特征增强的单阶段遥感图像目标检测模型
2022-07-04汪西莉
汪西莉,梁 敏,刘 涛
(陕西师范大学 计算机科学学院,陕西 西安710119)
遥感图像目标检测是遥感解译的重要任务之一,随着卷积神经网络的兴起,其研究和应用取得了很大进展。尽管如此,仍有一些难点问题阻碍了检测性能的提升,如遥感图像目标大小、形态等差异大、目标分布不均匀、空间场景复杂、存在遮挡等,使得不同尺度目标和遮挡目标的精确检测较为困难。
若采用网络最后一层特征和固定大小的锚框,很难灵活应对不同尺度目标的检测。为此,基于深度模型解决此问题,近年来采用的方法主要有:① 图像金字塔,如图像金字塔的尺度归一化(Scale Normalization for Image Pyramids,SNIP)[1]和混合分辨率(Hybrid-Resolution,HR)[2],可以显著提升检测精度,但计算量大,难以应用于实时目标检测。② 在单层特征图上使用锚框机制解决,如Faster R-CNN[3]和R-FCN(Region-based Fully Convolutional Networks)[4],使用不同大小的锚框检测不同尺度的目标,但是单层特征图信息有限,效果提升受限。③ 特征金字塔结构,它在多层不同分辨率特征图上使用锚框机制检测多尺度目标,是使用较多的策略[5]。如SSD(Single Shot multiBox Detector)[6]和MS-CNN[7]依赖深层低分辨率特征图检测大的目标,浅层高分辨率特征图检测小目标。由于浅层特征图缺乏对象语义信息,对小目标的检测效果不好,后续研究多将深层特征图的语义信息融合至浅层特征图,如DSSD(Deconvolutional Single Shot Detector)[8]利用反卷积上采样深层特征图,与浅层特征图相乘融合,增加浅层特征的语义信息;RefineNet[9]使用反卷积上采样深层特征,相加融合不同层的特征;FPN(Feature Pyramid Networks)[10]、RetinaNet[11]和Mask R-CNN[12]等使用插值法上采样深层特征图与浅层特征图相加融合,增加浅层特征图的语义信息;STDN(Scale-Transferrable Detection Network)[13]使用STM(Scale-Transfer Module)和池化构造特征金字塔;PFPNet(Parallel Feature Pyramid Network)[14]使用多次池化操作(Spatial Pyramid Pooling,SPP)生成不同分辨率的特征图,然后使用通道拼接融合不同层的特征(Multi-Scale Context Aggregation,MSCA);M2Det[15]构造MLFPN(Multi-Level Feature Pyramid Network)结构,使特征金字塔的每一层特征都来自于多个不同层次,丰富特征层的信息;Libra R-CNN[16]将FPN结构上的不同分辨率的特征层融合调整后相加到FPN每层特征上,进一步强化各层特征的信息;PANet(Path Aggregation Network)[17]在FPN结构的基础上构造自底向上路径,增加浅层特征的细节定位信息并传递至深层特征,使特征图的语义信息和细节信息都更加丰富。
有效的特征金字塔结构需要在不同层次获取有效的目标特征,以便在多层不同分辨率的特征图上使用锚框机制检测不同尺度的目标,因此在特征金字塔结构中,既需要将远离输入层的深层特征图丰富的语义信息传递至离输入层近的浅层特征图,增加后者的语义信息,也需要将浅层特征图丰富的细节信息传递至深层特征图,增加后者的细节信息。细节定位信息和目标语义信息的有效提取是提升不同尺度目标检测精度的基础。
