基于深度学习的变电站钢结构图纸标题栏文字检测与识别
2022-07-02秦辞海顾万里
秦辞海 顾万里
(国网上海市电力公司,上海 200120)
引言
随着社会经济的发展,越来越多的变电站采用钢结构形式,在这些变电站工程建设中,钢结构施工占据了举足轻重的位置。目前,国内工程公司通过派驻代表长期驻守施工现场配合施工来实现变电站钢结构施工相关管理。在材料及进场验收、施工安装、后期维护等重要环节,由于信息采集不及时、不准确、标准不统一等因素,对相关管理工作造成了极大的困扰,因此,有必要基于数字信息化实时反馈技术,对供货情况、出厂质量与现场验收情况进行实时掌握与反馈,通过数字信息规划卸货、吊装与安装,直观地掌握钢构件框架完成后的全貌。识别变电站钢结构相关图纸所列钢构件清单,生成与清单上所列构件相对应的钢构件编码,并生成后台数据库是建立实时反馈控制管理的重要环节。由于部分变电站钢结构图纸标题栏图像结构复杂、扫描不清晰,文字大小不均匀,给文本的检测与识别带来困难,传统基于光学的检测识别方法难以满足需求。
近些年随着计算机算力的增加,深度学习方法在图像识别领域得到空前发展,成为了文本检测与识别的核心算法之一。文本检测与识别的研究一直在进行,从传统文字切割光学文字识别技术OCR[1,2],到现在的深度学习网络模型技术,检测与识别效果有了很大的进步。黄娜君等人[3]通过对采集到的图像进行处理,分割出交通标志所在的感兴趣区域,利用深度卷积神经网络模型进行一系列的卷积和池化处理,最后通过一个全连接的 BP 网络完成分类识别,输出结果。P.He等人[4]采用级联多个卷积模型来实现准确预测,并在此基础上开发了分层模块,但是对弯曲或者倾斜文本检测效果欠佳。B.Shi 等人[5]提出的文本检测方法SegLink,它将文字分解为片段和链接两个类别,片段是覆盖字符或文字行的一部分,通过链接能够组合多个定向框,然后采用全卷积网络进行端到端的训练,最后在多尺度上对两类元素进行密集检测,从而获得检测结果,但是对文本行相距太远的情况,该方法检测效果不好。Z.Zhang等人[6]提出采用完全卷积网络以整体的方式预测文本区域,再结合显著图和字符成分来估计文本行假设,最后使用分类器去除假设,但是无法准确区分边框特征的敏感程度。Wang 等人[7]将大型多层神经网络的表征能力与无监督特征学习结合起来,采用端到端的方法,在定位自然场景图像中的字符区域,识别出字符方面取得显著效果,然而对中文检测识别效果不明显。这些方法在某些场景检测识别效果好,但是针对钢结构图纸中格式多样、文字模糊、大小不均等场景,检测识别效果不甚理想。
鉴于上述各种方法的局限性,本文提出了通过卷积神经网络与循环神经网络相结合的文字检测与识别方式,并将该方法运用到变电站建筑工地钢结构图纸标题栏图像文本检测识别中,解决钢结构图纸标题栏图像难检测、难识别的问题。然后,将识别出的信息传输到建立的数据库中,方便变电站钢结构施工质量管控。
本文研究内容主要分为两部分:一是文本检测,二是文字识别。在文本检测之前,要对输入的变电站钢结构图纸标题栏图像进行尺寸缩放、去噪等预处理; 检测出文字后,将文字区域分割出来,传入到文字识别模型中,进而得出图像文字信息,传输到指定数据库。
