基于稠密连接注意力单任务提升的深度多任务学习
2022-07-02舒雅宁闫振兴
王 进,任 超,舒雅宁,彭 浩,闫振兴
(重庆邮电大学 数据工程与可视计算重点实验室,重庆 400065)
0 引 言
多任务学习最初由Caruana[1]提出。多任务学习最明显的特征是具有多个损失函数,损失函数与任务一一对应。多任务学习之所以有效,首先是因为多个任务联合训练起到了正则化的效果,模型不会偏好任何一个任务的局部最优,避免了单个任务的过拟合问题,正如Caruana的观点[1]:“MTL通过利用相关任务的训练信号中包含的领域特定信息来改进泛化”;其次,任务间的知识共享可以给每个任务的训练提供额外的信息,这些信息往往是有用的,会使任务的训练变得更加简单,前提是任务受到知识负迁移[2]的影响要比前者小。目前,多任务学习在多个领域有所应用,比如疾病诊断[3]、谣言检测[4]、目标检测[5]等。
依据理论方法不同,多任务学习方法可以分为传统多任务学习方法和深度多任务学习方法两大类。传统多任务学习方法是对模型参数施加约束[6-7],或者使用矩阵分解[8-9]的显式来表示知识共享,此类方法不仅无法充分利用知识共享带来的好处,而且知识负迁移问题严重,即简单任务容易受到困难任务影响而训练效果变差。深度多任务学习方法基于深度学习理论,受传统多任务学习启发,通常是对模型结构进行改进来进行知识共享,这些结构往往是预先定义的,这也意味着任务间的关系是先验固定的,这会产生一个问题:先验性的知识共享如果设置不当,不仅不会给任务的训练带来收益,而且会产生严重的知识负迁移。
关于深度多任务学习,本文有如下几个观点:首先,任务间的知识共享应该由每个任务本身决定,也就是说,每个任务拥有特异于其自身的知识共享结构,其自己决定从其他任务所汲取知识的程度,且知识共享程度应该在训练的过程中动态确定;其次,在联合训练多个任务时,知识负迁移现象必定会产生,新的方法应该是如何极力减小其负面影响,或者另辟蹊径将其规避。
为了解决上述问题,本文提出了一种基于稠密连接注意力单任务提升的深度多任务学习方法 (deep multi-task learning based on single task enhancement of dense connected attention, SEDA),其创新点首先是每个任务使用自注意力单元来学习任务间的知识共享,然后通过稠密连接将共享信息与自身相结合,上述两者确保了每个任务可以动态地训练知识共享结构,并动态地设置知识共享程度;其次使用单任务提升训练方法贪心地优化每个任务。此种方法既可以享受多任务学习带来的好处,又可以规避知识负迁移带来的负面影响,贪心地最优化每一个任务,代价仅仅是少量的时间。
1 相关工作
1.1 多任务学习
