基于Python数据分析的学业预警研究
2022-07-05商惠华戴汇川
商惠华 戴汇川

摘要:为了协助教师改善教学效果,提高教学质量,选取计算机应用基础课程的在线学习成绩为基础数据,经过数据获取、数据预处理、模型构建并进行数据预测等步骤,运用Logistic回归、K最近邻分类算法、分类决策树、朴素贝叶斯、梯度提升分类树、随机森林分类6种经典的机器学习算法分别构建模型,对学生期末成绩进行预测。通过对比真实结果,最后验证LogisticRegression模型最优。运用该模型可对此类课程的学生学业成绩进行预警,进而指导教学的提前重点关注和干预。
关键词:在线学习成绩;数据分析;机器学习算法;成绩预测;学业预警
中圖分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)14-0022-03
1 引言
大数据时代,数据分析的应用已经在各个领域展现出卓越的价值。数据分析在教育领域的应用从不同角度提高了教育教学质量。如今的大学教育已不再局限于传统的教学模式,以翻转课堂为例,将学习知识的主动权交还学生,教师将知识课前传递,以引导为主。在课程教学的过程中,将数据分析的应用贯穿其中,从平时成绩分析中预测学生的总平时成绩和期末考试成绩,根据预测结果,产生预警信息,教师进行提前干预与重点辅导[1],为下一步教师的教和学生的学提供指导。
2 研究思路与流程
研究思路主要流程主要包括5个步骤:数据获取、数据预处理、建模与预测、模型评价与选取、模型的应用与部署[2]。如图1所示。
1)数据获取:是数据分析的工作基础,数据获取主要通过两种方式:本地数据和网络数据,本研究采用本地数据。
2)数据预处理:是指对数据进行数据合并、数据清洗、数据的标准化等,满足后续建模分析的需要[3]。
3)训练模型与预测:通过聚类模型、分类模型、回归模型等模型与算法构建模型,对数据进行分析,并进行数据的预测。
4)模型的评价与优化:是根据模型的类别,使用不同的指标评价其性能优劣的过程。常用的聚类模型的评价指标有AMI评价法、FMI评价法、ARI评价法等。常用分类模型评价指标有Accuracy(准确率)、Precision(精确率)、Recall(召回率)、F1 Value(F1值)等。常用的回归模型评价指标有平均绝对误差、均方差、中值绝对误差等。通过对比,选取评价指标最好的模型。
5)模型的应用与部署:是指将数据分析结果与结论应用于实际的教学过程中,进行学业预警。
3 研究设计
3.1 数据采集及研究对象
选取某师范学院2021~2022学年度第2学期期末的计算机应用基础考试成绩为研究数据。计算机应用基础是该校必修的公共课,在大一的第一学期开设,课程的平时成绩依托超星网络平台运行,采用翻转课堂的方式教学,共32学时,其中16学时为线上学习时间,16学时为重点内容讲解及答疑时间。数据的样本总量为3933条数据,即3933个学生的平时成绩记录及考试成绩记录。学生的平时成绩和考试成绩均采用百分制,最终的期末总评成绩为平时成绩和期末考试成绩各占50%。
研究数据的读取与分析过程均在Jupyter notebook环境中完成,使用Python编程语言,研究目的将主要围绕三个问题展开[4]:
1)在线平时成绩数据选项中,哪些选项对学生之间的差距影响大,哪些影响不大?
2)依据在线平时成绩,用哪种分析方法可相对准确地判断期末考试成绩的及格状况?
3)依据在线平时成绩,如何在期末考试前对学业预警?
