基于COG、Hadoop和 Spark的海量影像快速可视化共享方法
2022-07-04杨立业
杨立业
(甘肃省基础地理信息中心,甘肃 兰州 730000)
1 引言
随着国产卫星技术的快速发展,高分辨率卫星影像数据获取能力大幅提升。以甘肃省为例,全省范围2m分辨率卫星影像一季度可覆盖一次,月覆盖率达到90%以上,0.8m分辨率卫星影像一年可覆盖一次。丰富的遥感影像为政府部门和各行业、科研院所等提供了及时、可靠的数据基础。遥感影像数据的丰富应用场景对海量影像数据的快速可视化提出了较强的需求。为更好地管理和共享海量遥感数据, 国内研究者做了大量的基础研究[1-3]。
目前,海量影像可视化共享主要是通过预生成影像地图瓦片等方式实现。影像数据基于网络端的在线浏览方式主要为地图瓦片服务[4]。地图瓦片服务分为影像地图瓦片预生成和影像地图瓦片动态创建两种方式。其中,影像地图瓦片预生成方式是构建影像地图瓦片服务的主要方式[5-6],此方法具有更快的浏览响应速度,缺点是需要较长时间的线下预处理过程,且不支持动态波段组合显示、数据更新效率低;影像地图瓦片动态创建方式是根据客户端发出的请求,以实时在线方式生成影像地图瓦片,适合在数据持续更新的情况下使用,但存在浏览响应速度慢、占用在线计算资源较多等缺点[7]。上述海量影像可视化共享方式存在预处理时间长、时效性差、不支持动态波段组合显示、商业软件投入成本大、在线计算资源多等问题。
为解决上述问题,本文提出了基于Cloud Optimized GeoTIFF技术、Hadoop分布式存储技术和Spark并行运算技术,实现了海量影像的快速可视化显示,并支持动态波段组合显示,数据更新效率明显提升。
2 具体实现方法
2.1 关键技术