传统多任务学习中,一类方法是在目标函数中加入正则化项来对参数施加各种约束,显式表征模型的知识共享。不同的先验对应于不同的约束形式,最常用的Lasso[10]约束会产生一组稀疏解,此时,先验认为多任务学习的参数应当是稀疏的,这种稀疏性会使模型更加鲁棒,进一步得到更好的泛化性能。其他约束如组稀疏约束[11]会产生组稀疏性参数;另一类方法是对多任务学习的参数矩阵进行分解,一些方法将参数矩阵分解为两矩阵和[12]的形式;一些方法分解为矩阵乘积[13]的形式,这些方法通用的思想认为参数矩阵包含共享知识和特定于任务的知识两部分,矩阵分解后得到的两部分与其一一对应,在分解后的矩阵上施加不同的约束将得到不同的效果。
近年来,深度多任务学习成为多任务学习领域研究的热门方向。Caruana[14]在其论文中首次提出了基于深度学习的多任务模型,其设计思想如今仍是各种深度多任务学习方法的基础。多任务在网络底部共享参数,表示知识共享,随后每个任务拥有自己的网络层来产生特异于任务自身的参数。文献[15-17]中的一些方法通常是对网络结构进行改进;文献[18]的方法使用十字绣单元在任务间传输信息;文献[19]的方法则使用张量分解技术为每个任务产生参数;文献[20]的方法使用归一化的权重对多个网络进行集成;文献[21]则是在网络表层添加注意力机制产生新的输入输出。
1.2 注意力机制
注意力机制灵感源于人类的视觉感官注意力,经过实践证明其确实有效,且近几年已在多个领域有成功的应用[22-23]。当有多个目标存在时,可以使用注意力机制进行聚焦,其通过产生归一化的权重,将多个目标的信息进行结合。注意力机制在自然语言处理和计算机视觉领域应用广泛,Bert[24]使用Transformer[25]作为算法的主要框架,而Transformer中使用了多种注意力机制。AA-Net[26]使用同时参与空间和特征子空间的注意机制并引入了额外的特征映射。这2种方法都用到了自注意力机制。自注意力机制使用目标本身计算注意力权重,无需使用额外的参数进行对齐。多任务学习领域,已有一些方法使用注意力机制[27-29],像前面提到的文献[20]和文献[21],但注意力机制在多任务领域的研究尚未成熟,前述方法使用注意力机制的形式是否合适仍值得进一步研究。本文方法与前述方法相比,相同点是方法中都使用了注意力机制;不同点是本文方法使用自注意力单元表征任务间的知识共享结构,从而对知识共享信息进行学习。
2 本文方法
2.1 网络架构
本文研究了一种基于稠密连接注意力单任务提升的深度多任务学习方法SEDA,其网络架构主要包括3个部分:①自注意力单元利用输入层产生注意力权重;②使用注意力权重将输入特征进行加权结合得到共享信息;③使用稠密连接将任务自身特征与共享信息融合,然后对其进行批量归一化操作得到新的输出。将上述由整体输入得到新任务输出的网络架构统称为融合层,整体架构图如图1所示。
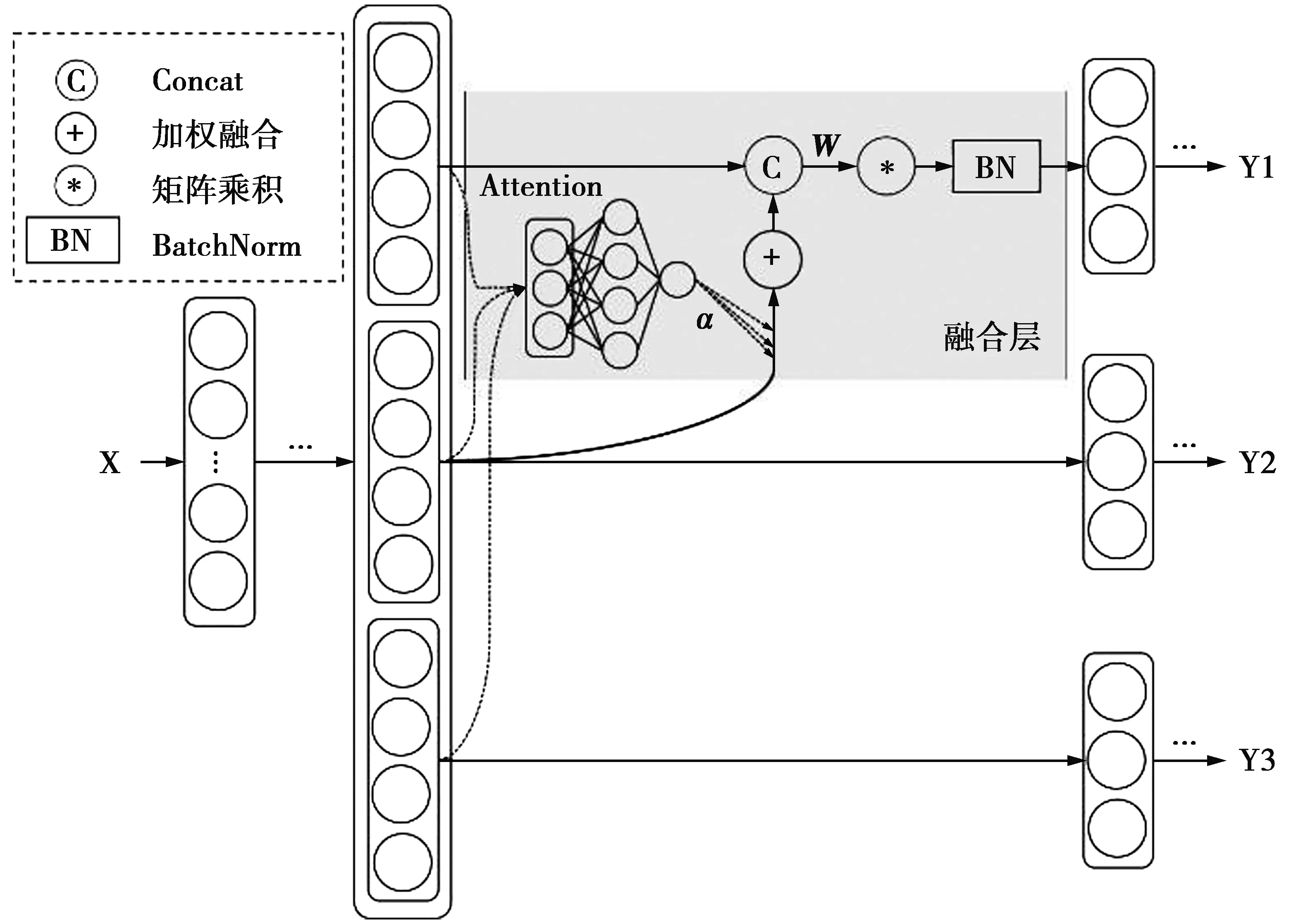
图1 SEDA方法网络架构图Fig.1 Network architecture diagram for the SEDA method