在结果分析中,本文设计了对比实验。一是对同一训练集,将本文检测方法与其他方法的检测结果进行对比; 二是采用不同训练集训练本文的文字识别方法,最终识别结果进行对比。最后,得出检测识别钢结构图纸标题栏图像中文字的最优模型,为智能实时管控做前期准备。
1 本文模型
1.1 文本检测方法
文本检测需在图像中定位检测到文字,传统的文本检测方法在OCR领域中获得不错的效果,但是对于复杂场景的检测中完全落后基于深度学习的检测方法。基于深度学习的文本检测方法模型,泛化能力强,对高层语义特征的识别更加稳定。卷积神经网络(Convolutional Neural Networks,CNN)[8]是常用的特征提取网络,在图像文字特征提取方面取得了很好的效果。本文采用VGG16模型[9],对预处理过的图像进行文字特征提取,使用循环神经网络(Recurrent Neural Network,RNN)[10]编码水平行的文字位置信息,全连接层进行分类,再经过非最大值抑制处理,得到最终检测结果。文本检测主要目的是为了检测出文字所在的区域,生成文字图像片段,作为后续文字识别的输入。
图1是VGG16网络的结构,它所有卷积层采用3像素×3像素的小尺寸卷积核,卷积步长为1。为保证卷积后图像大小不变,图像四周各填充一个像素。所有池化层都是2像素×2像素的核,步长为2。所有隐层的激活单元都是ReLU函数。
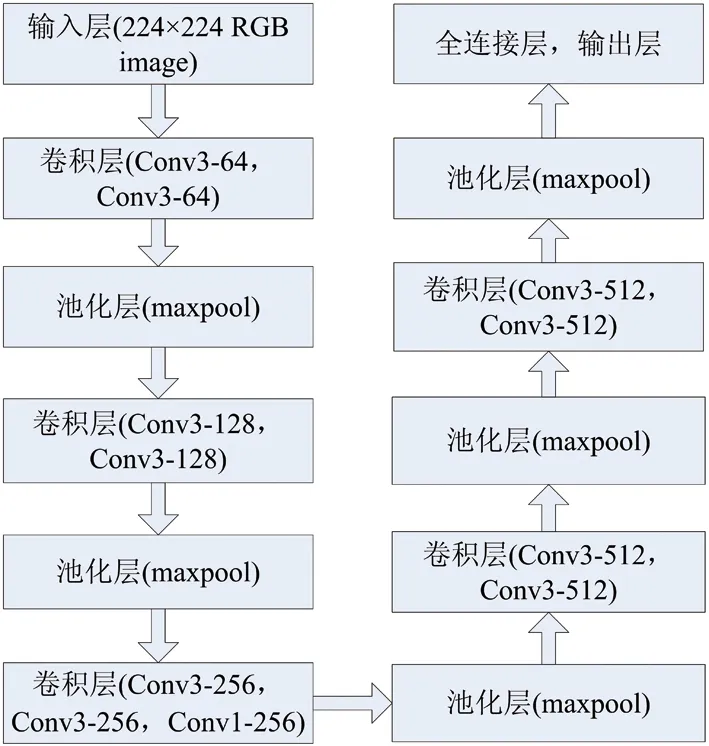
图1 VGG16网络结构
循环神经网络由输入层、循环层和输出层构成,其具有记忆功能,会记住网络在上一时刻运行时产生的状态值,并将该值用于当前时刻输出值的生成。循环神经网络的输入可抽象表示为向量序列:
x1,x2,…,xi,…,xt,
(1)
其中,xi是向量,下标i表示时刻。网络每个时刻接收一个输入xi,并产生一个输出yi。yi由之前的输入序列共同决定。在循环层中,t时刻的输出值是ht,它由上一时刻的输出值ht-1以及当前时刻的输入值xt共同决定,即
ht=f(ht-1,xt)
(2)
其中,f为激活函数,一般选用tanh函数,形如
(3)
标准的RNN会有梯度消失或者梯度爆炸问题。为避免这个问题,本文采用比较主流的LSTM方法[10]。LSTM是对循环层单元进行改造,主要由三个门组成:输入门、遗忘门和输出门。LSTM的网络单元结构如图2所示。图中,ht-1是循环层中t-1时刻的输出值;ct-1是t-1时刻的状态值;xt是t时刻的输入值;ht是t时刻的输出值; 输入门表示为It=σ(Wi[ht-1,xt]+bi),控制着当前t时刻的输入xt有多少可以进入当前状态Ct; 遗忘门为Ft=σ(Wf[ht-1,xt]+bf),决定了上一时刻的值ht-1有多少会被传递到当前状态Ct; 输出门为Ot=σ(Wo[ht-1,xt]+bo),根据当前状态Ct、上一时刻的值ht-1和当前时刻的输入xt来决定当前时刻的输出ht;σ是sigmoid函数,Wi、Wf、Wo是权重参数,bi,bf,bo是偏置参数。通过“门”的结构,有选择性的影响循环神经网络每个时刻的状态,输入门作用于当前时刻输入值,遗忘门作用于上一时刻的输出值,二者加权和,得出当前时刻状态;最后与输出门共同决定输出值,预测出文字序列位置信息,生成文字图像片段。

