基于深度学习的耦合度相关代码坏味检测方法
2022-07-05苏珊张杨张冬雯
苏珊,张杨,张冬雯
基于深度学习的耦合度相关代码坏味检测方法
苏珊,张杨*,张冬雯
(河北科技大学 信息科学与工程学院,石家庄 050018)(*通信作者电子邮箱uzhangyang@foxmail.com)
基于启发式和机器学习的代码坏味检测方法已被证明具有一定的局限性,且现有的检测方法大多集中在较为常见的代码坏味上。针对这些问题,提出了一种深度学习方法来检测过紧的耦合、分散的耦合和散弹式修改这三种与耦合度相关检测较为少见的代码坏味。首先,提取三种代码坏味需要的度量并对得到的数据进行处理;之后,构建卷积神经网络(CNN)与注意力(Attention)机制相结合的深度学习模型,引入的注意力机制可以对输入的度量特征进行权重的分配。从21个开源项目中提取数据集,在10个开源项目中对检测方法进行了验证,并与CNN模型进行对比。实验结果表明:过紧的耦合和分散的耦合在所提模型中取得了更好的结果,相应代码坏味的查准率分别达到了93.61%和99.76%;而散弹式修改在CNN模型中有更好的结果,相应代码坏味查准率达到了98.59%。
代码坏味;耦合;深度学习;卷积神经网络;注意力机制
0 引言
随着产品功能的不断变更,开发人员需要不断更新软件源代码以适应新的需求,代码在长期的增加和修改中通常会变得更加复杂,容易偏离最初的设计,从而导致软件的质量降低。软件重构是提高软件质量的有效手段,它重组软件应用程序的内部结构,同时不改变它的外部行为[1]。重构过程主要由三个步骤组成:1)确定软件应该重构的地方;2)确定哪些重构应该应用于已识别的位置;3)评估重构对软件质量特征的影响[1]。Kent Beck在识别软件应该在哪里重构时创造了“代码味道”这个术语[2],他认为,难闻的气味是“代码中暗示重构可能性的结构”,具有这种症状的软件系统很容易随着时间的推移而产生错误,因此会导致麻烦和昂贵的维护过程[3]。
在早期阶段检测代码坏味可以使重构在成本和时间方面更加经济,因此,研究人员提出了许多种不同的技术来检测代码坏味。Yoshida等[4]提出了一种基于内聚度量的方法来识别长方法;Palomba等[5]通过挖掘源代码的历史版本来识别特征嫉妒;Sales等[6]提出了一种基于依赖的方法(称为JMove)来识别特征嫉妒。然而,不同的研究人员对代码坏味的定义存在不同的认识,这就导致了在解释或对检测结果进行对比时会存在很大困难[7]。在这种情况下,使用机器学习技术被认为是处理这种缺乏共识的一种合适方法。Maiga等[8]引入支持向量机机制检测代码坏味;Kreimer[9]提出了一种基于决策树的检测方法检测长方法和上帝类;Fontana等[10]对数据类、上帝类、特征嫉妒和长方法四种代码坏味进行了16种机器学习算法的实验。然而,有实证研究表明,这种基于机器学习的代码坏味检测方法具有一定的局限性[11],值得进一步研究。
