奖励引导的辅助防空反导自主作战决策研究
2022-07-06韩兴豪曹志敏刘家祺李旭辉
韩兴豪,曹志敏,刘家祺,李旭辉
(江苏自动化研究所,江苏 连云港 222061)
0 引言
目前,在军事作战中主要靠指挥员以自己的直觉和经验做出实时决策。然而现代作战态势愈加复杂,场面瞬息万变,独以人力很难在短时间内根据复杂的战场信息完成最优决策。而现有的辅助决策技术效率低,决策质量差强人意,智能辅助决策水平亟待提高。为突破基于流程和规则的分层决策空间和基于决策树的分支推演技术,深度强化学习为现代作战智能决策技术的升级换代提供了强有力的理论与技术支持。
近年来深度网络在各个领域的广泛应用及卓越成效为强化学习的发展提供了又一次机遇,它针对强化学习的价值函数逼近问题提供了有效的解决方案,让强化学习重新焕发了生命力。深度强化学习在很多应用方面经过一系列发展已经可以交出一份让人满意的答卷,比如在Atari环境、三维虚拟环境、机器人控制等领域的应用取得了相当卓越的成果。但这些环境在复杂度上相比一些实际问题仍有着云泥之别。比如在海面作战环境中,就包括数十种作战单位,每种平台对应一种智能体,如何在同一环境下快速有效地学习自主决策是个极大的挑战。
现代全域作战态势复杂度过高,利用深度强化学习为指挥员在作战中提供辅助决策,将指挥员从一部分作战决策中解放出来,使其聚焦于战场调度等更重要的决策,是目前军事智能化的一大前景。但是,若想将每个作战平台同时实现智能化决策,其难度堪比大海捞针;另一方面,若仅在简单对战场景中构建深度强化学习智能体,例如空战1V1,其态势特征太过简单,对实战的参考价值十分有限,而且无法体现出深度网络提取态势特征的优势。基于以上2个原因,本文将复杂的战场态势在智能决策方面进行简化,在其他作战平台皆基于规则进行决策的仿真推演环境中,为执行辅助防空反导任务的歼击机构建智能体进行强化学习,探索逐步为现代多域作战全面实现智能化的道路。
然而强化学习在实际应用中,需要很久的训练时间,甚至可能不收敛。另一方面,仿真推演中可以明确地触发收益的“状态-动作”二元组很少,相互之间相隔时间步很远,且表示向目标靠近的收益更加稀缺,智能体可能会长期没有目的地漫游,即强化学习中所谓“高原问题”。良好的奖励函数可以有效缩短智能体学习时间,让算法更快地收敛。
解决稀疏奖励问题的典型方法是利用逆向强化学习,从专家样本中进行学习,逆推出奖励函数,但是这一方法对具有较强随机性的高维问题却无能为力。本文采用奖励重塑的方法,加入好奇心机制,可以在一定程度上解决稀疏奖励,激励智能体在环境中进行有效探索以获得最大累积奖励。
