基于多强化学习智能体架构的电网运行方式调节方法
2022-07-02项中明徐建平尚秀敏杨靖萍刁瑞盛
叶 琳,项中明,张 静,徐建平,吕 勤,尚秀敏,杨靖萍,刁瑞盛
(1.国网浙江省电力有限公司,杭州 310007;2.国网浙江省电力有限公司金华供电公司,浙江 金华 321000;3.国电南瑞南京控制系统有限公司,南京 211106)
0 引言
新型电力系统的安全、经济运行是非常复杂的控制问题,需要同时满足电压、频率、线路潮流等多种安全约束。近期碳达峰、碳中和的能源政策及相关行业标准将极大促进绿色能源发展,可再生能源在电网中的占比将不断提高。但由于风能、太阳能的间歇性、动态性和随机性,高渗透率的可再生能源对电力系统的安全和经济运行带来巨大挑战。
为了制定安全且经济的电网运行方式,通常针对可能出现的运行工况对电网进行建模、仿真、分析,一旦发现安全问题,需采取相应的控制措施来降低基态和故障(“N-1”或“N-k”)情况下的运行风险。该过程需要考虑电力负荷预测、基建计划、检修计划、发电机组启停及发电计划等因素。由于该问题的高复杂度和高非线性,电网合理运行方式的制定通常需要依靠工程师经验,对电网模型及参数进行大量人工调整和海量的仿真分析,以得到满足要求的电网运行方式。然而,考虑大电网负荷变化、可再生能源波动和故障等各种不确定性因素下,精准、快速地制定潮流控制策略变得十分困难[1-6]。因此,新型电力系统迫切需要一种有效的自动化方法来实现上述目标。
1 基于人工智能的控制方法
近年来,随着人工智能技术的快速发展和演变,深度强化学习算法在多种控制领域表现优异,这类控制问题可以归结为MDP(马尔可夫决策过程),其典型成功应用案例有AlphaGo、自动驾驶汽车和机器狗等,这些成功案例为有效解决电网规划和调控难题提供了借鉴[7-15]。本文提出一种基于多强化学习智能体架构的电网运行方式调节方法,为解决电网运行方式的自动制定提供一个通用平台。首先,将电网运行方式制定的问题描述为MDP,收集电网潮流信息形成状态空间(包括线路功率、母线电压、发电机输出功率和电网负荷等信息),将多种控制目标和安全约束建模为强化学习智能体的奖励值(包括基态奖励值和故障工况奖励值)。其次,提出两阶段的智能体训练框架,可使用多个强化学习智能体来自动调节不同类型的可控资源。在第一阶段使用发电机有功调整进行集中式训练,其控制空间由选定的发电机有功功率集合构成;在第二阶段使用局部变电站负荷转移进行分布式训练,其控制空间由变电站负荷有功功率构成;在每个负荷转移控制空间中,所选中的变电站之间的负荷有功总和与功率因数保持不变。大量的数值仿真试验结果表明,该方法在考虑多种故障工况下可调节传输线路功率,自动搜索得到满足电网安全约束的运行方式。