最近,深度学习已经广泛地应用到包括文本处理在内的许多研究领域。深度学习算法不同于建立在浅层结构上的传统机器学习,它可以对数据进行从低到高多层抽象[12]。深度神经网络已被证明能够很好地选择有用的特征,并自动建立从输入到输出的复杂映射。Guo等[13]提出了一种基于深度学习的方法,该方法结合了方法表征和卷积神经网络(Convolutional Neural Network, CNN)模型来检测特征嫉妒,可以自动地从文本代码和代码度量中提取语义和特征,并且还可以自动地在这些特征和预测值之间建立复杂的映射;卜依凡等[14]提出了一种深度学习检测方法,该方法不仅利用了常见的软件度量,还充分利用了代码中的文本信息,意图通过挖掘文本语义揭示每个类所承担的主要角色。
虽然现有的检测技术得到了很大的提升,但目前的工作仍存在一定问题:首先,现有的工作主要集中在那些流行的代码坏味,如特性嫉妒、上帝类和长方法,很少有工作进行耦合度相关的代码坏味检测;其次,据我们所知,还没有公共数据集用来检测与耦合度相关的代码坏味。
过紧的耦合、分散的耦合和散弹式修改是代码编写中三种典型的耦合错误,我们在21个开源项目中提取了这三种代码坏味的数据集,通过搭建由一维卷积层组成的CNN并引入注意力(Attention)机制来创建代码坏味度量特征和预测值之间复杂的映射,形成的代码坏味检测分类器在10个开源程序上进行了验证。实验结果表明,过紧的耦合和分散的耦合在本文所提模型中有更好的结果,散弹式修改在CNN模型中有更好的结果。
本文的主要工作如下:
1)现有的检测过紧的耦合、分散的耦合和散弹式修改这三种代码坏味的工作并不多,而且集中在利用启发式方法进行检测,但启发式方法存在一定的局限性,因此本文提出CNN和Attention机制相结合的深度学习方法,以自动提取数据特征并对输入特征进行权值分配。据我们所知,这是首次利用深度学习技术检测过紧的耦合、分散的耦合和散弹式修改这三种代码坏味。
2)现有的代码坏味数据集大多集中在较为流行的代码坏味,还未有公开数据集用于检测本文提出的过紧的耦合、分散的耦合和散弹式修改这三种代码坏味,为此本文构建了检测这三种代码坏味的数据集。
3)现有检测代码坏味的方法在呈现结果时都呈现的是整体的准确率,然而测试集数据不均衡容易出现含有代码坏味方法的准确率低、不含代码坏味方法的准确率高从而整体准确率高的情况,本文在呈现结果时分别呈现的是含有代码坏味方法和不含代码坏味方法的检测准确率,以避免对模型高准确率的误判。本文所提出的代码坏味检测方法能取得较高的准确率,过紧的耦合和分散的耦合在本文模型中有较好的结果。
1 相关工作
现在已经有一些在过紧的耦合、分散的耦合和散弹式修改这三种代码坏味检测方面的工作。Kessentini等[15]使用并行进化算法检测散弹式修改等代码坏味,他们将代码坏味的检测视为一个分布式优化问题,在优化过程中并行组合不同的方法,以找到关于代码坏味检测的共识;Fu等[16]利用关联规则从软件系统的变化历史中挖掘数据,在此基础上定义启发式算法来检测散弹式修改等三种代码坏味,在五个开源项目上的实验结果表明该方法具有较高的查准率和查全率;Vidal等[17]根据Lanza和Marinescu提出的检测策略开发了检测工具JSpIRIT,该工具可以用来检测过紧的耦合、分散的耦合、散弹式修改等代码坏味;Palomba等[5]提出了一种检测方法HIST,该方法通过从版本系统中挖掘变化的历史信息,特别是通过分析源代码之间发生的共同变化来检测散弹式修改等代码坏味。
