基于核心人物和交互关系建模的群组行为识别
2022-07-02刘继超王传旭
刘继超,刘 云,王传旭
(青岛科技大学 信息科学技术学院,山东 青岛 266061)
人类行为识别是一个具有挑战性的计算机视觉问题,并已引起研究界的广泛关注。挑战包括各种因素,例如动作类别内的可变性,背景混乱以及不同动作类别之间的相似性。群组行为识别[1-5]特点是其是由多人共同参与完成的,应用包括视频监控,体育分析以及视频搜索和检索,群组行为识别的特殊挑战在于它不仅需要个人信息,还需要成员间的交互信息,并且群组特征往往是由少数关键参与者来定义的。
目前,基于深度学习的方法在群组行为识别中发挥了巨大作用。在文献[6]提出了基于深度神经网络并且考虑时间信息的分层模型。该模型由两级LSTM组成:第一级LSTM使用从CNN获得的人员表征,然后对其进行最大池化合并,并作为输入传递给第二级LSTM捕获场景级别表征。但是此种方法会丢失群组中成员之间的关系信息。因此,文献[2]提出了一种基于LSTM网络的递归交互上下文建模方案。通过利用LSTM的信息传播/聚集能力,来捕获成员之间的交互关系。提出的方案统一了单人动态,组内和组间交互的交互特征建模过程。提出的高阶上下文建模方案产生了更多的可判别性交互特征用于群组识别。但是此种方法没有考虑到在多人参加的场景中,并不是所有人都参与了主要事件,往往只是其中一部分人占主导,定义了主要事件。为了解决此问题,文献[3]定义了群组中具有“长距离运动”和“闪光运动”特征的,为关键参与者。但是它没有考虑到,往往群组中只有一个核心人物,其他关键人物应该根据与核心人物的相关性来定义。因此,为了解决以上问题,本研究提出了一种新的基于深度学习的网络架构,结合层级关系网路和关键人物建模,来进行群组识别,并进行了实验验证。
1 算法描述
整个网络框架如图1所示,分为三部分,第一部分特征提取网络,第二部分为层级关系网络,第三部分为基于关键人物的网络模型。
首先将每帧中边界框中的个人图像和光流[7]信息分别作为空间CNN和时间CNN网络的输入,得到的时空特征经LSTM后进一步利用视频的长时序上下文关系,形成组群的时空级联特征,作为下一层的输入。
其次,融合后的群组时空特征进入堆叠的关系层,关系层每层把所有人作为一个团,利用共享的MLP计算相邻参与者的边的特征表示,然后堆叠多个关系层将深层的网络层合并在一起,这些深层的网络层结合了来自相邻人的信息,所以合并了这些单独的特征表示。从而得到了带有人与人关系信息的特征,并作为下一层的输入。