3.2 研究算法
采用多种数据分析方法进行建模,并将模型的评价结果进行对比分析,选取最佳模型对学生的平时成绩进行预测。为教与学分别提供指导意见。文中的算法均使用sklearn下的模块。
1)logistic回归
logistic回归分类的主要思想是根据现有数据对分类边界线建立回归公式,以此进行分类。训练分类器时的做法及时寻找最佳拟合参数,使用的是最优化算法。目标函数应该能接受所有的输入,预测出类别。在两个类的情况下,函数输出0和1,该函数就是二值型输出分类器的sigmoid函数[5]:
此文中数据分析应用模块linear_model下的LogisticRegression函数。
2)KNN(K最近邻分类)算法
KNN算法的思想是:如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特征。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别[1],比较适合对于类域的交叉或重叠较多的待分类样本集。
此文中数据分析应用模块neighbors的KNeighborsClassifier函数。
3)分类决策树
决策树是一种树形结构预测模型,表示基于特征对实例进行分类的过程。构造决策树的首要问题是当前数据集上哪个特征在划分数据分类时起决定性作用。为了找到决定性的特征,划分出最好的结果,必须评估每个特征。完成测试之后,原始数据集就被划分为几个数据子集。这些数据子集分布在第一个决策点的所有分支上。再根据某个分支下的数据属于同一类型,无须进一步对数据集进行分割。如果数据子集内的数据不属于同一类型,则需要重复划分数据子集的过程。直到所有具有相同类型的数据均在一个数据子集内[6]。决策树算法很多,例如:ID3、C4.5、CART等。
此文中数据分析应用模块tree的 DecisionTreeClassifier函数。
4)朴素贝叶斯
贝叶斯决策理论以概率为基础的,朴素贝叶斯分类是贝叶斯决策理论的一部分,思想是基于条件概率的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个概率值大,则该分类项属于哪一类。F8016F3D-6810-4DD3-B089-F442405FF70C
此文中数据分析应用模块naive_bayes下的GaussianNB函数。
5)梯度提升分类树
梯度提升分类树是一种迭代的决策树算法,由多棵决策树组成,所有树的结论累加起来做最终答案。关键是利用损失函数的负梯度在当前模型的值作为回归问题提升树算法中的残差的近似值,拟合一个回归树[6]。
此文中数据分析应用模块ensemble下的GradientBoostingClassifier函数。
6)随机森林分类
随机森林分类是决策树的组合,每棵决策树都通过对原始数據集中随机生成新的数据集来训练生成,随机森林分类的结果是多数决策树决策的结果。
此文中数据分析应用模块ensemble下的RandomForestClassifier函数。
4 数据分析过程
4.1 数据的读取及变量的选取
将3933条学生的平时成绩和考试成绩整理到一张EXCEL表中,用Pandas模块的read_excel函数将数据读出。学生的平时成绩包括课程音视频、章节测验、章节学习次数、讨论、作业、测试考试、签到、课程互动,共8项。
4.2 数据预处理
首先,查询成绩表中平时总成绩为一位数(即不足10分)的记录,直接删除。这些记录存在重修免听课等特殊情况。
其次,寻找数据差异最大的选项。平时成绩均相同的计量单位,采用方差来统计各项平均值的离散程度,得出对平时成绩影响最大的几个选项。结论如表1所示,分别为测试考试、作业、章节测试三项。该三列的数据,在后面的数据分析中重点选取。
4.3 训练集和测试集的划分
sklearn库集合了多种机器学习算法,在数据分析过程中快速建立模型,且模型接口统一,使用起来非常方便。此研究中,在数据集的划分上使用model_selection模型选择模块,将传入的数据划分为训练集和测试集[2],使用train_test_split函数,其中test_size参数值取0.3。
4.4 对数据进行标准化的预处理
平时成绩的各项的百分比占比不同,为消除特征之间取值范围差异可能造成的影响,对数据进行标准化处理,此处采用标准差标准化的方法。使用sklearn库的preprocessing数据预处理模块的StandardScaler函数。
基础代码为:
from sklearn.preprocessing import StandardScaler
sca = StandardScaler().fit(data_train)
sca_train = sca.transform(data_train)
sca_test = sca.transform(data_test)
4.5 模型的构建与预测
构建模型与预测的目的是根据学生的平时成绩,对最后的期末考试成绩做出预测,将期末考试成绩根据是否及格分别备注为1和0(1表示及格,0表示不及格)。根据预测类型,构建模型为分类模型。
