.将λ1设置为0.04,λ2设置为0.001.
4.3 性能比较
在Market-150和DukeMTMC-reID两个数据集上对提出方法进行了实验,并与其他主流的方法进行比较.
首先,在Market-1501上与11种主流方法进行对比分析,这些方法可以归纳为6类.包括:1)手工标记特征的方法:BoW(Bag-of-Words)+Kissme[32]、WARCA(Weighted Approximate Rank Component Analysis)[35];2)基于深度学习的方法:PAN(Pedestrian Alignment Network)[36],SVDNet(Singular Value Decomposition Net)[37];3)基于属性的方法:SSDAL(Sem-Supervised Deep Attribute Learning)[38],APR(Attribute Person Recognition)[39];4)行人掩膜引导的方法:Mask-guided[40],Background[41];5)基于人体姿势分割方法:PDC(Pose-Driven Convolutiona)[42],PSE(Pose-Sensitive Embedding)+ECN(Exemplar Camera Neighborhood)[43];6)基于时空的方法:TFusion-sup(Temporal Fusion supervised)[31],实验结果如表2所示.

表2 Market-1501 结果对比Table 2 Market-1501 results comparison
由表2可知,本文提出方法在Market-1501上进行的Rank-1为96.1%,mAP为88.7%,超过了其他方法在该数据上的取得最好性能.相比较于最优的人体姿势分割方法PSE+ECN[43],提出的方法在Rank-1和mAP上分别提升了5.8%和4.7%,这充分说明我们的方法能够提取到更加具有判别性的行人特征.
如表3所示,是本文提出的方法在DukeMTMC-reID数据集上和目前主流方法的对比结果.和表2类似,我们将方法分为5大类,包括:1)手工标记特征的方法:BoW+Kissme[32],LOMO(Local Maximal Occurrence Feature)+XQDA(Cross-view Quadratic Discriminant Analysis)[44];2)基于深度学习的方法:PAN[36],SVDNet[37],HA(Harmonious Attention)[23];3)基于属性的方法:APR[39];4)行人掩膜引导的方法:Human Parsing[3];5)基于人体姿势分割方法:PSE+ECN[43],MultiScale[45].
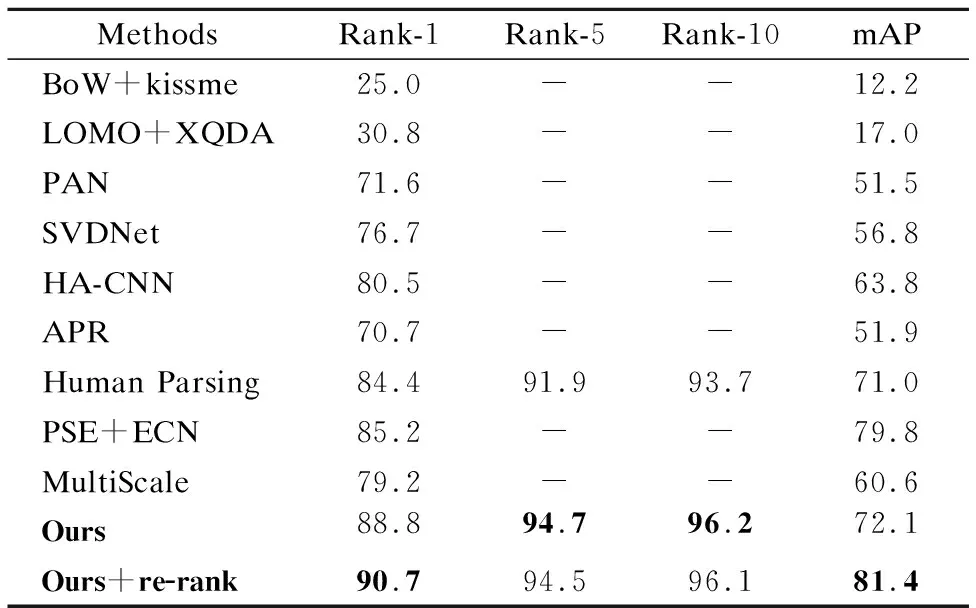
表3 DukeMTMC-reID结果对比Table 3 DukeMTMC-reID results comparison
从表3中可以看到,相比较于目前最优的PSE+ECN(使用Re-ranking)方法,本文提出的方法在Rank-1上从85.2%增加到88.8%.在使用Re-rank的情况下,我们方法的rank-1和mAP分别提高了了5.5%和1.6%.
4.4 消融实验
如公式(12)所示,提出的判别性信息增强的行人再识别方法主要包含身份损失(Lid)、特征一致性损失(Lc)以及全局-局部一致性损失(Lgl).其中,Lid用以约束网络提取行人的判别性特征,Lc通过约束原始图像与迁移后图像之间特征的距离来进一步增强行人的身份信息,Lgl利用全局与局部特征之间的约束来保证全局特征中的细粒度信息.为证明上述3个损失的有效性,在这一部分进行了消融实验,实验结果如表4所示.

表4 消融实验Table 4 Ablation experiment
由表4可以看出,Lid是保证特征判别性的基础.当加入Lc损失后,在Market-1501数据集上,mAP和Rank-1分别提升了2.6%和2.7%.同样,在DukeMTMC数据集上,性能也有很大的提升.这充分说明了该损失项能够有效增强行人的身份信息并消除摄像机成像风格对识别性能的影响.另外,加入Lgl后,识别性能进一步提高,表明通过全局与局部一致性损失约束能够使网络提取更加丰富的全局特征.
4.5 参数分析
在提出的模型中,一共用了两个超参数λ1和λ2分别权衡辅助子网络和主干网络的相对重要性.将这两个值分别设为0.04和0.001.为了证明选择的值是最优的,分别在两个数据集上做了参数分析的实验,并将结果展示如图3所示.

图3 λ1和λ2对mAP和Rank-1的影响Fig.3 Effect of λ1 and λ2 on mAP and Rank-1
由图3可以看出,当λ1=0.04,λ2=0.001的时候,提出的模型能够取得最优的性能.
5 结 论
本文提出了一种判别性信息增强的行人再识别方法,在摄像头风格迁移下生成新的图像,使得新生成图像和原来的图像组成一个新的数据集,以此来进行数据的扩充.在此基础上对全局特征进行拼接来增强行人特征中的判别性信息,并且利用行人的局部特征来丰富行人的特征细节,结合全局特征及局部特征融合的相似性来对图像进行一个归类.结合数据集中图像的时空信息和时空概率分布,在检索时去掉不相关的图像,从而提高检索的性能和速度.本文提出的方法在Market-1501和DukeMTMC-reID两个数据集上都取得了良好的性能,相比于目前的主流方法性能有较大的提升,消融实验充分说明了该方法的有效性.本文方法需要额外的网络进行样本扩充,对模型部署有一定限制,而且使用大量有标注的样本会消耗人力物力.在今后的工作中,会进一步研究无监督域自适应的行人重识别,在不使用人工标注的条件下减小不同数据的域偏移现象.
