蒙汉语音翻译数据集
2022-07-03戚肖克特尼格尔孙媛赵小兵
戚肖克,特尼格尔,孙媛,赵小兵*
1.中国政法大学,北京 102249
2.国家语言资源监测与研究少数民族语言中心,北京 100081
3.中央民族大学中国少数民族语言文学学院,北京 100081
引 言
语音翻译 (Speech Translation,ST),又称为口语翻译 (Spoken Language Translation,SLT),它的任务是将一种语言的语音转换为另一种语言的文本[1]。语音翻译是打破人类交流语言壁障的一项关键技术,应用较为广泛,如电影字幕、国际会议、旅游辅助等。
语音翻译技术建立在自动语音识别 (Automatic Speech Recognition,ASR) 和机器翻译 (Machine Translation,MT) 技术之上。近年来,随着计算机算力的提升、端到端神经网络方法的提出、数据的剧增等,ASR和MT领域都有了显著的进展,语音翻译也成为语音信号处理及自然语言处理领域的一个研究热点。
然而,受公开的数据集限制,目前ST方向的研究大多针对中英[2]、英德[3]、英法[4]、英日[5]等语言之间的翻译,较少机构研究面向少数民族语言的语音翻译。为了缓解这一问题,本文采集了年龄在20-25岁之间的36位蒙古族人员的语音,并由蒙汉专业人员标注了每个音频对应的汉语文本。经整合和预处理后,共得到25小时的有效蒙语语音数据,形成了蒙汉语音翻译数据集NMLR-Mon2Chs ST。本数据集不仅可供ST领域研究使用,还可用于ASR、MT、蒙语语音合成、说话人识别等方向的研究。
1 数据采集和处理方法
1.1 数据采集方法
蒙汉语音翻译数据集(NMLR-Mon2Chs ST)包含语音和文本两部分数据。语音数据由36位年龄在20-25岁之间的蒙古族说话人通过录制得到,这些说话人均来自于我国内蒙古自治区呼和浩特市。首先,准备蒙语文本,每位录音人员在安静的环境下,通过手机朗读文本的句子,进行录音,朗读的每句保存为一个wav格式的语音文件,文件名为朗读文本中的句序号,每个说话人的音频放在一个单独文件夹中。之后,由既懂蒙语又懂汉语的专业人员对每个语音文件标注对应的汉语文本。然后,整合语音和文本文件,并对其进行预处理,最终得到蒙语语音翻译数据集。
1.2 数据预处理方法
从36位录音人员处收集数据,数据的形式为每位说话人一个单独文件夹,文件夹内为以句序号命名的wav文件及对应的以句序号命名的蒙文和汉语文本。将此数据集称为原始蒙汉语音翻译数据集,对此数据集进行预处理,经过6个步骤后,可以得到最终的蒙语语音翻译数据集。具体的预处理步骤如图1所示。
