基于TF-IDF和FastText的快速外卖评论情感分类研究
2022-07-02吴玉娟陈亚军
吴玉娟,陈亚军,谢 婷
(西华师范大学 计算机学院,四川 南充 637009)
0 引言
在快节奏的互联网时代下,越来越多的人使用外卖平台进行点餐,从而产生了大量的外卖评论数据,顾客可以根据评论的数量及内容择选商品,商家也能从正面和负面的评价中挖掘有价值的信息,进行食品、销售、产业结构的调整.外卖平台亦可以分析用户评论的情感态度进行其喜爱的食物推荐……可见对外卖评论进行情感分类的重要性.情感分类是自然语言处理中的一个经典问题,其是指根据文本所表达的含义和情感信息将文本划分成褒义或贬义的两种或几种类型,是对文本作者倾向性和观点、态度的划分[1],常被应用于舆情分析、商品评价分析等领域.情感分类的方法主要可以分为两类,一类是基于情感词典的方法,一类是基于机器学习的方法.基于情感词典的方法方便高效,但构建一个适用于大多数应用场景的词典比较困难,且实现效果与机器学习有一定差距.基于机器学习的方法分为传统的机器学习方法与神经网络,传统的机器学习方法需要依赖大量的手工操作和特征工程才能获得比较好的效果,通常适用于数据量比较小的情况[2].而神经网络能使用预训练词向量,其结构灵活,信息容量大,不需要大量的人工工程,适用于数据量比较大的情况.随着Word2vec[3]等词嵌入算法的发展,越来越多的神经网络模型被运用在情感分类领域,其中基于深度学习的情感分类算法诸如TextCNN[4],TextRNN[5]等在文本分类领域有着良好的表现,但其需要大量的数据做训练支撑,比较耗费训练时间.相比之下,FastText[6]只是一个简单的线性分类器,但它在较短的训练时间内也可以达到和深度模型相媲美的精度(短文本分类中),所以本文采用FastText模型来进行快速文本情感分类.
FastText模型不太好处理外卖评论数据集中的较长文本,一方面是难以提取到准确的文本特征进行情感分类,另一方面是它只能处理定长的文本,因此本文采用了TF-IDF[7]算法来提取长外卖评论中的特征,并组成新的短文本与短外卖评论一起送入FastText模型进行训练,能够在一定程度上解决上述问题.
1 相关工作
Word2vec是词嵌入的一种方法,在自然语言处理中,必须要将非结构化的文本转变成结构化的向量,机器才能够进行运算.Word2Vec有两种训练词的方法,Skip-gram和CBOW,前者用目标词预测上下文,后者用上下文预测目标词.两者训练的目的都是为了获得训练的副产物—词嵌入矩阵.与独热向量相比,Word2vec能将自然语言中的词转化为稠密的向量,从而减少计算的消耗,并且语义相似的词会有相似的向量表示.本文采用Skip-gram模型来进行词的训练.
2 基于TF-IDF和FastText的情感分类模型
2.1 概述
网络现存的外卖数据参差不齐,其平均长度在20~40之间,大多数外卖评论的文本长度较短,但仍有少部分外卖评论文本长度较长,在一百到几百字之间.这些较长的外卖评论会导致分类模型难以提取到准确的文本特征和语义,在将这些较长外卖评论送入FastText模型进行训练时,若将其直接按所设置的pad-size进行截取,大概会损失掉后半部分的语义、导致训练不准确,而若将pad-size设置为数据集中最长文本的大小,不仅会导致短评论里被填充大量无效内容、影响分类效率,还会导致模型难以提取到较长外卖评论的准确特征.鉴于以上情况,本文设计了基于TF-IDF和FastText的情感分类模型来解决这一问题,整个模型的流程如图1所示.首先对外卖数据集进行数据清洗和预处理,接着利用TF-IDF算法提取较长外卖评论中的准确特征,TF-IDF算法处理过的较长评论文本长度变短,保留了关键特征、更有利于分类.然后将剩下的数据和处理过的较长评论进行整合,输入Fasttext模型进行文本表示和快速分类得到结果.

