基于IHBMO-RF 的眼底硬性渗出物检测①
2022-06-29赵仕成殷伟东
赵仕成, 马 力, 张 伟, 陈 颖, 殷伟东
(南京市卫生信息中心, 南京 210003)
1 引言
随着社会经济的快速发展, 人们的生活质量得到了很大提高, 饮食结构也不断改变, 高糖高热量食物的摄入导致糖尿病的发病人数不断增加[1]. 据统计, 2017年我国的糖尿病患者已达1.14 亿, 给国家带来了严重的社会和经济负担[2]. 糖尿病的并发症主要在血管硬化、糖尿病肾病、糖尿病足、周围神经病变, 视网膜病变等[3]. 其中糖尿病视网膜病变(diabetic retinopathy,DR)是糖尿病患者最主要的并发症之一, 有调查研究显示, 在糖尿病人群中10 年的DR 患病率达60%, 15年的DR 患病率达75%–80%, 是糖尿病患者致盲的主要原因[4], 对DR 的早期发现和诊断能够有效降低糖尿病患者的失明率, 提高患者的生活质量, 减少社会医疗支出, 具有重大意义[5].
传统的DR 检测主要依靠专业医师来人工发现诊断, 由于存在主观的判断和外界因素的干扰, 效率低且错误率高[6]. 计算机辅助系统的出现为DR 筛查提供了新的路径, 可以有效来对DR 进行辅助检查诊断, DR的主要表现是出血斑点、渗出、血管异常等[7], 其中检测的关键环节就是对硬性渗出物(hard exudates, HE)的检测, 硬性渗出物是DR 患者早期的明显特征[8], 因此如何准确检测到硬性渗出物是计算机辅助系统的主要任务.
硬性渗出物准确检测一直是专家学者研究的热点之一, 主流的检测算法主要分为两个大类: 一是先对眼底图像的关键结构进行分割, 然后对HE 病变进行检测; 二是先对眼底图像进行特征提取, 然后使用机器学习、深度学习等等算法对图像进行分类, 然后检测HE病变结构. 高玮玮等人通过Otsu 阈值分割和数学形态学相结合的方法快速提取视盘, 再根据数学形态学来构建糖尿病视网膜病变的自动检测的系统[9]. 吕卫等人发现利用单独的形态学方法对图像进行增强时, 由于一些外在因素的影响, 存在效果不佳的问题, 提出了一种基于改进的数学形态学糖网渗出物的自动检测方法,主要的改进方法是在亮度矫正之后, 通过多尺度的顶帽变换对图像进行增强, 避免了方向的单一性; 再综合图像边缘信息和亮度信息的方法定位视盘且利用水平集分割视盘, 最后利用背景估计的方法提取渗出物的轮廓[10]. 段彦华等人提出一种基于Canny 边缘检测算法与形态学重构相结合的HE 自动检测方法, 以解决目前算法灵敏度低、检测结果中视盘和血管的干扰等问题[11]. 韩婧通过对糖尿病视网膜图像视盘分割, 然后提出基于BAKFCM 硬性渗出物区域分割和基于PCAGA-SVM 硬性渗出物分类检测全方位来研究硬性渗出物检测算法[2]. Amel 等人主要是对L 通道进行增强, 再结合阈值处理和形态学重建消除视盘区域, 最后使用K-means 聚类、边缘检测及形态学重建的方法提取渗出物[12]; Sopharak 等人通过对I 通道进行增强, 然后利用形态学的方法分割视盘, 最后再结合标准差滤波和形态学重建的方法检测渗出物[13]; Osarah 通过采用Fuzzy C-Means 聚类获取渗出物候选区域, 再通过分类得到硬性渗出物[14]. Wang 等人利用深度卷积神经网络和多特征联合表示HE 检测新方法[15]. Theera-Umpon等人通过应用多种图像处理技术检测硬渗出物, 使用监督学习方法对其进行分类, 包括支持向量机、多层感知器(MLP)网络、分层自适应神经模糊推理系统(分层ANFIS)和卷积神经元网络[16].
由上述文献可以看出, 目前基本对硬性渗出物位置的检测都是使用形态学或者机器学习的方法, 一旦使用机器学习的算法就要考虑算法最优问题的解决, 机器学习中大部分的算法不是纯粹的凸函数, 或者是凸规划, 所以采用迭代下降的方法, 这种研究方法很容易陷入了局部最优的困境, 找到的通常是局部最优, 这样的模型对于眼底硬性渗出物的检测很不利, 会影响检测的准确度. 为了解决这个问题, 本文提出一种基于蜜蜂交配优化-随机森林 (honey bee mating optimizationrandom forests, IHBMO-RF)的眼底硬性渗出物的检测算法研究, 优化后的IHBMO 算法不仅能快速找到全局最优, 而且能够有效精确提取渗出物, 具有很好效果.
2 理论基础
本文对提出了基于IHBMO-RF 的眼底硬性渗出物的检测算法, 首先对眼底数据集的图像进行预处理分割, 完成后利用IHBMO-RF 算法对图像进行分类,得到最终的结果, 流程见图1. 下面将对蜜蜂交配优化(HBMO)算法和IHBMO-RF 算法相关原理进行描述.