在卷积神经网络的特征逐层传递过程中,引起特征丢失主要有两个原因。一是下采样操作越多,特征丢失越多;二是中间经过的特征层数越多,特征丢失越多。根据文献[17]的分析,FPN网络构造了自顶向下路径,将深层特征图的语义信息传递至浅层特征图,而浅层特征图的细节信息是通过主干网络路径传递至深层特征图的,自顶向下路径和对应的主干网络路径的下采样率是相同的,相同下采样率的卷积神经网络结构中,中间经过的特征层数越多,特征丢失越多。FPN中自顶向下路径上的特征层数较少,语义信息的传递效果较好;主干网路径上层数多,细节信息的传递效果相对较差。因此PANet网络在自顶向下路径的基础上构造自底向上路径,减少中间经过的特征层数,提升细节信息的传递效果。
由于背景复杂或遮挡等的影响,造成目标特征被干扰、与周围环境不易区分,这种情况下精确地检测目标极具困难性。使用位置注意力强化目标区域特征是提升目标检出率的有效方法,对解决遮挡问题也有实际意义。可以通过强化目标边界框内的区域来强化目标的特征,如FAN(Face Attention Network)[18]注意力模块将边界框内的像素标记为目标像素,边界框外的像素标记为背景像素,形成弱监督像素级标签,损失函数为图像分割损失函数,训练后将位置注意力权重作用至预测特征图,增强识别为目标像素的区域,相对弱化识别为背景像素的区域,重标定预测特征图的特征分布。
FAN注意力模块的不足之处在于:弱监督标签导致注意力权重生成不够精确,强化的目标边界框内的像素并不全是目标。如图1(a)所示,FAN位置注意力反强化目标边界框内的所有像素,而在基于锚框的目标检测网络中,主要是边界框内的中心区域负责检测目标,如图1(b)所示。边界框内靠近边界的很多像素属于背景,因此FAN的做法同时强化了一些非目标区域,如果能更精确地强化目标,则有利于检测精度的提升。
为了在特征逐层传递过程中更好地保留、融合细节和语义信息,文中提出跳跃连接特征金字塔模块(Feature Pyramid Network with Shortcut Connections,SCFPN)。为弥补语义信息从深层特征传递至浅层特征的丢失问题,在主干网络末端使用全局平均池化生成聚合丰富语义信息的特征图,利用跳跃连接相加融合至自顶向下路径上的各层特征图,以增加各层特征的语义信息;同时将高分辨率特征图的细节定位信息利用跳跃连接相加融合至自底向上路径上的各层特征图,增加各层特征的细节信息。为使位置注意力的生成方式(即关注边界框中心区域)与目标检测头网络中基于锚框的检测方式保持一致,笔者提出基于锚框的位置注意力模块(Anchor-based Spatial Attention Module,ASAM)。该模块采用基于锚框的识别方法,以达到只强化边界框内中心区域的目的。在预测时,预测以像素位置为中心的锚框包含目标的概率,再使用通道维度取最大值方法将预测值压缩形成位置注意力权重,作用至预测特征图上以更精确地调整预测特征图的特征分布。
为评价提出的跳跃连接特征金字塔模块和基于锚框的位置注意力模块的有效性,将其嵌入到目标检测模型RetinaNet中,设计了一个特征增强的单阶段遥感图像目标检测模型FENet。主要贡献总结如下:① 提出跳跃连接特征金字塔模块,缓解特征金字塔结构中特征逐层传递造成信息丢失的问题,进一步增强预测特征图的语义和细节信息,为检测不同大小的目标提供基础;② 提出基于锚框的位置注意力模块,通过强化锚框中心区域的特征,尽可能准确地强化目标特征,以提升目标的检测性能。在UCAS-AOD[19]和RSOD[20]遥感图像数据集上检测多类目标,笔者给出的模型在精度和速度上展现出优于比较方法的结果。
1 FENet模型
FENet模型的总体框架如图2所示。该模型首先使用主干网络ResNet-50[21](图2中的A)和跳跃连接特征金字塔模块(图2中的B和C)从输入图像中提取卷积特征,然后使用添加基于锚框的位置注意力模块的目标检测头网络(图2中的D)生成预测边界框以及类别分数,并使用NMS(Non-Maximum Suppression)筛选检测结果。目标检测头网络中的分类和回归子网络与RetinaNet的对应子网络设置相同,分别连接4个256通道的卷积操作后,再分别添加KA个通道的卷积层和4A个通道的卷积层,经过激活层后预测目标类别分数和位置信息,其中K表示类别数,A表示每一像素位置的锚框数量。下面详细介绍FENet模型中的跳跃连接特征金字塔模块和基于锚框的位置注意力模块(图2中的ASAM)。