图1 TF-IDF-FastText流程图
2.2 TF-IDF较长外卖评论特征提取
TF-IDF算法是词频-逆文本频率算法,用来提取文本中的重要特征.其主要思想是:一个词语的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比(除停用词外).TF即词频,反应了一个词语出现在它所在文档的次数,公式1为TF的计算方法,其中Nw表示某一文本中词w出现的次数,N是该文本总词条数.IDF即逆向文档频率,反应了一个词语在整个文档中出现的频率,公式2为计算IDF的方法,其中Y是语料库的文档总数,Yw是包含词条w的文档数.TF-IDF等于TF的值乘上IDF的值,如公式3.一个词的TF-IDF值越大表示该词对这个文本的重要性越大,在对文本进行关键词提取的时候越容易被保留,而TF-IDF值越小的词则越容易被丢弃.在已经预处理过的评论数据输入分类模型之前,对每条数据的长度进行判断,如果数据的长度超过所设定的阈值,则进行TF-IDF关键词提取,提取的关键词个数由具体实验而定,TF-IDF程序会自动按照提取出的关键词的权重进行排序,越靠前的关键词权重越大,对文本也越重要.抽取出来的词构成关键子句,能有效的表达原句的语义.然后将抽取出的关键子句与短外卖评论进行整合,一起送入FastText模型进行训练.
(1)
(2)
TF-IDF=TFw*IDFw
(3)
2.3 Fasttext快速分类模型
FastText模型是一个快速文本分类器,其结构共有三层,如图2所示,第一层是输入层,输入的是构成文本的词向量及其N-Gram特征[8],N-Gram是一种基于统计语言模型的算法,它的基本思想是将文本里面的内容按照字节进行大小为N的滑动窗口操作,形成长度是N的字节片段序列.常用的N-gram特征是Bigram和Trigram,它们的滑动窗口分别为2和3.例如“你今天喝水吗”的Bigram特征是“你今,今天,天喝,喝水,水吗”.N-gram向量在一定程度上可以作为文本的特征补充、并保持文本的局部顺序,但补充的N-gram向量太多又会影响计算效率和内存.
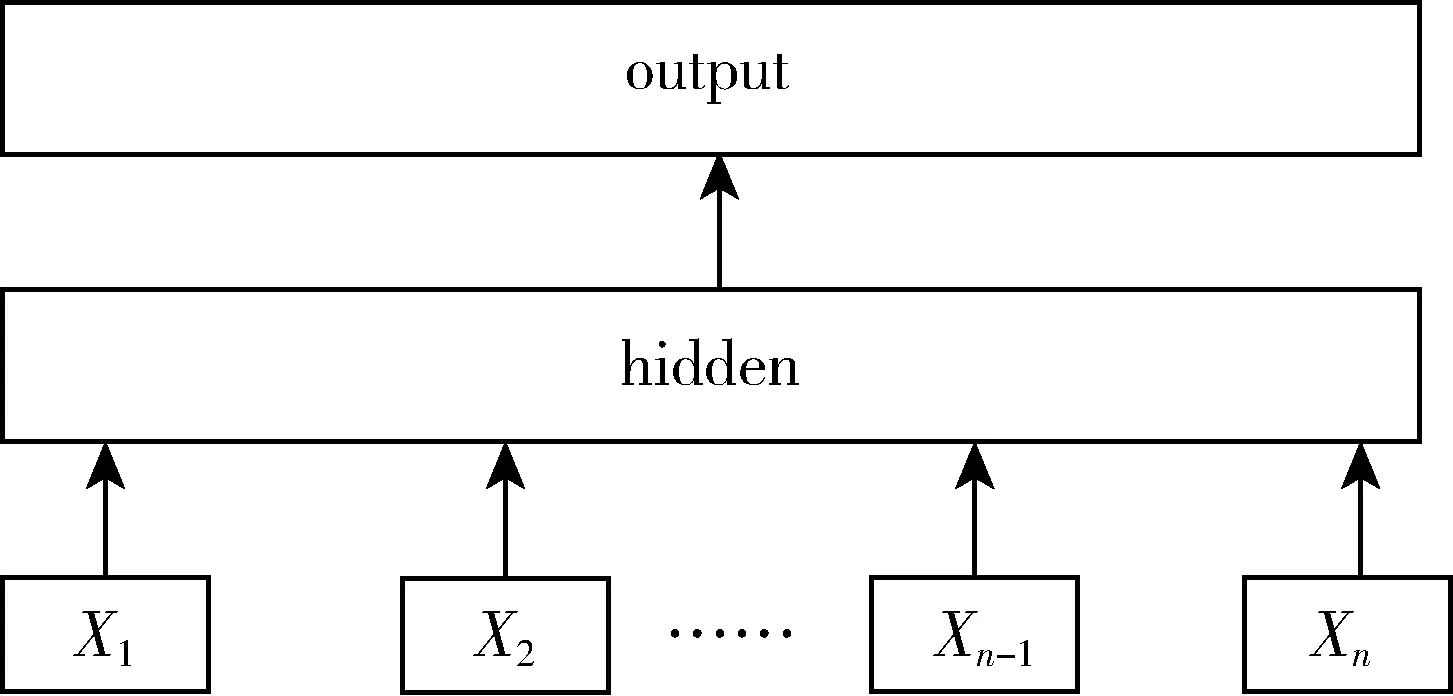
图2 FastText模型结构
第二层是隐藏层,隐藏层用来生成表征文档的向量.即对输入层输入的词及N-gram词向量进行平均池化操作.