图1 流程图
2.1 蜜蜂交配优化(HBMO)算法原理
Abbass 在2001 年提出了一种以蜂群的繁殖行为作为模型而设计的一种蜜蜂交配优化算法(honey bee mating optimization, HBMO)[17]. 蜂群算法是由蜂王、雄蜂、工蜂和幼蜂组合而成[18]. 在蜂群中, 蜂群中的每只蜜蜂都有着自己的职责. 蜂王是唯一能够繁殖后代的雌性蜜蜂, 它的主要职责是产子; 而雄蜂的主要任务是与蜂王进行交配, 一旦交配结束, 则雄蜂的生命也即将结束; 工蜂的主要责任是照顾幼蜂、修整蜂巢等工作. 基本的蜜蜂交配优化算法的步骤如下所示[19]:
1) 群体初始化: 设置雄蜂的数量、幼蜂的数量、蜂王受精囊的大小, 将个体中适应度值最大的蜜蜂视为蜂王, 而蜂王的选取是根据随机森林(RF)算法对眼底图像的特征数进行分类的结果作为当前的最大的适应度值, 其他视为雄蜂.
2)婚飞: 婚飞过程中, 蜂王以固定的速度在不同的状态来回转变, 设蜂王的初始速度和能量分别为S(0)、E(0), 而在每一种状态下, 雄蜂以Pi的概率与蜂王进行交配, 若交配成功, 则将雄蜂的染色体植入受精囊中.在每次状态更新后, 蜂王的速度和能量有所减弱, 具体计算公式如下:
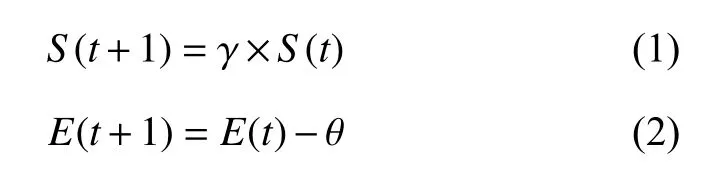
其中,S(t)、E(t)为t时刻蜂王的速度和能量, γ ∈[0,1]为衰减系数, θ ∈(0,1)是指在每次状态更新后能量的衰减值, 而当蜂王的速度和能量值达到预先设定的临界值,则蜂王飞回蜂巢. 在婚飞的过程中, 雄蜂与蜂王进行交配, 公式如下:

其中, Δ(f)为雄蜂与蜂王的适应度之差.
3)繁殖过程: 在受精过程中, 随机的选择一条染色体与蜂王的染色体结合, 产生幼蜂[20].
4)饲养过程: 工蜂采用启发式算法, 通过不断地对幼蜂进行局部搜索, 寻找适应度值最好的解.
5)若幼蜂的适应度的值高于蜂王, 则取代蜂王, 否则仍然保持原样, 剩余的为雄蜂.
6)判断是否达到婚飞次数. 若达到, 则停止飞行,否则转到步骤2).
蜜蜂算法的流程图如图2 所示.

