基于移动设备位置数据的油气管道第三方破坏行为识别研究
2022-07-01张行凌嘉瞳刘思敏董绍华
张行,凌嘉瞳,刘思敏,董绍华
1 中国石油大学(北京)管道技术与安全研究中心,北京 102249
2 中油国际管道公司,北京 102206
0 引言
第三方破坏是管道线路安全面临的主要风险之一,我国2001 年至2020 年由第三方破坏引起的管道事故占事故总量的30%至40%。国内外管道安全研究领域学者多年来一直致力于油气管道第三方破坏事故风险的研究,重点开展了基于不确定性的第三方破坏事故可能性分析、第三方威胁事件监测预警、第三方破坏事故后果模拟等研究工作[1-3]。由于油气管网线路点多线长、人文地质环境复杂,部分地区居民并未正确认识破坏管道的危险后果,仍在管道周边实施占压、开挖等活动,或受利益驱使开展盗油盗气、破坏管道重要设施等违法活动;加之各地区工业化发展需求使得地面施工日渐频繁,各施工企业与管道运营企业之间缺乏沟通,因非管道企业施工造成管道破坏的事故时有发生,故管道保护工作仍面临巨大挑战[4-5]。
随着信息化技术的发展,庞大的手机用户群提供了大量表示其时空出行序列的手机位置数据,已经成为当前用来感知个人或群体活动规律的重要资源,在生活服务领域中得到了广泛的应用[6-8]。例如根据居民位置信息可为广告投放筛选出最合适的位置,通过获取用户位置信息向其推荐附近热门商户和服务等。基于位置信息的异常轨迹作为表征用户异常行为的重要因素之一,使轨迹异常检测成为了当前位置信息相关的研究热点。异常检测算法已经广泛应用于交通领域,例如在同一片海域中识别含异常轨迹的船只[9];基于出租车行驶轨迹发现绕路欺诈行为,利用车辆GPS定位数据对行驶道路拥堵状态进行判断等[10]。
为解决当前第三方破坏识别中存在的实时性不足、监测范围小、数据匮乏、活动预测难、不确定性强的问题,以位置数据异常轨迹研究为基础,将位置数据引入到管道第三方破坏防范领域,对打孔盗油、私人挖掘、工程建设类型第三方破坏识别展开研究。提出从位置数据中挖掘管道附近用户的行为模式,提取用户的活动规律,为管道第三方破坏活动预警提供新思路。
1 第三方人员活动异常停留点提取
1.1 数据的采集与预处理