第一步,去除空文件。由于说话人在录制过程中,存在误触、录制失败等问题,导致空语音文件的产生。因此,预处理首先要去除无语音数据的文件。方法为:设置一个阈值,当语音音频时长小于阈值时,认为该文件内不含有意义的语音数据,因此将从数据集中删除该音频文件。在本数据集中,设置阈值为0.2秒。
第二步,去除非蒙语存在的音频。在录制的蒙文文本中,存在非蒙文词,如2020、King、Uncle、Roger 等。由于数量较少,在预处理时简单地将这类文本数据及对应的语音数据从数据集中删除。
第三步,重采样。由于36位说话人在不同的时间不同的设备上录制语音,使得数据集中不同的音频文件采样率存在区别,如存在个别音频的采样率为44.1 kHz。为解决这一问题,对所有音频,重采样至16 kHz。
第五步,按照一定格式重命名音频,具体格式描述如第2章所示。
第六步,文本文件重组。原始蒙汉语音翻译数据集中每个音频都对应一个文本文件,不利于数据的处理。因此,将所有音频的文本加入音频名称作为文本标记,全部整合入一个文本中,形成最终的文本文件。
2 数据样本描述
本数据集为蒙汉语音翻译数据集,数据集中包含1个zip压缩包和1个文本文件。其中,压缩包内有一个名为wav的文件夹,大小为1.61 GB,未压缩时大小为2.68 GB。wav文件夹内包含36个子文件夹,每个子文件夹对应一位录音人员的语音数据,命名规则为录音人员的“姓名拼音”与“录制的音频的总时长(以分钟为单位)”。例如,子文件夹“ahei40”表示该文件夹下的音频均为“阿黑”录制,录制的语音总时长约为40分钟(由于预处理过程中去除了一部分无效语音,因此最终有效时长略小于此处标记的值)。子文件夹下为多个音频文件,每个文件的命名格式为“该音频所在的子文件夹名称-音频序号.wav”,如“ahei40-0001.wav”、“ahei40-0002.wav”等。对本数据集中36位录音人员录制的音频文件数目和音频总有效时长(以分钟为单位)进行统计,结果如表1所示。平均每位录音人员录制 597句,平均有效时长 41.7分钟。整个蒙汉语音翻译数据集中共包含21478个音频文件,有效时长为25小时。
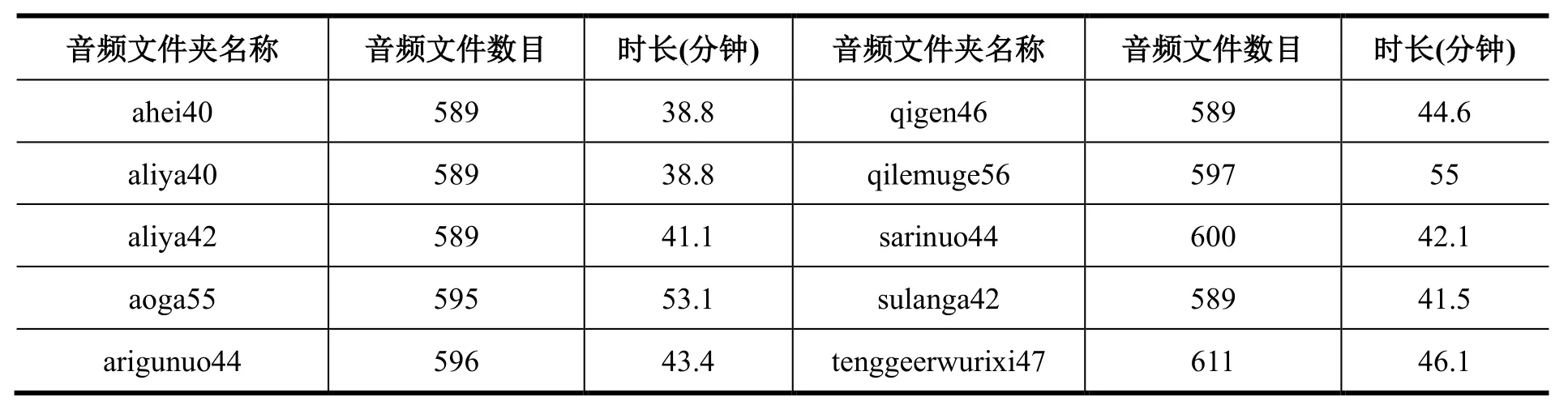
表1 36位录音人员的音频数据统计表Table 1 Audio data statistics table of 36 recordists
