一种结合GAN的定向口令猜测方案
2022-07-04杜李旭弘杨小雪
杜李旭弘,陈 杰,2,杨小雪
(1.西安电子科技大学 通信工程学院,陕西 西安 710071;2.桂林电子科技大学 广西密码学与信息安全重点实验室,广西壮族自治区 桂林 541004)
随着互联网时代的飞速发展,人类许多传统的生产生活方式都发生了空前的改变,各类信息技术更是将社会的数字化程度大幅提高。与此同时,各类信息安全隐患问题也随之而生,身份认证的重要性更加不容忽视。身份认证是保障用户个人信息安全的第一道防线,在很多信息系统中甚至是惟一的一道防线,而基于口令的安全验证方式作为最基本且应用最为广泛的身份认证方式,更是起着举足轻重的作用。
随着信息的爆炸式增长,越来越多的服务需要通过口令进行保护,更有越来越多的用户个人信息被储存至网络空间。这些信息面临着被泄露的风险,而在信息泄露的同时,数字时代的攻击者便有可乘之机。用户个人信息中往往含有一些未被发掘的潜在联系,若被攻击者利用,则可能会导致很严重的后果。比如,据国外媒体Inverse报道,美国著名运动品牌Under Armour的MyFitnessPal服务被黑客攻击,1.5亿用户数据被泄露。在此次数据泄露事件中,黑客可获得的用户数据包括用户名、邮箱地址以及年龄等常规信息[1],虽然这些信息单从表面看并不存在风险,但却会被不法分子加以利用,从而做出针对用户的威胁行为,如针对性市场营销。各种新服务络绎不绝的上线,都会让个人可标识信息(Personal Identifiable Information,PII)数据集更加庞大,这意味着数据之间的关系网会更加完善,那么数据之间的潜在联系会更容易被黑客所提取,从而“窥探”到用户的潜在行为。若要在此种环境下保护用户的信息安全,就要试图研究和了解数据集中数据的来源及构造原理。
由于人类的记忆能力有限,通常情况下只能记忆5~7个口令[2],迫使用户不可避免地采取如下存在安全隐患的行为:低信息熵弱口令的使用[3]、利用个人信息构造便于记忆的口令[4]以及同一口令在多个网站中的重复使用[5]。口令虽然容易记忆,但作为随机变量其概率分布不均,因此熵值不高[6]。为研究口令安全,学者们提出了各种口令猜测概率模型,如Markov[7]和概率上下文无关文法(Probabilistic Context Free Grammar,PCFG)[8]等。