用于识别管道第三方破坏行为的移动设备位置信息不涉及用户隐私,将采取隐藏用户真实标识信息的保密措施,通过与通信公司签订数据使用协议,说明数据使用具体用途并提交技术可行性方案,向当地公安机关备案,保证位置数据使用的合法性。位置数据采集方式可通过手机应用程序与运营商数据采集等多种方式,多样的数据来源保障了管道附近位置信息获取的可行性。
本文手机定位数据来源于移动通信网络与手机终端的交互,该交互过程可分为非周期性和周期性位置更新[11]。在数据的采集、存储过程中,由于外部自然、人为环境的干扰和移动通信网络自身存在的缺陷会导致定位数据中存在着大量“噪声”数据[12],会对定位数据的分析结果产生极大的影响。本文对收集的定位数据预处理操作如下:对字段缺失或取值不在正常范围内的无效数据进行删除;对漂移数据进行纠正或平滑处理;通过对时间间隔的设定进行时间分片,对定位数据进行等时间间隔化处理,使得每条位置数据在时间维度上代表的意义相同,为后续基于聚类算法识别定位数据中停留点提供数据基础。
1.2 基于时空聚类方法的停留点识别
对于油气管道领域,管道路由走向指出了管道位置的分布情况,管道附近用户位置数据标记了用户与管道位置的关系,轨迹停留点识别有助于挖掘位置数据中与用户日常行为特征有关的重要信息。对用户轨迹中的停留点进行提取、处理与分析,可在一定程度上对用户活动规律进行重新刻画[13-14]。在与管道相关的私人挖掘、工程建设、打孔盗油等第三方破坏活动中,由于破坏活动的实施过程需花费一定时间,其部分移动轨迹一定会表现出停留或在一定区域内移动的状态,故管道附近用户的停留点提取是识别管道异常第三方活动的首要研究内容,本文将停留点定义为用户在管道或光纤两侧一定范围内停留时间超过给定时间阈值的位置。
在对手机位置数据进行预处理后,得到按时间排序的等时间间隔定位数据,手机用户在某个地点停留时间的长短可以根据定位轨迹点在空间上的密度计算得出,但如果仅以空间密度作为唯一依据进行停留点筛选,可能将处于不同时间段但距离相近点聚集在一起,造成停留点的误识别。因此本文利用一种基于点排序的时空聚类算法识别停留点[15-16],首先根据位置数据的密度在空间层上对轨迹点进行聚类,再结合停留点判别时间阈值约束条件,初步实现管道附近区域手机用户停留点的获取。