图2 FENet模型结构
1.1 跳跃连接特征金字塔模块(SCFPN)
如图2所示,在提取特征的主干网络(图2中的A)之后添加两个步长为2的卷积操作,生成两个不同分辨率的特征图(即P6、P7预测特征图)。随着传递层数增加,逐层传递特征逐渐丢失信息,因此在构造自顶向下和自底向上路径的过程中,添加跳跃连接以弥补特征丢失。在构造自顶向下路径(图2中的B)的过程中,先在主干网络末尾添加全局平均池化操作,生成聚合丰富语义信息的特征图,称为GAP(Global Average Pooling)特征图(图2中的G)。在每次使用最近邻插值上采样特征图后和主干网络上对应的特征图相加融合的同时加上GAP特征图,使自顶向下路径上的特征图(图2中的P3、P4、P5)既融合逐层依次传递的语义信息,又直接融合GAP语义信息,达到增强特征图语义信息的目的。
给定主干网络上的特征图Ci∈RC×H×W和全局平均池化形成的特征图G256×H×W,则自顶向下路径上对应的特征图Pi∈R256×H×W可表示为
(1)

特征金字塔结构中,语义信息沿着自顶向下的路径(图2中的B)传递,中间经过的特征层数不多,语义信息丢失相对较少;而细节定位信息沿着主干网络路径(图2中的A)传递,中间经过的特征层数多,细节定位信息丢失相对较多。为此在自顶向下路径(图2中的B)的基础上构造自底向上路径(图2中的C),减少中间经过的特征层数,使细节定位信息也可有效传递至深层特征图。
在构造自底向上路径的过程中,从P3特征图开始下采样特征图,依次传递细节信息,与对应自顶向下路径上的特征图(图2中的P3、P4、P5)相加融合。此外,将P3特征图分别2倍、4倍池化,相加融合至自底向上路径上的各层特征图,使该路径上的特征图(图2中的N3、N4、N5)既融合依次传递的细节定位信息,又融合直接池化得到的细节信息,达到增强特征图细节定位信息的目的。
给定自顶向下路径上的特征图Pi∈R256×H×W,则自底向上路径上对应的特征图Ni∈R256×H×W可表示为
Ni=Pi+M2(Ni-1)+M2i-3(P3) ,
(2)
其中,Mk表示k倍池化下采样,i∈[4,5]。
最终将特征图N3、N4、N5作为预测特征图,这些特征图既有丰富的语义信息,又有丰富的细节定位信息。
1.2 基于锚框的位置注意力模块(ASAM)
首先分析FAN位置注意力机制,其次介绍笔者提出的ASAM位置注意力机制。
FAN位置注意力机制将框级标签转化为弱监督像素级标签,使用全卷积网络依据弱监督像素级标签预测像素类别。将像素的目标置信度分数作为位置注意力权重,指数化后作用于预测特征图上,强化目标像素特征,弱化背景像素特征。FAN将目标边界框内的背景像素也标记为目标像素,会影响像素类别预测的准确度,从而降低位置注意力权重生成的准确度。此外,FAN位置注意力机制将目标边界框内的像素区域都强化,但基于锚框的目标检测寻找目标边界框中心位置附近的像素对应的锚框与边界框标签的IOU(Intersection Over Union)大的样本,在训练时视其为正样本,测试时通常是微调后需要保留的预测结果,因此该区域特征是需要强化的,而其他区域(即目标边界框内非中心位置附近的区域和背景区域)像素对应的锚框与边界框标签的IOU较小甚至为零,在训练期间或者为负样本或者不参与训练,在测试期间通常是属于根据类别置信度分数和后处理操作筛选掉的预测结果,因此这些区域是要弱化的。而FAN位置注意力机制对它们不加区别。
可见基于锚框的目标检测要求施加位置注意力权重标定预测特征图的特征分布时,主要强化目标边界框中心位置附近的像素,其他位置的像素要弱化。因此文中提出基于锚框的位置注意力模块,基于锚框判别像素是否是正样本像素。
具体地,在训练时,将与边界框标签的IOU较大的锚框视为正样本锚框,否则为负样本锚框。锚框的大小设置与目标检测头网络中锚框的设置相同,损失函数为二分类Focal Loss交叉熵损失函数。若一个像素对应的多个锚框中有一个锚框是正样本,则该像素属于正样本,需要被强化;若其对应的锚框都是负样本锚框,则该像素属于负样本,应被弱化。可见边界框中心位置附近的像素对应的锚框与边界框标签的IOU较大,会被识别为正样本,进而被强化,而非中心位置的像素和背景区域的像素对应的锚框与边界框标签的IOU较小或为零,会被识别为负样本像素,从而被弱化。因此这样判断一个像素是否是正样本像素,满足基于锚框的目标检测方法的要求。
在预测时,当某一位置像素对应的锚框中包含负责预测对象的锚框时,负责预测对象的锚框的预测值接近1,使用通道维度取最大值压缩后的结果也接近于1,将压缩后的结果值作为位置注意力权重作用于预测特征图,强化正样本像素。当某一位置像素对应的锚框都不负责预测对象时,所有锚框的预测值都接近于0,使用通道维度取最大值压缩后结果接近于0,将其作为位置注意力权重作用于预测特征图,弱化负样本像素。
具体如图2中的ASAM所示。首先,连接4次卷积操作;其次,基于锚框判别特征图上每一位置像素的类别;然后,在通道维度取最大值压缩预测结果特征图;最后,采用先点乘预测特征图再相加融合至预测特征图的注意力施加方式,强化正样本像素、弱化负样本像素。通过强化目标区域特征和弱化非目标区域特征重标定预测特征图的特征分布,提升目标检测网络的检测精度。
给定特征图F∈RC×H×W,则位置注意力权重特征图Ms(F)∈R1×H×W可表示为
(3)
(4)