这些模型均运用于传统概率猜测算法,猜测过程不借助用户的个人信息,而是关注于用户会采取流行口令的行为,攻击者一旦拥有泄露的口令文件,其攻击目标则会尽可能多地猜测出文件中的口令。区别于传统漫步猜测模型,定向猜测模型在漫步猜测使用流行口令行为的基础上,还会使用用户个人信息构造口令以及口令重复使用等危险行为[9]。随着大规模个人信息泄露事件的不断发生,各种类型的个人可标识信息和用户在其他网站使用的口令都越来越容易被攻击者获取,定向猜测带来的现实威胁日益严峻。比如,据中国互联网络信息中心(CNNIC)的2015年度报告,6.68亿中国网民中超过78.2%都曾遭遇过个人可标识信息数据泄露[10]。
这意味着,现有建立在那些漫步猜测概率模型[7-8]之上的口令生成规则[11]和口令强度评价算法[12],只考虑了十分受限的离线猜测威胁,而无法防御越来越现实、危害越来越大的定向在线猜测攻击,并且与传统方法相比,神经网络方法在口令猜测领域更为准确和实用。文献[13]提出的多源深度学习模型GENPass,将神经网络与PCFG相结合,从单个数据集学习时,该模型比单独使用神经网络模型匹配率提高了16%~30%;文献[14]提出采用循环神经网络(Recurrent Neural Network,RNN)与PCFG相融合的混合猜测模型。该模型破解率始终显著高于传统的PCFG(107量级猜测数下)和Markov模型(106量级猜测数下),为提高口令猜测效率提供了潜在的新途径。笔者在文献[14]提出模型的基础上,对定向猜测中用到的个人可标识信息进一步划分,并结合生成式对抗网络,以提升口令猜测的成功率。为了使生成的猜测口令更接近真实口令,笔者对TarGuess-I[15]模型中所用到的个人信息分类中的用户名进一步划分:除了单纯按照数字、字母段划分之外,对用户构造的带有用户行为特征的字符串也进行划分,从而避免合并用户行为特征。将真实口令经过模型解析后的真实规则再利用生成式对抗网络进行学习和处理,生成高质量伪规则集,并利用该伪规则集进行口令猜测攻击实验。其中生成式对抗网络由生成网络以及判别网络两部分构成,分别用于猜测口令的生成以及对猜测口令的判定,使得猜测口令的结构在接近真实口令结构的同时,又能产生新的结构规则,从而使口令猜测成功率得到进一步的提升。