图2 蜜蜂交配优化算法的流程图
2.2 佳点集原理


3 IHBMO-RF 算法的改进
对渗出物候选区域进行二分类, 划分的依据是将眼底图像的公共数据库中所提取的候选区域与数据库中提供的真实的分类的标签进行对比, 以此将渗出物候选区域划分为硬性渗出物和非硬性渗出物. 将渗出物候选区域内的特征数作为优化的变量, 通过使用改进的IHBMO 对特征数进行优化, 获取最合适的特征子空间的维数, 而将最初的特征数根据RF 算法分类得出的结果作为初始蜂王, 此时的蜂王的适应度的值最大, 具体的IHBMO 优化如下.
二维初始化蜂群时, 在相同的取点数下, 运用佳点集的方法取点比随机初始化蜂群会更加均匀, 因此将佳点集的原理结合到HBMO 算法中可以均匀初始化蜂群. HBMO 算法在每次迭代的过程中, 让幼蜂秉承了蜂王的优良的基因, 增加了后代蜂群进化最优解的可能性. 传统的HBMO 算法是随机初始化蜂群, 增加了计算的复杂度, 所以本文引入佳点集的方法对蜂群进行初始化, 加快蜂群的收敛速度. 由于传统的HBMO算法易陷入局部最优, 且易早熟收敛, 因此, 在迭代的过程中, 引入了随机蜜蜂来代替那些表现不佳的雄峰,进而维持蜂群的丰富性, 得到全局最优解.
改进蜜蜂交配优化算法的流程如下:
1)蜂群初始化: 将个体中适应度值最大的视为蜂王, 剩余的作为雄峰;
2)婚飞: 蜂王以初始速度S(0)和初始能量E(0)飞行, 若蜂王的能量已达到临界值, 则直接转入步骤3),否则, 随机选择雄峰, 按照式(3)来计算交配的概率Pi,若Pi>r,r∈[0,1], 则将此雄峰的染色体加入受精囊中,雄峰宣告死亡, 设counter=0, 否则counter++, 然后再根据式(1)和式(2)计算雄蜂的速度和能量;
3)繁殖过程: 蜂王q与雄峰dri根据式(4)和式(5)产生幼蜂bri、br′:

4)饲养过程: 工蜂通过对蜂王和幼蜂进行局部搜索, 而产生新的值, 若现在的值高于原来的值, 则将现在的值来取代原来的值;
5)若第i只雄峰的counteri大于预定值, 则被取代,否则不变;
6)若当前幼蜂的适应度的值大于蜂王的适应度的值, 则蜂王的位置由幼蜂暂时保管, 否则保持不变;
7)当迭代次数一旦大于预先设置的数值时, 则宣告循环结束, 否则转到步骤2), 迭代次数再加1;
改进蜜蜂交配优化算法的适应度函数曲线如图3.

图3 适应度变化曲线图
从图3 可知, 随着迭代次数的不断地增加, 适应度的值不断地趋近于1, 逐步趋向于最优状态; 其主要原因是由于改进的蜜蜂交配优化算法, 通过引入佳点集原理, 引入了随机蜜蜂来代替那些表现不佳的雄峰, 进而维持蜂群的丰富性, 降低了算法易陷入局部最优的问题, 致使整个寻优过程不仅收敛快且稳定性好.
4 实验结果与分析
4.1 数据集及评价指标
本文在公开的眼底数据库DiaretDB1 下进行试验[22].选取了89 幅分辨率为1500×1152 的眼底图像, 其中包括47 幅病变图像和33 幅棉绒斑图像. 对任意一幅眼底图像, 以数据库中图像标注的病变结果作为参考, 检测出相同或者不同的区域分别称为真阳性(TP)和假阴性(FN), 同理, 以标注的正常的区域作为参考, 本文算法给出相同或者不同的结果分别称为真阴性(TN)和假阳性(FP). 基于此, 分别有4 种评价参数: 灵敏度(SE)、特异性(SP)、阳性预测率(PPV)及准确率(AC).其中, 敏感性也被称为真阳性率, 是指运用某种方法能检测出病变的概率; 特异性也被称为真阴性率, 是运用某种方法来判定某种病变的概率; 阳性预测值是指真实患病的人数占整个患病人数的百分比. 其计算公式如下:

糖网的眼底硬性渗出物的检测方法的性能的评价标准是基于灵敏度(SE)、特异性(SP)、准确率(PPV)及预测值(AC)这4 种参数来判断图像是否含有硬性渗出物, 进而判断疾病是否可靠的依据.
4.2 实验结果
本文实验是在Windows 10 操作系统, Matlab 2014a的编程环境下进行的. 在公共数据库DiaretDB1 中, 对方法进行性能测试.
根据本文方法对候选区域进行分类得到最终的眼底硬性渗出物的位置, 如图4 所示, 图4(a)表示利用IHBMO-RF 算法检测的眼底硬性渗出物的具体的位置, 图4(b)表示检测的眼底硬性渗出物在彩色眼底图像中具体的位置.

图4 硬性渗出物的位置标记图像
主要根据算法的SE、SP、PPV及AC四个方面进行评价, 本文方法和其他检测硬性渗出物的方法的比较结果如表1 所示.

表1 本文方法与其他检测算法的比较 (%)
由表1 可以看出, 与Welfer 等人[23]基于数学形态学对彩色眼底图像渗出物进行检测和Osarah 等人[14]提出的K 近邻、高斯二次和高斯混合模型分类器的机器学习方法相比较, 本文的阳性预测值分别高出了70.98%和3%. 比使用支持向量机(SVM)[24]算法来分类眼底硬性渗出物准确率提高了1.7%, Niemeijer 等人提出的全自动的机器学习方法虽然在敏感性和阳性预测值上取得较好的效果, 但是准确率上稍微有所欠缺[25].Fraz 等人提出的用于视网膜眼底图像渗出物多尺度定位和分割的自举决策树集成分类器, 通过两者结合, 效果不错, 本文的准确率比其高出7.68%[26].
通过使用IHBMO 算法对选取的RF 算法内的特征数进行优化, 而获得特征子空间的维数, 进而获取特征向量以及新的数据集, 然后在公共的眼底数据库中提取渗出物候选区域与现有的分割出的渗出物进行对比, 生成硬性渗出和非硬性渗出的二分类的分类标签[27].最后根据RF 算法将新数据分为测试集和训练集, 从而获取最终的眼底硬性渗出物的位置, 得出的SE、SP、PPV和AC的数值分别为95.65%、88.23%、92.3%、95.4%.
IHBMO-RF 算法的准确率相较于其他人的算法,在准确率上更高且稳定性更好, 但在敏感性、特异性及阳性预测值方面仍有欠缺, 因此, 在未来的研究中,仍然需要对算法做进一步的优化, 以便能更准确地检测眼底硬性渗出物的位置, 减少误诊率及漏诊率.
5 结束语
糖尿病视网膜病变患者越来越多, 为了更好早期诊断, 对眼底硬性渗出物的检测至关重要, 为了解决机器学习中陷入的局部最优的困境, 本文提出了一种基于IHBMO-RF 算法的眼底硬性渗出物的检测算法研究. 在IHBMO-RF 算法的眼底硬性渗出物的分类中,主要是通过HBMO 算法的理论知识及佳点集原理, 然后因为HBMO 算法存在的不足, 提出了改进的方法.由于HBMO 算法是随机初始化蜂群, 导致计算的复杂度不断地增加, 易陷入局部最优状态; 因此, 通过引入佳点集原理对蜂群进行初始化, 不但能保持蜂群的多样性, 而且还能加快蜂群的收敛速度, 获得全局最优解.实验结果表明本文提出的算法敏感性、特异性、阳性预测值和准确率都取得了较好的结果. 但本文也有局限性眼底硬性渗出物区域的提取主要以视盘消除为前提, 如何更好定位视盘是关键[28], 这个可以作为今后研究的重点方向之一.