数据集中的文本文件名为text.json,大小为4.9 MB。每个音频文件对应文本中的一个字典,字典中的键“filename”“mon”和“chs”分别表示“音频文件名”“音频对应的蒙文文本”和“音频对应的汉语文本”,示例如表2所示。
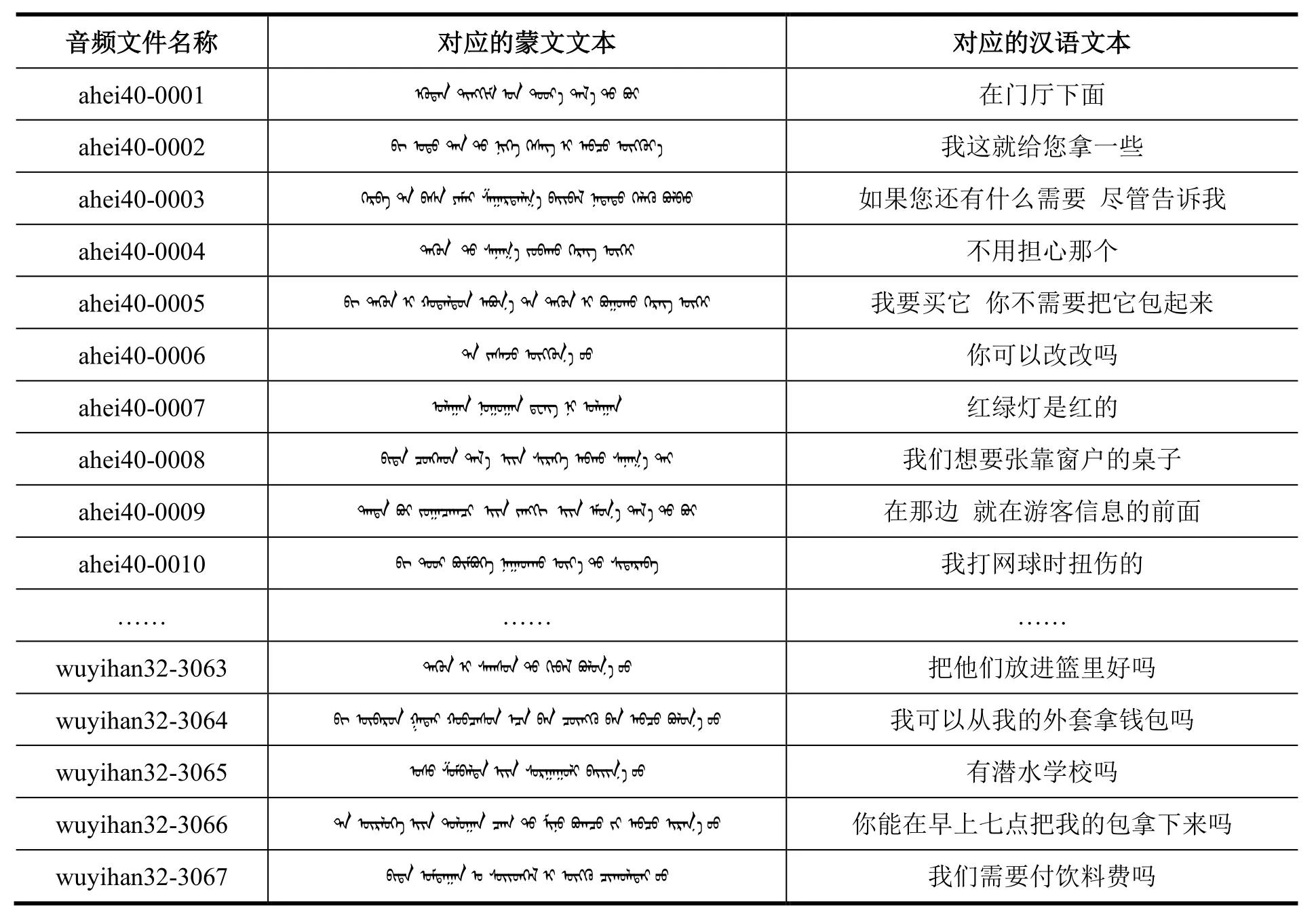
表2 音频对应的文本内容示例Table 2 Samples of text corresponding to audio
3 数据质量控制和评估
本蒙汉语音翻译数据集由36位蒙古族人员在安静环境中录音的音频文件、对应的蒙语文本以及汉语文本组成,在预处理阶段对音频和文本进行了质量控制,去除了无效的音频、非蒙文的句子等,确保数据的可靠性。对音频时长区间的分布进行分析,如图2所示,图中的柱状图表示不同音频时长区间在所有音频中的占比,折线图为不同音频时长区间在所有音频中的累积占比。从图中可以看出,50.7%的音频时长在2-4秒,97.8%的音频时长在8秒以内。同时,通过计算可以得出,本数据集中音频的平均时长为4.2秒。
4 数据价值
蒙汉语音翻译数据集中的语音来源于36位蒙古族人员,年龄在20-25岁之间,采用手机录制音频,文本由专门的人员标注,经过整合和预处理后得到25小时的可靠数据。本数据可为蒙汉语音翻译研究提供数据基础。此外,本数据集还可用作蒙语语音识别、语音合成、说话人识别等任务的测试集,同时也可作为训练集用于研究小样本下的任务。例如,蒙语语音和蒙文文本可用于小样本下的蒙语语音识别的研究。蒙文文本与汉语文本作为一对平行语料,可用于小样本下的蒙汉机器翻译的研究。平均每个说话人录制了约600句音频,可用于研究小样本蒙语语音合成或多说话人蒙语语音合成算法。语音数据按照说话人分别存储在不同的文件夹下,因此,本数据集也可用于小样本下的说话人识别研究。
致 谢
获取本数据集得到呼和浩特民族学院包乌格德勒、斯日古楞的大力支持,在此表示感谢。
数据作者分工职责
戚肖克(1985—),女,山东省菏泽市人,博士,副教授,研究方向为语音信号处理、自然语言处理。主要承担工作:数据集的预处理和整合、论文撰写。
特尼格尔(1990—),男,内蒙古自治区呼和浩特市人,博士研究生,研究方向为计算语言学。主要承担工作:数据采集与质量控制。
孙媛(1979—),女,山东省滨州市人,博士,副教授,研究方向为自然语言处理。主要承担工作:数据集前期整合。
赵小兵(1967—),女,内蒙古自治区呼和浩特市人,博士,教授,研究方向为自然语言处理。主要承担工作:数据质量控制与综合管理。