1 定向口令猜测模型
不同于漫步口令猜测模型,定向猜测模型是在给定目标用户的前提下猜测出该用户的真实口令。通过利用用户的个人信息提高猜测成功率,同时一定程度上减少猜测次数,并且利用个人可标识信息标签加强了口令解析以及口令猜测过程的针对性和有效性[16]。用户的个人信息可归为两类:第1类是用户身份的认证凭证,主要包含用户的旧口令和其他网站泄露的口令;第2类即为个人可标识信息,主要包含有姓名、出生日期、年龄、身份证号码、学历、职业等。如何利用个人可标识信息设计定向猜测模型是现阶段关于定向猜测研究的重点。
1.1 用户构造口令行为分析
用户构造口令的行为主要分为:流行口令的使用、同一口令的重复使用以及如何使用自己的个人信息构造口令。文献[17]研究发现,60.1%的用户在口令中使用了至少一种自己本人的个人可标识信息,因此利用个人信息构造口令的行为具有较高的研究意义。笔者采用带有用户个人信息的中文用户中国铁路数据集12306进行研究。中文流行口令大多由数字组成,而英文流行口令大多包含有涵义的字母串或者键盘键位布局,根据中国人构造口令的习惯,中文流行口令相对英文流行口令分布较为集中[15],因此中文用户面临的定向在线猜测攻击的风险也更大。经过统计,在中文口令的构造中,各类用户个人信息的使用情况如图1所示,使用频率最高的个人信息是出生日期、用户名以及生日,其次是邮箱前缀、身份证号以及手机号。
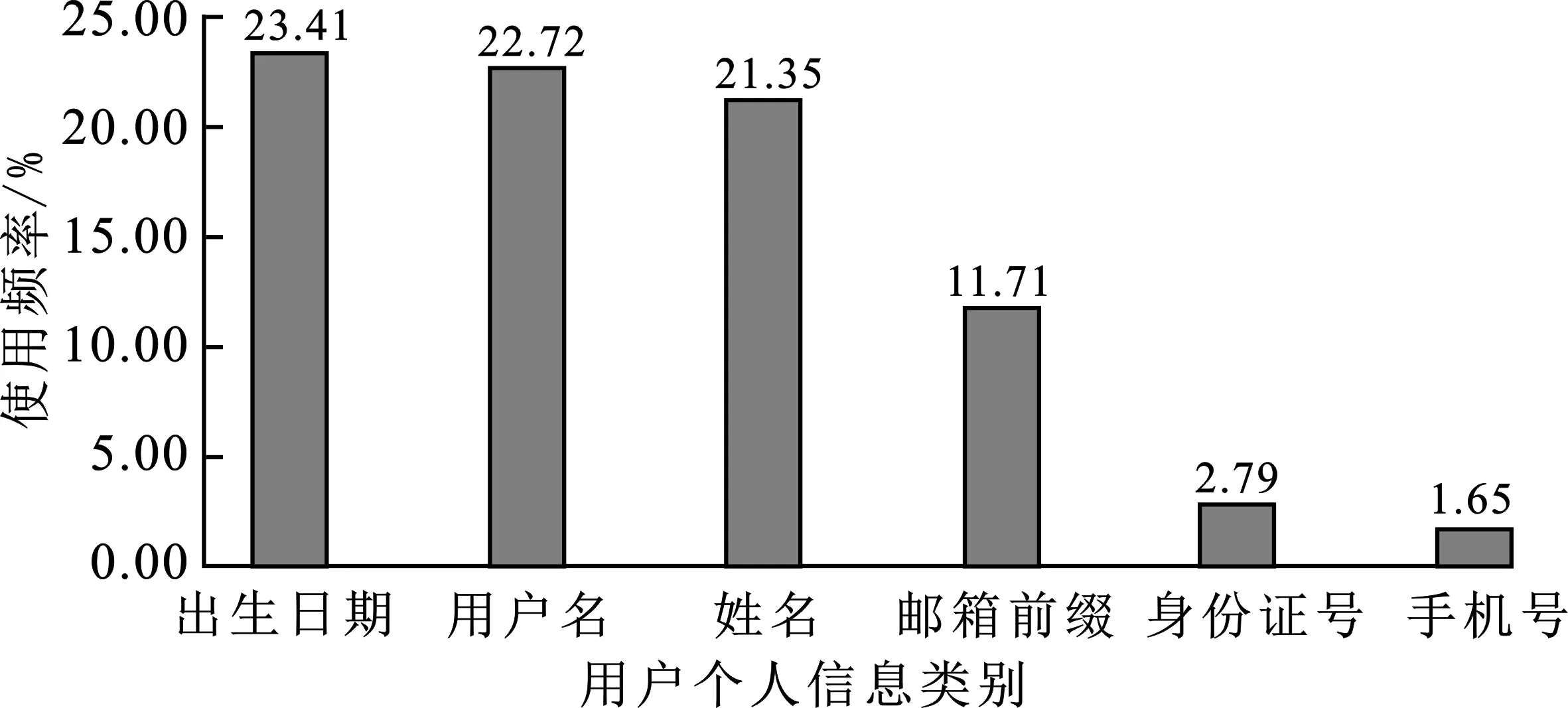
图1 12306口令集中个人信息使用率示意图
1.2 铁路基于PCFG的口令解析
文献[8]于2009年提出的基于PCFG的漫步口令猜测算法,是PCFG在口令猜测领域的首次应用。其核心思想是将口令按照数字、字母以及特殊字符进行划分,在口令解析阶段统计各个类型中字符串出现的概率并进行降序排列,随后在猜测攻击阶段利用各类型的字符串概率表,重新组合各类型的字符串,生成猜测列表。文献[17]于2016年将用户个人信息应用于猜测攻击,提出了可识别个人可标识信息语义的定向口令猜测模型Personal-PCFG。Personal-PCFG在前人提出的基于PCFG口令猜测算法的基础上,又基于长度匹配将用户个人信息划分为:姓名、出生日期、电话号码、身份证号码、邮箱地址和用户名。