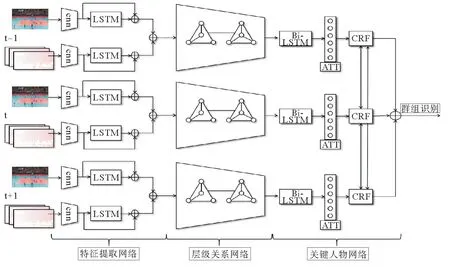
图1 基于视频的群组行为识别系统框架图Fig.1 Overview of video-based group behavior recognition system
同时,在关键人物检测网络,定义运动特征最强的一个成员为核心人物,依据与核心人物的空间距离和运动特征相关性,定义其他关键人物;再将所有关键人物的特征输入到Bi-LSTM,学习关键人物之间隐含的交互关系。为了进一步优化识别结果,将通过softmax层获得的群组识别候选标签的概率值输入CRF层,利用二元势函数鼓励外观特征和运动特征相近的群组分配相同标签,纠正由于学习偏差引起的错误。
1.1 特征提取网络
假设视频中每个人的边界框是已经给定的,对于空间CNN,从视频中提取视频帧作为输入。对于时间CNN,首先采用稠密过流算法[7],利用OpenCV获取视频中的光流作为时间CNN的输入。相比于网络中的卷积层特征,全连接层(full connected)的特征具有更好的语义和更高层的抽象信息,因此更适合作为LSTM的输入。因此分别抽取空间CNN和时间CNN的FC6层作为LSTM的输入。
最终第i个人在第t帧的输出定义为,所以第t帧的所有人的特征输出表示为Ft=(P1,P2…Pi…PN)。⊕表示级联操作符,∇表示池化操作符。
1.2 层级关系网络
群组行为是由多个成员目标共同协作完成的,仅使用单人的时空模型难以正确区分它。因此设计了一种新的层级关系网络来捕获人与人之间的关系特征。
层级关系网络一次处理一个视频帧,输入的视频帧具有与多个潜在关系图,以及相关联的N个初始人物特征向量。向单个关系层提供N个特征向量和一个关系图,并将它们映射到N个新的关系表示形式。层级关系的基本模块是个人关系处理单元如图2所示,用于处理场景中的个人。通过汇总关系图中每个相邻人的信息,将每个人的特征向量映射到新的表示形式。在一个关系层内,使用此人关系处理单元处理场景中的每个人。这样就为场景中的每个人提供了新的特征表示,可以捕获他们的个人特征以及邻居的特征。然后,通过如图3所示的残差结构,构建多个关系层,每个层都有自己的图结构和关系单元参数,学习参与者的高阶关系表征。最终合并人物的特征来用于构建场景特征。
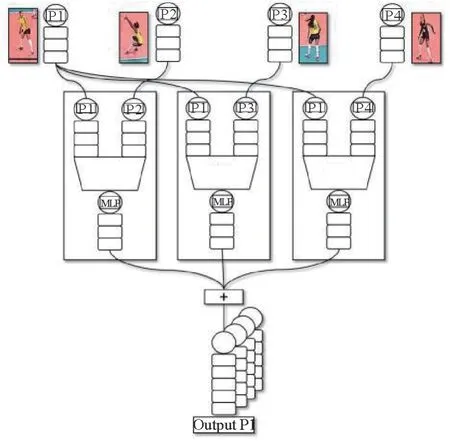
图2 个人特征关系处理单元Fig.2 Relational unit for processing one person