本文首先介绍电网运行方式的数学模型和安全约束,以及SAC(最大熵)强化学习算法;然后给出所提方法的技术方案细节,包括多智能体框架设计、奖励值设计、状态空间和控制空间的制定以及算法的实现流程;最后,在某实际电网模型中验证该方法的有效性。
2 电网运行方式模型与强化学习算法
2.1 电网运行模型
本文主要考虑电网规划和运行中的准稳态,包括故障前的基态以及故障后的运行工况。为了保证电网的安全运行,需时刻满足多种安全约束条件。为了描述电力系统的稳态特性,通常对发电机、母线、负荷、输电线路和变压器等电力元件进行建模,形成相应的代数方程。潮流求解通常使用牛顿-拉夫逊计算方法,得到有效的解。电网的准稳态运行模型由式(1)—(12)给出:
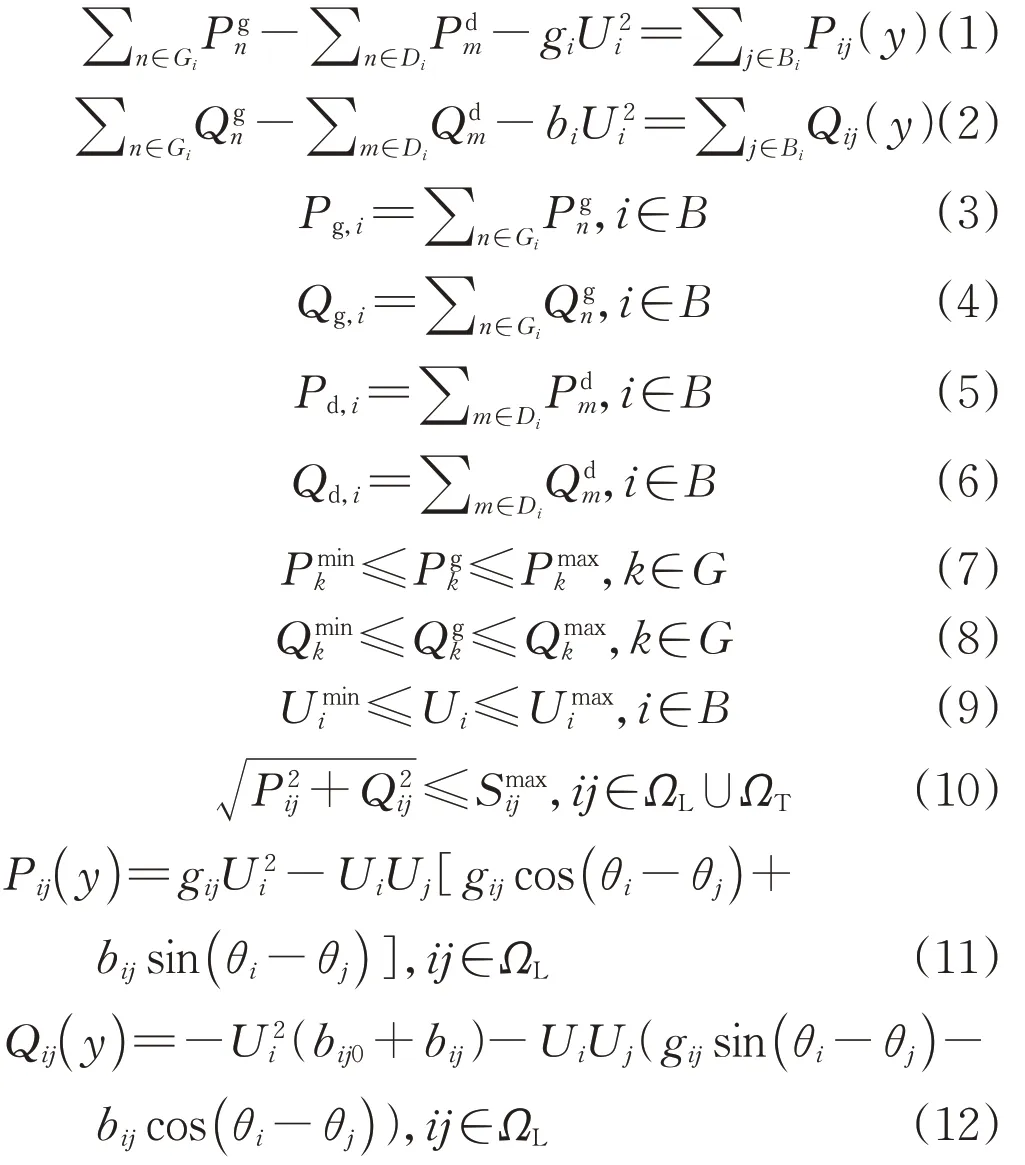
式中:Gi、Di、Bi分别为与母线i相连的发电机集合、负荷集合、母线集合;和分别为发电机n输出的有功功率和无功功率;和分别为负荷m的有功功率和无功功率;gi和bi分别为母线i的电导和电纳;y为线路标识;Pg,i和Qg,i分别为母线i的发电机有功功率和无功功率;Pd,i和Qd,i分别为母线i的负荷有功功率和无功功率;和分别为发电机k的有功功率下限和上限;和分别为发电机k的无功功率下限和上限;和分别为母线i电压幅值Ui的下限和上限;为线路ij的视在功率上限;gij和bij分别为线路ij的电导和电纳;bij0为线路ij的初始电纳;θi和θj分别为母线i和j的电压相角;Pij和Qij分别为从母线i到母线j的有功功率和无功功率;ΩL为传输线路集合;ΩT为变压器集合。
式(7)—(10)为电网安全运行的不等式约束,分别描述各种电力设备的安全极限,要求所有的线路潮流、发电机输出和电压幅值均运行在其物理极限以内。
电网合理的运行方式可考虑多种控制目标,即在满足上述所有约束条件的同时,尽量减少发电成本或输电网损。以最小化发电成本为控制目标见式(13),以最小化输电网损为控制目标见式(14):

式中:c(k)为发电机k的发电成本;Ploss(ij)为线路ij的网损。
2.2 强化学习算法
强化学习算法是人工智能的一个重要分支。与监督式学习和无监督式学习不同,强化学习智能体的训练过程需与物理系统或仿真环境不断互动,通过观测状态空间给出相应的控制动作,从环境中获得奖励值。强化学习智能体通常使用大量的样本训练,以最大化奖励值的积累,达到既定控制目标。使用强化学习算法的控制问题可建模为MDP,包括状态空间S、动作空间A、转移概率p、奖励函数R。在每个控制迭代步骤t中,智能体在状态空间S中观察状态为st,在A中选择并执行动作at,获得一个标量奖励值r(st,at)。智能体的决策行为定义为策略π:p(A)←S,该控制策略将状态空间映射到控制动作的概率分布。强化学习智能体的控制性能好坏通常用Q值函数来描述,智能体的控制目标是找到最优策略,以最大化奖励的期望值。