文献[15]提出了基于 PCFG 定向猜测攻击模型TarGuessⅠ~Ⅳ系列,与文献[17]提出模型的不同之处在于,提出的口令猜测模型是基于类型的个人可标识信息匹配,而非基于长度的个人可标识信息匹配,因此在TarGuess模型中用户的个人信息被划分得更为具体、准确[16](如,B1表示年月日格式;B2表示月日年格式;B3表示日月年格式;B4表示月日格式;B5表示年份格式;B6表示年月格式;B7表示月年格式;B8表示年份后两位数字+月日格式;B9表示月日+年份后两位数字格式;B10表示日月+年份后两位数字格式)。文献[18]2019年提出基于主题PCFG的口令猜测模型T-PCFG。该模型关注于个人兴趣爱好对口令结构影响的研究,其通过对字母字段的提取方法进行修改,并组成新的猜测集进行试验。笔者侧重于个人习惯对口令结构影响的研究,通过对字母、数字、特殊字符字段的组合提取,进一步防止用户行为被合并。
根据口令集中个人信息使用率的统计结果以及口令处理过程中发现的规律,考虑用户名在构造口令过程中的高利用率和高复杂性,笔者提出全面细化用户名在口令中的构造规则可以提高猜测成功率的设想,从而在文献[15]提出的定向口令猜测模型TarGuessⅠ的基础上,将基于类型的个人可标识信息匹配进一步优化:将口令中含有的用户构造的特殊的字符串,不再只单纯划分为对应个人可标识信息全称字段以及数字、字母两种数据类型的字段,而是在包含个人可标识信息全称字段的基础上考虑数字、字母以及特殊字符3种数据类型,并且按照“数字+字母”“字母+特殊字符”“数字+特殊字符”的形式划分(如:口令为“zs1997”,匹配的PII中用户名为“zs19970606”,则匹配过程不能单纯划分为数字段“19970606”或者字母段“zs”,而是应该划分为字母+前4位数字“zs1997”),此种划分方式可防止用户的某些行为特征被合并,从而提高猜测成功率。文中的个人可标识信息标签类型见表1。按照文中划分的个人可标识信息标签,将真实口令集中的所有口令与每个口令所对应的用户个人信息进行匹配,从而解析为基于PCFG的规则序列集合。解析过程中除了个人可标识信息标签的转换以外,同时从真实口令集中训练获得数字(D)、字母(L)和特殊字符(S)分别基于长度的频次表,并进行降序排列(在解析过程中,口令中的字符串若被转换为个人可标识信息标签,则不会添加到L、D、S频次表中)。
