基于Transformer结构的多目标追踪算法研究综述
2022-07-04曾文献李伟光李岳松
曾文献,李伟光,马 月,李岳松
(河北经贸大学信息技术学院,河北 石家庄 050061)
0 引言
多目标追踪MOT(Multiple-Object Tracking)是指在视频序列中进行目标检测、特征提取并对帧间数据关联与匹配从而得到多个目标的运动轨迹[1]。随着深度学习的发展,基于深度学习的MOT方法在自动驾驶[2]、自动监控[3]、行人追踪[4]、车辆追踪[5]等领域得到了广泛应用,但是MOT仍然存在在场景复杂、遮挡、目标轨迹重叠[6]、目标像素值过小、目标密集等特定场景下准确度低、误检漏检等问题。随着Transformer网络结构成功应用于MOT,与基于卷积神经网络CNN(Convolutional Neural Network)的方法相比,性能指标得到大幅提升。本文分析Transformer结构,总结优势,对基于Transformer结构的MOT方法进行分类分析和性能指标对比,提出基于Transformer结构在MOT上面临的挑战以及未来发展趋势。
1 Transformer网络结构
Transformer网络结构[7]由谷歌公司于2017年提出并应用于自然语言处理NLP(Natural Language Processing)领域。作为一种新型骨干网络,Transformer网络逐渐成为NLP领域的研究热点,并随着迁移学习的发展在图像处理领域已经获得良好效果。
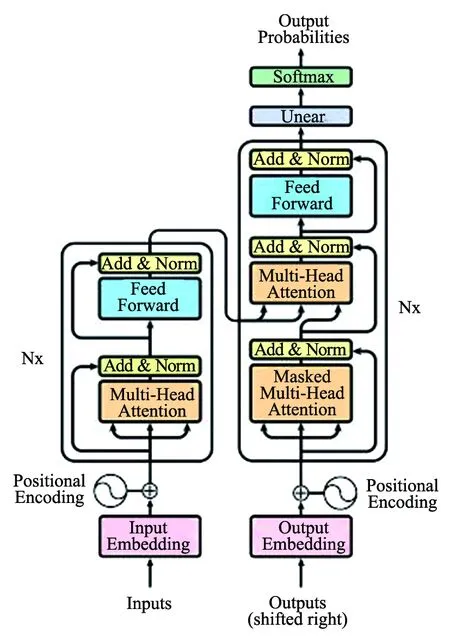
图1 Transformer模块结构图
1.1 编码器-解码器结构
Transformer网络由6个相同的编码器块与6个相同的解码器块组成,模块结构如图1所示。
Transformer编码器块由多头注意力层和前馈神经网络组成,解码器块由多头注意力层、带掩码的多头注意力层和前馈神经网络组成。Transformer使用带掩码的多头注意力机制将未知信息掩盖,避免模型在训练过程中参考未知后续信息。为了适应处理不定长输入序列任务与提升网络稳定性,Transformer采用层归一化LN(Layer Normal)[8]操作。提出使用位置编码解决Transformer无法像RNN和CNN结构一样获取输入元素之间的位置信息的问题,Transformer使用三角函数进行位置编码,如公式(1)所示。