在基于点排序的时空聚类算法进行停留点识别时,将所采集位置数据用于创建初始样本集D;创建有序队列Q用于保存核心对象及其对应的直接密度可达对象,队列中元素按可达距离顺序从小到大依次进行排列;同时创建结果队列O用于存储已完成访问处理的样本点。基于时空聚类方法的停留点识别步骤如下:首先,从样本集D中随机选取一个核心对象样本点作为研究对象存入结果队列O中,同时搜索该样本点给定邻域半径内所有直接密度可达对象,将所有对象按要求规则放入有序队列Q中,此时可达距离最小的元素排在队首。其次,从有序队列Q中取出样本点,将其标记为已访问样本点后保存至结果队列O中,并对该点进行核心对象判别,若该样本点为核心对象,则继续搜索其给定邻域半径内直接密度可达点并存储到有序队列Q中,每次插入新样本点到有序队列Q中都按可达距离排序进行位置更新;按照以上步骤对样本集D中所有数据进行处理。为进一步完成结果队列O中的样本点聚类,依次取出结果队列O中样本点p进行判别。首先进行样本点p可达距离与给定半径ε之间的比较,若样本点p可达距离在给定半径ε范围内,则将该点划分到当前点簇中,否则进入下一步判别;第二阶段判别以样本点p核心距离与给定半径ε之间的大小关系为判断依据,若样本点p核心距离大于给定半径ε,则将该点判断为噪声,反之,若样本点p核心距离不大于给定半径ε,则将该点划分到新的聚类中。按照上述判断流程,遍历结果队列O中所有样本点。最后,按位置数据中时间要素对样本数据进行排序更新,生成以位置数据时间戳为横轴,样本数据可达距离为纵轴的排序图。
提取管段附近某一时段手机定位数据进行停留点识别与分析,表1 列出了预处理后某手机用户的定位数据。其中,用户识别码是经脱敏处理后的用户标识码,表示用户身份信息,具有唯一性;时间戳指获取位置时的时间信息,已完成等时间间隔处理,同一用户两条位置数据间的时间间隔为2 min,即120 s;经度、纬度是位置数据中直接获取到的信息,为方便距离计算,将位置数据中经度、纬度分别转换为投影坐标下的墨卡托经纬度。
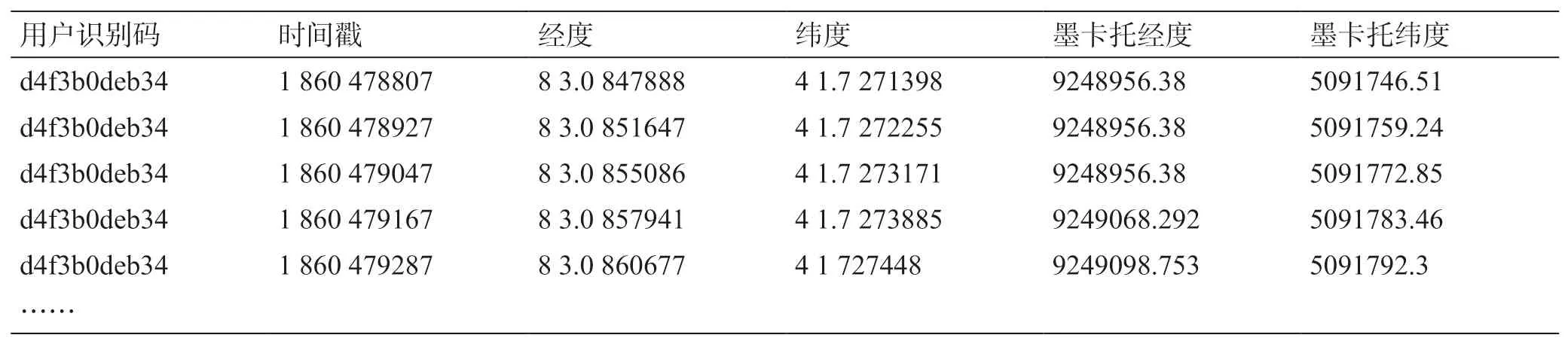
表1 定位数据Table 1 List of location data
结合第三方破坏停留时间特征,在本停留点识别中约束条件设置如下:时间邻域设为1800 s,距离邻域设为3 m,最小邻域点数MinPts设为15,基于该参数取值进行停留点识别,可达距离排序图如图1 所示。