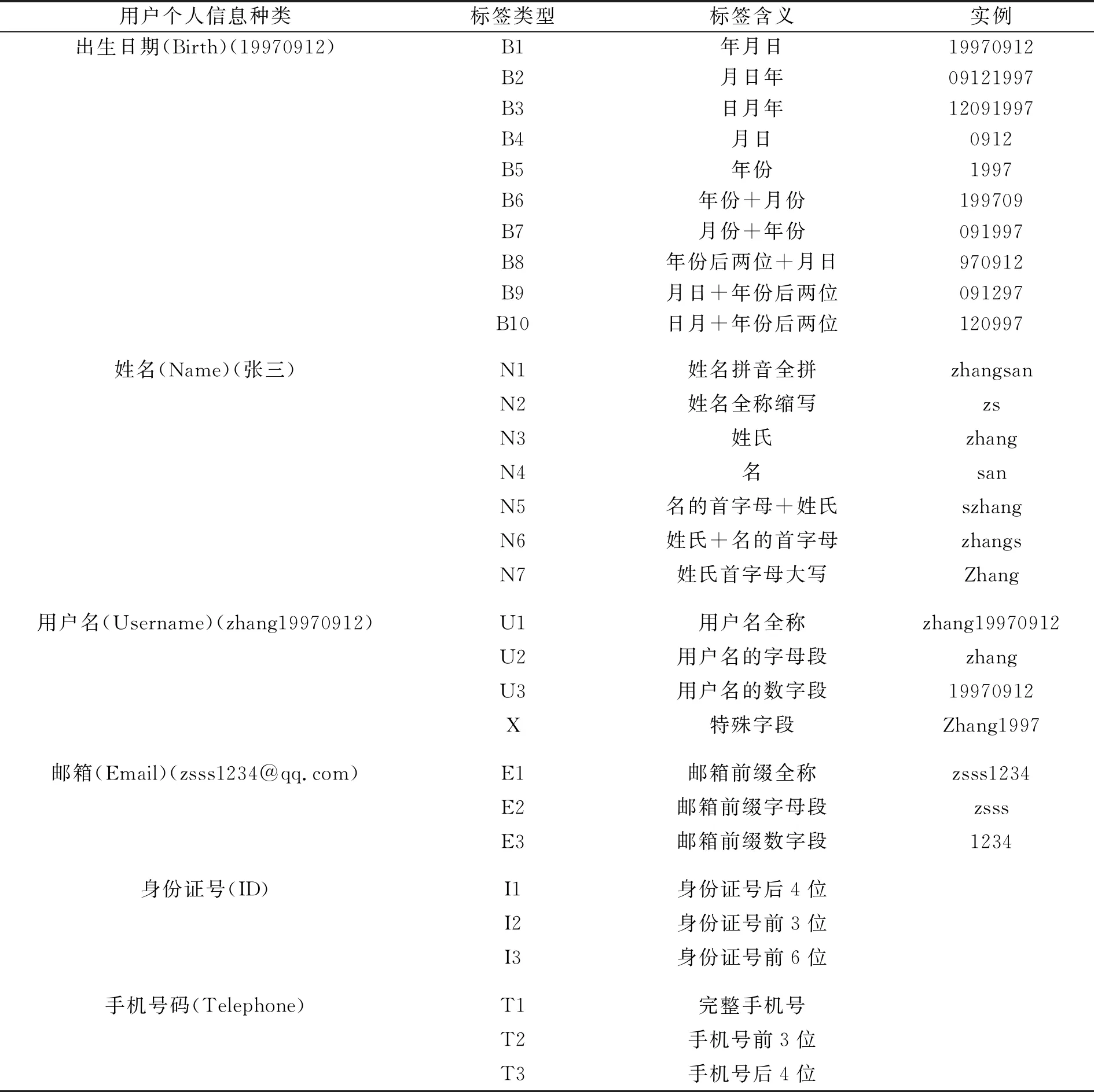
表1 基于PCFG的PII标签类型
2 生成式对抗网络模型
将优化后的口令猜测模型与深度学习算法相结合,在无需任何先验知识的情况下,通过使用生成对抗网络从实际泄漏的口令中自主学习真实口令分布,并生成高质量的规则序列,运用深度学习的过程中还会学习到口令中一些用户自己都无法发现的潜在联系,这意味着在保证规则序列符合规范的同时,还会生成新增规则,从而提升猜测成功率。笔者所用的生成式对抗网络由生成网络和判别网络两部分组成,真实口令集经过上节所述解析过程之后,得到基于PCFG的口令规则集合,将其与噪声均用作生成式对抗网络的输入,如图2所示,每次迭代训练之后,输出的伪规则都更接近于真实规则序列的分布。
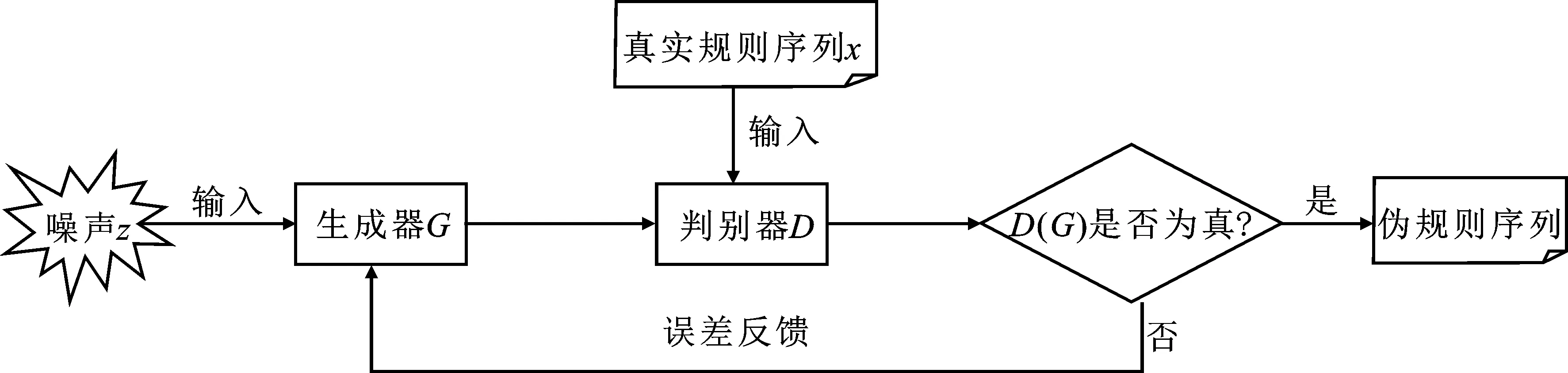
图2 生成对抗网络结构示意图
生成对抗网络的目标是从训练集S={x1,x2,…,xn}中学习并生成相同分布的样本。该网络将多维随机样本z作为输入以训练生成器G,训练过程将密度估计问题转化为二元分类问题,其要解决的优化问题可以总结为[19]
(1)
其中,f(xi;θd)和g(zj;θG)分别代表D和G。根据生成对抗网络的训练目标,定义生成对抗网络的目标函数为V(D,G),则博弈过程可表示为
(2)
其中,E表示真实数据x和样本数据z的数学期望。由于V是连续的,因此期望可以通过将V写成微积分的形式来表示:
(3)
其中,pdata(x)为真实规则分布,pz(z)为生成规则分布。博弈过程为先固定G,求解D的最优解;再固定D,求解G的最优解,然后两个网络交替训练。
设G(z)生成的规则为真实规则x,则噪声z和噪声的微分dz可表示为
G(z)=x⟹z=G-1(x)⟹dz=(G-1)′(x)dx。
(4)
将z和dz分别代入V(D,G),可得

(5)
定义pg(x)表示噪声z的生成分布,则
pg(x)=pz(G-1(x))(G-1)′(x) 。
(6)
将式(6)代入式(5),可得
(7)
对式(7)求关于D的偏导数:
(8)