本文选取SAC算法。SAC在训练过程中可同时最大化奖励的期望值和熵,相比于其他强化学习算法,其在样本使用效率和稳定性方面表现出了更好的性能[14]。在控制策略的目标函数中,平衡系数α决定熵项与奖励值的权重,从而控制最优策略的随机采样程度。值得注意的是,如果使用固定的平衡系数α,那么SAC 智能体会随着训练的样本增多而变得不稳定,为了解决该问题,本文采用自动更新平衡系数的方法来提升智能体训练的收敛速度和稳定性。平衡系数可以随着控制策略的更新而自动变化,以探索更多的可行解。具体的实现方法是将平均熵约束添加到原始目标函数中,同时允许熵在不同状态下发生变化。目标函数为:
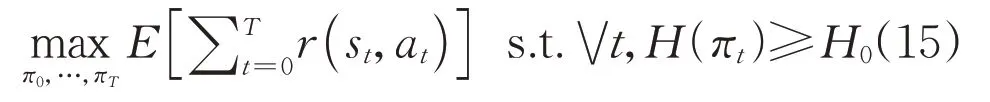
式中:πt为时刻t的控制策略;π0为初始控制策略;H(πt)为策略是πt时的熵值;H0为期望的最小熵值。
平衡系数的损失函数为:

3 技术方案
3.1 系统设计
强化学习智能体可提供预防性和矫正性控制措施,以确保电网在多种运行工况下的安全性。在训练智能体搜索电网最优运行方式过程中,所考虑的约束条件包括电网交流潮流方程、发电机功率极限、电压极限和输电线路的极限(包括热极限和稳定极限)。多强化学习智能体的电网潮流自动调节架构如图1所示,包括离线训练模块和在线应用模块。

图1 多强化学习智能体的电网潮流自动调节架构
离线训练模块分为发电机控制阶段(第一步)和负荷控制阶段(第二步)。这两个阶段都包括3个子模块,即电网环境、智能体和经验池。
1)电网环境子模块采用电网模型和运行数据作为输入,从数据文件中提取电网状态信息,启动强化学习智能体训练过程。该模块使用交流潮流求解程序来计算奖励函数值。
2)智能体子模块从智能体的控制动作策略中更新神经网络参数,并根据状态输入提供控制动作at。
3)经验池子模块从另外两个子模块收集(st,at,r,st+1)作为样本数据,用于更新控制策略和Q值函数的神经网络。
在施加发电机控制后,使用交流潮流求解程序对电网进行安全评估。如果部分传输线路过载问题仍然存在,则将第一阶段得到的最优控制策略施加到电网模型中,作为第二阶段负荷控制的输入,继续训练第二阶段的负荷控制智能体,以解决剩余的线路过载问题。
在线使用模块使用第一阶段由智能体搜索到的最优控制策略文件作为输入。在第二个阶段控制完成之后,将最佳的控制措施加入到电网运行方式中,该文件则是多强化学习智能体的最终输出。
3.2 状态空间与动作空间
在第一阶段中,使用发电机功率控制的状态空间定义为向量Sg=(P,U,G),其中P为被控区域内的线路有功功率向量,U为同一区域内的母线电压幅值向量,G为发电机有功功率输出向量。动作空间Ag定义为G,作为调节电网传输线路有功功率的控制措施。