COG,即云优化 GeoTIFF格式, 是为了解决GeoTIFF文件在云存储中读写性能的问题,而对GeoTIFF格式进行了优化。它具有高效地提取GeoTIFF文件中的子区域的特性[8]。COG是规则化的GeoTIFF文件,将概览等元数据信息添加到普通的GeoTIFF文件, COG技术实现了GeoTIFF文件的优化云端处理,通过优化的概览元数据信息,可以快速定位和读取指定范围的局部影像数据块,可大幅提高海量遥感影像数据的读取性能。
Hadoop提供了一个分布式文件系统(HDFS)[9]。通过HDFS可使用廉价计算机设备搭建集群,解决海量遥感影像高并发请求访问时磁盘I/O性能瓶颈。
Spark 是一种基于内存的分布式计算框架,核心是图计算和数据流的快速处理,但其本身并不具备直接处理遥感影像数据的能力[10]。文献[10]主要研究了面向Spark计算框架的遥感影像金字塔模型构建方法及其数据存储组织结构,解决了遥感影像的即时计算处理效率及分布式存储优化,实现了影像的动态渲染。本文在此研究基础上,采用遥感影像COG网格模型优化遥感影像的数据存储和组织结构,利用Spark加速影像COG网格模型的构建过程、影像瓦片数据的局部读取和基于波段信息的动态渲染过程。影像COG网格模型的构建过程主要是对遥感影像数据进行重采样,根据网格模型将其分割成COG文件,并存储到Hadoop集群的HDFS文件系统中。影像瓦片读取和动态渲染过程主要是从HDFS中存储的COG文件中读取局部影像数据块,并根据波段组合动态渲染成PNG图片。与基于Hadoop MapReduce的遥感影像金字塔模型的构建效率相比,Spark 可以将原始影像数据集转成RDD,并将计算处理后的中间结果保存在内存中,减少了影像数据的 I/O 次数,大幅提高了遥感影像处理速度。