1.3 损失函数
使用多任务损失函数联合优化FENet模型的参数。损失函数由分类损失Lc、回归损失Lr和注意力损失La三部分构成,具体定义为
(5)
其中,k表示特征金字塔层次的索引(k∈[3,7]),Ak表示特征金字塔层次Pk上定义的锚框的集合。


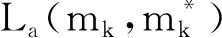
2 实验结果和分析
使用ResNet-50作主干网络,用在ImageNet上预训练的权重初始化主干网络。在跳跃连接特征金字塔模块后的注意力、分类和回归子网络中,前4个卷积层以偏置b=0和高斯方差σ= 0.01的权重初始化。在分类子模块和基于锚框的位置注意力模块中做预测的卷积层以偏b=log((1-π)/π)和π=0.01初始化。所有实验在一块Titan X GPU上训练,实验数据集以7∶3随机划分成训练集和测试集,图像尺寸800×800像素,batch-size为2。使用随机梯度下降法训练模型,迭代训练100个epoch,初始学习率为0.001,学习率在60 epoch和80 epoch分别降低为原来的1/10。权重衰减和动量分别设置为0.000 1和0.900 0。
2.1 数据集与评价指标
在两个遥感图像目标检测数据集UCAS-AOD和RSOD上进行实验。UCAS-AOD数据集中有汽车图像510张,包含汽车样本7 114个;飞机图像1 000张,包含飞机样本7 482个。RSOD 数据集有2 326 张图像,类别包含飞机、油桶、操场、立交桥4种,图像采集于Google Earth。其中飞机图像446张,包含飞机样本4 993个;油桶图像165张,包含油桶样本1 586 个;操场图像189张,包含操场样本191个;立交桥图像176张,包含立交桥样本180个;其余是背景图像。使用mAP和运行时间作为评价指标。
定义精确率P(Precision)为
(6)
召回率R(Recall)为
(7)
其中,RTP指正类被判定为正类,RFN指正类被判定为负类,RFP指负类被判定为正类,RTN指负类被判定为负类。
AP(Average Precision)被定义为在11个不同召回率水平[0,0.1,0.2,…,1.0]上的最大精确率的平均值:
(8)
其中,Pmax(r)指在召回率为r时的最大精确率。AP是单个类别目标的评价指标,mAP指多个类别目标的AP的平均值。
2.2 增加跳跃连接特征金字塔模块的实验
在UCAS-AOD遥感数据集上对比了FAN模型和添加跳跃连接特征金字塔模块的FAN模型的实验结果。实验结果见表1,采用跳跃连接特征金字塔模块mAP提升了1.35%,表明跳跃连接可以在一定程度上弥补逐层传递时的信息丢失问题,增强特征图的语义和细节信息。