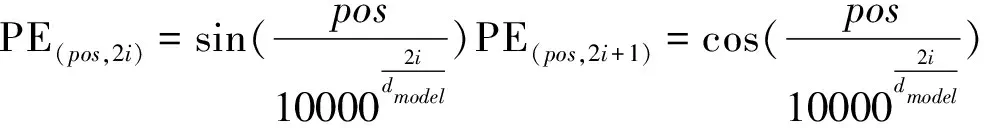
(1)
1.2 注意力机制
Transformer结构采用的多头注意力机制使模型在不同子层空间中学习到不同语义特征,在投影过程中调整权重和不同的投影方法,使模型更具泛化性。多头注意力机制计算公式如公式(2)和公式(3)所示。
MultiHead(Q,K,V)=Concat(head1,…,headh)Wo
(2)
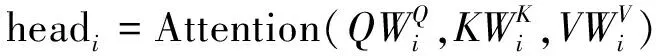
(3)
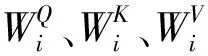
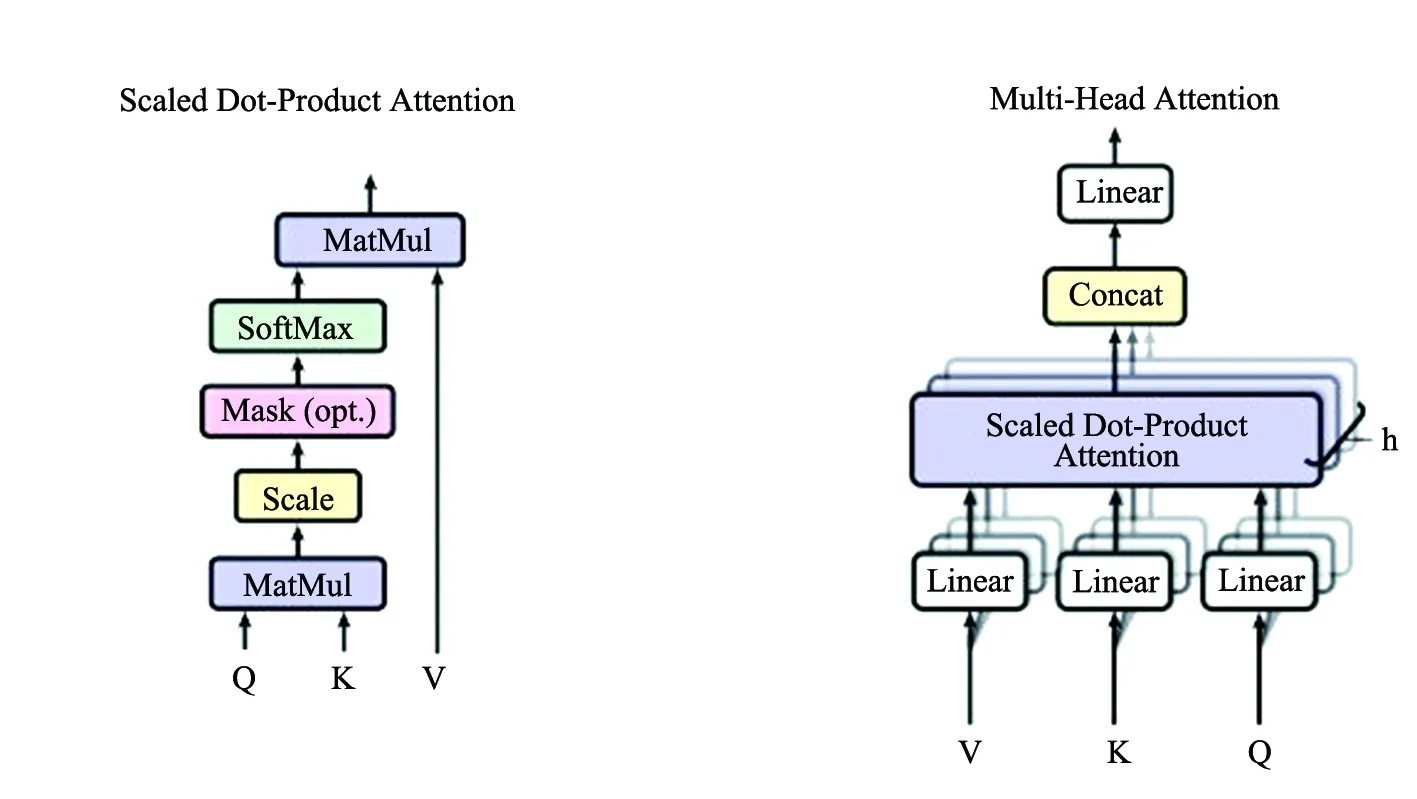
图2 Transformer中的点积注意力机制
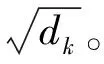
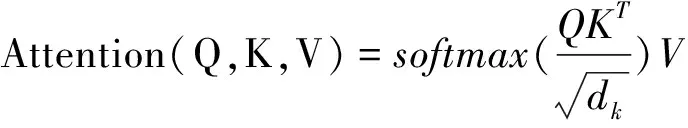
(4)
1.3 Transformer优势
相较于NLP领域经典网络循环神经网络RNN(Recurrent Neural Network),Transformer直接处理句子整体,建立长距离依赖,避免线性序列结构与递归计算方式,模块中注意力机制和前馈神经网络允许并行计算。因此,Transformer网络训练时间与预测时间都大幅降低,准确率得以提升。
在计算机视觉领域通常采用卷积神经网络CNN(Convolutional Neural Networks)作为骨干网络,目前已有众多基于CNN结构的模型用于处理多目标跟踪任务[9-10],实现了端到端MOT网络[11]与实时MOT网络[12]。虽然CNN网络在MOT任务上取得SOTA效果,但是CNN存在卷积操作缺乏对图像的全局理解,无法形成建模特征之间的依赖,上下文信息利用不足且权重固定,不能适应动态输入等缺点。因此,有大量研究将Transformer研究成果迁移到图像处理领域[13-15],且使MOT性能得到多方面提升。
在MOT领域Transformer相较于CNN结构具有的优势:
(1)有效学习长距离关系。CNN学习全局信息时需要经过多级卷积核计算,学习不同位置的信息所需要的操作次数与距离长度成正比。Transformer结构可以直接学习长距离关系,不需要隐层传递,更适合实时MOT任务计算。