第三层是输出层,输出层将隐藏层生成的文档向量做Sigmoid二分类,其中Sigmoid函数的作用是将输出空间限制在0到1之间,在此基础上加上二分类阈值以实现输出结果的离散化.对于任意一个输入xi,y(i)是其真实的类标,hθ(z)是其预测的类标.输出层的目标就是利用梯度下降使公式4的损失函数最小化.若做多分类任务,输出层可以采用Softmax分类,若分类的类别很大,可以采用分层SoftMax来解决模型运行耗时的问题.
(4)
(5)
z=x*θ
(6)
当所有的长外卖评论被处理好后,再将所有的数据进行整合并送入FastText模型进行分类.为了更加精确的表达文本的语义,实验尝试着对每条数据进行N-gram特征补充,补充的N-Gram特征分别为Bigram和Bigram+Trigram,再在隐藏层进行平均池化,最后将隐藏层生成的文本表征输入Sigmoid分类模型,判断每条评论是正面评价还是负面评价.
3 实验与分析
3.1实验环境
实验环境采用win10 64位操作系统,处理器为lntel(R)Core(TM)i9-9900K CPU @3.60GHz 3.60 GHz,内存(RAM)大小32.0 GB,Python版本3.8,torch版本1.1.
3.2 实验数据
实验外卖数据集来源于网络,抽取的是某外卖平台的外卖评论数据,最长的评论有452个字,最短的评论只有3个字,共11 987条,其中正面评价4 000条,负面评价7 987条,正负比例约为1∶2,从中随机抽取了9 000条做训练集,1 200条做验证集,1 200条做测试集,训练集、测试集、验证集各不相交,且正负评价的比例都为1∶2.数据集样本如图3所示.

图3 数据集样本
3.3 数据预处理
对该外卖数据集进行数据清洗后,采用jieba分词工具进行分词,并利用中文停用词典去除停用词,针对情感分类问题,本实验对停用词典进行了一定的修改,在停用词典里增加了一些与外卖评论语义无关的符号,去除了停用词典中一些与表达情感有关的停用词,以保证数据集的准确性.
3.4 实验评价指标
本实验采用精确率、召回率、F1值来评价模型效果[9],公式如下,其中TP为真正类,TN为真负类,FP为假正类,FN为假负类.精确率P强调查准率,召回率R强调查全率,F1-score是综合评估模型查准率和查全率的指标.