1 实验环境及预处理
本文实验环境为某战役级仿真平台,支持联合作战模拟的战役战术一体化仿真推演。对战双方控制各自兵力进行对抗,包括进行机动、开关传感器、武器发射等,从而做出探测、跟踪、打击等命令,最终决出胜负。模型库中包括实际作战中的多种平台的仿真模型,比如飞机、水面舰艇、机场等,每个平台的指令类型可以是任务驱动(包括巡逻任务、打击任务、伴机/舰飞行等),也可以由实时指令驱动(如航线规划、目标打击等)。仿真环境中的单位可以按照已编辑好的想定过程和规则进行决策动作,并且内置裁决系统,每一局对战结束后,可以统计弹药消耗与平台毁伤程度,根据每个平台的价值,计算对战双方得分,从而判定胜负。进行多次推演,每局对战训练流程如图1所示,对胜负次数加以统计,评价智能体自主决策效果。
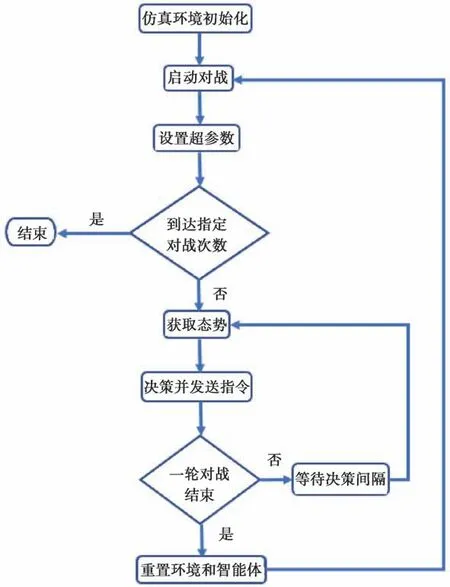
图1 对战训练流程
本实验重点研究海面全域作战中歼击机在辅助防空反导任务中的自主决策水平,目前仅构建歼击机的强化学习智能体,在仿真环境的基础上对态势信息进行提取与封装,便于算法实现与智能体构建。图2为对战训练框架。

图2 对战训练框架
1.1 确定输出动作空间
为了便于强化学习建模与训练,决策模型采用指令集合,将多维输出映射到指令集中。对战训练框架如图2所示,将歼击机指令模型化为探测、突击、拦截等。指令参数包括以下几种:(1)是否选择敌方单位作为打击目标,用0~1表示;(2)目标选择,包括敌方预警机、战斗机及敌方发射的反舰、防空导弹等,用敌方单位编号表示;(3)传感器开关,为发现、跟踪敌方单位并防止自己被敌方探测或跟踪;(4)突击方向,即相对正北方向角度,顺时针最大360°;(5)武器选择,一方面针对不同运动介质中的平台分配不同类型的武器,包括反舰导弹、空空导弹等,另一方面根据武器的打击范围与毁伤能力进行部署;(6)武器齐射数量,根据武器的打击能力与目标平台的毁伤程度分配适量的武器,尽量避免武器的浪费或打击不充分;(7)武器发射距离与最大射程百分比,当前武器发射与目标平台的距离与武器最大打击距离的比例,比值越小命中率越高。
1.2 态势信息构建和预处理