(2)网络结构灵活。卷积神经网络在进行卷积和池化操作时容易丢失部分信息,且网络精度提升需要更深层次的网络结构。Transformer结构块输入输出向量维度相同,易于搭建深层架构,提升MOT准确度。
新经济形态下,数字化、信息化是各行各业发展的重要趋势。在建筑工程领域,BIM技术是其数字化应用的基本形态;在BIM技术支撑下,建筑工程项目信息管理的方式得以系统转变,其在同一平台上实现了建筑工程各利益方的信息交互与共享,有效的提升了信息管理、信息决策的效率和质量。新时期,要实现工程项目信息管理质量的提升,保证工程建设效益获得,进行深层次的BIM技术应用势在必行。基于此,本文就BIM在项目信息管理中的应用展开分析。
(3)更具可解释性。Transformer结构便于查看注意力分布,结构块中的多头注意力机制可以投影到不同子层空间,提取MOT任务中更有效的特征信息。
(4)更适合处理多模态任务。卷积神经网络结构常被用来处理图片视频等多媒体信息,但不擅长与文字等信息结合处理。Transformer结构可以使用编码后的图片和文字等信息作为输入,擅长融合多类多媒体信息[16],通过多传感器信息融合进一步提升MOT精度。
2 基于Transformer的多目标追踪模型
2.1 基于稀疏查询方式
2.1.1 TransTrack
文献[17]提出TransTrack网络,首次将Transformer结构应用于MOT任务。引入可学习目标查询序列LOQ(Learned Object Queries)查询检测框,保存当前帧中的目标OD(Object Detection)特征,以减少将单目标追踪SOT(Single-Object Tracking)网络应用于MOT任务时存在的目标漏检情况。使用对象特征查询OFQ(Object Feature Queries)记录目标历史位置、外观等信息并查询跟踪框。TransTrack进行多目标追踪时序图如图3所示。Backbone块使用ResNet网络提取当前帧的目标特征,经过Encoder块编码处理得到Key向量集合。Decoder块分别使用LOQ和OFQ对Key查询得到当前帧中目标和目标轨迹,应用Kuhn-Munkres算法的IoU标准进行相同目标匹配。
