可堆叠重校准特征金字塔目标检测方法
2022-07-02陈乔松
陈乔松,刘 宇,张 冶,谭 彬,邓 欣,王 进
(重庆邮电大学 数据工程与可视计算重庆市重点实验室,重庆 400065)
0 引 言
计算机视觉领域中的目标检测为人脸识别、自动驾驶、机器人视觉等上层应用提供了基础支持,为其功能的丰富提供了极大的帮助。例如:捕捉摄像机中人脸的位置,对该区域进行自动对焦[1];识别画面中主体人物的位置,方便无人机进行跟踪拍摄;对来访人员进行人脸配对,方便查找一些基本信息。目标检测的任务主要分为2个子任务:①定位。找出图片中的目标物体位置,并给出一个二维坐标;②分类。标记目标物体的所属类别,如人、猫、狗等。
近年来,目标检测得到了快速发展。随着深度学习在图像分类任务上取得重大进展,目标检测方法也从早期基于人工特征提取和机器学习的传统方法[2-3],发展到了目前利用深度学习自动进行特征工程的检测模型。这些方法在PascalVOC[4]、Coco[5]等公开数据集上取得了非常不错的成绩。在2012年的ILSVRC分类大赛上,AlexNet[6]取得了84.7%的top-5准确率,让人们看到了深度学习以及深度卷积神经网络(deep convolutional neural networks,DCNN)在计算机视觉上的潜力。之后VGG[7]、ResNet[8]等同样使用深度学习技术的分类模型一直刷新着ILSVRC记录。DCNN的优势随后被文献[9]引入目标检测,极大地简化了流程并提升了精度。
但目前基于DCNN的目标检测网络仍存在以下挑战:第一,目标检测对实时性要求较高,早期的检测方法动辄几十秒的时耗导致实际使用价值不足;第二,模型体积过大,不方便在手机等边缘设备上进行部署;第三,对多尺度物体必须拥有较强的鲁棒性,能够检测出同一类别物体下的不同尺度实例。
针对以上问题,本文提出一种基于YOLOv3[10]的改进目标检测方法。第一,使用文献[11-13]中提出的主干网来代替Darknet53网络,运行效率更高。以损失少量精度为代价,可以极大地降低参数数量和提高运行速度。第二,使用更加轻量的加法操作来代替拼接进行特征融合,引入卷积块注意力模块(convolutional block attention module, CBAM)[14]对融合结果进行重校准,并设计为可独立调整堆叠数量以平衡精度和速度。通过重复堆叠加大特征多尺度信息,进一步增加感受野,提升对多尺度物体的检测精度。
1 相关工作
基于深度学习方法的目标检测模型主要分为双阶段模型和单阶段模型两大类。