在第二阶段中,使用分布式负荷转移控制,其状态空间定义为向量Sd=(P,U,D),其中D为变电站负荷向量。动作空间Ad定义为负荷转移的控制措施,需满足所选中变电站之间的负荷有功总和与功率因数保持不变。负荷转移智能体进行调控前,会搜索网架结构和设备运行状态来选择可能的转移方式,从而确保所选变电站之间负荷转移的物理可行性。为了保持不同类型数据的一致性,在训练强化学习智能体的过程中对状态值和动作值都进行了归一化处理。
本文所提出的基于强化学习算法自动调节电力网络潮流的方法具有良好的扩展性,可根据不同需求将多元化调控手段添加至控制空间中对强化学习智能体进行训练,例如线路投切状态、变电站母线分裂等拓扑变化[14]。
3.3 奖励值设计
强化学习算法的奖励值是智能体在每个控制迭代过程中表现好坏的评价。有效的奖励值设计可以加速智能体训练的收敛速度,提升调控性能。本文的控制目标是获取满足基态和故障条件下电网安全约束的最优运行方式,即在基态和故障(电网中的传输线路故障)工况下联络线潮流均不越限,被控区域必须能够保持基态和“N-1”故障后的安全性。因此,智能体的奖励值函数定义为故障奖励与基态奖励之和,即:
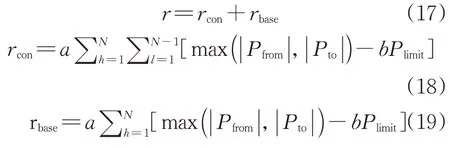
式中:rcon为故障工况下的奖励值;rbase为基态工况下的奖励值;Pfrom和Pto分别为在输电线路首端和末端的有功功率测量值;Plimit为该线路的有功上限,代表线路热极限或稳定限额;a和b为奖励值系数;N为线路总数;h为基态工况下线路个数计数器;l为“N-1”故障工况下线路个数计数器。
rcon可有效量化“N-1”故障后被控区域内线路功率的越限程度,rbase评估当前拓扑结构不变的前提下线路功率的越限情况。奖励值的计算流程如图2所示。

图2 奖励值计算流程
3.4 算法实现
算法实现流程见表1,程序使用Python 3.7 版本编写。其中:第1—13行给出了发电机强化学习智能体的训练方法,第7—10 行生成马尔可夫元组,用于更新策略和Q值函数的神经网络参数;第11—13行,当智能体收集样本数大于batch_size(采样批量大小)时,控制策略和Q值函数的神经网络参数随机更新,这个过程与负荷转移智能体的控制过程类似;第15—28 行给出了使用发电机作为控制手段未能完全解决线路越限问题后,使用负荷转移智能体的训练过程。

表1 多智能体潮流控制算法
4 算例分析及讨论
为了验证所提方法的有效性,本文采用浙江电网实际电网模型进行验证。该电网模型文件(浙江地区)包括6 500 条母线、600 台发电机、6 000条线路和4 300台变压器。为了展示多强化学习智能体在不同调控阶段的性能,进行两个测试:第一个测试针对集中式发电机智能体的训练与性能测试,选取的金华分区电网包括224 条母线、231条输电线路和7台发电机,代表2019年1月的电网运行工况;第二个测试使用2019年10月的浙江电网运行方式文件,综合测试发电机智能体和负荷控制智能体的调控性能。