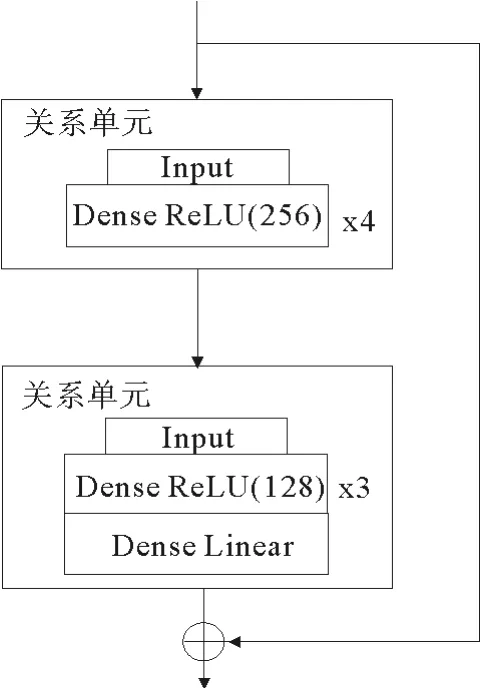
图3 残差结构图Fig.3 Residual structure diagram
具体的说,给定个人及其初始特征向量,这些向量将馈送到堆叠的关系层。每个关系层都与图形相关联(在本文实验中每层都用的完整的图)。每层共享的MLP计算2个相邻参与者的特征表示,输出的池化特征向量作为下一层的输入。
公式表示如下,给定一个视频帧,第L个关系层中的第i个人的表示的计算如下
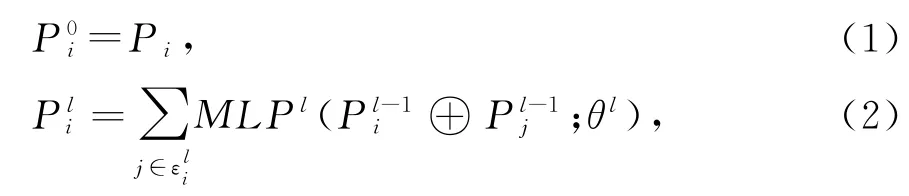
函数MLPl是共享参数为θl的第l个网络层的MLP,是端到端可微分模型。MLP的输入大小是2Nl-1和输出大小Nt。给定两个串联的向量,MLPl将它们映射到新向量,新向量中捕获了成员之间的关系特征。
通过如图3的残差结构,将多个压缩关系层级联,并且每个压缩关系层都有各自的图结构,可以从一个层到另一层构造降维的个人特征,直到形成所需的紧凑关系表示。最终场景表示S是来自最后一个关系层输出的人员表示的集合,并定义为:
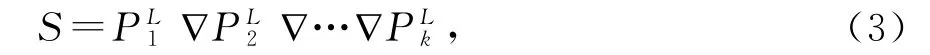
1.3 关键人物网络
群组行为中通常只有少数参与者本质上定义了群组的行为属性,因此,文献[3]将关键人物定义为在视频中平均运动强度大的人,并且根据运动强度排序,取排名靠前的为关键人物,有效的提高了识别精度。但是,群组中的核心人物往往只有一个,其他关键人物往往取决于和核心人物的相关性。因此,本文提出了一种新的关键人物建模方法,将关键人物可以细分为核心人物和活跃人物。
首先,计算视频中每个人的平均运动强度。公式如下:
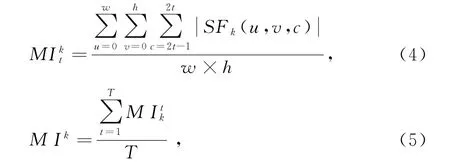
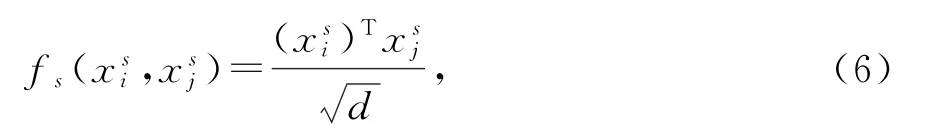
其中,xs表示运动特征,表示两人之间的运动特征相关性,本研究利用点积来计算运动相关性。

其中,xd表示边界框的中心坐标,表示两个人的距离相关性,采用欧式距离来表示空间距离相关性。
然后将两个函数融合,形成标量权重,以综合考虑两个人的运动特征关系和空间距离关系,公式如下:

然后根据相关性将群组的成员特征按降序排列,保留相关性最强的4个人作为活跃人物,将所以关键人物如图4所示。
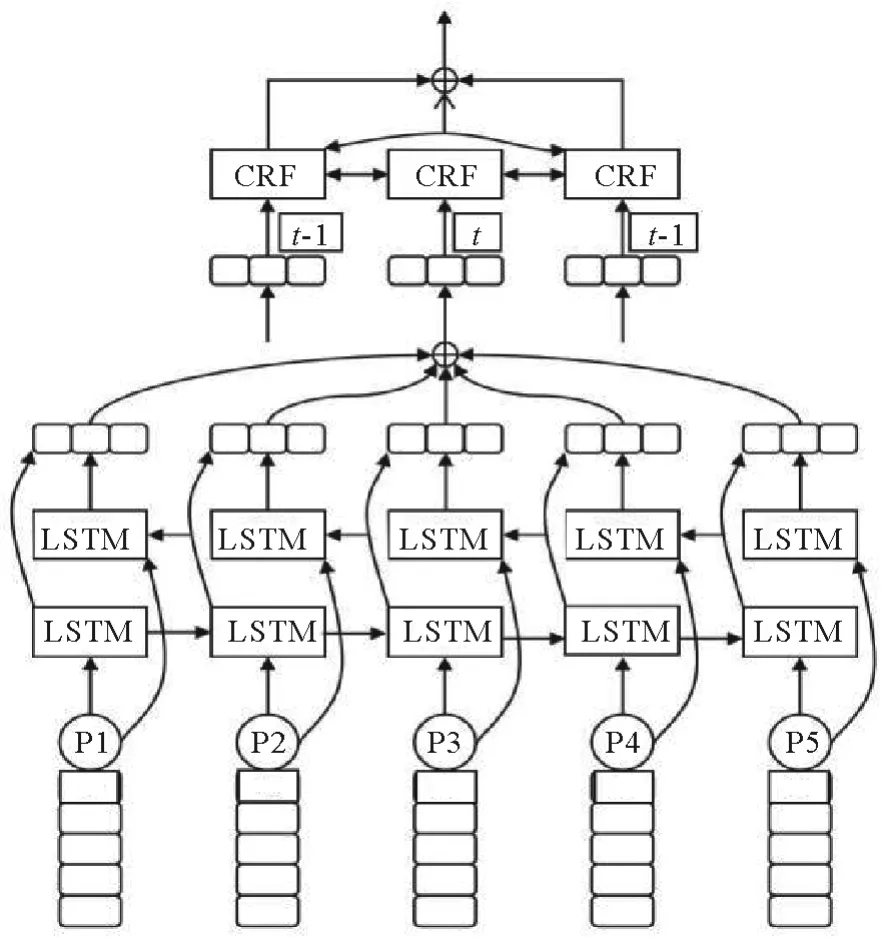
图4 基于关键人物的网络模型Fig.4 Network model based on key persons