双阶段检测方法是以R-CNN以及衍生出的Fast[15]/Faster RCNN[16]、Mask-RCNN[17]等为主的一系列目标检测模型。其检测流程分为两步:①产生候选的目标区域;②对候选区域进行分类和进一步修正。其中,R-CNN使用选择性搜索得到候选框;Fast-RCNN共享了部分网络的计算结果来加快运行速度;Faster-RCNN使用区域生成网络(region proposal network, RPN)来代替传统的选择搜索过程,并将多轮训练过程转化为单个训练过程。R-CNN系列网络在精度上非常出众,但其候选区提出与最终检测框生成相分离的结构导致运行速度十分缓慢,不能满足工业上实时目标检测需求。
单阶段检测方法的代表是文献[10,18-19]提出的YOLO系列模型以及文献[20]提出的SSD检测模型。和双阶段检测不同,单阶段检测方法主要使用单个网络进行单次向前运算并同时得到定位与分类结果,因此速度较快。YOLOv1将输入图片分为7×7小格,使用全连接网络来直接预测每个小格的物体类别和定位框的中心点坐标以及宽高;SSD使用全卷积网络(fully convolutional network,FCN)来进行多尺度密集采样,通过设置大量的先验框来减少训练难度。
虽然单阶段检测模型的速度优于双阶段,但其精度稍逊一筹。近年来,单阶段模型的优化主要体现在精度上的提升。以YOLO系列为例。YOLOv1使用最后7×7的特征图来进行预测,每个点预测2个定位框和1个分类类别,随之产生3个问题:①限制了模型的预测数量,当两个物体的中心落在同1个点上时,网络只能作出一个预测;②7×7的特征图失去了一些细粒度的特征,不利于小物体的检测和定位;③采用直接预测定位框坐标的方式,造成了训练困难。针对这些精度上的缺陷,YOLOv2将最后检测特征图的分辨率提升到了13×13,并通过直通层引入细粒度特征,增强了邻近物体和小物体的检测性能。而新增的基于聚类选择的先验框机制,在增加训练稳定性的同时也加快了收敛速度。YOLOv3使用了更深的主干网Darknet53作为特征提取网络,并加入基于拼接的特征金字塔结构(feature pyramid network,FPN)和针对大、中、小物体的多尺度预测,极大地提升了精度。
深层主干网和FPN虽带来精度上的提升,但参数量和计算量的增加不能忽视。Darknet53通过堆叠使用53层卷积核大小为1×1与3×3的卷积层,来增加特征提取能力,但是,参数量相对于YOLOv2使用的Darknet19增加了一倍,采用的拼接FPN结构也不够高效,从而带来了额外的200 M参数量。因此,采用更加高效的结构进行优化替换,可以在不过于损失精度的同时大幅度减少参数量和提升速度。
2 本文方法
2.1 特征提取主干网
网络的主体结构如图1所示。图1中,主干网是整个目标检测网络的基础,负责特征提取。本文使用针对移动设备设计的MobileNetV3[13]作为主干网。其主要特点是使用深度可分离卷积来替代传统的卷积层,并使用资源受限神经网络搜索得到参数量和计算量受限的网络结构。MobileNetV3的卷积层参数量为30 M,相比Darknet53而言减少了92%。理论FLOPs计算量也减少了96%,而在ILSVRC数据集上的top-1错误率只增加了3%。因此,使用MobileNetV3进行替代能以轻微精度损失为代价换来更加高效的主干网。