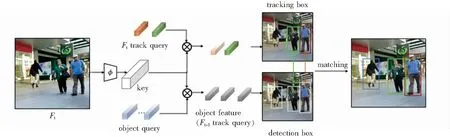
图3 TransTrack进行多目标追踪时序图
TransTrack虽然在MOT任务取得SOTA的成绩,但其还存在很多问题:(1)TransTrack存在数据链接匹配计算IoU过程,并不是一个端到端的模型。(2)对于LOQ和OFQ存在特征信息冗余,可以通过对OFQ进行变换与LOQ进行融合。(3)TransTrack无法利用历史特征信息。(4)对于遮挡和重复检测等问题未做处理。
2.1.2 TrackFormer
Meinhardt T等人将MOT任务定义为一个帧到帧的集合预测问题,提出基于tracking-by-attention范式的TrackFormer网络[18]。将注意力机制作用于数据关联和检测追踪,避免对于外观特征等信息的依赖,实现了轨迹隐式关联。TrackFormer进行多目标跟踪时序图如图4所示。
图4 TrackFormer进行多目标追踪时序图
TrackFormer提出一种同时在时间和空间上对目标进行检测追踪的方法track query,通过自注意力机制,将轨迹查询特征变换到可学习目标查询特征空间,与TransTrack相比,实现了可学习目标查询与轨迹查询特征融合。由于TrackFormer网络特征提取不充分,存在大量误检与ID切换情况,提取高鉴别性特征可以进一步提升网络精度。
2.1.3 MOTR
MOTR[1]将目标检测端到端网络DETR[19]扩展到MOT领域,提出Track Query方法结合轨迹标签感知策略TALA(Tracklet-Aware Label Assignment)实现目标跟踪, MOTR网络整体结构如图5所示。
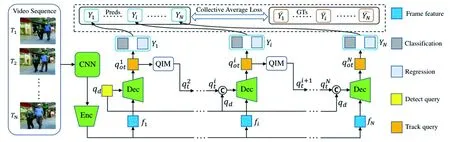
图5 MOTR整体结构图
为增强长期时间关系建模能力,MOTR提出集体平均损失CAL(Collective Average Loss)与时间聚集网络TAN(Temporal Aggregation Network)。CAL使用视频序列整体损失更新权重,充分利用历史信息。TAN收集跟踪对象的历史track queries,将历史信息与当前帧信息首次结合输入到多头注意力模块,进行权重更新。TAN计算公式如下:
(5)