2.2 稠密连接注意力

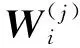
(1)
其次,将各中间层拼接,如(2)式。
(2)

(3)
然后,将各注意力分布进行拼接。
(4)

(5)
关于共享知识信息,一种重要的思想是其只能用来辅助每个任务进行训练,每个任务仍由自身主导。稠密连接的跨级信息融合将共享知识信息与任务自身网络结构相结合。稠密连接首先将共享信息与自身特征在特征维度上连接(concat)。
(6)
(7)
2.3 训练流程
为了使每个任务既能享受多任务学习带来的好处,又能规避知识负迁移问题,本文方法采取了单任务提升训练的方法,该方法与稠密连接注意力单元相结合,会最大程度地提升每个任务性能。具体来讲,对T个任务,按照随机顺序训练每个任务。SEDA方法对当前训练的任务的网络中添加融合层,其余任务只使用普通的神经网络,这样做的目的是使得关联任务在利用多任务学习形式的同时又能极大程度地避免知识负迁移问题。各个任务的训练会在网络中保留自身的特征,而通过融合层的干预,这些网络中又会只保留对当前训练任务有益的部分,这些干预通过反向传播实现。同时优化多个任务时,不同任务对特征会有不同的偏好,这些特征对其他任务并不是全部有益,知识负迁移由此产生,而单任务提升训练的方法使得每次训练专注于一个任务,不必担心知识负迁移的现象,训练流程如图2所示。
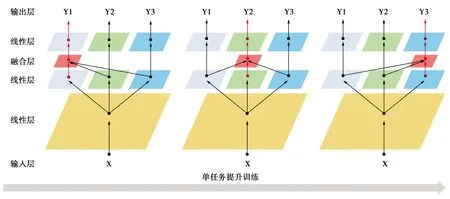
图2 单任务提升训练方法Fig.2 Training method of single task enhancement
SEDA使用带任务权重以及正则化项的多任务目标函数。假设有T个任务,N个输入数据,则目标函数可以表示为
(8)
(8)式中:W=[w1w2…wT]表示要学习的参数;wi是第i个任务的参数;xi,j表示第i个任务第j个输入(多数情况下所有任务的输入相同);yi,j表示第i个任务第j个真实输出;βi为任务权重;Ω为正则化项;λ表示正则化项的系数;f表示模型本身;L则表示损失函数。回归任务使用MSE损失函数,计算式为
L(yi,j,f(xi,j,wi))=[yi,j-f(xi,j,wi)]2
(9)
分类任务使用过交叉熵损失函数,计算式为
L(yi,j,f(xi,j,wi))=-yi,jlogf(xi,j,wi)
(10)
3 实验分析
3.1 数据集
为了验证SEDA方法的有效性,本文在Census[20]、Climate[30]、Sarcos[31]以及Rf2[32]数据集上进行实验及分析。
Census[20]数据集来自于1994年人口普查数据库,共包含299 285条数据,收录于UCI机器学习仓库中。本文通过该数据集,构造2个基于40维特征的多任务学习问题,每个问题包含2个任务。
Numerical simulation study on the impact of a tropical cyclone on the ending of Meiyu