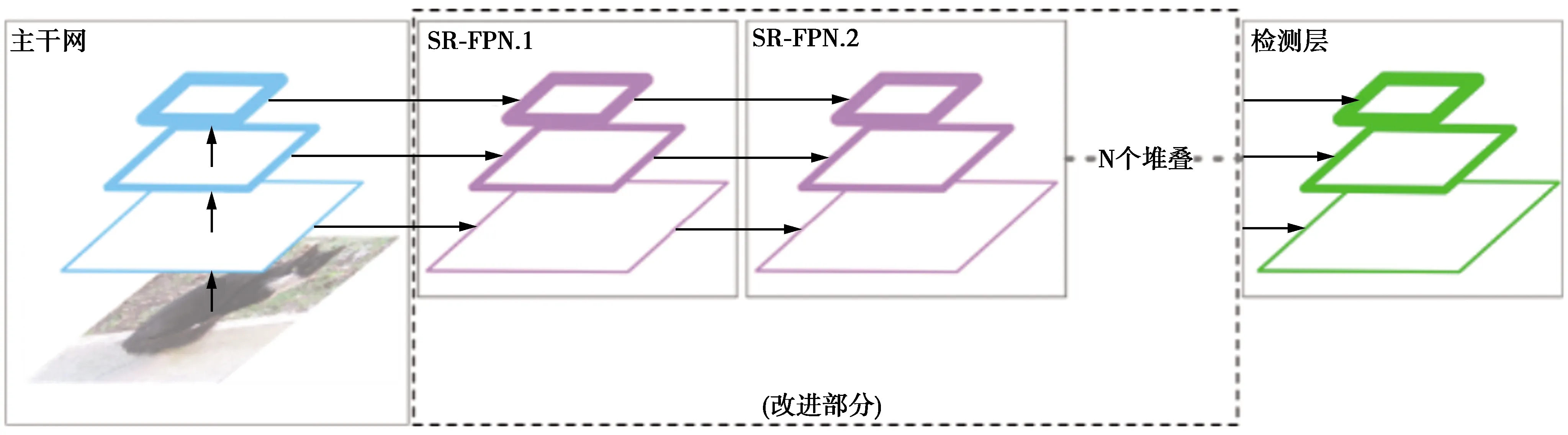
图1 网络主体结构Fig.1 Structure of network
2.2 可堆叠重校准特征金字塔结构
FPN是文献[21]提出的一种自顶向下、带有侧向连接层次结构的多尺度特征融合方式。该方法使用深度卷积网络本身的多层次、多尺度结构来构造特征金字塔,是一种轻量的网络结构。其目的是将富含语义的深层特征(适合用来分类)与富含位置信息的浅层特征(适合用来定位)进行融合,使最终用于检测的特征同时包含语义信息与位置信息,加强目标的分类与定位。
YOLOv3中使用的FPN如图2所示。

图2 原始YOLOv3的FPN结构Fig.2 Original YOLOv3 FPN structure
图2中,由主干网依次向前计算得到不同大小,步长分别为8、16、32的特征图,记为{C3、C4、C5}。融合过程从最小的高层特征图C5开始,分别经过11、33等总共5个普通卷积层得到输出;然后,将C5的输出进行上采样与C4进行拼接,再同样经过5个普通卷积得到C4的输出;类似地得到C3的输出。但是,这种结构主要有3个问题:①负责检测大物体的步长为32的高层特征图并没有融合来自浅层的细粒度特征信息,不利于定位。文献[22]也采用增加一条Bottom-Up路径的方式,使浅层信息重新融合到高层,证明了浅层的信息的确起了较大作用。②采用拼接的方式,容易造成卷积层参数过多。③不利于扩展,随着深度的增加,梯度信息更加不容易回传。
针对以上问题,本文提出了可堆叠重校准特征金字塔模块。该结构每个步长的最终输出都融合了其他步长的特征,综合语义和位置信息,并在最后对这些融合信息进行重校准,抑制或去除多余、无效的信息。并使用加权残差连接增加信息回传以及减小训练难度。单个模块结构如图3所示,主体分为3个部分:①Top-Down结构;②Bottom-Up结构;③重校准结构。

图3 单个SR-FPN模块Fig.3 Single SR-FPN module
为了减少参数量和计算量,使用深度可分离卷积(3×3卷积核的分组卷积+1×1卷积核的逐点卷积)作为基本单位。Top-Down结构与文献[21]中的结构类似,通过上采样的方式将顶层的小特征图放大到与上一个步长的特征图一样大小。与文献[21]不同,融合方式采用加权相加的方式进行融合,之后依次重复进行上采样、加权融合得到Top-Down的输出;在这之后,使用Bottom-Up结构重新将经过Top-Down初次融合后的特征传导到高层中,使用最大池化把浅层特征图缩小到和下一个步长一样大小,并与来自Top-Down相同大小的输出进行加权融合,同时与输入中相同大小的特征图进行加权残差连接;经过重校准结构,使用CBAM进行通道维度和空间维度的重校准,对重要的区域进行特征加强,并使用Bottom-Up的输出进行加权残差连接。