MOTR是第一个基于Transformer结构的完全端到端MOT神经网络,对目标实现隐式关联,逐帧更新迭代预测轨迹信息,实现学习数据时间变化信息。
2.2 基于密集查询方式
Xu Y等人受基于锚点方式的MOT任务解决网络[20]的启发,提出了第一个基于Transformer结构应用像素级密集多尺度热力图检测跟踪的网络TransCenter[21]。TransCenter整体采用孪生网络结构,使用相邻两帧图像作为输入,通过共享权重的CNN与Encoder提取特征,当前帧Mt经过查询学习网络(QLN)得到多尺度图像特征DQt,由Decoder解码得到当前帧多尺度检测特征DFt。前一帧热力图、Mt-1和Mt经过处理进行位移预测。网络结构如图6所示。
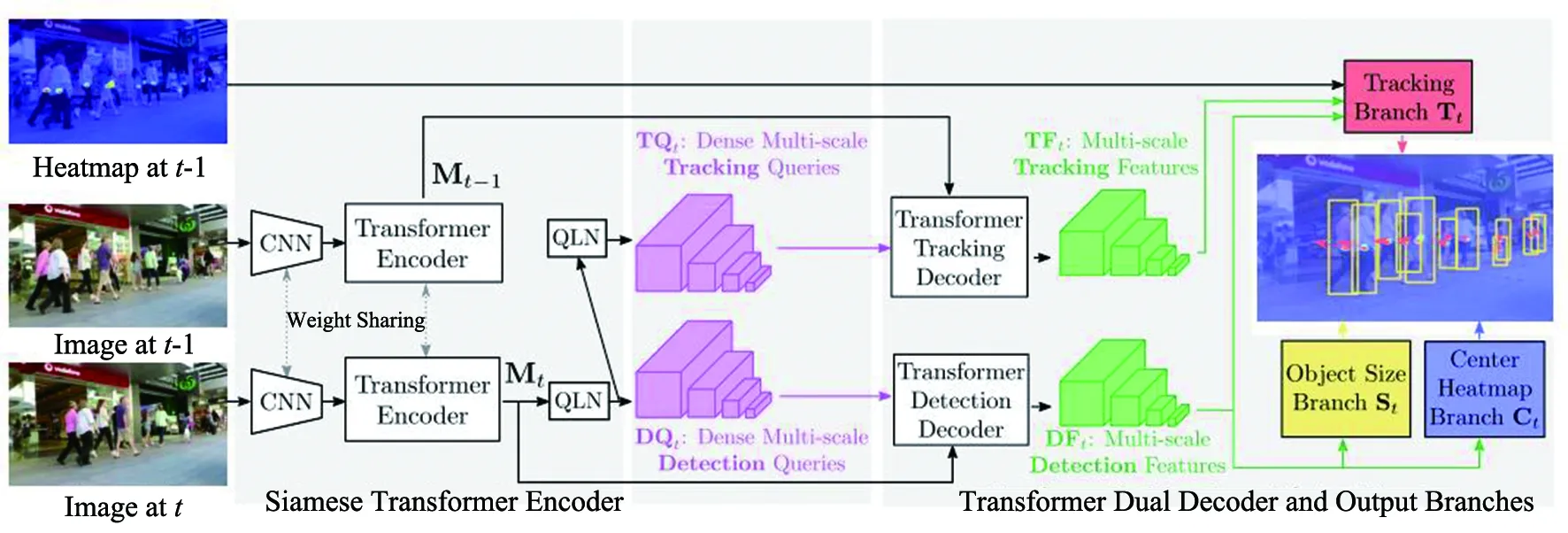
图6 TransCenter网络结构图
TransTrack和TrackFormer网络基于边界框Bbox(Bounding box)进行检测与跟踪,在目标密集场景下容易受目标重叠影响,为解决这一问题,TransCenter使用二维高斯分布表示目标,对于目标密集数据可以获得更好的追踪效果。相较于朴素密集查询,TransCenter自适应输入图像像素大小,无需重复训练,避免采用匈牙利算法匹配与人工设计queries大小,节省计算时间,并且受噪声干扰更小。
3 MOT常用数据集
多目标跟踪常用数据集MOT16、17等数据集由MOTChallenge平台发布。
MOT15数据集[22]:共包含11个视频训练数据集和11个测试数据集。包括多角度与无约束条件下由静态或动态相机拍摄的视频序列。
MOT16数据集[23]:共包含7个视频训练数据集和7个测试数据集,MOT16数据集为全新收集的数据集。对比MOT15数据集训练集和测试集行人密度为7.3和10.6,MOT16数据集的训练集和测试集的目标密度分别达到20.8和30.8,使检测与跟踪任务更具有挑战性。
MOT17数据集:与MOT16数据集使用相同视频序列,但提供多种检测器。
MOT20数据集[24]:共包含4个视频训练数据集和4个测试数据集,在非约束条件环境下拍摄,具有更精确的标注,同时测试数据集和训练数据集精度分别达到了149.7和170.9,适用于拥挤场景。