2.2 基于Spark的影像COG网格模型构建及存储
基于Spark的影像COG网格模型是一种利用弹性数据集RDD来处理海量遥感数据的模型。影像COG网格模型的构建过程中会顾及影像数据的分层和影像数据的分块,其最大分层数是根据原始遥感影像的分辨率大小确定的。将原始遥感影像切分成大小相等的COG文件,进而根据最大分层数及每层的网格元数据构建网格模型,建立多分辨率层次影像COG网格文件并存储到HDFS分布式文件系统中。
传统的遥感影像瓦片金字塔模型构建,是先将原始影像按照一定的规则切割成大小相等的一系列瓦片,形成最底层级的瓦片数据,然后通过数据抽稀和瓦片合并,形成上一层影像数据,循环操作,直到单层瓦片的个数小于4则完成影像金字塔构建[11-12]。与传统的构建影像金字塔模型相比,本文提出的面向 Spark 的影像COG网格模型的构建策略,大大减少了影像金字塔分层级数和影像切片数量,计算量也会大大减少,解决了遥感影像的分布式切片问题。具体实现流程如图1所示。
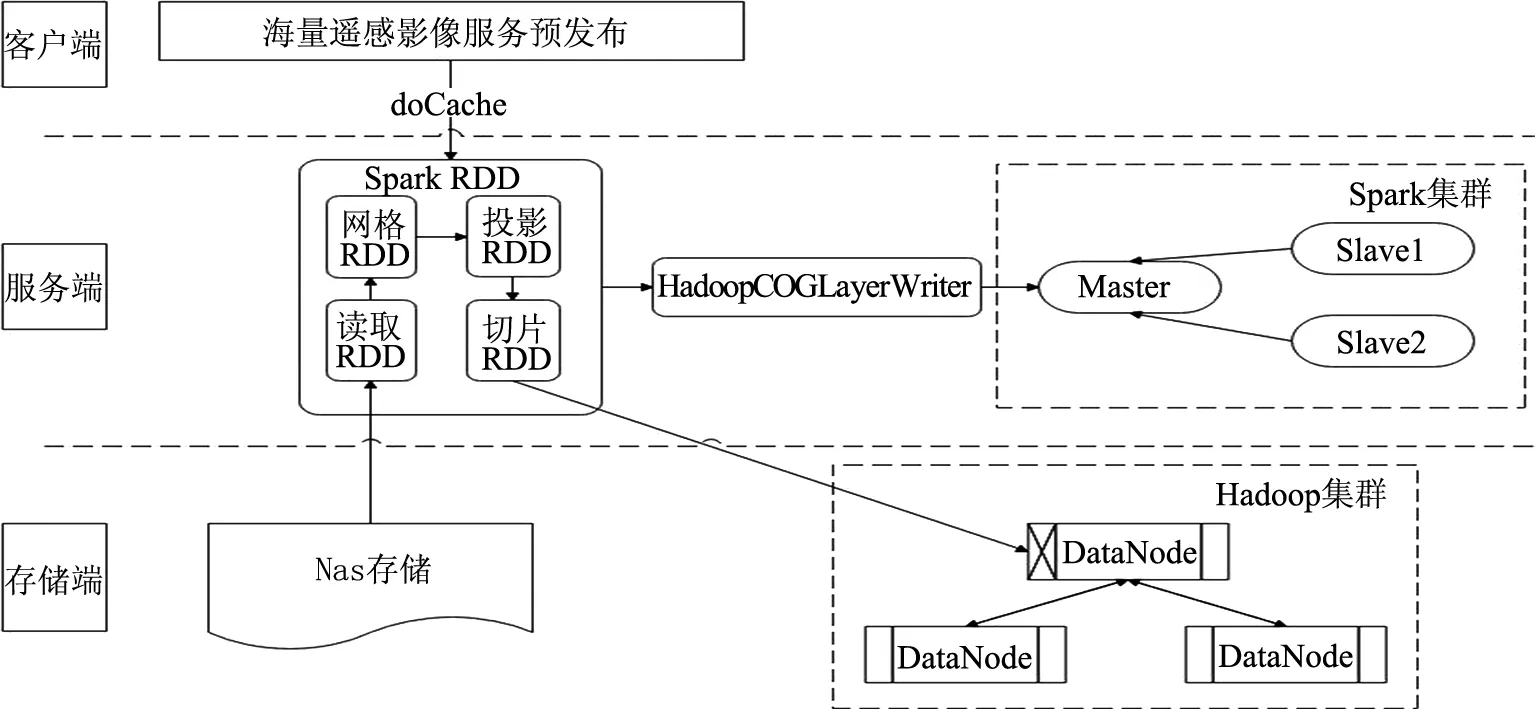
图1 基于Spark的影像COG网格模型构建
未使用COG技术时,Geotrellis通过ETL操作实现对数据的处理,将数据推送到后端Hadoop中,形成Layer的概念,实际上在后端Hadoop中存储的是不同层级的大量小瓦片,然后再根据请求读出相应的瓦片进行处理。
在Geotrellis中使用COG技术,将GeoTIFF文件转换为COG文件,在转换的过程中生成对应的元数据,在元数据里描述的是如何找到请求对应的包括文件名称、存储位置、数据范围(HTTP Range)等数据信息,可以精准快速的请求到此数据,并支持对请求到的数据进行其他处理。不仅解决了瓦片数据读取性能和耗费存储空间的问题,也解决了瓦片生成耗时长等问题,大幅缩短了数据处理时间,并提高了瓦片请求访问效率。