可得D的最大即最优解为
(9)
从D(x)的最优解D*(x)的表达式中可以看出,期望当生成分布与真实分布一致时,即pg(x)=pdata(x)时,D(x)=0.5,即此时判别网络D只能以抛硬币的概率来猜测输入数据的真假性。然后将式(9)代入式(7),并引入连续函数的KL散度。将目标函数整理成散度表达式,可得
(10)
根据KL散度的定义,当生成规则的分布pg(x)与真实规则分布pdata(x)一致时,KL为零,所以当D逼近最优解时,G网络也无限逼近最小值,符合G网络的训练目标。经过多次交替迭代训练,即可生成合法且遵循真实分布的高质量规则。
2.1 基于生成对抗网络生成高质量伪规则集
生成网络是潜在空间Z:Rk和数据空间X之间的确定性映射函数G:Z→X。生成对抗网络的框架通过遵循对抗式训练法来学习深层生成模型,训练过程由判别网络D引导。在训练过程中,潜在噪声点z直接从Rk中采样并作为输入提供给G,G再将这些点映射到数据空间中,并将其反馈给生成网络D。生成网络D同时接收来自训练集的真实口令规则和生成网络G生成的伪口令规则,并且给出G(z)的误差,从而令生成网络G得到对抗性训练从而更新权重。优化目标遵循网络G、D的误差最小化。对文献[19]提出的PassGAN模型进行改进,使其能够更好地在基于PCFG解析后的规则序列集上训练,同时输出更高质量的伪规则序列。文献[19]使用了Wasserstein GAN改进训练来实例化PassGAN,同时依靠 ADAM 优化器来最小化训练误差[16]。为减少生成模型输出的伪规则数据与其训练数据之间的不匹配,笔者主要从以下几个方面进行了优化改进:latent size、迭代次数、输入口令向量的最大长度。通过上一节得到的PCFG规则序列集,作为改进后生成对抗网络的输入数据集,通过无先验知识的自主学习,逼近真实口令解析后的规则分布,生成高质量且扩充的伪规则集。通过对生成的伪规则集进行分析和统计,伪规则集中不重复规则、符合规范的合法规则以及出现次数n≥3次的高质量规则序列的数量随着伪规则集规模的扩大而增加,具体如图3所示。
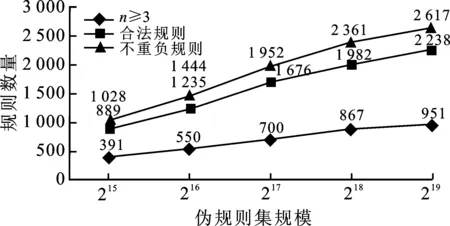
图3 生成对抗网络生成的高质量规则数量变化趋势示意图
2.2 定向猜测攻击模型