现有的检测过紧的耦合、分散的耦合和散弹式修改这三种代码坏味的研究还不广泛,对这三种代码坏味的检测方法大多是基于启发式的代码坏味检测技术。有一些基于启发式的方法如JSpIRIT[17]是依赖于度量的,然而不同工具使用检测代码坏味的度量可以不同;此外,即使度量是相同的,度量的阈值也会改变,通过改变这些值,检测到的坏味数量可以相应地增加或减少[10]。还有一些检测工具依赖于与代码结构和命名相关的其他规则,例如HIST[5]检测方法通过挖掘版本历史信息进行代码坏味的检测。这些基于启发式的方法必须人工指定且有可能相当复杂。
深度学习技术也已经被用来检测代码坏味,这种技术可以在一定程度上避免代码坏味的主观认识造成的影响。Hadj-Kacem等[18]提出了一种基于自动编码器和人工神经网络的混合检测方法检测了特征嫉妒等代码坏味。在第一阶段,使用深度自动编码器对输入特征空间进行降维,提取最相关的特征;第二阶段选择构建人工神经网络来构建代码坏味分类器。Kim[19]利用CNN构建代码坏味与面向对象度量之间的关系,并通过改变迭代次数和隐层数量进行实验,检测了上帝类等六个常见的代码坏味,均取得了较好的检测结果。Das等[20]构建了CNN来检测大脑类和大脑方法,并通过调整测试的项目数量来展示实验结果,实验结果表明该方法能较好地检测出代码坏味。这些采用深度学习检测代码坏味的方法都取得了较好的检测结果,说明利用深度学习算法检测代码坏味是可行且有优势的。
本文提出了基于深度学习的代码坏味检测方法,该方法是依赖于度量的,通过深度学习技术可以自动建立起度量和标签的复杂映射。
2 三种代码坏味的定义
根据代码坏味的范围,代码坏味可以分为三类:应用程序级、类级和方法级。耦合是指程序中模块及模块之间信息或参数依赖的程度,是影响软件复杂程度和设计质量的一个重要因素。本文将重点检测方法层面上三种与耦合度相关的代码坏味,分别为过紧的耦合、分散的耦合和散弹式修改,这是三种典型的耦合错误。
1)过紧的耦合。过紧的耦合是指某个方法和少数几个类中的很多方法相关联时出现的一种代码结构缺陷[21]。在这种情况下,该方法与这几个类之间的关系将变得不够明确。
2)分散的耦合。分散的耦合是和过紧的耦合具有相反特征的一种代码坏味。在这种情况下,某个方法与其他很多类中的方法有着不是很密集的联系[21]。分散的耦合会导致涟漪效应,分散在各个类中方法的变化潜在地影响了与其相耦合的方法。
3)散弹式修改。与过紧的耦合和分散的耦合相比,散弹式修改重点关注函数调用引起的传入依赖。散弹式修改指的是某个方法被很多其他类中的方法调用[21],这种设计的不协调意味着如果在这样的方法中发生了更改,可能还需要更改与其相关联的其他大量方法,从而导致维护问题。
3 本文检测方法
图1显示了检测代码坏味的总体工作流程。首先从Github中收集了21个开源项目,再将这些项目输入度量分析工具以生成所需度量,根据各个代码坏味的度量检测规则对项目中的方法进行标记;之后将标记好的数据即训练数据集输入神经网络模型进行训练和优化,训练好的模型最后由代码坏味的测试数据集进行评估。