智能体依靠态势信息进行决策,如何在海量复杂的态势中提取出对决策有用的信息,需要人为对仿真过程中产生的数据进行处理。仿真推演过程中可以获取每个单位的状态信息,包括经纬度、高度、剩余油量、机动速度、运动航向等,对不同类型的平台还需要针对性地收集信息,例如飞机、水面舰艇需收集所载传感器类型和探测距离、搭载武器的种类及数量、平台毁伤程度等,对这些态势数据进行提取和格式化处理作为强化学习的状态输入。取个时刻的态势作为第一维,智能体的数量作为第二维,每个智能体的态势信息作为第三维,组成仿真环境的状态空间,作为智能体的决策依据。
2 奖励函数设计
在复杂的作战仿真环境中,收益稀疏的问题愈发显著。及时提供非零收益让智能体逐步实现目标,已经是一个十分困难的挑战,而让智能体高效地从各种各样的初始状态下进行学习无疑难上加难。本章节探讨完成奖励计算模块,根据态势信息计算奖励,作为决策动作的反馈,嵌入仿真环境中与智能体进行交互。
如何设计并重塑一个适用于一般作战想定的奖励函数,获得较为显著的训练效果,提高决策质量,是本文研究的创新点和重点。作战过程一般会持续比较久的时间,期间每次决策奖励的延迟时间也长短不一,所设计的奖励函数要能够在一定程度上体现出每次决策的效果。本文主要为执行辅助防空反导作战任务的歼击机重塑奖励函数。
2.1 动作奖励
单个平台每做出一次决策,即选择一个动作,或机动到指定点,或选择武器进行攻击,或开关传感器等,都会从环境获得奖励。
2.1.1 机动指令奖励
提出一种基于相对方向与相对位置的奖励函数设计方法,以敌方每个平台对我方智能体的威胁系数为权值,对距离进行加权求和。采取机动指令会根据该平台方位的变化所带来的影响来计算奖励,奖励的大小由以下因素决定:
(1) 与己方单位的平均距离D。该指标在一定程度上可以体现出其安全系数,与己方单位距离较近时,方便互相之间进行协同,能够快速形成以多打少的局面,避免出现孤立无援的情况,存活率较高,奖励值会相对较大。采用加权距离D,计算方式如下:
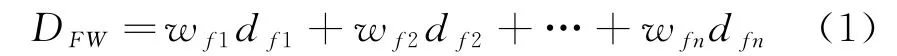
式中:w与d表示平台1~的重要性系数及其与智能体的距离。
(2) 与敌方单位的平均距离D。该指标可以体现出平台受威胁系数。一方面避免孤军深入;另一方面为防止仿真作战过程中,智能体一直游离在战场环境之外,在广泛的时空域中反复进行无效的探索,需要利用奖励函数引导作战单位与敌方拉近距离进行对战。
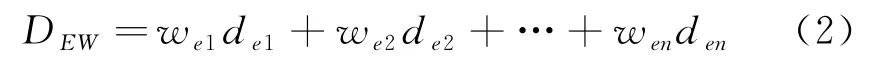
式中:w与d分别表示敌方平台的威胁系数及其相对我方智能体的距离。
为防止我方平台进入敌方单位集火范围,应尽量与敌方某一落单目标拉近距离,而与其他平台保持距离。