P=TP/TP+FP
(7)
R=TP/TP+FN
(8)
F1=2*P*R/P+R
(9)
3.5 实验结果分析
本实验采用Python编写,输入模型的数据以Word2Vec训练的300维度的字向量表示,经过不断的调试最终选取超参数,lr=0.001,epoch=30,dropout=0.5,minibatch=256,N-gram=1.判定较长文本的阈值设定为100,关键词提取个数为20.实验过程中训练集的准确率与损失变化如图4所示,实验结果如表1所示.

图4 训练集的准确率与损失变化

表1 本模型实验结果
表1可以看到,本模型在外卖情感分类任务中有着不错的表现,在3s中达到了90.23%的准确率.负面评价的精确率达到了91.67%,召回率达到了93.82%,F1值达到了92.73%.负面评价在预测中表现的更好,有一部分原因是负面评价在该数据集中比正面评价多,为了比较模型效果,本模型还与TextCNN,TextRNN,TextRNN_Attention[10],Transformer[11]模型做了对比实验,实验结果如表2所示.
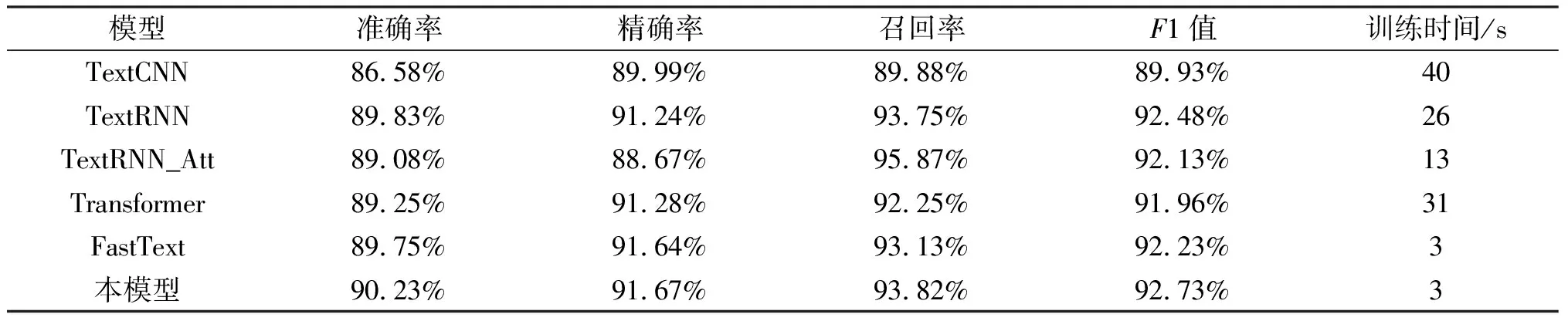
表2 模型实验对比
表2可以看出,基于TF-IDF-FastText模型在该数据集上的准确率比TextCNN高出了3.65%,比TextRNN高出了0.4%,比TextRNN_Attention高出1.15%,比Transformer高出0.98%模型,且在三项评价指标上都普遍优于其他模型.其他模型的训练时间都比本模型长,本模型的训练时间只有3秒,说明本模型适合对外卖情感进行快速的分类.
实验还探究了最适合本模型的N-gram特征,以及mini_batch大小,探究结果如下所示:
图5表明,本模型选择过大或过小的batch_size准确率都会有所下降,当选取batch_size大小为256时,模型的准确率最高.图6表明,当给输入模型的文本附加N-gram特征时,模型的准确率会下降,训练时间也增加了很多.例如,给模型添加Bigram特征时,准确率下降了0.87%,运行时间增加了27 s,给模型同时添加Bigram特征与Trigarm特征时,训练时间达到了50 s,准确率也没有提高,而不采用N-gram特征时,模型的效果最好,训练时间最少.推测是因为N-gram特征对中文不太敏感[12],并且对TF-IDF提取的长外卖评论特征本身所表达的情感语义产生了影响.