残差连接在文献[8]中被证明是有效的,学习残差使网络更易优化。本方法使用的残差连接和融合方式在原本简单相加的基础上进行了加权,对于不同层次来源和深度的特征不是同等对待,而是让网络去学习缩放权重,找到最优组合方式。假设{C3、C4、C5}来自不同步长层级的特征图,记Top-Down结构的输出为下标td,记Bottom-Up结构输出为下标bu。那么Top-Down的中间输出使用以下公式计算。
C5td=DSConv(C5)
(1)
Bottom-Up的中间输出用以下公式计算。
(2)
(1)—(2)式中:DSConv为深度可分离卷积操作;Up为上采样操作;Down为下采样操作;wi,j为网络学习的缩放系数,初始值为1,在使用时,先用ReLU激活函数进行激活,保证其值总是大于0,方便进行特征归一化;eps为一个较小的数,避免除数为0,本文取0.000 1。
通过多次叠加SR-FPN模块,可以加强特征融合、扩大感受野以及提高网络表达能力。因为主要使用了深度可分离卷积,所以不会显著增加参数量以及计算量。
2.3 损失函数
YOLOv3损失函数分为3个部分,分别为Lcoord坐标损失、Lobjness置信度损失以及Lclass分类损失。
L=Lcoord+Lobjness+Lclass
(3)
原始的YOLOv3中使用L2范数损失作为坐标损失,优点是计算简单,缺点是低L2损失不能直接反映预测框与真实标签框的交并比(intersection over union,IoU)。L2损失对物体尺寸敏感,大物体的损失一般高于小物体的损失,会掩盖掉小物体的损失,因此,本文使用文献[23]中提出的广义交并比(generalized intersection over union,GIoU)损失替代。GIoU损失使用新的类IoU度量作为损失对坐标进行回归,并且与IoU的定义类似,可以直接反映重合度,对物体的尺寸变化也不敏感。坐标损失公式为
(4)
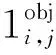
置信度损失和分类损失依然使用二分类交叉墒作为损失函数。置信度表示了该预测框包含有物体的概率。置信度损失公式为
(5)
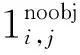
分类损失为
(6)

2.4 训练流程
依据原始YOLOv3训练目标,以标签框GT之间IoU最大的先验框作为正样本目标,其余IoU大于一个阈值的先验框将被忽略而不参与训练,剩下的即是负样本训练目标。但是这样会造成正样本过少,不利于训练的稳定性。例如:假设输入图片的高宽为416×416,其中标签框目标有4个。那么,根据先验框的设置,网络一共会生成10 647个检测框;然而,只有4个检测框会作为正样本参与训练。