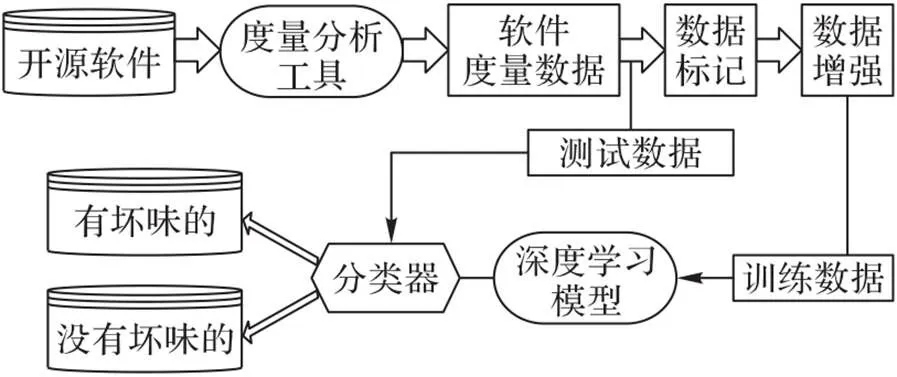
图1 代码坏味检测框架
3.1 提取度量
使用代码分析工具iPlasma分析下载的Java项目。iPlasma是一个面向对象软件质量分析的工具,该工具包含80多个最先进和新颖的设计指标库,可以应用于不同的抽象层次。使用该工具提取了项目中检测三种代码坏味所需要的5种度量,分别为CINT、CDISP、MAXNESTING、CC和CM,三种代码坏味需要提取的度量及定义如表1所示。

表1 代码坏味度量
3.2 标记数据
根据Lanza等[21]工作中检测各个代码坏味的规则,对提取的度量数据进行标记,含有代码坏味的标记为1,不含有代码坏味的标记为0。
判断过紧的耦合、分散的耦合和散弹式修改的公式如式(1)~(3)[21]所示,本文将用它们对这三种代码坏味进行标记:
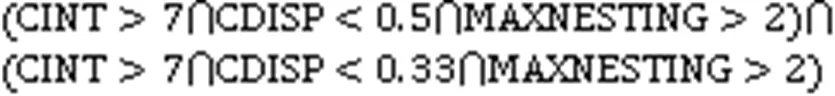
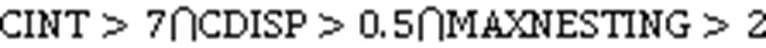
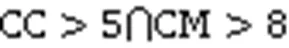
3.3 数据均衡处理
利用深度学习检测代码坏味面临的挑战之一是是否能够收集到大量标记的样本来训练分类器。由于在程序中含有代码坏味的方法是少数,这就导致数据集中含有代码坏味的方法数量远远小于不含代码坏味方法的数量,为了避免数据不均衡对深度模型准确率造成的影响,分别采用了欠采样和过采样方法。
在21个项目中一共提取了165 830条数据,首先采用欠采样方法从中去掉了大量标记为0的数据,但此时数据集中仍存在数据不均衡的情况。为了改善这种情况,使用SMOTE算法[22]对数据进行了增强,SMOTE算法的基本思想就是对少数类别样本进行分析和模拟,并将人工模拟的新样本添加到数据集中,进而使原始数据中的类别不再严重失衡。经过SMOTE算法增强的数据集,标记为1和0的比例达到了1∶1。
3.4 模型结构
本文采用CNN和注意力机制相结合的模型(Attention-CNN)来检测代码坏味,如图2所示。
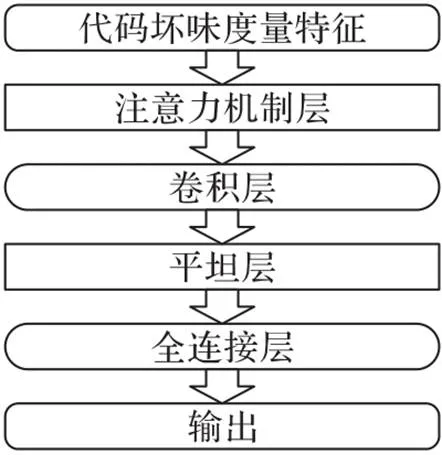
图2 Attention-CNN模型
CNN主要包括输入层、隐藏层和输出层。数据通过输入层进入隐藏层;隐藏层中含有单个或多个卷积层,它根据指定数目的滤波器和激活函数执行卷积运算;最后的输出层负责提供预测结果。
注意力机制是一种资源分配机制,可以通过对输入特征赋予不同的权重来突出更加重要信息的影响[23]。本文在模型中加入了注意力机制对输入的度量特征进行权重分配。
模型中各层的描述如下:
1)输入层。输入层将代码坏味的度量特征数据作为输入,如式(4):
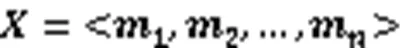
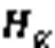
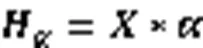
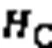
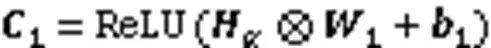