(3) 是否在敌方单位的武器打击范围内。充分发挥武器射程优势,尽量保持在敌方攻击范围之外,保证己方安全又使敌方单位在我武器打击范围之内,对敌方单位进行“风筝”式攻击。
对这些因素进行加权求和,在单位采样步长的变化值即为机动指令奖励值。
2.1.2 武器发射奖励
发射武器首先会反馈比较小的负奖励,不同的武器根据成本和威力大小对应不同的奖励值。武器发射一方面表示弹药消耗,会从环境获得即时的负奖励。另一方面预示着可能给敌方平台带来损伤,即命中奖励,将此部分归结为武器命中事件,属于事件奖励,将在后续进行介绍。
2.2 状态奖励
在作战推演过程中,所有平台的状态处于不断变化中,包括油量、毁伤程度等。油量的变化主要由机动和加油引起,机动过程引起油量的降低会获得负奖励;在油量越低的情况下进行加油获取的奖励越大。毁伤情况分为不同平台、不同部位的毁伤,根据命中目标的不同,获取不同的奖励,从导弹、轰炸机到歼击机奖励逐渐增大。对敌方平台,按照其威胁程度,威胁越大的目标受损时获得的奖励越大;对我方平台,按照重要性升序,越重要的平台受损获得越大的负奖励。
2.3 事件奖励
现代战场可以说是信息的较量,谁在作战中掌握了更多信息,谁就掌握了战场的主动权,对取得作战胜利起着至关重要的作用。将信息表征为各种关键事件的发生,将事件类型分为:(1)探测事件,包括捕获目标、捕获目标消失、目标识别、目标跟踪等;(2)武器系统事件,包括发射失败、弹药耗尽、武器命中、超出武器射程、目标跟踪丢失等,其中命中事件的触发需要武器发射后相当一段时间才能进行判定,因此该动作奖励有较大的延迟问题。本文采用长短期记忆网络(LSTM)对一段时间内的状态、动作进行记忆与传递,间接反映出决策的优劣,进而对后续动作产生影响;(3)干扰事件,包括遭受干扰、受干扰结束等;(4)通信事件,包括数据链建链、数据链结束、网络开通、收发、网络结束等。多数时候纯以动作的奖励无法反映出这些事件所带来的影响,因此需要为这些事件单独设计奖励,从态势中获取事件信息,触发奖励。
3 实验仿真
初步确定超参数,包括仿真回合数、仿真速度、决策间隔、最大决策步数、学习速率等。引入Pytorch深度学习框架实现神经网络结构,利用Python语言搭建智能体构成Agents模块,实现以下功能:重置智能体、计算动作状态价值、计算损失函数、计算优势函数、动作选取与价值评论等。
3.1 智能体神经网络结构设计