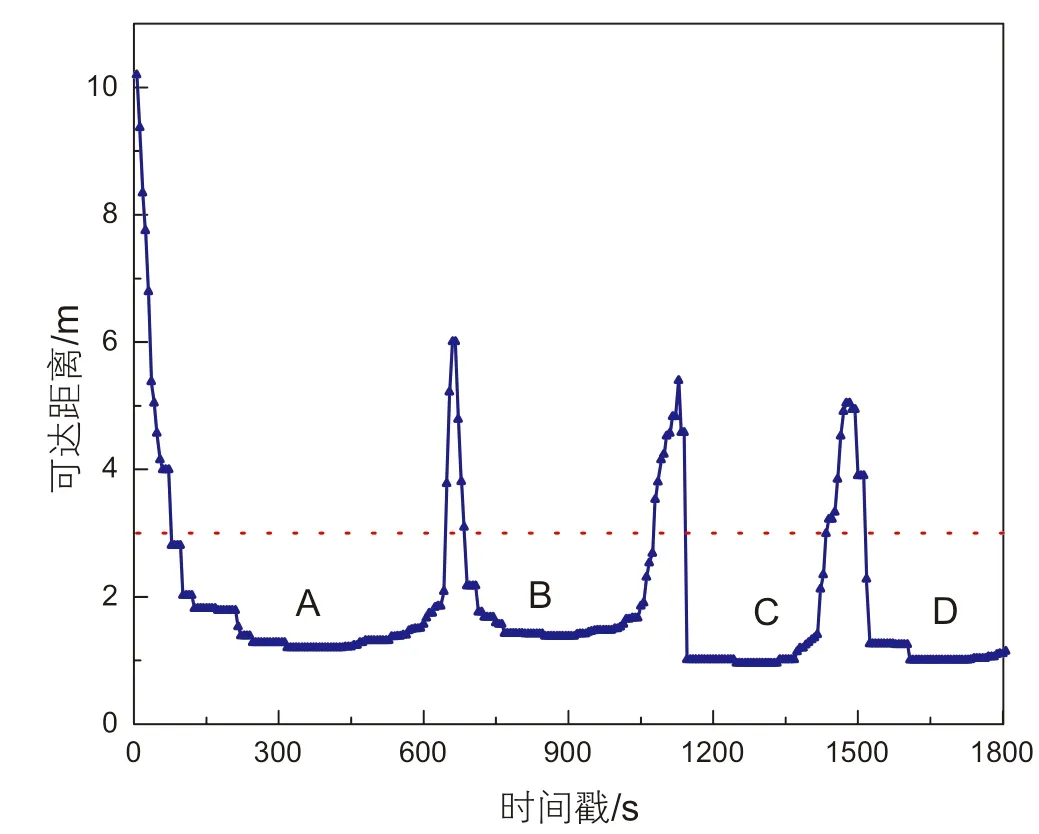
图1 可达距离排序图Fig. 1 Reachable distance sorting graph
从可达距离排序图可知,样本点最大可达距离10.2 m,大部分样本点可达距离集中在1 m附近,当距离邻域设定为3 m时,该数据集共识别出簇稠密区A、B、C、D共4 个停留点。从时间戳信息中可以判断停留时间由长到短依次为A点、D点、B点、C点。可达距离排序图在原位置数据中的聚类结果如图2 所示。
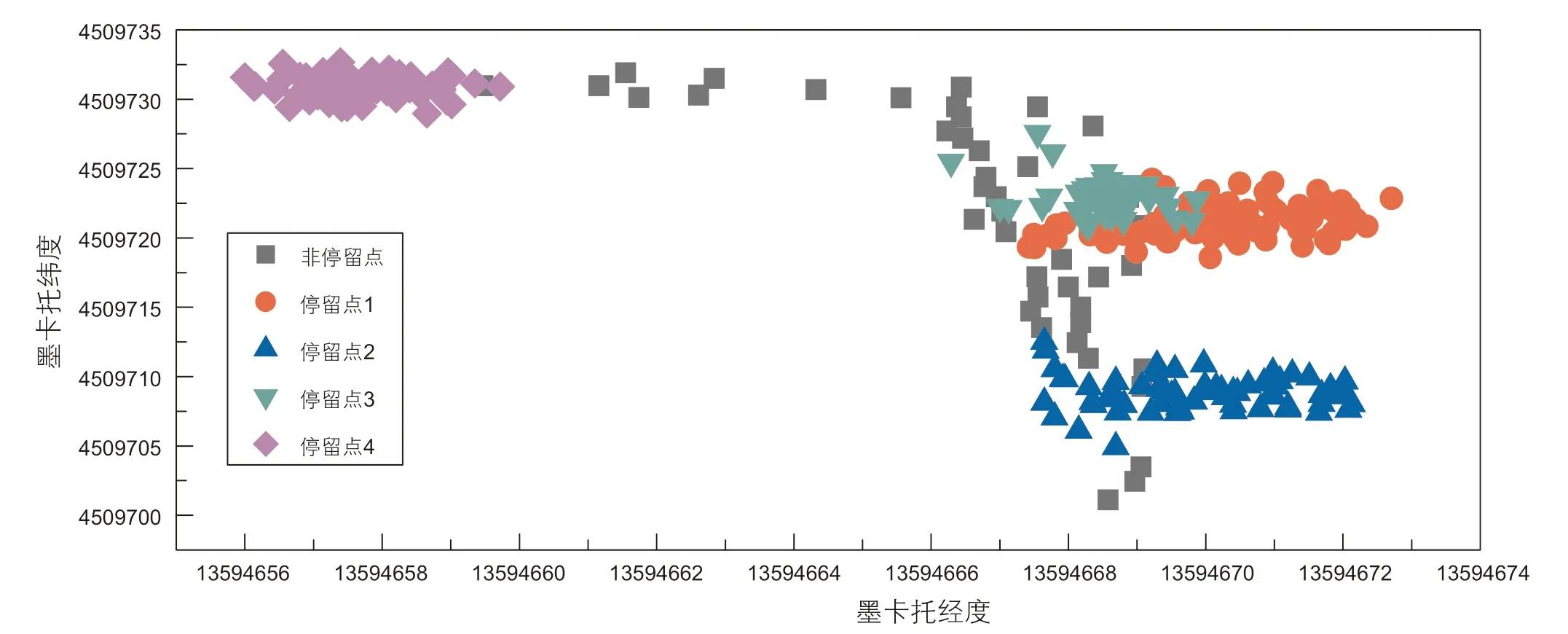
图2 聚类结果图Fig. 2 Clustering result graph
2 第三方人员活动轨迹差异度计算
2.1 寻找轨迹邻域
基于由于第三方破坏行为特点的多样性,难以对异常行为轨迹的移动特征进行具体的总结归纳,本文提出利用管道附近移动对象之间的关联性对异常轨迹进行识别。位置特征是轨迹的基本特征之一,包括轨迹分段起始点经纬度,轨迹数据反映了移动对象的位置活动规律,标记了第三方用户在监测范围内的空间位置变化情况,通过位置信息可获取轨迹分段在当前局部空间中的其他近邻轨迹[17]。第三方人员在管道附近区域的正常活动普遍具有周期性与规律性,如果一个对象与邻域内的对象都发生了偏离,则该对象也一定偏离距离它更远的对象,换言之,一个基本单元的空间特征往往能被邻域内的基本单元所反映。各轨迹分段按位置特征查找邻域,轨迹分段tfi的局部空间近邻包括所有与tfi距离不超过给定距离阈值d的轨迹分段集合。
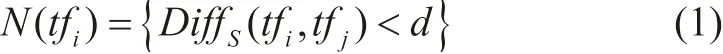
式中,N(tfi)表示轨迹分段tfi的近邻轨迹分段集合,DiffS(tfi, tfj)表示轨迹分段tfi与tfj两条轨迹之间空间距离,具体描述为轨迹段间垂直、水平、角度距离的综合加权。
2.2 邻域轨迹差异度
异常轨迹通常被描述为违反某类既定规则的事件,或是表现出不同于大多数对象的行为。在不同应用场景中,用户的异常轨迹通常被描述为轨迹异常、地点异常、行动异常等[18-19]。通过对管道附近行人移动特征的研究与分析,要实现对第三方破坏行为的早期预警,找出第三方破坏的迹象和正在实施的第三方破坏行为,准确识别第三方异常轨迹是关键。将相邻区域内移动轨迹进行比较,若某一轨迹与大多数第三方运动轨迹相似,则认为其为正常活动行为,反之判断为异常行为活动。