得到生成对抗网络学习生成的高质量伪规则集之后,利用该规则集攻击测试集中的用户,攻击过程为:根据生成的伪规则集,给定目标用户,利用其个人信息以及口令解析过程得到的L、D、S字段的降序表匹配生成该用户的猜测口令集,若该猜测口令集中包含该用户的真实口令,则攻击成功。定向猜测攻击模型的系统框架如图4所示。
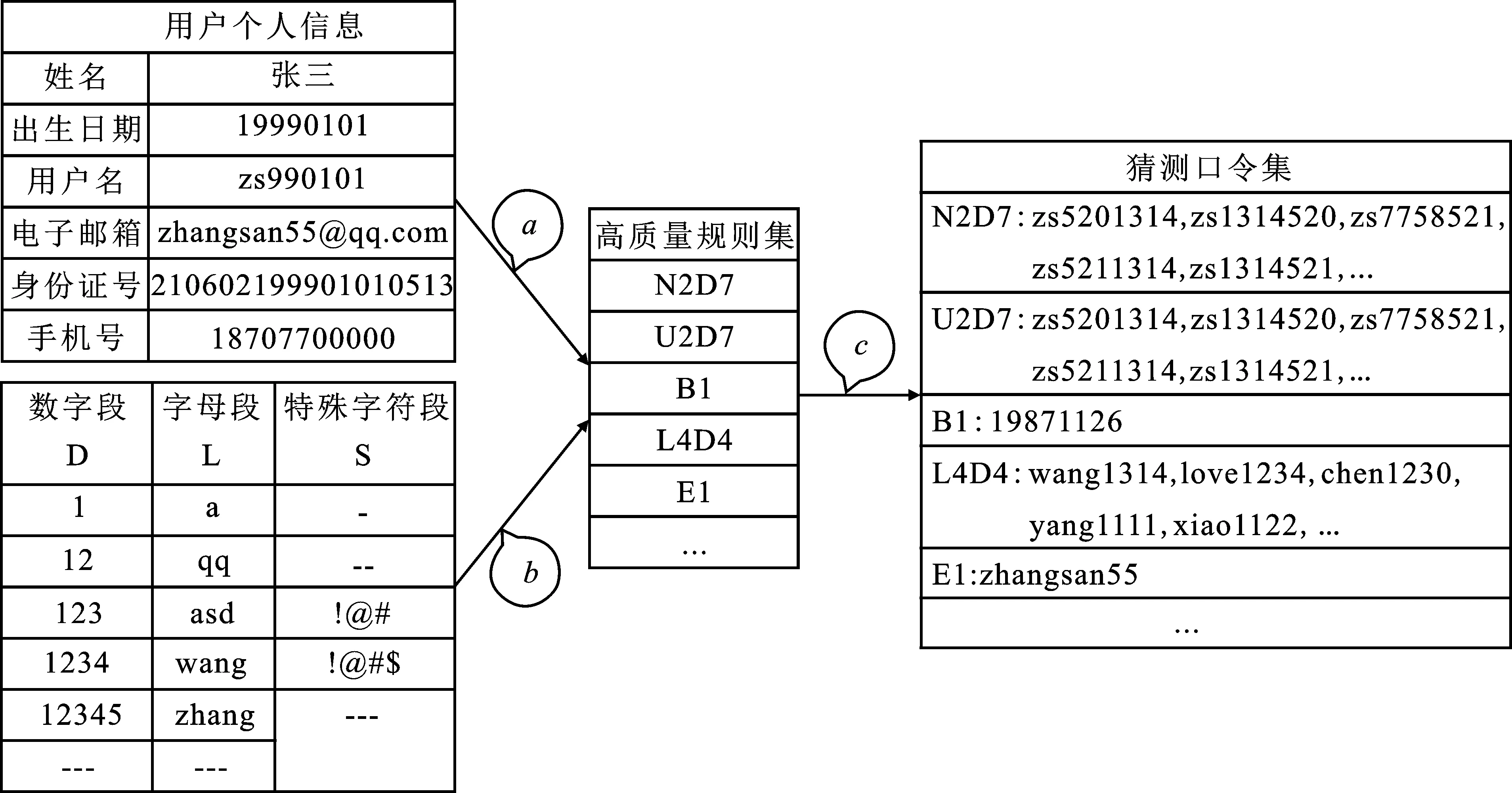
图4 定向猜测攻击模型的系统框架示意图
过程a表示将用户个人信息按照Nn、Bn、Un、En、In、Tn、Xi,j7种标签进行划分,其中n代表字段类型,i代表特殊字符串起始位置,j代表特殊字符串长度;过程b表示按照长度匹配L、D、S字段频次表中不同长度字符串;过程c表示将过程a、b中匹配到的字符串按照规则集中的规则序列恢复生成猜测口令。在猜测口令的生成过程中,规则序列“N2D7”除了使用用户的姓名全称缩写以外,还需要在长度为7的数字段列表中按照频率从高到低依次使用数字字符串序列,从而组合生成猜测口令列表,而“B1”则不需要,它仅需要按照用户出生日期的年月日格式并利用个人信息从而生成对应的猜测口令。
3 实验结果与分析
在中国铁路12306数据集上完成了基于个人可标识信息标签的口令解析实验、基于生成对抗网络的伪规则集生成实验以及基于前两者的口令猜测攻击实验,得到了基于PCFG的真实12306口令集对应的规则序列集,并将其作为训练数据输入经过优化的生成对抗网络,经过多次迭代训练,生成对抗网络输出高质量的伪规则集合;该集合不仅包括显在的规则序列,还包含潜在的新增规则序列,因此借助该伪规则集合匹配生成的猜测口令质量更高,从而提升了猜测成功率。在实验过程中,通过对伪规则集进行分析研究,得出伪规则集中符合规范的合法规则占比随着伪规则集规模的扩大而增加,并且伪规则与真实规则的相似度同样随伪规则集规模的扩大而增加,分别如图5和图6所示。在伪规则集规模为215时,规则合法率约达到86.48%,随着其规模增加至219的过程中,规则合法率一直稳定在83%以上。因此,可认为训练生成的规则集具有较好的合法率;同时,在伪规则集规模从215增至219的过程中,伪规则集与真实规则集的相似度保持在96%以上,并且呈上升趋势,所以可认为生成的伪规则集与真实规则集也具有较高的相似度。