Income学习任务。任务1为预测收入是否超过5万美元,任务2为预测是否未婚。任务简记为Y1-Y2。
Education学习任务。任务1为预测是否从未上过大学,任务2为预测是否未婚。任务简记为Y1-Y2。
Climate[30]数据集中的数据由4个英格兰南部的传感器收集,以2017年3月1日至2017年3月31日5分钟间隔的正常气候信号(5 369个样本)为特征,将4个测站的气温预测作为学习任务。任务简记为Y1-Y4。
Sarcos[31]数据集的学习任务是预测机械臂每个关节测量的扭矩,数据集中包括7个任务和21维特征,共有44 484个样本。任务简记为Y1-Y7。
Rf2[32]数据集是一个多目标回归数据集,共包含8个任务,9 125条数据,576维特征。任务简记为Y1-Y8。
3.2 对比方法
为显示SEDA方法的有效性,本文设置了多个对比方法,包括以下。
Lasso[10]:使用l1范数对每个任务单独进行训练。
MTFL[34]:该方法为传统多任务学习方法,在任务间共享特征来进行知识共享。
NN:拥有一个隐层的全连接层,作为深度多任务学习方法的基线。
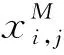
(11)
十字绣单元中,αMM和αNN被看作是任务固有信息,而αMN和αNM被认为是任务间信息传输量的阈值。Cross-Stitch网络在任务单独初始化,手动固定α的值效果最好。
MMoE[20]:该方法使用为每个任务设置一个门口结构将多个专家的输出进行加权融合,可以看作是一种多头注意力机制,也可以看作是模型集成。
MRAN[21]:该方法中使用多种关系的注意力机制。MRAN的一个明显缺陷是其方法中多种注意力机制产生的关系都是固定的,且是对输入输出进行修改,无法利用网络深层次的高级特征。本文使用基于多头注意力机制的MRAN作为对比方法。
3.3 对比实验设置
本文实验环境包括:CPU为i5-8300H,GPU为GTX1050Ti,操作系统为64位windows,开发语言为Python3.7。所有方法的实现均基于PyTorch(1.7.1-GPU版),并使用高斯过程算法[35]对超参数进行调优。本文采用Xavier参数初始化方法以及Adam优化算法,使用MultiStepLR对学习率进行简单调整,迭代次数设置为200。其中,SEDA方法在不同数据集上的参数设置如表1所示。表行网络结构为在输入层之后每个任务的具体网络设置,Linear为线性层,Relu为激活函数,FL为融合层(非当前优化任务不设置融合层)。数据集设置上,所有数据集均等分为二分别作为训练集和测试集,并为所有方法设置相同且固定的随机种子。对于回归数据集,使用均方根误差(root mean square error, RMSE)作为评价指标,对于分类数据集,使用ROC曲线下面积(area under curve, AUC)作为评价指标。