为了增加正样本的数量,本文设定了一个IoU阈值(一般取0.5)。除了与标签框之间IoU最大的检测框以外,如果其他检测层拥有与标签框IoU大于阈值的检测框,那么也将这个检测框纳入正样本。
3 实验与分析
3.1 网络训练和优化
本文实验硬件环境为:CPU为AMD(R)Ryzen(TM)3600 CPU@4.0 GHz,GPU为NVIDIA GTX1070,内存大小为32 GB;软件环境为:Archlinux操作系统,Jetbrains Pycharm集成开发环境,MXNet深度学习框架。
对于数据集,本文使用PascalVOC[4]数据集作为训练和测评数据集。训练集使用PascalVOC 2007 trainval+PascalVOC 2012 trainval,测试集使用PascalVOC 2007 test。测评标准使用各类别精度-召回曲线下面积的平均值(mean average precision,mAP)。
具体的训练流程为:和文献[10,24]中使用的试验参数类似,设定总体学习epochs数量为150,Batch数量为8,基准学习率为0.001;在前3个epoch内使用文献[25]中建议的warmup技术把学习率从0线性增加到0.001,并在第120、135个epoch把学习率乘以0.1进行衰减;整个网络使用SGD+Momentum[26]作为优化算法。
对于测评设置,使用mAP@0.5(预测框与标签框的IoU超过0.5作为真阳性预测的判定标准)分数作为主要测评标准。并将参数数量以及每秒运行帧率(FPS)作为运行效率测评工具。
3.2 对比
为了统一对比环境,对于不同模型,本文使用同一套用于验证的超参数。非极大值抑制(non maximum suppression,NMS)阈值设置为0.45,运行5次,取平均运行时长来计算FPS。其他的模型来源于MXNet的官方实现[27]。
使用的PascalVOC训练集包含16 551张图片,总共47 223个标签框实例。验证集拥有4 952张图片,总共拥有14 976个标签框实例,但被标记为“困难”样本的实例不参与到mAP的计算中,实际参与测评的实例数量为12 032。mAP计算方式采用PascalVOC 2007中使用的公式,即取召回率Recall≥0{0,0.1,0.2,…,1}共11个点的最大查准率的平均值作为mAP计算结果。计算运行帧率时排除了图片预处理操作,统计从预处理图片送入网络进行向前运算开始,到经过非极大值抑制处理之后的最终结果为止的运行时间,并在整个测试集上计算平均值。
表1为本文提出的改进模型与其他主流模型的对比。
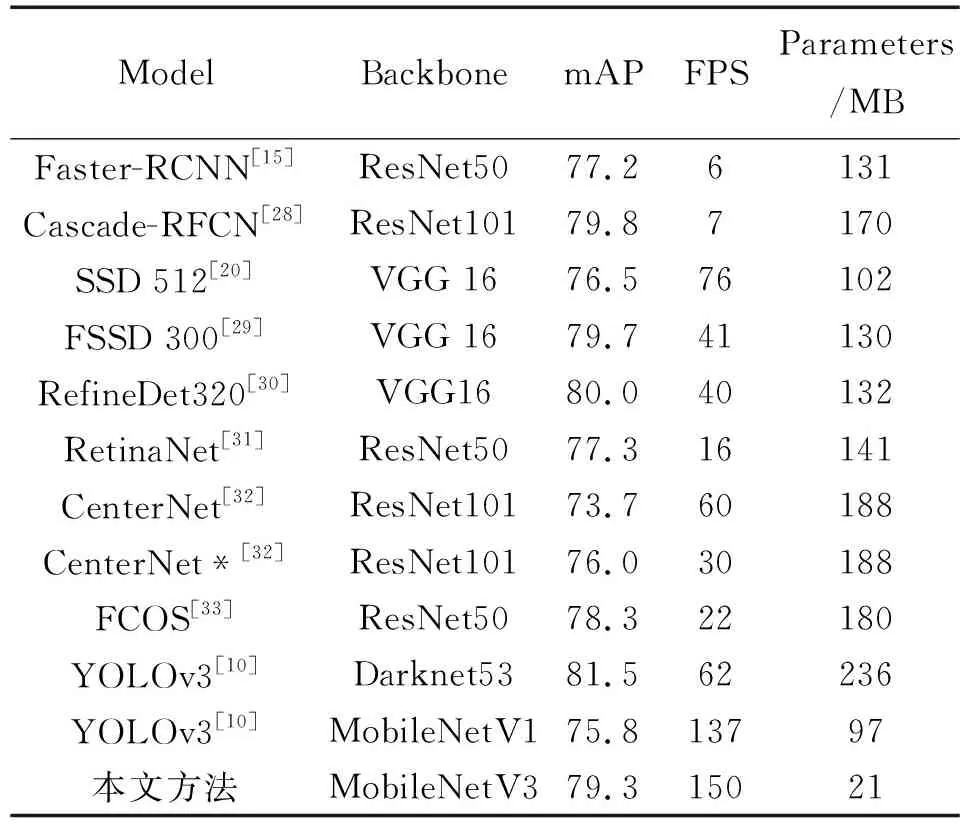
表1 PascalVOC 2007 test下的测评结果Tab.1 Evaluation results of PascalVOC 2007 test dataset