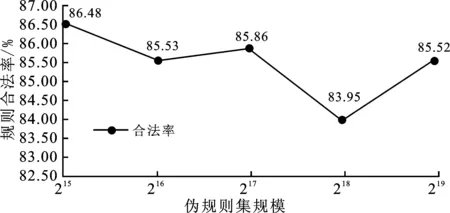
图5 不同规模伪规则集的合法率变化示意图
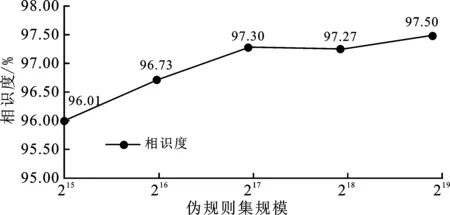
图6 伪规则集与真实规则集的相似度变化示意图
本节主要关注于定向口令猜测攻击的实验效果。实验与TarGuess-I模型一样,都使用中国铁路12306数据集,并尽量采用相同的实验配置,将数据集80%的数据作为训练集以及另外20%的数据作为测试集,在文中优化后的猜测攻击模型与TarGuess-I模型以及Personal-PCFG模型两种定向猜测模型上进行比较实验,实验结果如表2所示。

表2 定向猜测攻击效果
实验结果表明,优化后的定向猜测攻击模型在猜测规模为102时,成功猜测出36.70%的真实用户口令,在同等条件下,优于TarGuess-I模型以及Personal-PCFG模型,分别比后两种模型多猜测成功约16.5%、22.8%的用户口令。因此,笔者提出的口令解析方案能够进一步捕捉到用户构造口令的行为,并通过优化后的生成对抗网络模型对口令构造规则进行扩充,扩充后的伪规则借助在口令解析阶段获得的L、D、S段序列频次表以及目标用户的个人信息对其进行字段匹配,组合生成高质量的新口令序列,从而提高口令猜测的成功率。
4 结束语
针对用户使用个人信息构造口令的行为,笔者提出了一种基于PCFG并结合生成式对抗神经网络的定向口令猜测攻击方案。该方案由基于PCFG的口令解析模型以及基于生成对抗网络的高质量猜测生成模型组成。在口令解析的过程中,将解析口令的个人可标识信息标签进一步划分,使得解析后的口令最大程度地保留用户的行为习惯。在生成猜测的阶段,将解析后的口令以及噪声作为优化后生成对抗网络的输入数据,噪声经过网络中生成器和判别器的对抗训练,会更加关注并逐渐学习到真实解析口令的分布,再通过多次迭代训练得到包含真实口令规则和新增口令规则的伪规则集,利用伪规则集生成高质量猜测口令从而提高口令猜测成功率。通过在含有用户个人信息的铁路12306数据集上进行定向口令猜测攻击实验以及与其他方案的对比试验,验证了笔者所提方案的有效性。
在今后的研究工作中,将进一步改进生成式对抗网络的网络结构,以生成更高质量的猜测口令,进一步提升定向口令猜测攻击的成功率。