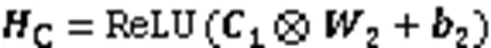
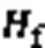
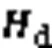

4 实验与分析
4.1 训练数据集
数据集所使用的项目是从GitHub项目中挑选出来的,共包括21个项目,如表2所示,其中:NOC为类的数量,NOM为方法的数量,LOC为代码行数。在构造数据集时选择了不同领域的项目,这样可以消除相同领域项目可能带来的特定代码风格的影响,以保证训练样本的综合性;除此之外,这些样本都是知名的开源项目,代码质量较高,在获取样本时可以获得更为准确的标签样本[14]。
利用3.1节方法先从表2的项目中提取5种度量特征;再根据3.2节方法对提取的特征进行标记;针对提取数据不均衡的情况,以3.3节介绍的方法进行过采样和欠采样处理。最终形成的代码坏味的训练数据集形式如表3所示,训练数据集共8 001条。表3中最后一列标签1表示为该方法存在此代码坏味,标签0表示该方法不存在此代码坏味。
4.2 测试数据集
选取10个新的程序用于生成测试数据集,测试集使用的程序如表4所示,测试集共89 455条。
4.3 实验过程
首先以4.1节方法构建出训练数据集。将数据集输入Attention-CNN模型中,本文所构建的模型代码是基于Keras实现的,在模型优化阶段,以交叉熵作为损失函数,并选择自适应学习率的Adam作为优化算法。随后,模型在训练集上进行多轮训练,将迭代次数设置为100,批尺寸设置为64,经过训练,可以得到一个以软件度量值为输入的分类器。
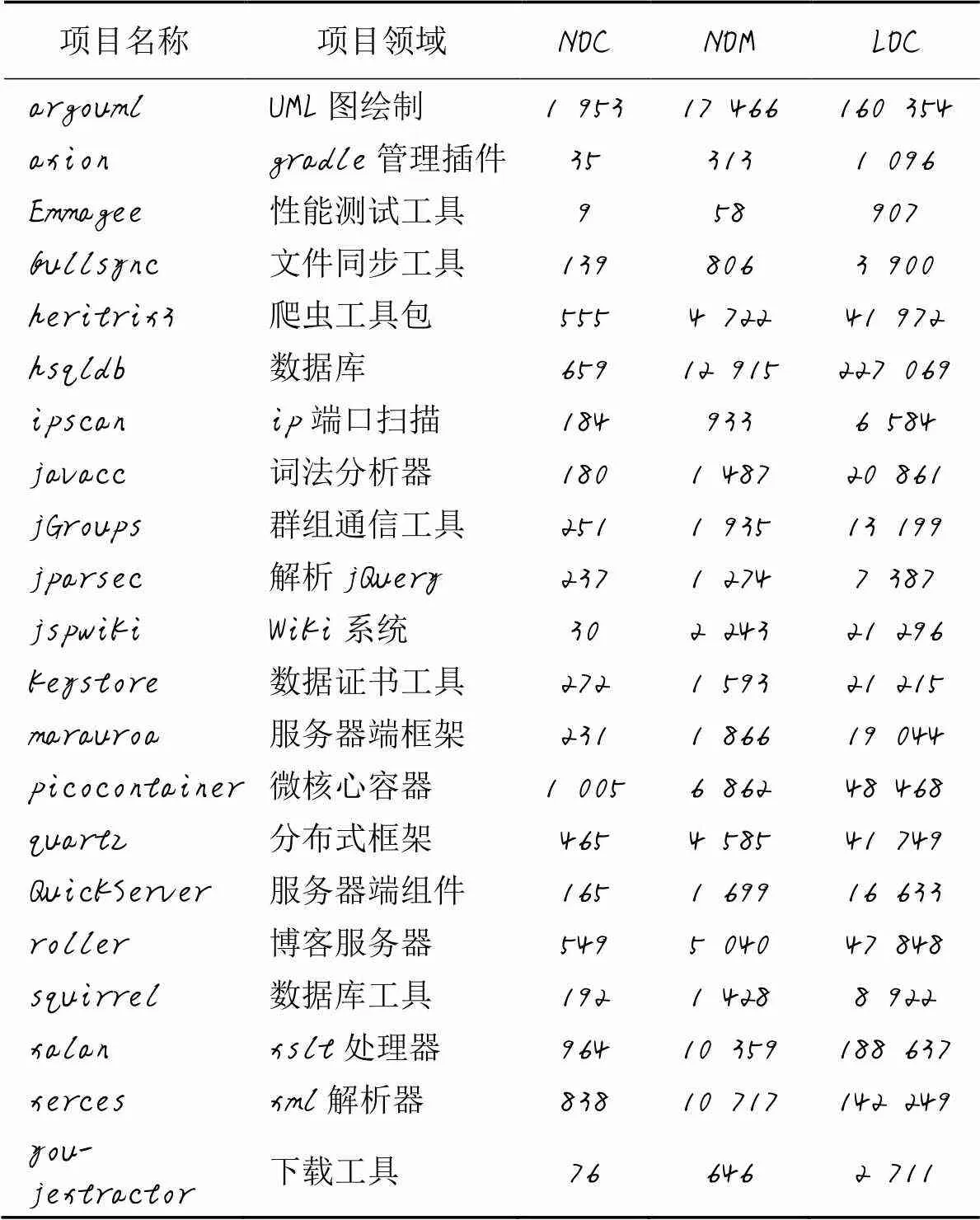
表2 训练集所涉项目
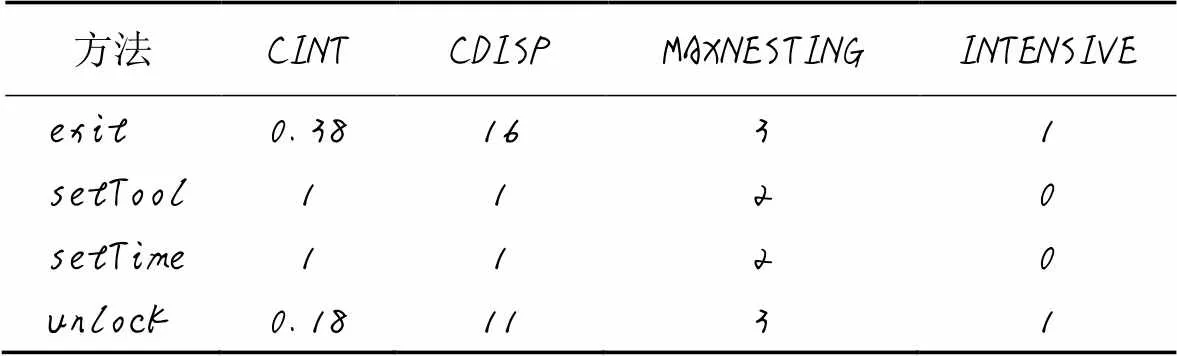
表3 过紧的耦合训练数据集
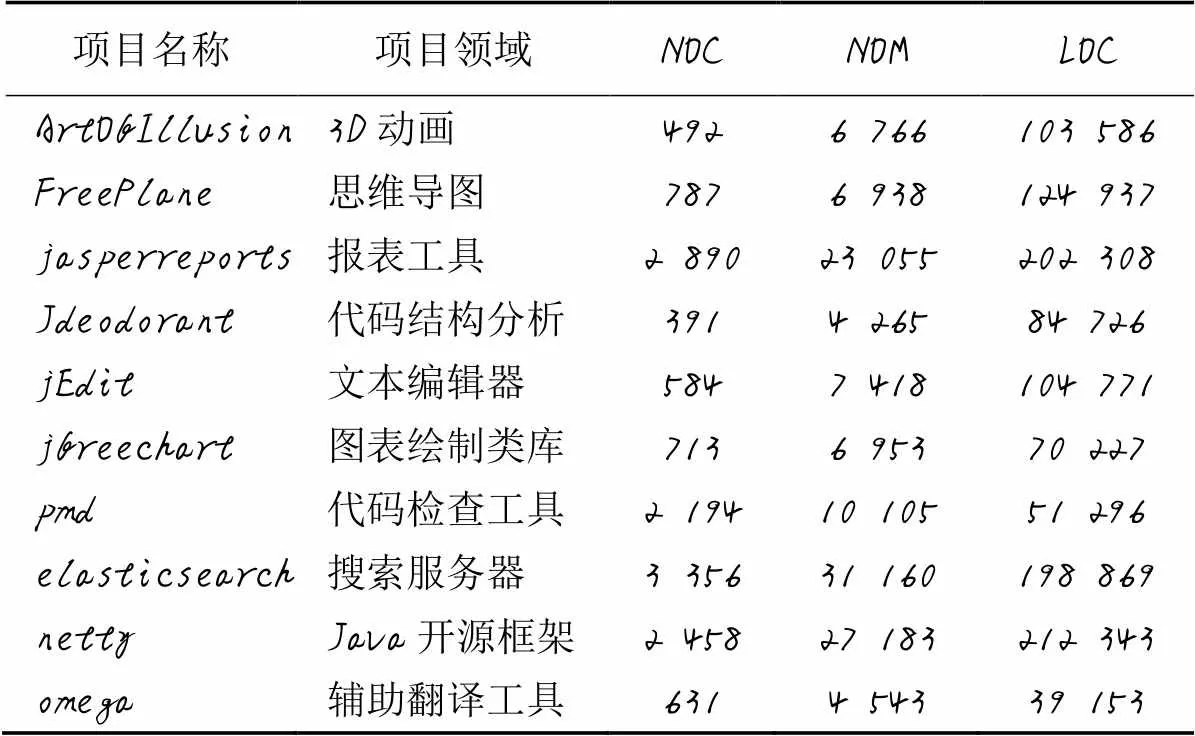
表4 测试集所涉项目
以4.2节所述方式生成测试数据集。将测试数据集输入到已训练好的神经网络分类器后,得到的输出集合即为神经网络分类器在此测试集上的预测结果。
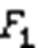

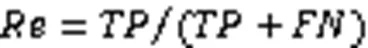
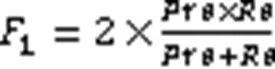
4.4 实验结果
现有的利用深度学习检测代码坏味的方法如Kim[19]提出的构建深度学习模型来建立代码坏味与面向对象度量之间的关系是基于CNN模型的,2019年Das等[20]提出利用CNN模型构建代码度量特征和预测值之间复杂的映射,在依赖度量特征信息来构建深度学习模型的工作中,很多工作用到了CNN模型,所以本文将CNN模型作为对比模型。
三种代码坏味的检测结果如表5~7所示。因为一个开源项目中存在代码坏味的方法是少数,即在测试集中标签为0的数量远远大于标签为1的数量。为了避免出现对标签1的预测结果不够高,但对标签0的预测结果很高,从而导致整体预测结果较高的情况,选择分别显示对标签1和标签0的预测结果来展示本文所构建模型的性能。