提取轨迹的速度、加速度、转角作为判断异常轨迹移动特征。速度特征作为移动对象的固有属性之一,表示移动对象运动的快慢程度,在第三方进行异常活动时,相应轨迹通常表现为停留或是以极小的速度移动,利用轨迹特征点中的地理位置标记和时间标记来计算手机用户速度,方向即沿特征点连线方向。加速度特征是移动对象的内在属性之一,表示移动对象速度的变化情况,因为异常行为的出现一般可表现为速度的突变,包括速率和方向,所以加速度是判断异常轨迹的重要因素。转角特征表示移动对象运动方向的变化量,由目标特征点与紧邻前、后时刻特征点连线所构成的角度,轨迹转角的异常变化一定程度上反映了受外界扰动或影响情况,第三方异常行为轨迹与正常行为轨迹存在的位置偏移现象可用转角特征表示。依据移动特征计算轨迹分段行为差异度,寻找出在轨迹邻域内发生移动偏移的轨迹分段。
根据不同移动特征对异常轨迹识别的重要程度分别赋予恰当的权重并进行加权处理。
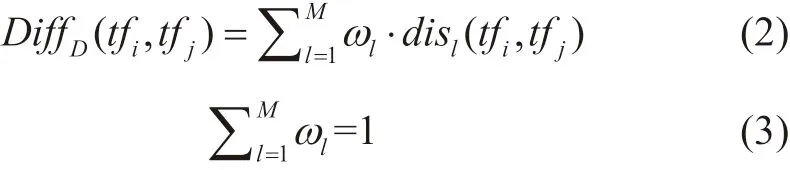
DiffD(tfi,tfj)表 示 轨 迹 分 段tfi和tfj的 行 为 差 异 度,以ω1, …… ,ωM分别表示轨迹数据每个特征的权重,disl(tfi,tfj)表示任意两条轨迹分段tfi和tfj在特征l上的距离。
为了计算轨迹分段的异常程度,将轨迹异常因子(Trajectory Anomaly Factor,TAF)用于表示轨迹分段在其轨迹邻域内移动的异常程度。由于同一用户轨迹会根据不同特征点被划分为多个轨迹分段,所以在计算某一用户轨迹异常因子时,选取最大异常因子作为该用户最终轨迹行为差异度。
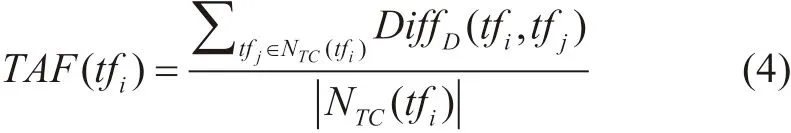
式中,TAF(tfi) 为轨迹分段tfi的轨迹异常因子,DiffD(tfi,tfj)为轨迹分段tfi和tfj的行 为差 异度,|NTC(tfi)|为轨迹分段tfi邻域内轨迹分段个数。
3 基于决策树的异常活动识别