除MOT系列数据集,KITTI数据集[25]提供汽车与行人标注的数据;ETHZ数据集[26]通过车载摄像头采集,视频帧率为13-14fps;EPFL数据集[27]提供多种场景下的视频序列,拍摄角度均为离地面2m左右角度。
4 模型性能对比
多目标跟踪任务常用的性能评价指标有:多目标跟踪精度MOTA(Multiple-Object Tracking Accuracy)、身份F1分数IDF1(Identity F1 Score)、命中轨迹占比MT(Mostly Tracked Trajectories)、丢失轨迹占比ML(Mostly Lost Trajectories)误检测数量FP(False Postive)、未命中检测数量FN(False Negetive)、身份ID切换次数IDS(Identity Switches)。其中,多目标跟踪精度MOTA为衡量模型追踪质量与性能的主要指标。MOTA计算见公式(6),其中t表示视频帧时刻。
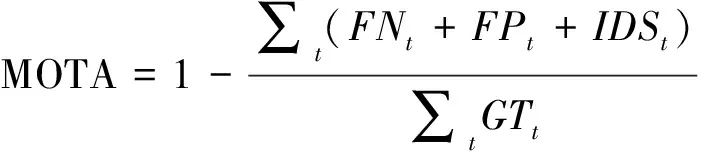
(6)
TransTrack、TrackFormer、MOTR、TransCenter在以上数据集上实验,实验结果对比如表1所示。
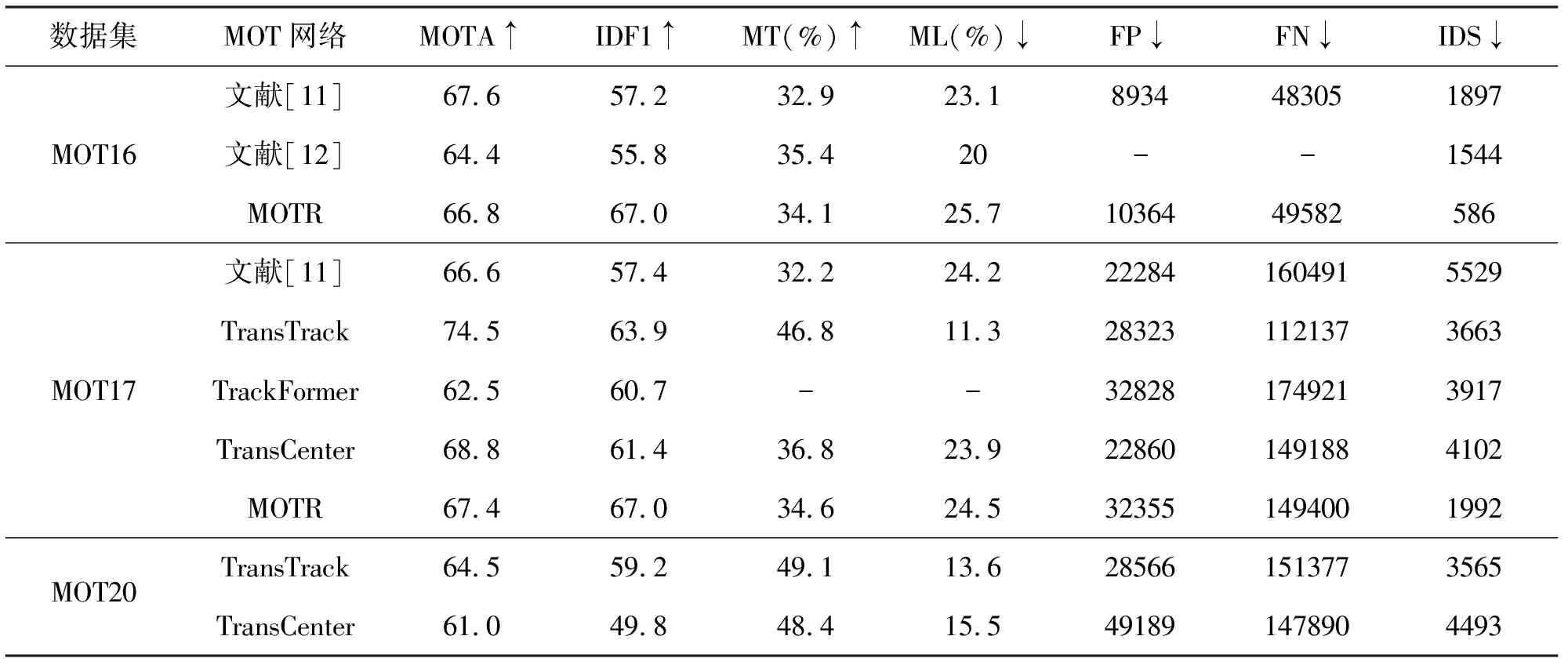
表1 不同模型在数据集上实验结果对比
基于MOT16、17、20数据集得到的MOTA指标均达到60%以上,TransTrack在JDE范式下同时优化检测与跟踪分支,在MOTA指标上有较大提升,但仍需要使用匈牙利算法进行数据关联。TrackFormer网络提出的TBA范式检测追踪避免了对外观等特征的依赖,实现了隐式的多帧注意力。TransCenter受噪音影响更小,更适合处理目标密集的数据,但身份ID切换次数IDS指标过高,是该模型需要改进的方向之一。MOTR是首个完全端到端的基于Transformer结构的深度神经网络,避免了启发式算法,更适合建模长时间关系。
5 结语
Transformer结构适合建模长距离关系,搭建深层神经网络,已经成功应用于MOT领域并取得良好的效果。但是目前基于Transformer结构的MOT网络仍存在对于小型目标和密集场景检测跟踪效果不佳等问题。基于现状,提出未来发展趋势:(1)针对视频序列小目标检测与跟踪。(2)针对复杂环境条件下多目标的检测与跟踪。(3)针对具有极高密度目标视频序列的检测与跟踪。