输入关键人物网络的BiLSTM,BiLSTM产生的前向隐藏状态序列和后向隐藏状态序列}在时间t的最终表示为},是通过逐级求和来计算的输出。令H为由输出向量[h1,h2,…,hT]组成的矩阵BiLSTM层产生的特征向量,其中T是场景中人的个数。场景的表示r由这些输出向量的加权和表示为
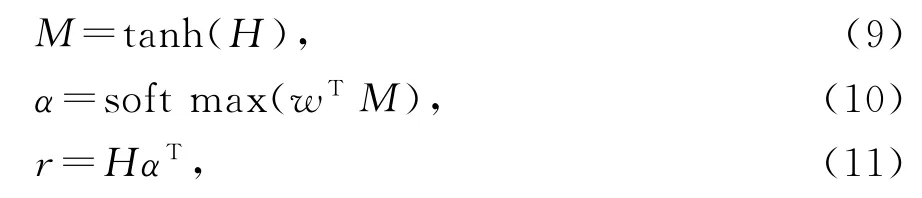

在此设置中,使用softmax分类器从场景r集合中预测标签。分类器将隐藏状态h*作为输入:
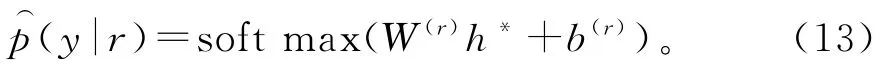
成本函数是真实类别标签y的负对数似然:

其中t∈Rm是one-hot表示的ground truth,y∈Rm是每个类别通过softmax估计的概率(m是目标类别的数量),而λ是L2正则化超参数。在本研究中,将dropout与L2正则化相结合以缓解过度拟合,最终得到相应的权重值,权重值越大对于群组就越重要反之亦然。
为了更好的提高识别精度,把softmax层获得的群组识别候选标签的概率值输入CRF层,利用二元势函数鼓励交互关系强的特征分配相同的类别标签,从而可以纠正判错类别的视频帧,最终达到优化视频精度的目的。与传统方法不同,本研究把每一帧作为一个节点,视频序列帧与帧的关系作为边,构成一个全连接随机场,以捕获长距离的依赖关系。则全连接的条件随机场模型中的基普斯能量表示为

由此,通过变量ri,以及帧与帧之间的交互关系(边)来重新判定第i帧对应的类别标签yi。其中ψu(yi)是一元势函数,二元势函数定义为
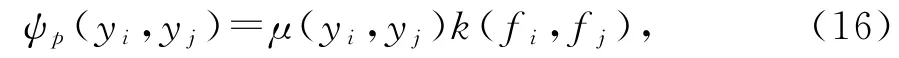
其中,μ(yi,yj)μ(yi,yj)是标签兼容性函数(label compatibility function),由Potts模型μ(yi,yj)=[yi,≠yj]给出,对于相似度高但是分配了不同标签的帧特征引入这种惩罚机制;向量fi和fj分别表示第i帧和第j帧的特征向量,和分别是第i和第j帧的外观特征,和分别是第i和第j帧的运动特征;k(fi,fj)代表高斯核函数,ω,θ1和θ2是核参数,表示如下:

可以看出核函数受特征向量影响,即相同群组应该有相近的底层外观特征和运动特征,然后将CRF层的输出候选标签概率重新辨别,最终得到优化后的分类结果。
2 结果与讨论
2.1 数据集介绍