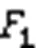
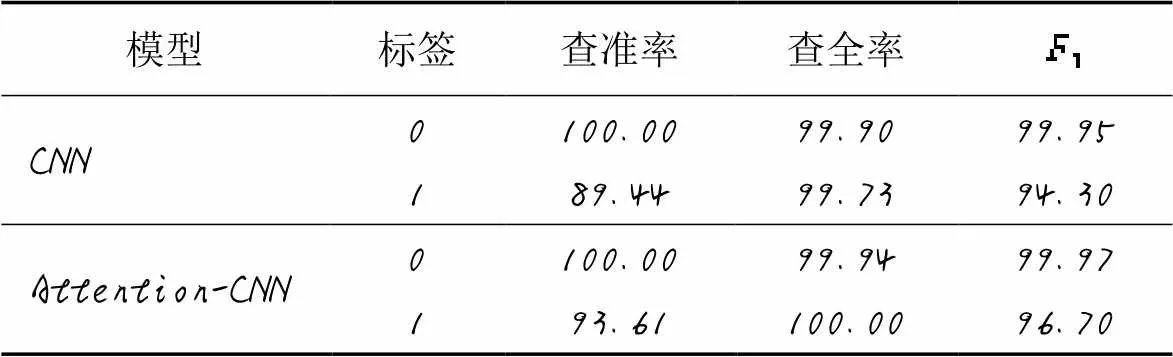
表5 过紧的耦合检测结果 单位: %
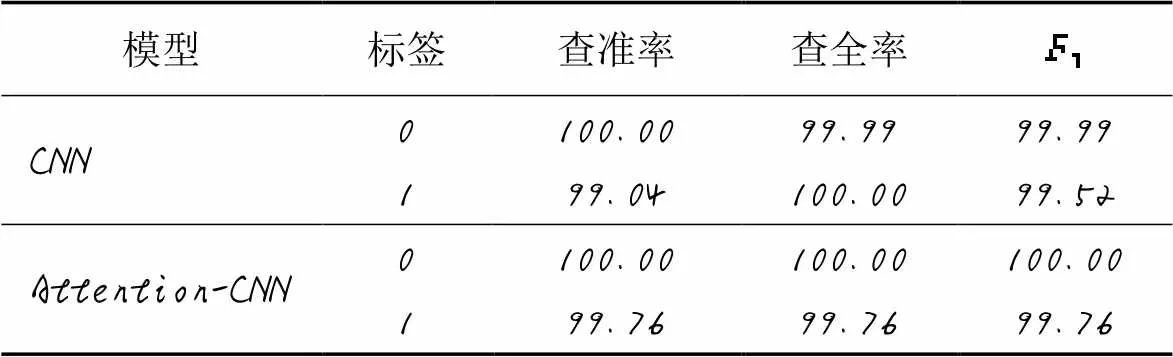
表6 分散的耦合检测结果 单位: %
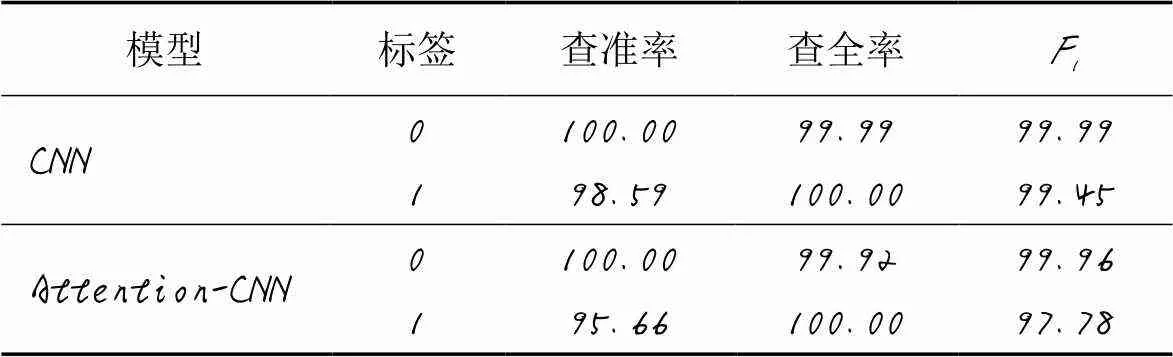
表7 散弹式修改检测结果 单位: %
由表8可知Attention-CNN的模型相较于CNN模型由于增加了模型复杂度,所以时间开销有所增大,但是增幅并不大,过紧的耦合和分散的耦合在Attention-CNN模型上有更好的结果,在检测这两个代码坏味时牺牲小部分时间开销来增加准确率是值得的。

表8 三种代码坏味的时间开销 单位: s
4.5 有效性威胁
对实验过程中威胁有效性的几个因素讨论如下:
1)项目中具有代码坏味的方法是少数,这会导致提取的训练集中容易出现数据不均衡的情况。为了减少这一威胁,采用了欠采样和过采样技术,去掉了大量标签为0的数据,并使用SMOTE(Synthetic Minority Oversampling Technique)生成了一部分标签为1的数据。
2)实验数据集中仅包含10个开源项目,本文所得出的结论有可能不适用于其他项目。为了减少这一威胁,实验选择的训练及测试项目均出自不同的研究领域及开发人员,以期减少某些项目间的特定特征对验证结果造成的影响。
3)测试集中标签0的数量远远多于标签1的数量,在这种情况下,模型对标签0的预测结果通常很高,这就导致模型所体现的高预测率可能仅仅体现在对标签0的预测上。为减少这一威胁,选择分别讨论对标签1和标签0的预测结果来展示本文所构建模型的性能。
5 结语
本文提出了一种基于深度学习的代码坏味检测方法来检测与耦合度相关的三种代码坏味。从21个开源项目中提取训练样本,对这些样本进行度量信息提取和标记后将其输入神经网络模型进行训练,最后在开源项目上对所生成的网络模型进行了测试。实验结果表明,本文提出的深度学习方法具有较高的预测精度。未来我们将把代码更多层次的特征融合在检测方法里,不仅关注代码的度量特征,还将关注代码的语义和历史信息等特征,在更准确的检测代码坏味方面作出更大的努力。
[1] MENS T, TOURWE T. A survey of software refactoring[J]. IEEE Transactions on Software Engineering, 2004, 30(2): 126-139.
[2] FOWLER M, BECK K, BRANT J, et al. Refactoring: Improving the Design of Existing Code[M]. Boston: Addison-Wesley Professional, 1999: 71-76.
[3] APRIL A, ABRAN A. Software Maintenance Management: Evaluation and Continuous Improvement [M]. Hoboken: John Wiley & Sons, 2012: 1-5.