深度网络对数据有更强的信息提取能力,本文采用卷积与循环神经网络(CRN)。网络结构如图3所示。与传统神经网络相似,它由一系列带有权重与偏置的神经元组成,每个神经元从上一层接受输入,先进行矩阵运算,再利用激活函数进行非线性处理。将当前连续时刻的状态数据进行堆叠作为网络的输入,卷积网络(CNN)能够取代传统的人工,更高效地对态势环境进行特征提取。但这增加了网络的存储和计算难度,因此插入循环神经网络(LSTM),对时间轴上的历史状态信息进行提取与记忆,做出优化决策。经验表明,在部分可观测模型中,CRN 网络结构表现出比其他网络更好的性能,也更适用于作战仿真中复杂任务的训练。各神经网络模块功能见表1。
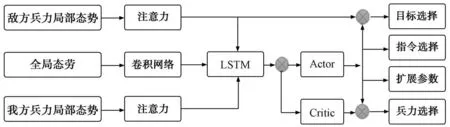
图3 网络结构

表1 网络模块说明
3.2 智能体学习训练算法实现
根据马尔可夫决策过程(MDP)进行建模,仿真推演过程中,智能体(Agent)与作战环境之间进行数据交互,在每个时间步,智能体从环境中获取状态数据,然后根据策略和约束条件从动作空间中选取可执行的动作,再从环境获取奖励,直到环境的终止状态。训练目的是获得一个策略函数(即从状态到动作的映射),使智能体采取一系列动作之后所获取的累积奖励最大。由于仿真环境中战争迷雾的存在,使典型的局部可观测马尔可夫决策过程(POMDP)。本文中MDP 包括无限的状态空间与有限的动作空间,以及奖励函数:→,表示智能体在状态下采取动作获得的期望奖励,策略:→表示从状态到动作的映射。智能体在时刻获取到带有奖励r与动作a的状态观测o,态势状态为s,那么时刻的奖励R定义为累积折扣奖励:

式中:为折扣系数。
算法的目标就是将累积奖励最大化。加入并行机制,即在一台计算机上使用多个线程进行训练,每个线程单独与环境进行交互并计算梯度。这种方法可以免去发送梯度参数的通信消耗。各线程中使用不同的探索策略,平行地运行多个动作-评论网络可以更快速有效地对环境中的各个部分进行探索。将多个线程结合在一起,进一步减弱了探索事件的相关性,利于程序的收敛。
本文采用强化学习的典型算法异步优势行动者-评论者算法。A3C 算法是由行动-评论者(Actor-Critic)算法发展进化而来,智能体包括两部分:行动者和评论者,通过对环境的探索与利用来获得两者更好的表现。训练流程如图4所示。行动者用策略函数(a|s;θ)表示,评论者用价值函数V(s,θ)表示,用深度神经网络对策略与价值函数进行近似与逼近。状态的状态价值为:
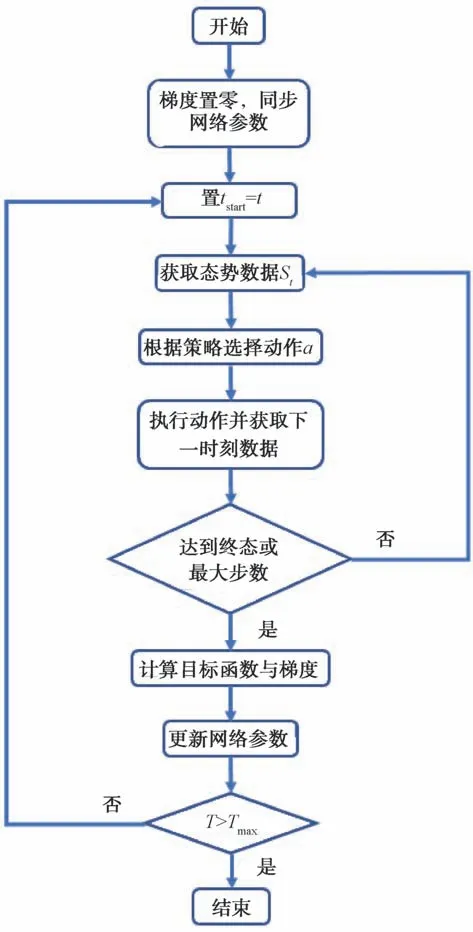