表1 FAN和FAN+SCFPN在UCAS-AOD数据集上的性能比较
在自底向上路径上逐层传递特征细节定位信息的过程中,我们尝试3种不同的特征图下采样操作,分别是池化、步长为2的卷积操作以及使用通道分离后,一部分通道特征池化、另一部分通道特征卷积下采样。表2展示了这3种不同做法在UCAS-AOD数据集上的实验结果。3种下采样操作中,池化操作不需要学习参数,相对来说速度最快,卷积操作需要学习参数,会增加运行时间,第3种操作兼用卷积操作和池化操作,复杂度更高。综上以及结合表2的实验结果,文中在跳跃连接特征金字塔模块的自底向上路径上使用池化下采样操作。

表2 跳跃连接特征金字塔模块在UCAS-AOD数据集上的实验
2.3 增加位置注意力模块的实验
表3在UCAS-AOD数据集上对比了不使用位置注意力模块的模型和文中FENet模型的结果。从实验结果可以看到,使用基于锚框的位置注意力模块有0.43%的精度提升,表明在基于锚框的位置注意力模块中,强化的正样本像素的特征区域与目标检测头网络中负责预测边界框的特征区域更为匹配,提升了目标检测头网络的检测能力。

表3 使用和不使用基于锚框的位置注意力模块的FENet模型在UCAS-AOD数据集上的性能比较
笔者尝试了3种位置注意力生成方式,第1种在基于锚框的位置注意力模块中第4个卷积操作之后添加一个降维的卷积操作,将256通道的特征图转变为1维权重特征图;第2种使用取最大值压缩通道的方式将基于锚框的位置注意力模块的预测特征图压缩为1维通道的权重特征图;第3种在第2种方式的基础上再做卷积操作,以学习将压缩后的预测特征图转化为位置注意力权重的转化参数。3种做法的实验结果展示在表4中,3种位置注意力生成方式都比较有效。考虑到对预测结果特征图的利用及简单性,采用第2种位置权重生成方式。

表4 不同的位置注意力生成方式在UCAS-AOD数据集上的对比实验
下面在UCAS-AOD数据集上对位置注意力权重特征图的不同施加方式进行了实验,分别对比了权重相乘后相加、直接权重相乘以及指数化权重后相乘3种方式,结果如表5所示。注意力权重在0到1之间,所以直接权重相乘会对预测特征图的目标区域和背景区域都产生不同程度的弱化,因此需要采用权重大于1的方式,结合表5的实验结果考虑,笔者选择相乘后相加的位置注意力权重施加方式。

表5 位置注意力权重的施加方式在UCAS-AOD数据集上的实验对比结果
2.4 目标检测实验及分析
表6是文中模型FENet和其他模型在UCAS-AOD数据集上的对比情况,结果均来自文中实验。FENet取得95.47%的精度,高于采用特征金字塔和焦点损失的RetinaNet和特征注意力网络FAN,在UCAS-AOD数据集上取得较高的精度。

表6 FENet模型和对比模型在UCAS-AOD数据集上的性能比较
为了验证文中模型的有效性与鲁棒性,在RSOD遥感数据集上对比了文中模型和其他先进模型,如表7所示。RetinaNet、FAN和FENet结果为文中实验所得,其他模型结果来自文献[22]。用于多角度目标检测的RFN(Rotated Feature Network)模型[22]的mAP精度达到了92.30%,立交桥和操场的检测性能较好,飞机的检测精度有一定的提升,但仍不高。采用密集连接特征金字塔结构的Densely Connected FPN模型[23]对飞机的检测精度有进一步的提升,对油桶的检测精度也有明显的提升,在ResNet-50的主干网络下mAP达到91.53%,而使用ResNet-101主干网络时mAP达到94.19%,精度显著提高。FAN和RetinaNet对不同尺度的目标都能较好地处理,飞机和油桶的检测精度得到进一步提升,但是立交桥、操场的精度略有降低。文中模型FENet在保持立交桥、操场较高检测精度的同时,提升了飞机和油桶的检测精度,在RSOD数据集上超越了其他模型。