Collective Activity Dataset[8],该数据集是使用低分辨率的手持摄像机获取的44个视频片段,每个视频的帧数从193到1 800不等。标记此数据集有5种行为(action)标签:Crossing,Queuing,Walking,Talking,Waiting;8种姿势标签(实验中未使用);五种行为标签即每帧行为中N个人共同完成的场景标签:Crossing,Queuing,Walking,Talking,Waiting。每个人都有一个行为标签,群组的行为标签大多数人的行为标签确定。本研究遵循文献[9]提供的训练/测试拆分。按照文献[2]中的实验设置,本研究将“Walking”和“Crossing”类合并 为“Moving”,并报告由于测试集不平衡而导致的平均分类准确度(MPCA)。
Volleyball Database[6],由55个视频组成,包含4 830个注释帧。此数据集有9类个人行为(action)标签:waiting,setting,digging,falling,spiking,blocking,jumping,moving,standing。8种组群行为标签,即每帧行为中N个人共同完成的场景标签:right set,right spike,right pass,right winpoint,left winpoint,left pass,left spike,left set。每个人都有一个行为标签,每帧图像都有一个场景行为标签。本研究对训练和测试集的划分与[6]中的相同,其中2/3用于训练,1/3用于测试与验证,并且使用多类分类准确度(MCA)和平均分类准确度(MPCA)。
2.2 实验网络参数配置与细节
为了与相关作品进行公平的比较,在两个数据集上使用T=10帧作为模型输入:中间帧之前5帧和之后4帧。对于排球数据集,本文将每帧的大小调整为720×1 280分辨率,对于集体数据集将其调整为480×720。模型的输入是由在Dlib库[10]中实现的对象跟踪器在T帧上跟踪的每个人周围的一组边界框(小轨迹)。本研究提出的框架适用于各种复杂的网络(例如VGG[11],Res Net[12]和Goog LeNet[13]),并且可以用于在个人动作识别阶段进行特征表示。采用了预先训练的Alex Net模型[14]来提取每个人对应的边界框上的CNN特征。在训练方式上,采用分阶段的方式来训练网络。具体来说,首先以端到端的方式训练由CNN和LSTM层组成的个人网络,以识别个人的行为。然后,将空间CNN和从个人网络输出的时间特征的级联传递到残差层级关系网络进行训练。接着将关系网络的输出的带有关系的特征传递到BiLSTMCRF网络,最终完成群组识别。