具体实例如下所述:
(1)输入已有影像,如图2所示;

图2 示例影像数据
(2)通过sc.hadoopMultibandGeoTiffRDD(inputPath)创建影像读取的RDD;
(3)使用ZoomedLayoutScheme指定瓦片金字塔规则,WebMercator代表Web墨卡托投影,tilesize代表瓦片大小256*256;
(4)使用reproject将原始影像空间参考投影到Web墨卡托;
(5)通过HadoopCOGLayerWriter创建COG格式影像块存储写操作;
(6)通过COGLayer.fromLayerRDD创建COG图层和图层元数据信息;
(7)通过ZCurveKeyIndexMethod设置每层COG影像块文件命名规则采用Z曲线网格编码算法,如图3所示;

图3 COG影像块文件命名规则Z曲线网格编码
(8)通过writer.writeCOGLayer方法启动Spark算子执行COG裁切;
(9)实现效果图,代码执行后数据COG目录组织格式,如图4所示;
(10)COG文件的命名规则如图5所示。
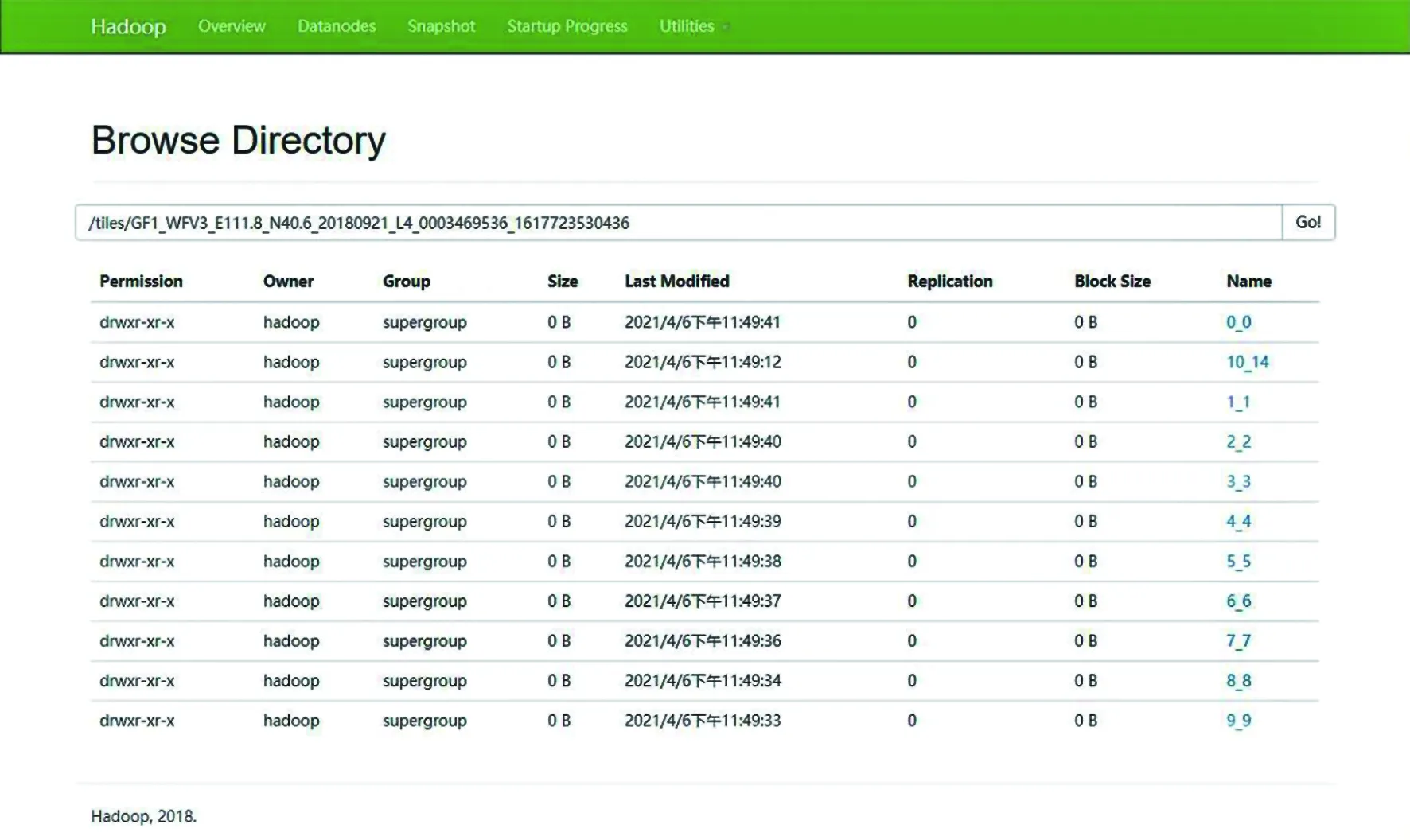
图4 COG影像目录组织格式
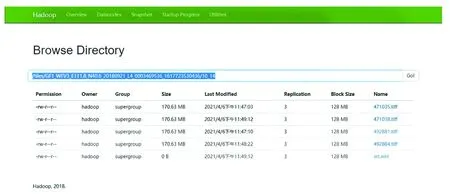
图5 COG文件命名规则
2.3 基于Spark的影像瓦片动态渲染
基于Spark的弹性数据集RDD分布式计算能力,可快速实现影像瓦片数据读取和动态渲染,主要是从存储在HDFS中的COG文件中读取局部影像数据块并根据波段组合信息动态渲染成PNG图片。