[4] YOSHIDA N, KINOSHITA M, IIDA H. A cohesion metric approach to dividing source code into functional segments to improve maintainability[C]// Proceedings of the 16th European Conference on Software Maintenance and Reengineering. Piscataway: IEEE, 2012: 365-370.
[5] PALOMBA F, BAVOTA G, DI PENTA M, et al. Mining version histories for detecting code smells[J]. IEEE Transactions on Software Engineering, 2015, 41(5): 462-489.
[6] SALES V, TERRA R, MIRANDA L F, et al. Recommending move method refactorings using dependency sets[C]// Proceedings of the 20th Working Conference on Reverse Engineering. Piscataway: IEEE, 2013: 232-241.
[7] MÄNTYLÄ M V, LASSENIUS C. Subjective evaluation of software evolvability using code smells: an empirical study[J]. Empirical Software Engineering, 2006, 11(3): 395-431.
[8] MAIGA A, ALI N, BHATTACHARYA N, et al. Support vector machines for anti-pattern detection[C]// Proceedings of the 27th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2012: 278-281.
[9] KREIMER J. Adaptive detection of design flaws[J]. Electronic Notes in Theoretical Computer Science, 2005, 141(4): 117-136.
[10] FONTANA F A, MÄNTYLÄ M V, ZANONI M, et al. Comparing and experimenting machine learning techniques for code smell detection[J]. Empirical Software Engineering, 2016, 21(3): 1143-1191.