图4 A3C算法流程图
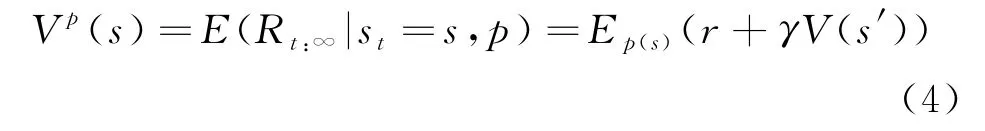
式中:表示在状态下采用策略的期望;为的后继状态。
状态 动作价值函数为:
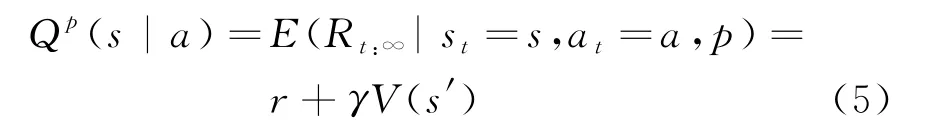
利用时间差分将Actor网络和Critic网络连接起来,计算时序差分(TD)误差为:
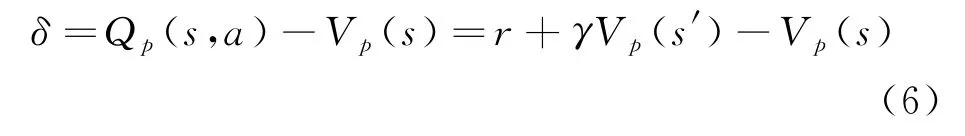
定义优势函数:
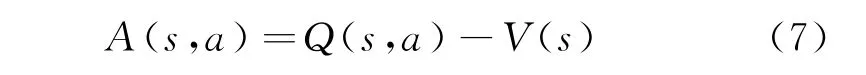
在异步算法中,将优势函数进一步细化为:
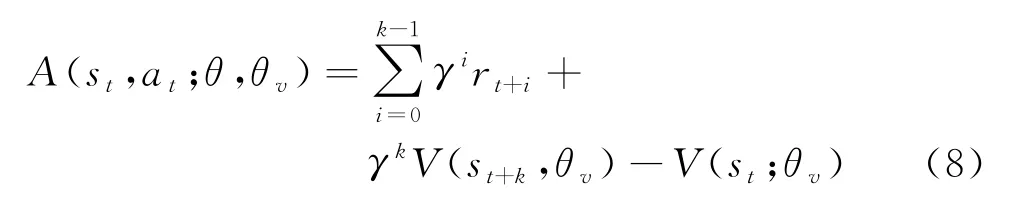
式中:表示时间步长,最大不超过。
为了评估策略的优劣,定义目标函数(),表示从初始状态开始得到的所有状态价值的平均值:
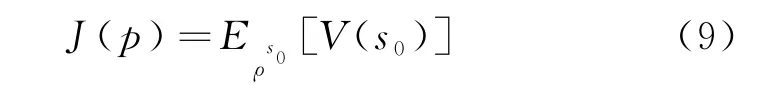
根据策略梯度定理,得到其梯度:
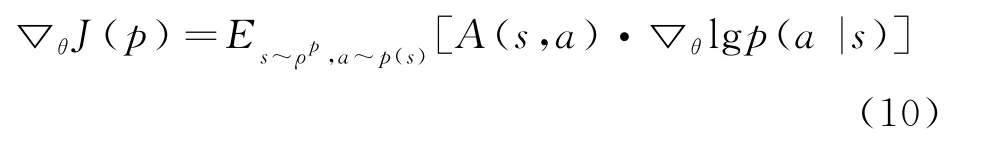
尝试最大化目标函数。采用异步并行训练方式,其算法架构如图5所示,策略函数与价值函数每经过时间步或到达终止状态后进行参数更新。将每个线程中的运行结果反馈给主网络,同时从主网络获取最新的参数更新,最终达到优化网络参数的目的。
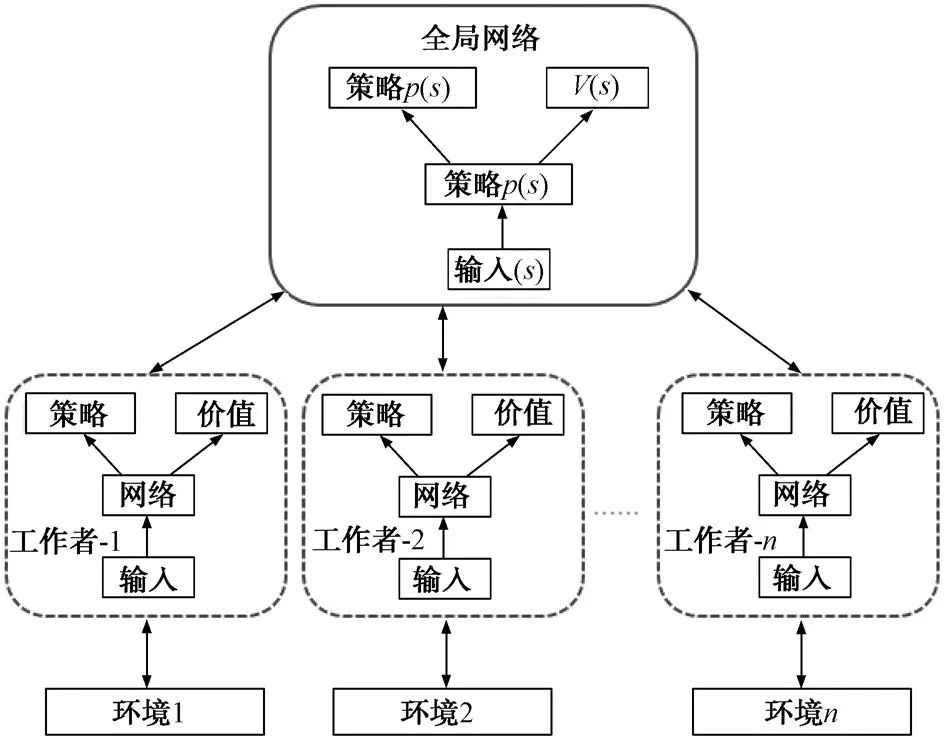
图5 A3C异步架构图
3.3 结果分析
在基于规则的仿真环境中加入红方歼击机智能体进行推演与学习,训练前,智能体决策质量差,而且经常会游离在主战场之外,导致红方胜率很低。但经初步仿真训练,在多次推演迭代后,反复更新智能体策略网络参数。对每百次实验结果进行记录,并统计红方胜率,可以发现红方胜率有明显提升。虽然现阶段智能决策水平相比基于规则的决策方法尚有差距,但其发展空间很大,随着迭代次数与技术水平的提高,达到超越人类专家的决策水平的目标已不再遥不可及。
4 结束语
现在国际局势扑朔迷离,瞬息万变,但有一点毋庸置疑,于我不利。小规模冲突不断,虽然发生大规模作战的概率不高,但仍需我军提高警惕,时刻准备作战。实现军事决策智能化对我军实现战术升级、减小损耗、降低伤亡有着重要意义。本文探索了一条实现现代作战智能化的道路,对模型相似的作战单位构建智能体进行学习,未来逐步实现预警机、护卫舰等作战平台的智能体,为护国强军保驾护航。