决策树是基于有监督学习进行分类的方法,能够从给定的带有特征和属性标签的样本中分析特征与属性间的映射关系,并以树状图的结构形式呈现决策规则,实现对新样本的正确分类[20]。基于历史破坏数据先验信息,建立异常活动识别决策树,将第三方人员的行为与管道风险特征结合,对轨迹行为差异度大的异常活动进行第三方破坏类型的判断。
3.1 特征提取
管线监测范围内待识别的破坏行为与历史破坏行为通常具有相似性,且第三方人员的破坏行为与管道风险因素之间存在相关性,本文采用基于数据驱动的方法挖掘第三方人员行为特征。通过第三方破坏风险因素识别与相关信息收集,将管道风险特征与第三方人员的行为特征作为管道第三方异常活动识别决策树模型输入特征[21]。时间和人数特征按实际数值给出,其余各特征参数对应下表内容给出。
3.2 基于决策树的第三方异常活动识别模型
通过建立一种基于决策树的管道第三方异常活动识别方法,挖掘管道风险特征、第三方活动特征与第三方破坏类型的潜在关系。利用开源python语言sklearn机器学习工具包,调用tree模块,对模型对象进行实例化、训练、测试,完成一棵完整决策树的建立。模型建立步骤如下:
(1)确定输入与输出。将第三方活动时间、人数、位置、当地经济水平、公众宣传效果、巡线质量、安全标志、人员活动频率共8 个因素作为输入特征,第三方破坏类型作为标签,根据历史数据建立模型,挖掘各类特征与第三方破坏的关系。
(2)确定最佳节点和最佳的分枝。纯度用于衡量节点处各类标签所占比例,在决策树模型中以不纯度作为衡量最佳节点与分枝的指标,较低的不纯度值表明决策树对训练集的拟合效果越好。在异常活动识别模
型中引入信息熵和基尼系数作为衡量指标分别对节点不纯度进行了计算,结果表明两种不纯度指标下的模型准确率大小基本相同,最终选择信息熵作为衡量指标。
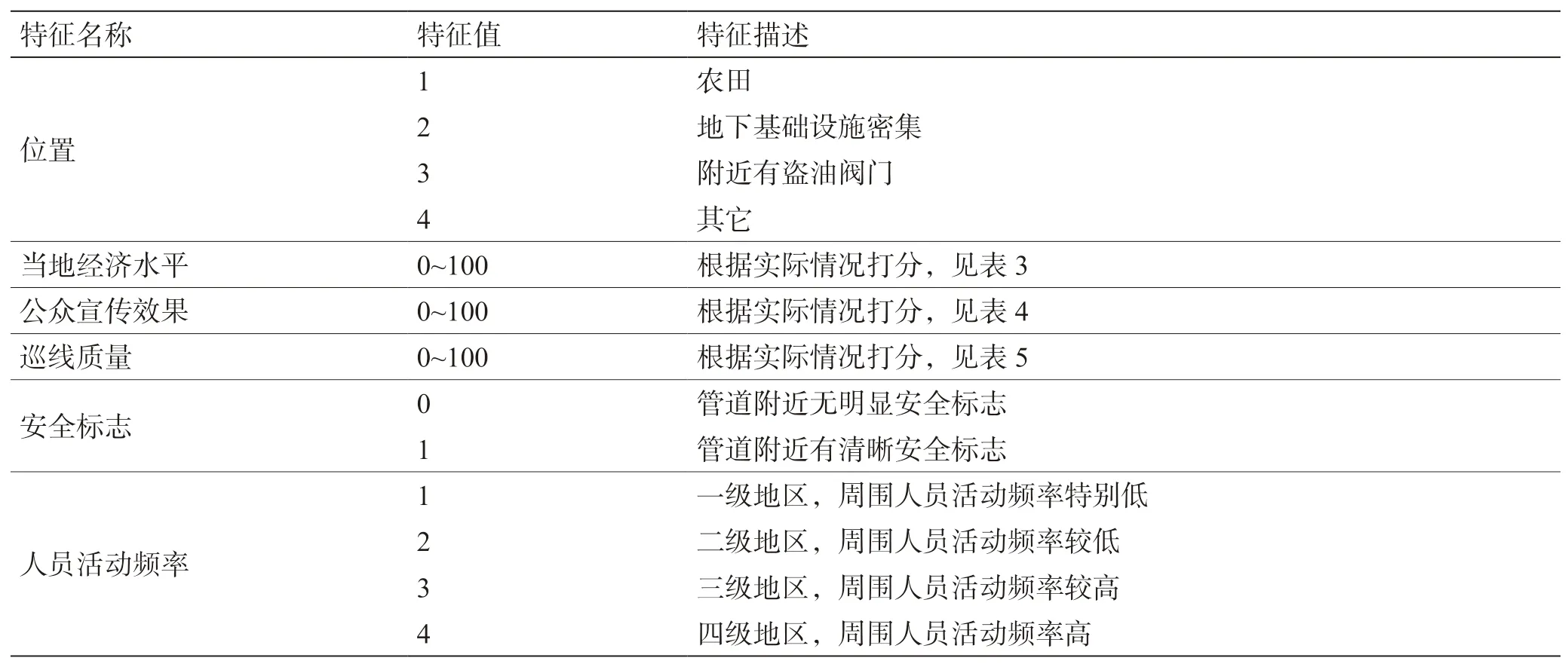
表2 特征值表示Table 2 Characteristic value description

表3 当地经济水平Table 3 Economic level description

表4 公众宣传效果Table 4 Publicity effect description
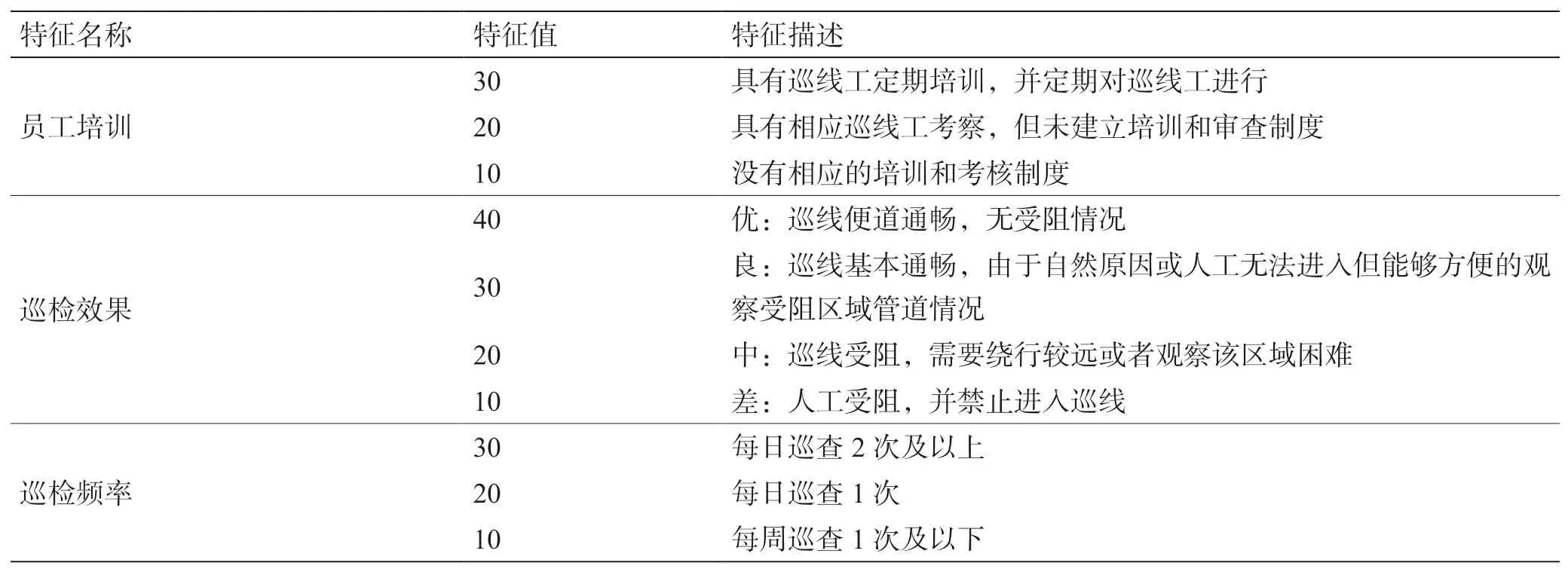
表5 巡线质量Table 5 Line inspection quality description