所有实验硬件平台中CPU是Intel酷睿四核I7-7700k,GPU是NVIDIA GTX1080Ti(12 GB RAM),内存64 G。实验的第一步和第三步在Py-Torch框架上实现。网络使用0.001的学习率的Adam算法[15]来最小化代价函数,并且每10个周期后,学习率就会降低到原始值的1/10。在排球数据集的实验中,个人LSTM使用10个时间步长和3 000个隐藏节点。Bi-LSTM具有6个时间步长(一个子组中有6个人)和1 000个节点。在“集体行为数据集”上的实验中,单人LSTM使用10个时间步长和3 000个隐藏节点。Bi-LSTM具有5个时间步长(一个子组中有6个人)和1 000个节点。由于此数据集中的人数从1到12不等。为每个框架选择5个有效人员,并将其视为一个整体。如果人数少于5,将全零矩阵作为新人物的轨迹。第二步中的层级关系网络使用Lasagne框架[16]。用随机梯度下降法,通过ADAM[15]优化器将模型训练200个周期,初始学习率为0.000 1,固定的超参数为β1=0.9,β2=0.999和ε=10-8的。模型中使用的批次大小为200。关系模型中的输入层后面是50%的dropout层。使用大小为的两层MLP网络。第一层使用线性激活函数(f(x)=x),第二层使用Re-LU非线性。利用网格搜索算法对ω,θ1和θ2在训练集上进行学习,并对所有核函数参数进行交叉验证以寻找最优解。
2.3 基线模型设置
在实验中基本方法设置如下(为了比较,默认是RGB图像作为输入):
Baseline1:特征提取网络+群组成员特征最大池化。
Baseline2:特征提取网络+层级关系网络。以验证层级关系网络的有效性。
Baseline3:特征提取网络+关键人物网络。以验证关键人物网络的有效性。
Baseline4:特征提取网络+层级关系网络+关键人物网络。以验证层级关系网络和关键人物网络结合的有效性。
Baseline5:特征提取网络+层级关系网络+关键人物网络+CRF。以验证CRF的有效性。
Baseline6(光流):特征提取网络+层级关系网络+关键人物网络+CRF。
Ours(RGB+光流):特征提取网络+层级关系网络+关键人物网络+CRF。以验证时空特征结合的有效性。
2.4 CAD数据集实验结果