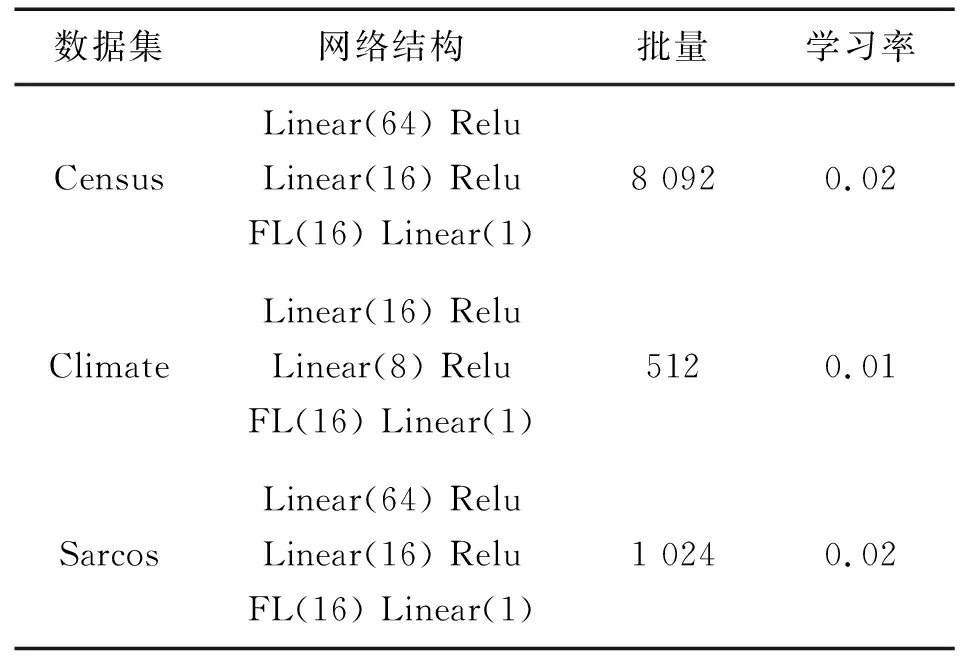
表1 SEDA方法对比实验设置Tab.1 Comparative experimental setup of SEDA
3.4 对比结果分析
表2,3,4分别为Census、Climate以及Sarcos数据集上的对比实验结果,其中,在Climate与Sarcos数据集上的CSS、MMoE及MRAN方法的实验结果沿用自文献[21]。表2中数值为AUC值,结果越大越好,表3及表4中数值为RMSE值,结果越小越好,加粗数值为对比方法中的最优结果。SEDA在3个数据集上均表现最优。相比传统方法,SEDA在3个数据集上的性能平均提升48.6%(Lasso)、46.9%(L2)和43.2%(MTFL),相比深度多任务学习方法提升45.0%(NN)、31.5%(CSS)、26.0%(MMoE)和8.8%(MRAN)。在耗时方面,深度学习对比方法在3个数据集上平均每次迭代耗时1.2 s(NN)、1.33 s(CSS)、1.92 s(MMoE)和2.4 s(MRAN),使用单任务提升训练的SEDA方法耗时3.89 s。SEDA方法相比基于注意力机制的MMoE和MRAN均表现更优,可能的原因是MMoE只是简单的模型集成,并没有特异于任务的知识,也就没有明显的知识共享。而MRAN则受制于其静态的注意力机制,以及其建立在浅层特征上的关系。

表2 Census数据集对比实验结果Tab.2 Comparative experiments on Census dataset
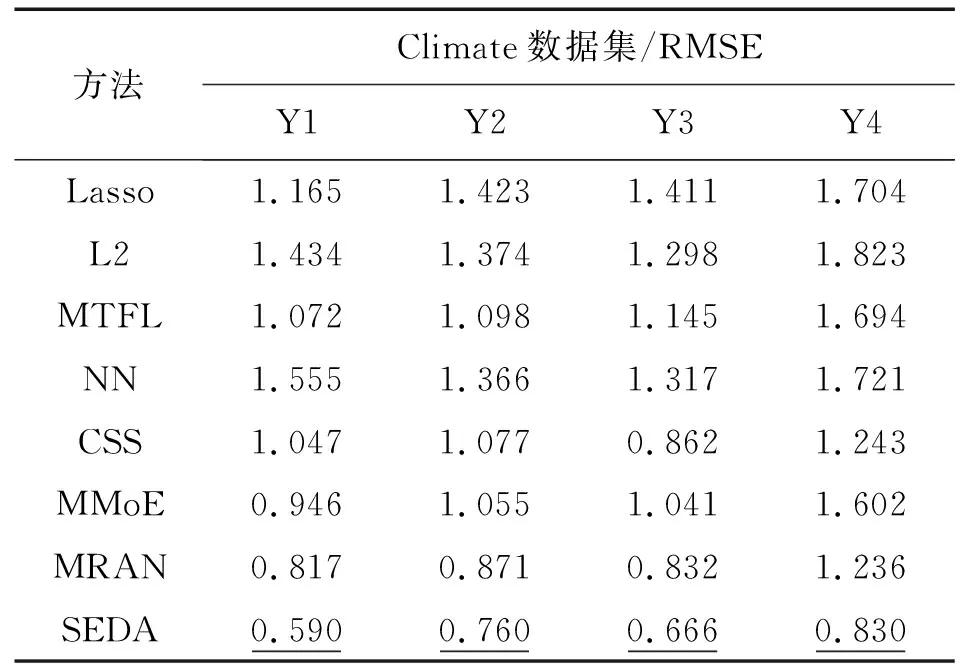
表3 Climate数据集对比实验结果Tab.3 Comparative experiments on Climate dataset

表4 Sarcos数据集对比实验结果Tab.4 Comparative experiments on Sarcos dataset
3.5 仿真参数实验
本文在Rf2数据集上对SEDA的仿真参数(即超参数)进行实验,并分析仿真参数对SEDA性能所造成的影响,参数包括融合层数量、融合层位置以及训练方式。SEDA方法融合层的输出与输入具有相同的大小,因此,可以置于任意两层网络之间。实验中的网络架构在数据输入后设置一层任务共享的线性层,随后为每个任务设置一系列相同大小的全连接层。SEDA融合层的数量和位置实验均基于此网络进行。实验过程均基于相同的学习率(lr=0.001),相同的迭代次数(100轮),以及相同的优化算法(Adam)进行,并采用五折交叉验证保证实验结果的可靠性。