构建了几种分类模型,进行预测,并分别给出了相应的评价指标对预测模型的性能进行评价,这些指标主要包括精确率(Pricision),准确性(Accuracy),召回率(Recall)和F1值(f1-score)。以下以逻辑斯蒂回归算法为例:
利用sklearn库的linear_model模块LogisticRegression函数,建立模型,如图2所示,预测训练集的结果(取前50个),如图3所示。
基本代码如下:
from sklearn.linear_model import LogisticRegression
log = LogisticRegression().fit(sca_train,target_train)
print('建立的linear_model模型:\n',log)
#预测结果
sca_target_pred_log = log.predict(sca_test)
print('预测的前50个结果为:\n ',sca_target_pred_log[:50])
4.6 评价指标的选取
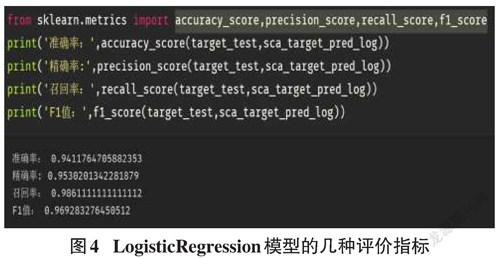
为了有效判断一个预测模型的性能表现,需要结合真实值计算出准确率、精确率、召回率、F1值等指标来衡量。以LogisticRegression模型为例,利用sklearn库的metrics模块中的accuracy_score,precision_score,recall_score,f1_score几个函数,代码及运行的结果如图4所示,几种评价指标都比较接近最佳值1.0,该模型效果较好。
4.7 模型的结果对比分析
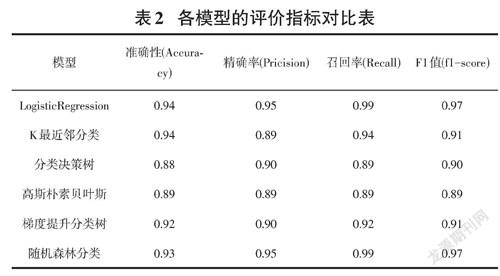
用类似的方法,又构建了其他的几种模型,并分别通过评价系数进行对比,找出最优的模型。各模型的评价指标对比分析如表2所示。
通过各种模型的评价指标的对比,可以分析得出, LogisticRegression模型最优,随机森林分类也较好,各项系数也接近于1.0。
根据分类模型和评价参数,教师可以根据学生在临近学期末的学习成绩进行预测,对可能期末成绩低于60分的同学进行提前干预,给予这部分同学个别的知识辅导或提醒,并督促这部分同学抓紧学习,可实现基于在线平时成绩的期末总评成绩的提前预警。
5 结束语
以大学计算机应用基础课程为例,对依据超星学习平台的在线学习平时成绩的数据对影响学生期末总评成绩进行了具体分析,主要解决了三个具体问题:F8016F3D-6810-4DD3-B089-F442405FF70C
1)在线学习平时成绩的8项数据中,通过分析可得出,学生相差比较大的选项是测试考试、作业、章节测试三项,其他选项相差不大。在针对学生的个别预警中要重点关注。
2)在多种模型的应用中,通过对比各种模型的评价指标,可以分析出Logistic Regression模型最优,随机森林分类也较好。针对类似的成绩分析,可采用这两种模型来分析和预测。
3)应用上述的两种模型,依据在线的平时成绩各选项的预测,教师可进行过程管控、预警,进而重点关注,教学干预[7]。
大数据时代,教师作为信息化教学的主导者和实施者,为了更好地了解课程、教学及学生学习等状况[8],除应用现代化的教学方式外,应用现代化的技术和工具对教育数据进行分析,发现其规律并为教学提供帮助,将有利于教学质量的进一步提高。
参考文献:
[1] 喻佳,白舒伊,吴丹新.基于机器学习的在线教学学生成绩预测研究[J].电脑编程技巧与维护,2021(8):118-119,154.
[2] 黄红梅,张良均.Python数据分析与应用[M].北京:人民邮电出版社,2018.
[3] 张运玉.基于Python的数据分析的研究[J].电脑知识与技术,2019,15(30):3-4.
[4] 熊思灿,农莹.在线学习数据与学生学习成绩的相关性分析——以大学概率论课程为例[J].西南师范大学学报(自然科学版),2021,46(11):84-89.
[5] 柳毅.Python数据分析与实践[M].北京:清华大学出版社,2019:249-255.
[6] 石胜飞.大数据分析与挖掘[M].北京:人民邮电出版社,2018.
[7] 宋丹,刘洞波,丰霞.基于多源数据分析的课程成绩预测与课程预警研究[J].高等工程教育研究,2020(1):189-194.
[8] 彭煥卜,谢志昆.基于Python的学习者基本数据分析与可视化研究[J].中国教育信息化,2021(15):60-64.
收稿日期:2022-03-09
基金项目:潮州市科技计划项目(项目编号:2019ZC12);韩山师范学院科研项目-理科(项目编号:XN201924)
作者简介:商惠华(1978—),女,河北沧州人,讲师,硕士,主要研究方向为数据分析、计算机软件与理论;戴汇川(1977—),男,湖北黄冈人,高级工程师,博士,主要研究方向为现代质量管理、物流信息技术。F8016F3D-6810-4DD3-B089-F442405FF70C