与基本方法比较:表1显示了与基线相比所提高的识别精度。Baseline2和Baseline3分别比Baseline1的结果提高了6.4%和12.1%,充分说明了层级关系网络(HRLN)和关键人物网络(KN)的重要性。Baseline5比Baseline4提高了1.6%,说明了CRF层的有效性。Ours是本研究最终的模型所采取的方式,与Baseline5比较提高了2.4%,与Baseline6比较提高了6.9%,既说明了时空特征的重要性也说明了层级关系网络和关键人物网络相结合的有效性。

表1 基于CAD数据集与基本方法的比较Table 1 Comparison with baseline model
与其他方法的比较:表2显示了在CAD数据集上使用不同方法进行的比较。本研究类似文献[3,17],将“Walking”和“Crossing”合并为“Moving”类别,并且根据文献[6,10,12]中报告的混淆矩阵计算了几种方法有关MPCA的结果。本研究方法不但高于相同的主干网络的方法文献[6](4.3%)和文献[3](1.7%),还高于用了更深层网络的文献[17,18,19]。分别比用了VGG16的文献[17]高了5.6%,比用了Inception-v3的文献[18]提高了4.0%。文献[6]只是简单的将所有人特征最大池化后作为群组识别的特征,文献[17]是采用了层级能量层来进行群组识别,文献[18]是通过个人特征产生个人标签然后群组基于语义识别,文献[3]是将群组行为的关键的参与者定义为“长动作”和“快动作”的参与者。文献[3,6,17,18]都没有充分考虑人与人之间关系特征,所以和他们比较充分证明本研究的网络在不丢失每个人的信息同时能更好的包括了每个人的关系特征来进行群组识别。文献[20]利用了表示各个人之间的空间关系的行为图作为中间件来进行群组识别文献[20]采用了高层的语义关系图,本研究的方法优于最新方法文献[19](0.1%),尽管他用了更深的网络VGG16,并且仅仅比用了I3D网络的文献[20]少了0.3%。因为I3D网络比本研究的网络大得多,没有可比性,所以充分证明本研究的方法在在CAD数据集上的有效性。
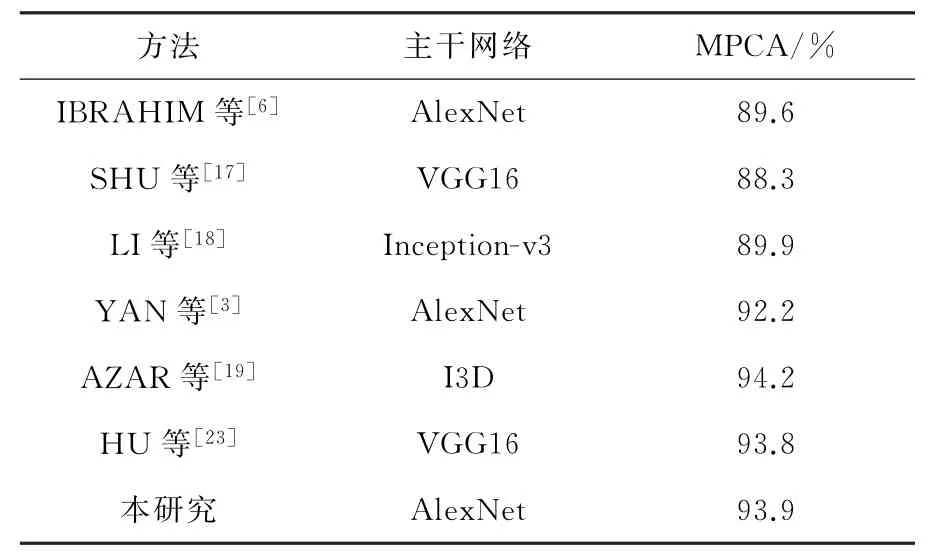
表2 基于CAD数据集与其他方法的比较Table 2 Comparison with other methods
此外,通过图5的混淆矩阵,可以看出Moving,Queuing和Talking已经能很好的被区分,Queuing识别率已经达到100%。但是Waiting识别率只有78%,把22%的Waiting错判成Moving,究其原因是因为动作类“Waiting”总与“Moving”一起发生。