融合层数量实验是为了验证同一网络中设置的融合层数量与性能的关系。本文对Rf2的8个任务分别设置了0至4层融合层进行实验。实验结果如表5所示,其中加下横线数据为任务(表行)最优结果,对应最优融合层数量。实验表明,当对Rf2的每个任务进行训练,6个任务在2层融合层时达到最优性能,2个任务在3层融合层时达到最优性能,说明,当融合层达到2层时,能使任务间知识共享效益最大化,少数困难任务则需要三层,因此,在使用SEDA时可以对融合层数量参数进行一定的实验来提升效果。

表5 Rf2数据集任务性能与融合层数量关系实验结果Tab.5 Experiments of the relationship between task performance and the number of fusion layers on Rf2 dataset
融合层位置实验在4个网络层位置设置1个融合层,位置1至4代表与输出层的距离远近,例如位置1表示置融合层于输出层前一层。实验结果如表6所示,其中加下横线数据为任务(表行)最优结果,对应最优融合层位置。实验结果表明,Rf2的所有任务将融合层置于位置1时达到了最好的效果。这反映了将融合层置于每个任务深层网络之后会更加有效,此处的网络层更能反映每个任务的高级特征,融合层也就能将更丰富的知识共享传递给当前训练的任务从而达到更好的性能,这也与MRAN浅层注意力机制形成了对比。使用SEDA方法时同样需要对融合层位置参数进行微调。

表6 Rf2数据集任务性能与融合层位置关系实验结果Tab.6 Experiments results of the relationship between task performance and the location of fusion layer on Rf2 dataset
最后进行单任务提升训练方法与同时训练方法的对比实验。在基础网络架构上,为Rf2的每个任务在同一网络层位置单独设置融合层得到实验结果,然后在所有任务相同的位置同时设置融合层进行训练得到同时训练的实验结果。实验结果如表7所示,其中加下横线数据为任务(表行)最优结果,对应最优训练方式。结果表明,相比于同时训练,单任务提升训练方法使得每个任务的性能有了更大的提升。同时训练方法中的融合层会对各任务的网络参数同时进行反向传播,梯度的累加会导致参数训练不稳定,参数空间震荡。而单任务提升训练方法会为参数训练提供明显的方向,使得参数朝着对当前训练任务有益的方向进行更新,极大地避免了知识负迁移问题。

表7 SEDA方法同时训练与单任务提升训练对比实验结果Tab.7 Experiments between simultaneous training and single task enhancement training on SEDA
4 结 论
本文提出了一种基于稠密连接注意力单任务提升的深度多任务学习方法。该方法通过稠密连接注意力单元实现特异于任务的知识共享,知识共享结构以及共享程度均为动态的训练。该方法使用单任务提升训练贪心地优化每一个任务,极大程度地规避了知识负迁移问题。实验证明,本文方法相比当前先进的多任务学习方法有明显改进,在每个任务的性能上都有较大的提升。