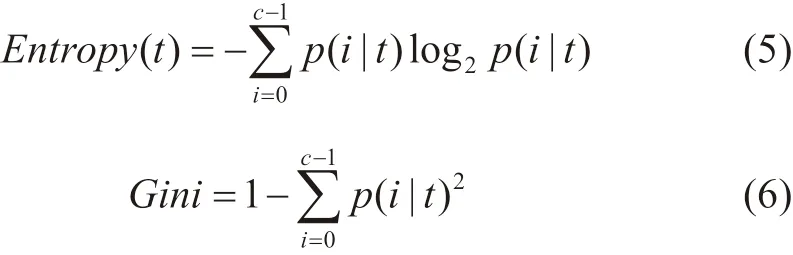
式中,Entropy为信息熵,c为叶子节点上标签类别的个数,t为决策树节点,i为标签分类,p(i|t)为标签分类i在节点t中的占比,Gini为基尼系数,该模型中的信息熵值是父节点信息熵与子节点信息熵之差。
(3)确定最大深度值。为使模型具有更好的泛化性,减轻过拟合对结果的影响,应对决策树进行剪枝操作。设置树的最大深度值(max_depth)是限制过拟合的有效方式,通过计算不同深度下的模型拟合效果以确定最佳决策树深度值。结果表明,当决策树最大深度为4时模型准确率达到最大值,当深度小于4 时决策树欠拟合且未能覆盖重要特征;当深度大于4 时,多余的分枝使得模型过拟合,不仅增大了模型计算负担,而且降低了模型准确率。因此,确定max_depth为4。
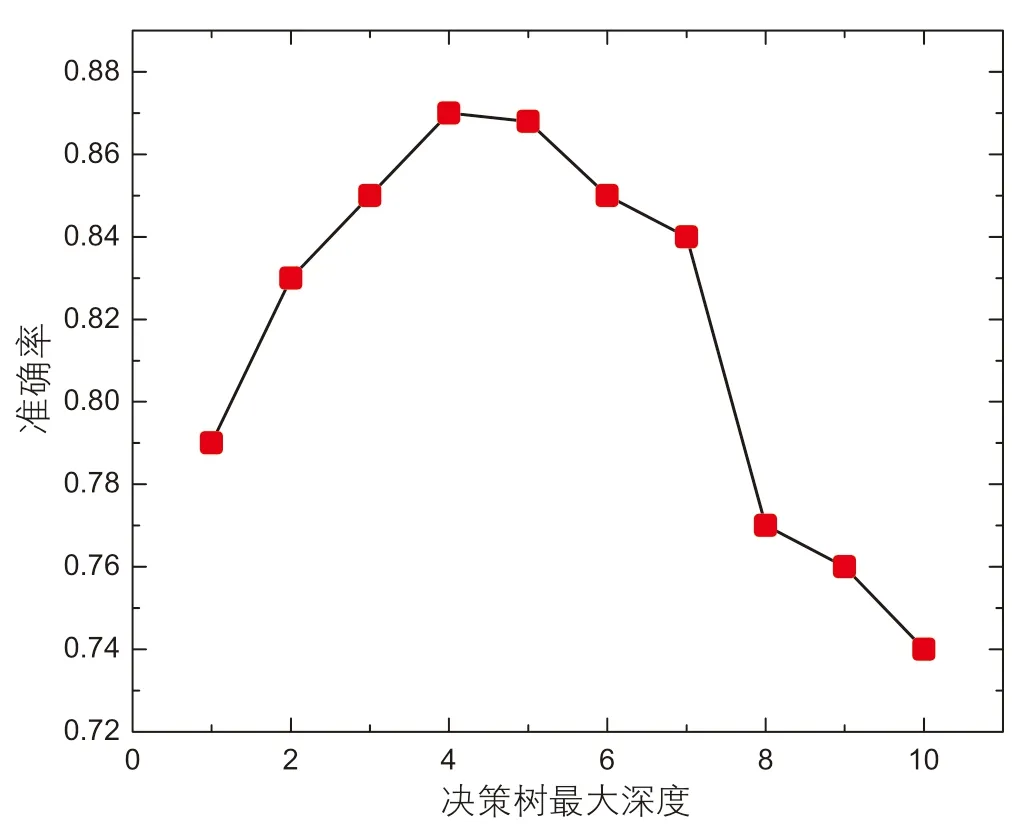
图3 不同深度决策树准确率Fig. 3 Accuracy of decision trees with different depths
(4)决策树剪枝策略优化。设置最小叶子节点样本数(min_samples_leaf,msl)与最小划分样本数(min_samples_split,mss)值对决策树进行优化,最小叶子节点样本数msl表示在分枝后的任一子节点都必须包含至少msl个训练样本;最小划分样本数mss表示当节点包含至少mss个训练样本时才允许被分枝。为寻找基于决策树的异常活动识别模型中最小叶子节点样本数与最小划分样本数的最佳组合,对0~50 之间的数字组合进行遍历,最终得出当最小叶子节点样本数为2,最小划分样本数为4 时模型准确率最高。
3.3 模型训练与测试
将所收集到第三方破坏历史特征数据7/10 划分为训练集,3/10 划分为测试集,按照决策树建立步骤,由训练集数据所建立的异常活动识别决策树如图5 所示,该决策树的结构表明了根据各类特征对第三方异常活动类型进行判断的过程,用测试集对模型准确率进行测试,该识别模型准确率为90.9%。