图5 本研究方法CAD数据集上的混淆矩阵Fig.5 Confusion matrix for CAD
2.5 VD数据集实验结果
与基本方法比较:表3显示了本研究方法与基线相比较的识别精度。Baseline2和Baseline3分别比Baseline1的结果提高了12%和13.3%,充分说明了层级关系网络(HRLN)和关键人物网络(KN)的重要性。Baseline5比Baseline4提高了0.1%,说明了CRF层的有效性。Ours是本研究最终的模型,与Baseline5比较提高了0.3%,与Baseline6比较提高了0.9%,说明了层级关系网络和关键人物网络相结合的有效性。
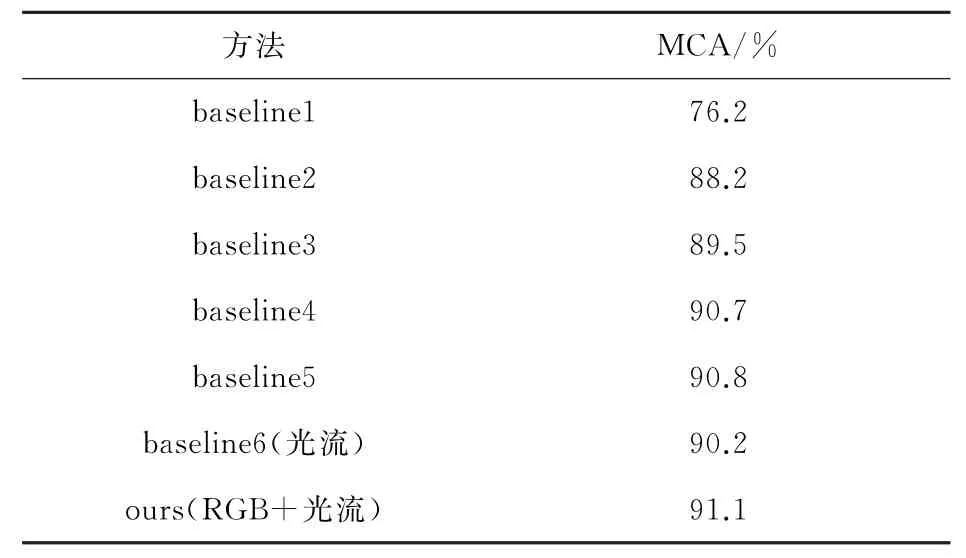
表3 基于CAD数据集与基本方法的比较Table 3 Comparison with baseline model
与其他方法的比较:如表4所示,本研究方法的MCA和MPCA均优于所有使用相同主干网络(Alex Net[14])的最新方法[3,6,21],即使是在本研究只采用RGB特征的情况下。并且本研究的方法甚至优于大多数使用主干网络Inception-v3的方法[11-12]和VGG16的方法[4,10,22],与文献[23-24]中的方法比识别率相当,仅仅少于使用I3D网络的[24]1.9%(MCA)。I3D比本研究的网络(Alex-Net[14])大的多,所以没有可比性。所以综上充分证明了本研究的方法在VD数据库上的有效性。

表4 基于CAD数据集与其他方法的比较Table 4 Comparison with other methods
另外,本研究方法的混淆矩阵如图6所示,可以看到,本研究的方法在大多数行为中的识别率都超过90%。主要的失败的类别来自“rset”和“rwin”,这是由于关键参与者的动作和位置非常相似所导致。
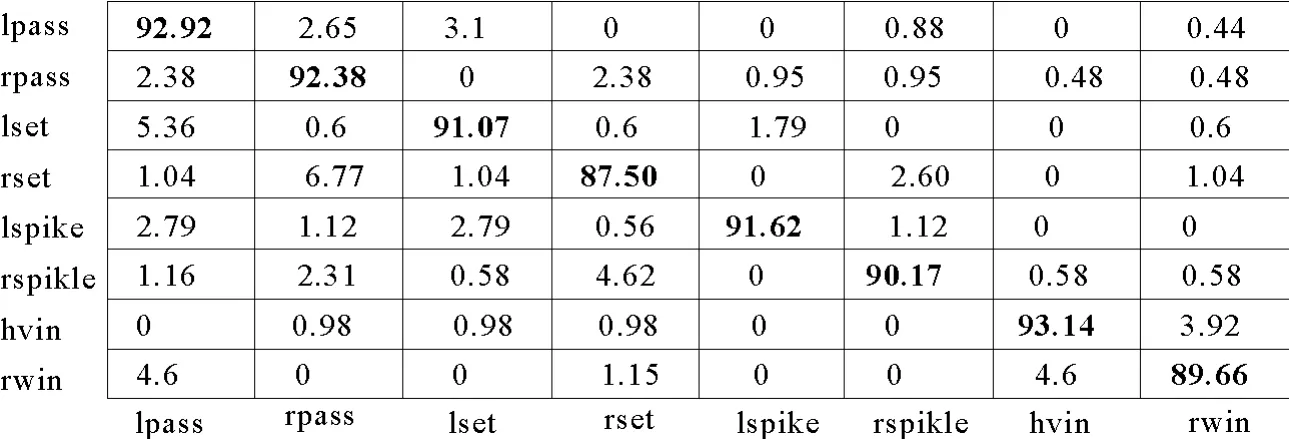
图6 本研究方法VD数据集上的混淆矩阵Fig.6 Confusion matrices for VD
3 结 语
针对群组行为识别问题,提出了一种层级关系网络与关键人物网络相结合的识别方法。通过对比基线方法和最新方法,证明了本研究提出方法的有效性。在大多数行为中本研究方法的识别率都超过90%。接下来,本研究计划研究模型的网络优化,以减少模型训练时间,并争取进一步提高模型的识别精度。另外,为了考虑实时性问题还需要进一步优化光流提取技术。