表7 FENet模型和其他先进模型在RSOD遥感数据集上的性能比较
表8对比了文中模型和其他遥感目标检测模型在RSOD图像上的测试时间,各实验使用的GPU型号是12 GB存储的Titan X。其中FENet和FAN模型结果来自文中实验,其他模型结果来自文献[23]。
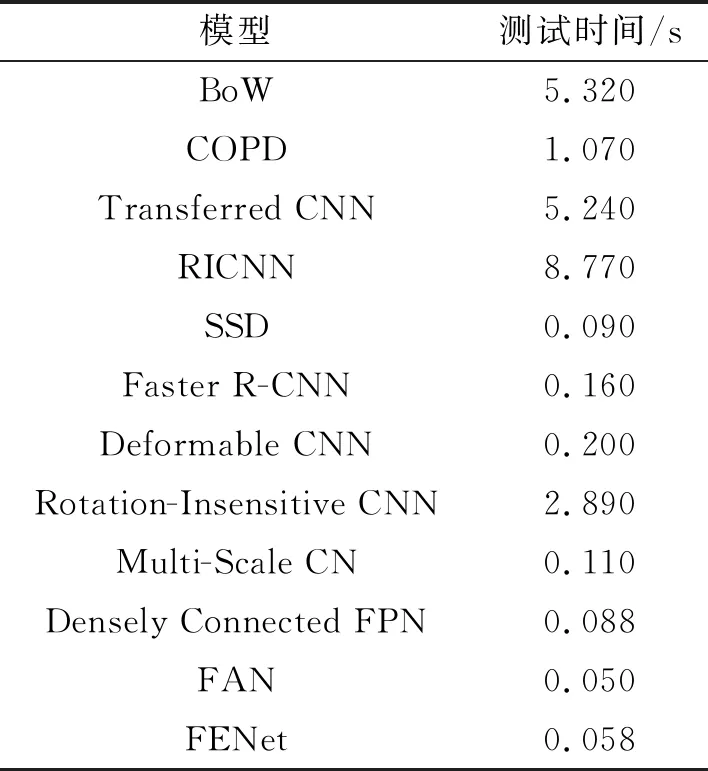
表8 不同目标检测模型在RSOD数据集上的测试时间对比
从表8可以看出单阶段目标检测模型普遍比两阶段模型检测时间短,FENet的测试时间和其他单阶段检测模型相差不大。
图3展示了文中模型FENet和对比模型RetinaNet、FAN在UCAS-AOD遥感目标测试集的部分检测结果。从图3可见,飞机的大小有明显的不同,方向不一。对于飞机目标,RetinaNet和FAN有漏检或检测框没有准确框住目标的情况。汽车目标普遍较小,仔细看也有大小不一、停放方向不一的情况。对汽车RetinaNet和FAN有漏检的情况,如第4行右下角的汽车。第5行左侧中间的汽车有部分被树遮挡,RetinaNet没有检出,而FAN和FENet都检出了。

图3 UCAS-AOD数据集上的部分检测结果
图4展示了文中模型FENet在RSOD测试集上的部分检测结果。该数据集有4类目标,立交桥、操场偏大,相比之下,油罐和飞机偏小,而且油罐和飞机即使同类目标也存在目标大小不一的情况。从图中可以看出,FENet采用跳跃连接特征金字塔模块和基于锚框的位置注意力模块,使其对不同大小的同类和不同类目标展现了较好的检测结果。

图4 FENet在RSOD数据集上的部分检测结果
3 结束语
为解决在特征金字塔结构中,语义信息和细节信息逐层传递引起的特征丢失问题,以及位置注意力权重生成方式与基于锚框的目标检测头网络的预测方式不一致的问题,笔者提出由跳跃连接特征金字塔模块和基于锚框的位置注意力模块构成的单阶段遥感图像目标检测模型FENet。FENet模型通过构建自顶向下和自底向上的特征金字塔路径,以及层间、同层连接和融合,缓解语义信息和细节信息逐层传递过程中信息丢失的问题,从而更好地获得具有语义和细节信息的预测特征图;同时设计了新的位置注意力权重生成方式,与基于锚框的卷积预测模块的预测方式保持一致,强调目标的特征,进而提升目标检测模型的性能。通过UCAS-AOD和RSOD遥感数据集上的实验,以及与相关方法的比较,结果表明,所提模型可以提升在不同大小目标上的检测精度,作为单阶段目标检测方法,具有较快的检测速度,验证了文中方法的有效性和鲁棒性。笔者所提模型FENet与当前目标检测中先进的模型相比,在检测速度方面仍然有提升空间,下一步工作考虑使用可分离卷积减少冗余卷积操作,在不降低模型精度的情况下缩短模型的检测速度。