[11] DI NUCCI D, PALOMBA F, TAMBURRI D A, et al. Detecting code smells using machine learning techniques: are we there yet?[C]// Proceedings of the 2018 IEEE 25th International Conference on Software Analysis, Evolution and Reengineering. Piscataway: IEEE, 2018: 612-621.
[12] BENGIO Y, COURVILLE A, VINCENT P. Representation learning: a review and new perspectives[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2013, 35(8): 1798-1828.
[13] GUO X L, SHI C Y, JIANG H. Deep semantic-based feature envy identification[C]// Proceedings of the 11th Asia-Pacific Symposium on Internetware. New York: ACM, 2019: No.19.
[14] 卜依凡,刘辉,李光杰. 一种基于深度学习的上帝类检测方法[J]. 软件学报, 2019, 30(5): 1360-1374.(BU Y F, LIU H, LI G J. God class detection approach based on deep learning[J]. Journal of Software, 2019, 30(5): 1360-1374.)
[15] KESSENTINI W, KESSENTINI M, SAHRAOUI H, et al. A cooperative parallel search-based software engineering approach for code-smells detection[J]. IEEE Transactions on Software Engineering, 2014, 40(9): 841-861.
[16] FU S Z, SHEN B J. Code bad smell detection through evolutionary data mining[C]// Proceedings of the 2015 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement. Piscataway: IEEE, 2015: 1-9.
[17] VIDAL S, VAZQUEZ H, DIAZ-PACE J A, et al. JSpIRIT: a flexible tool for the analysis of code smells[C]// Proceedings of the 34th International Conference of the Chilean Computer Science Society. Piscataway: IEEE, 2015: 1-6.
[18] HADJ-KACEM M, BOUASSIDA N. A hybrid approach to detect code smells using deep learning[C]// Proceedings of the 13th International Conference on Evaluation of Novel Approaches to Software Engineering. Setúbal: SciTePress, 2018:137-146.
[19] KIM D K. Finding bad code smells with neural network models[J]. International Journal of Electrical and Computer Engineering, 2017, 7(6): 3613-3621.
[20] DAS A K, YADAV S, DHAL S. Detecting code smells using deep learning[C]// Proceedings of the 2019 IEEE Region 10 Conference. Piscataway: IEEE, 2019: 2081-2086.
[21] LANZA M, MARINESCU R. Object-Oriented Metrics in Practice: Using Software Metrics to Characterize, Evaluate, and Improve the Design of Object-Oriented Systems[M]. Berlin: Springer, 2006: 115-167.
[22] CHAWLA N V, BOWYER K W, HALL L O, et al. SMOTE: synthetic minority over-sampling technique[J]. Journal of Artificial Intelligence Research, 2002, 16: 321-357.
[23] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [EB/OL]. [2020-12-08]. http://de.arxiv.org/pdf/1409.0473.
Coupling related code smell detection method based on deep learning
SU Shan, ZHANG Yang*, ZHANG Dongwen
(,,050018,)
Heuristic and machine learning based code smell detection methods have been proved to have limitations, and most of these methods focus on the common code smells. In order to solve these problems, a deep learning based method was proposed to detect three relatively rare code smells which are related to coupling, those are Intensive Coupling, Dispersed Coupling and Shotgun Surgery. First, the metrics of three code smells were extracted, and the obtained data were processed. Second, a deep learning model combining Convolutional Neural Network (CNN) and attention mechanism was constructed, and the introduced attention mechanism was able to assign weights to the metric features. The datasets were extracted from 21 open source projects, and the detection methods were validated in 10 open source projects and compared with CNN model. Experimental results show that the proposed model achieves the better performance with the code smell precisions of 93.61% and 99.76% for Intensive Coupling and Dispersed Coupling respectively, and the CNN model achieves the better results with the code smell precision of 98.59% for Shotgun Surgery.
code smell; coupling; deep learning; Convolutional Neural Network (CNN); attention mechanism
This work is partially supported by National Natural Science Foundation of China (61440012), Key Basic Research Project of Hebei Fundamental Research Plan (18960106D).
SU Shan, born in 1995, M. S. candidate. Her research interests include software refactoring.
ZHANG Yang, born in 1980, Ph. D., associate professor. His research interests include intelligent software, software refactoring.
ZHANG Dongwen, born in 1964, Ph. D., professor. Her research interests include intelligent software, software refactoring.
TP311
A
1001-9081(2022)06-1702-06
10.11772/j.issn.1001-9081.2021061403
2021⁃08⁃05;
2021⁃09⁃08;
2021⁃10⁃20。
国家自然科学基金资助项目(61440012);河北省基础研究计划重点基础专项(18960106D)。
苏珊(1995—),女,河北石家庄人,硕士研究生,主要研究方向:软件重构;张杨(1980—),男,河北秦皇岛人,副教授,博士,CCF高级会员,主要研究方向:智能软件、软件重构;张冬雯(1964—),女,河北石家庄人,教授,博士,CCF 会员,主要研究方向:智能软件、软件重构。