由表1可见,传统的双阶段检测模型Faster-RCNN虽然mAP精度不错,但是过慢的运行速度以及庞大的模型并不利于在移动设备的应用;单阶段SSD模型在速度上比Faster-RCNN快了不少,但参数量依然超过了100 MB;YOLOv3得益于更大的主干网络和基于拼接的特征金字塔模块,将mAP提升到了最高的81.5,但是运行帧率下降且模型大小增加。
本文方法使用了更偏向于运行效率的主干网,mAP相比表1中精度最高的YOLOv3下降2个百分点,但是运行速度提升了140%,模型参数量减少了91%。这主要得益于本文提出的高效率特征金字塔结构。本文提出的SR-FPN使用轻量级的深度可分离卷积,其参数量和计算量相比普通的FPN[21]结构大幅度下降[11]。相比使用Concat拼接操作的YOLOv3,本文使用的Add加法操作并不会使后面的卷积层接收的输入通道数增加,从而进一步减小了卷积层的参数量和计算量。
因此,相比表1列出的其他模型,以及近几年兴起的Anchor-Free模型,本文基于SR-FPN结构的YOLOv3改进模型更加适合部署于移动手机等边缘设备上。
3.3 消融实验
为了证明本文提出改进方法的有效性,以YOLOv3作为基准Baseline,先后使用各个改进流程,进行了如表2所示的消融实验。
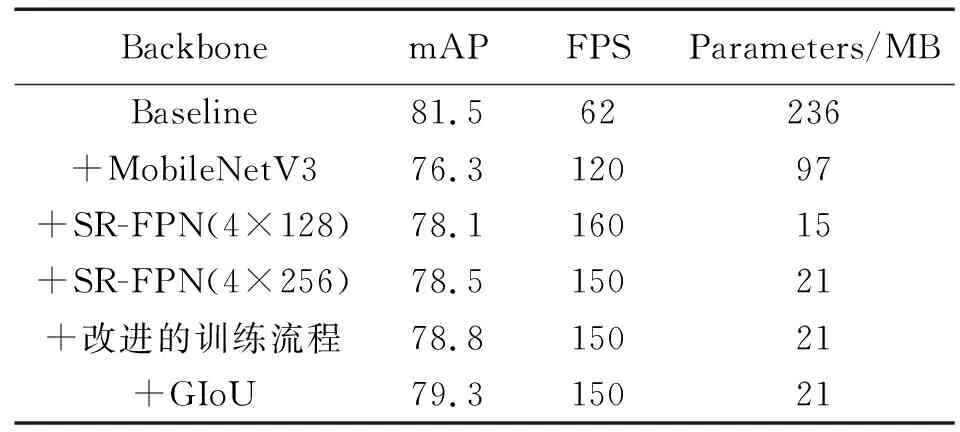
表2 模型消融实验结果Tab.2 Results of ablation experiments
以MobileNetV3替换掉Baseline中Darknet53主干网之后,FPS帧率提高了1倍,参数量减少了1/2。但是,检测精度下降了近5个百分点,且MobileNetV3模型的特征提取部分参数量只有11 MB大小,多余的参数即是Baseline中的FPN部分。使用本文提出的SR-FPN(通道数量为128,进行4次堆叠),进一步优化精度和参数量;然后,使用通道数量为256、堆叠数量为4的SR-FPN配置,使精度、速度与模型大小达到了一个平衡点;最后,使用GIoU替换掉原损失函数中的坐标损失部分以及优化后的训练流程,在不影响速度与参数量的同时,将mAP提升到了79.3。
4 结束语
本文提出可堆叠重校准特征金字塔模块,使用更加高效的特征提取主干网网络,对YOLOv3目标检测模型进行优化。解决参数量大、运行速度缓慢的问题,提升其在工业上,尤其是边缘设备上的应用价值。在PascalVOC数据集上进行的对比实验以及消融实验表明,本文提出的方法更加高效灵活,可自由设置堆叠数量与通道数量等超参数来对精度、速度以及参数量进行平衡。但该算法依然存在不足,如需要手动调整超参数进行调优、单个堆叠会极大影响精度,以及缺少在其他数据集上的验证等。下一步的改进工作主要着眼于优化堆叠方法以及更加详细的验证实验。