图2 LSTM单元结构
1.2 文字识别方法
文字识别模型复杂多样,本文主要运用基于深度学习的卷积循环神经网络(Convolutional Recurrent Neural Network,CRNN)[11],进行钢结构图纸标题栏图像内容的文字识别,它是通过端对端地解决基于文本检测结果图像的不定长的文字序列识别问题。CRNN将CNN与RNN相结合,把特征提取、序列建模和转录整合到统一的神经网络架构中。CRNN网络结构如图3所示,CRNN模型主要分为两个部分:一部分为特征提取,由多个卷积层、池化层和激活函数组成; 另一部分是序列预测,由循环层RNN和转录层CTC模型组成。CTC是不定长字符识别,具有归纳字符连接间的特性,可解决输入序列和输出序列对应关系未知的问题。本文识别模型是使用CNN从文本检测结果图像中提取特征序列,传递给循环层RNN预测出特征序列的时序和种类,最后CTC是把时序和种类通过去重整合等操作转换成最终的识别结果。

图3 CRNN网络结构(其中X、Y代表不同的网络神经元,Softmax是分类函数)
2 模型训练
文本检测训练模型,数据集采用ICDAR 2017[12],损失函数采用交叉熵与定位损失相加权的方式,即
L(p,u,tu,v)=Lcls(p,u)+αLloc(tu,v)
(4)
其中,交叉熵为:
Lcls(p,u)=-∑plog(u)
(5)
定位损失为:
Lloc(tu,v)=∑smooth(tu-v)
(6)
式中,p是类别概率值;u是类别,tu是第u类预测矩形框,v是真实矩形框,α是人工设定的参数;smooth是一个光滑分段函数,表达式为:
(7)
文字识别训练数据集是在不同图纸中截取的文字,训练集800张,验证集300张。损失函数采用负对数条件似然函数,即
(8)
式中,χ表示训练数据集,Ii代表训练数据集中的一张图像,li是对应标签序列标注,yi表示对应预测概率分布序列。
3 评测指标
3.1 文本检测评测指标
目标检测常见的评测指标[13]是精确率(Precision)、召回率(Recall)和F1-度量(F1-score)。根据预测标签与实际标签定义的关系,精确率为:
(9)
召回率为:
(10)
F1-度量为:
(11)
其中,TP为实际标签为正例,预测标签为正例;FP为实际标签为负例,预测标签为正例;FN为实际标签为负例,预测标签为负例。F1-度量越高,说明实验方法越有效。
3.2 文字识别评测指标
在文字识别中,识别效果的评测指标主要是单字识别准确率AR(Accurate Rate)和整行识别率LA(Line Accurate)。单字识别准确率AR是文本行中正确识别的字符个数占总字符个数的比例。整行识别准确率LA是文本行中完全识别正确行的比例,即
(12)
其中,Nt指整行识别正确行数量,Na指整个图像测试集行数量。
4 工程应用结果与分析
4.1 图像文本检测结果分析