浏览器端通过WMTS协议请求影像时,将图层名、级别、行号、列号和波段组合信息发送到服务端,服务端程序接收到请求后会调动Spark集群根据图层名、级别、行号和列号快速查找和定位到HDFS中存储的COG文件,并只读取传入的瓦片范围区域内的局部栅格数据块MultibandTile,将MultibandTile和bands组合信息传送到PNG渲染程序,将MultibandTile数据块根据bands信息重新波段组合,生成新的MultibandTile数据块,然后将各波段赋予R、G、B值生成PNG格式数据流返回给浏览器端,完成数据请求和动态渲染过程。请求流程如图6所示。
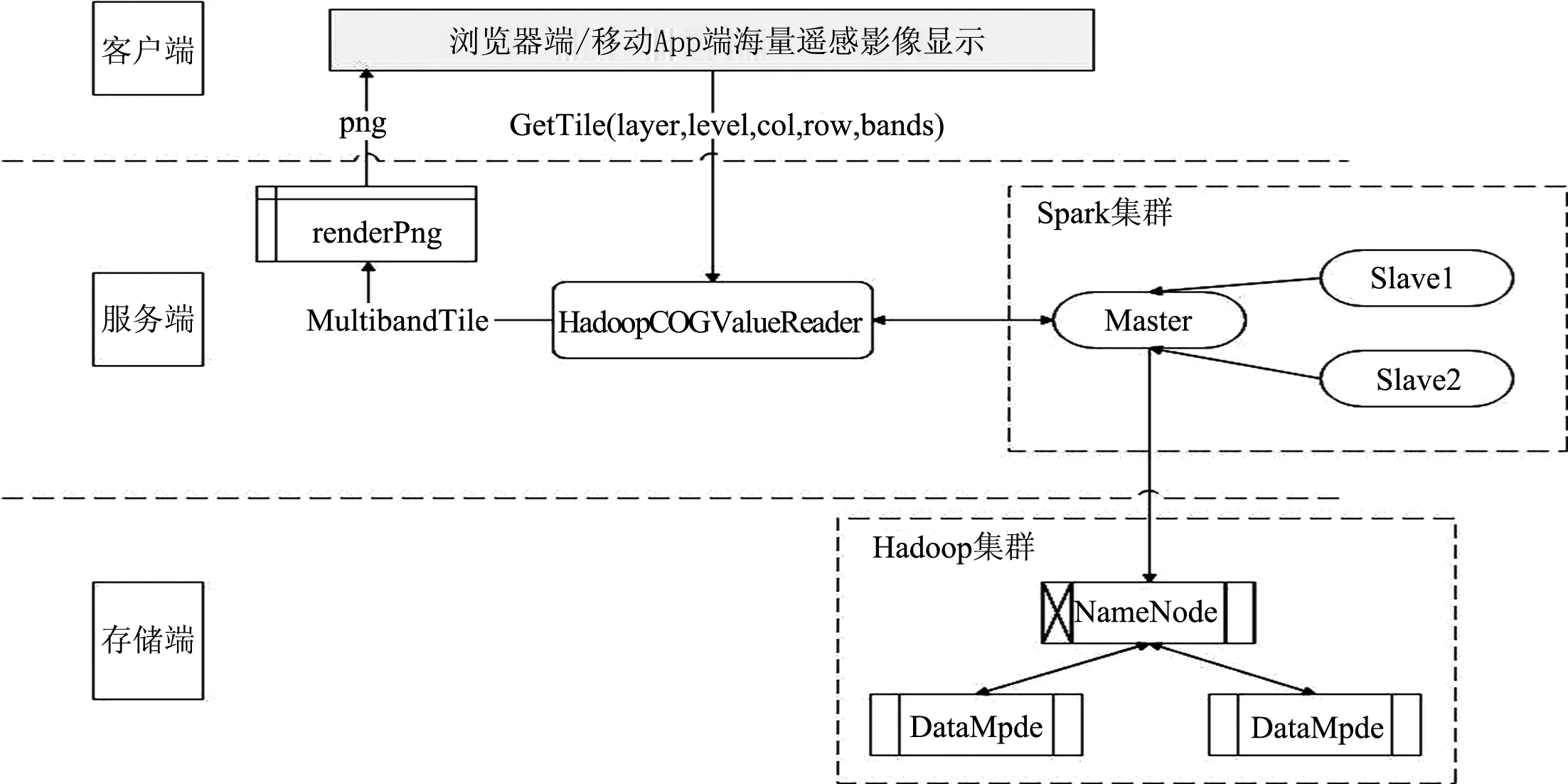
图6 基于Spark的影像瓦片动态渲染请求流程图
3 应用验证
以甘肃省2019年全省第三季度2m分辨率影像为例,影像数据含金字塔数据量约1TB。COG数据入库约90min,影像数据入库即发布为WMTS服务,满屏按波段任意组合、动态渲染处理和显示时间≤2s。传统ArcGIS Server发布静态切片需要20多小时,并且静态切片不支持波段组合。
影像数据按波段组合动态渲染输出显示效果如图7-图9所示。

图7 按波段组合动态渲染输出效果图(1,2,3波段组合)

图8 按波段组合动态渲染输出效果图(2,1,3波段组合)

图9 按波段组合动态渲染输出效果图(单波段)
4 结束语
综合应用COG、Hadoop和 Spark技术,实现了影像快速可视化及共享,经应用验证,其大幅提升了从影像数据到发布成可视化的影像服务的效率,并实现了按波段组合动态渲染,因此该技术方法比较适用于海量影像的数据可视化共享。