异常活动类型判断决策图如图4 所示,为5 层决策树,第一层首先对巡线质量特征进行判断,比较其对应特征值与68.203 的大小关系并进入决策树第二层,对时间和位置特征进行判断,以此类推,直到判断出最终的活动类型。在该决策树中,entropy为不纯度指标,samples值表示样本个数,value值表示属于不同类型破坏样本个数,如value=(10,41,35,14)表示属于打孔盗油类别样本数为10 个,属于私人挖掘类别样本数为41 个,属于工程破坏类别样本数为35个,属于其他类别样本数为14 个;class代表最终分类结果,不同种颜色代表所属不同的破坏类型,其中两个分类结果为打孔盗油的白色方框不纯度指标为1,难以进行判断,其分类结果不准确。
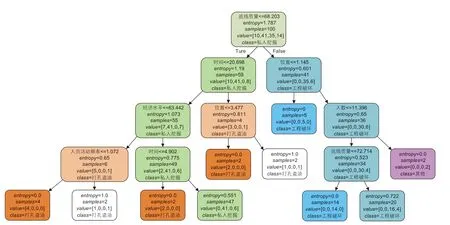
图4 异常活动类型判断决策图Fig. 4 Abnormal activity type decision diagram
对不同类型的第三方破坏活动判别特征分别如下,打孔盗油破坏的判别含巡线质量、时间、经济水平、位置、人员活动频率共5 个特征,私人挖掘破坏含巡线质量、时间、经济水平共3 个特征,工程破坏含巡线质量、位置、人数共3 个特征。各类特征的重要程度如表6 所示,权重越大,对应特征对模型贡献度越大,所提取的8 个特征因素中,公众宣传效果和安全标志在该模型中对第三方破坏类型的判断无影响,其余6 个影响因素对破坏类型判断的影响权重依次为:巡线质量、时间、经济水平、人数、位置、人员活动频率。

表6 各特征权重Table 6 Feature weight
在该模型中,决策树各分枝判断依据及模型的准确率将根据数据量的变化有所更新,当有更多的历史数据作为训练集输入到模型中时,需要重新调整各特征参数,并对模型进行优化。
4 结论
(1)通过对某长输管段附近第三方活动进行监测,基于时空聚类法提取异常停留点,得到了停留点识别决策图与聚类图,直观地反映了管道附近用户移动规律。
(2)结合轨迹位置特征与速度、加速度、转角多个移动特征的轨迹行为差异度计算,综合体现了轨迹分段在其邻域内移动的异常程度,为管道监测范围内第三方异常轨迹的识别提供重要依据。
(3)针对差异度值较大的用户轨迹,基于管道第三方破坏行为识别决策树模型挖掘第三方风险特征与第三方破坏行为的潜在关系,有助于及时发现私人挖掘、工程破坏和打孔盗油等第三方管道破坏活动,实现第三方破坏智能防范。