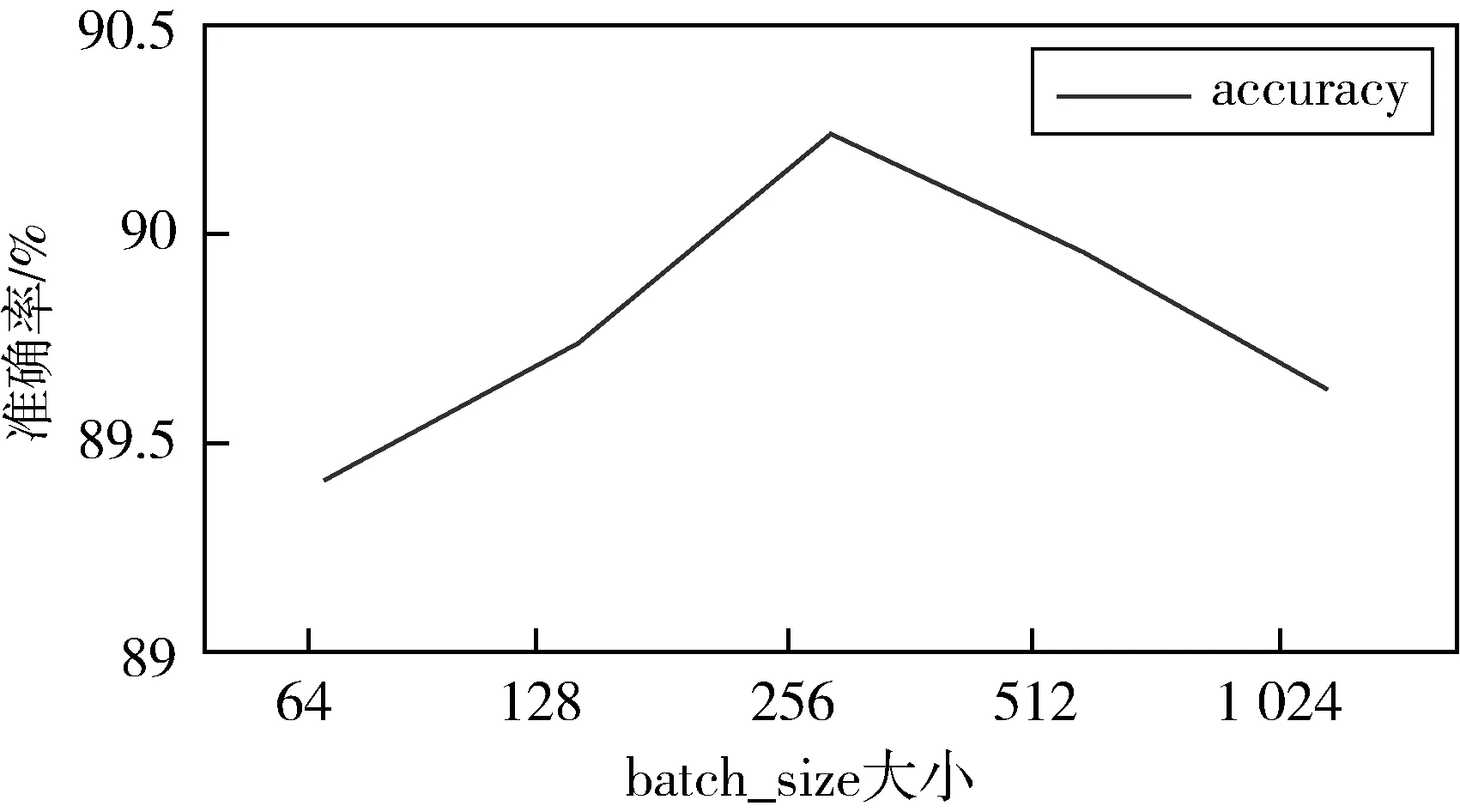
图5 batch_size大小与准确率

图6 N-gram大小与准确率
4 结束语
本文采用了基于TF-IDF和FastText的模型对外卖评论进行分类,在一定程度上解决了FastText模型难以提取准确长外卖评论特征等问题.实验数据表明,本模型能在非常短的时间内对外卖评论的情感进行基本的正负向判断,准确率达到了90.23%.实验最后也探究了N-gram大小与模型准确率的关系,说明N-gram特征对FastText模型的加持,并不适用于所有问题.