在第一个算例测试中,使用大型发电机组来训练SAC智能体,其状态空间维数为462(包含母线电压、线路功率、发电机有功功率),动作空间维数为7(代表7 台所选区域内的发电机组有功出力)。该智能体的训练迭代步骤及智能体性能如图3所示。由图3(a)可以看出,同时使用7台发电机组训练出来的SAC智能体,可以在20个训练样本后成功收敛,即完全解决基态与故障工况下的线路过载问题。图3(b)给出了7 台发电机组在不同迭代步数中的有功功率输出。

图3 第一阶段使用发电机智能体训练进程与效果
在第二个算例测试中,当完成第一阶段发电机智能体训练后,智能体并未完全解决线路过载问题,即仅通过调整发电机组有功出力的方式无法找到同时满足基态和故障工况下的安全电网运行方式。其原因在于所选7台发电机组的地理位置距离越限线路较远,调控灵敏度过低,在调节金华分区电网局部线路潮流过程中具有局限性。因此,需要将负荷转移控制作为辅助调控手段,以解决局部线路过载问题。在第二阶段智能体训练过程中,训练负荷转移智能体可同时调节该局部区域6个变电站有功负荷,其状态空间维度为453(包括母线电压、线路功率和负荷有功值),动作空间维度为5,而第6 个变电站负荷吸收其余5 个变电站负荷总的有功变化,训练过程中保持负荷的功率因数不变。所选中的6个变电站之间负荷转移的物理可行性由网架结构和变电站间联络设备运行状态确定。该强化学习智能体的控制结果如图4 所示,即负荷控制智能体迭代30 次之后,可成功解决局部线路过载的问题。

图4 第二阶段使用变电站负荷转移智能体训练进程与效果
5 结语
本文提出一种基于多强化学习智能体架构的电网运行方式调节方法,包括训练集中式发电机智能体和分布式负荷转移智能体,以自动搜索满足基态和故障工况下多种安全约束的可行电网运行方式。智能体的训练和测试过程采用带有自适应平衡系数的SAC算法,该方法在2019年浙江电网运行方式计算中得到了测试。使用两阶段的控制方式,SAC 智能体可自动寻找到满足多种安全约束的电网运行方式,有效减轻工程师手动调节电网运行方式的负担。
下一阶段研究方向包括:
1)进一步提升适用于电网运行方式自动调节的强化学习算法训练速度和控制性能。
2)考虑更加复杂的电网运行工况与多元化电网运行方式调节措施,扩充强化学习智能体的控制空间。
3)将本文所提方法的应用场景进一步扩展至电网频率控制、电网经济性运行等方面。
4)在强化学习智能体奖惩机制设置过程中,添加电网安全稳定性约束,综合考虑多调控目标,进一步实现电网运行方式生成过程的自动化。