本文是在NVIDIA GeForce GTX 1070Ti的GPU工作台,基于谷歌公司Tensorflow平台进行开发测试,训练采用Adam优化器,初始学习率0.001,每1 000次迭代,学习率下降为之前的0.95,其他参数默认。在ICDAR 2017数据集上,分别对SARI FDU[14]、Wenhao He et al[15]和本文模型进行训练。根据训练完成的模型分别对大量经预处理的藴藻浜—闸北220kV线路装设统一潮流控制器工程变电站的钢结构图纸标题栏模糊图像和清晰图像进行测试。图4绿色框是本文模型的检测结果,从图中可以看出,本文模型钢结构图纸标题栏模糊图像(如图4(a)所示)与图像清晰(如图4(b)所示)文本检测结果相近,基本可以正确检测出文本文字片段。

(a)变电站钢结构图纸标题栏模糊图像文本检测结果
对于不同训练集训练的模型,根据上文3.1文本检测评测指标,其评测结果如表1和表2所示。从表中可以看出,同一数据集,使用不同的方法进行训练,最终预测的结果存在一定差异,本文检测模型的评测指标优于SARI FDU、Wenhao He et al.两个方法,在清晰图片上的文本评测对比更加明显。

表1 不同方法在ICDAR2017数据集上的模糊图片文本评测对比
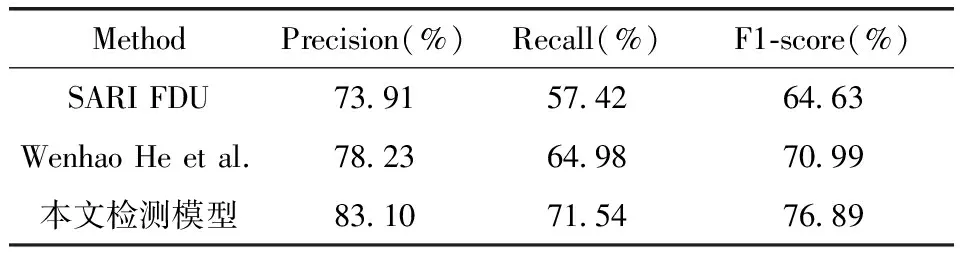
表2 不同方法在ICDAR2017数据集上的清晰图片文本评测对比
4.1 图像文本检测结果分析
检测出图像文字后,采用CRNN在不同数据集上训练后的模型,分别对变电站钢结构图纸标题栏模糊图像和清晰图像进行文字识别,识别结果如图5所示。从图5中可以看出,本文识别方法基本可以正确识别出模糊图片(如图5(a)所示)和清晰图片(如图5(b)所示)的文字信息。

(a)模糊图像文字识别测试结果
通过大量图像测试,根据上文3.1文字识别评测指标,其评测结果如表3和表4所示。从表中可以看出, 通过本文数据集训练的CRNN模型测试钢结构图纸标题栏图像的单字识别准确率和整行识别准确率是高于MSRA-TD500、ICPR2018数据集。主要原因是针对测试图像,进行了针对性的训练,特别是训练集中含有大量的钢结构图纸标题栏图像。

表3 CRNN模型在不同数据集训练模糊图片文字识别测试结果
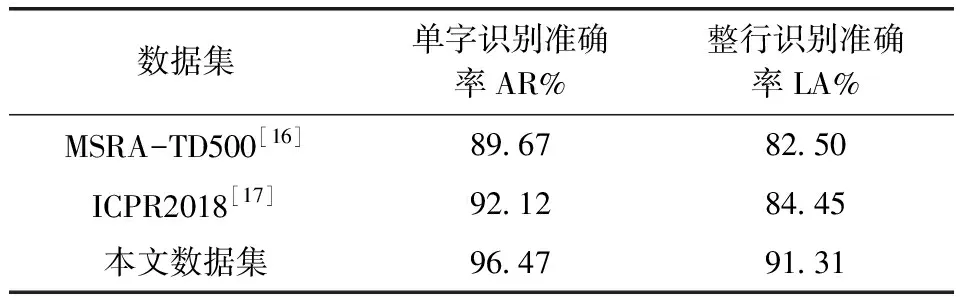
表4 CRNN模型在不同数据集训练清晰图片文字识别测试结果
4 结论
本文提出了一种CNN与RNN相结合的变电站工程钢结构图纸标题栏文本检测与文字识别模型。在文本检测中,同一训练集下分别对模糊和清晰的图像进行测试,工程应用结果表明本文所采用的方法检测精确率达到80%以上,整体优于文中提到的SARI FDU、Wenhao He et al.两个方法。
在文字识别中,通过不同的训练集训练CRNN模型,分别对已经检测定位的模糊图像和清晰图像文字进行识别,工程应用结果表明在测试图像中,本文数据集模型识别准确率达90.87%以上,识别效果高于MSRA-TD500、ICPR2018数据集。
本文模型有效检测、识别出了变电站钢结构图纸标题栏图像的主要信息,可有效应用于变电站建筑工地钢结构数据库的建立与实时管理。
