基于关系型数据库的网络流数据预处理方法
2022-06-28年爱华
年爱华
(兰州现代职业学院 信息工程学院, 甘肃 兰州 730300)
为规范网络管理工作,保障网络安全,技术人员需对网络设备进行分类处理,而网络流数据预处理效果,直接关系网络设备分类成果。常规网络流数据预处理方法以编程语言为基础,编写开发工具类软件,局限性较大,不能推广普及。就此,关于新型网络流数据预处理方法的研究具有鲜明现实意义。
一、现有网络流数据预处理方法
现有网络流数据预处理方法包括以下三种,处理原理不同,处理效果不同。
(一)基于端口的预处理方法
该方法原理如下:对比分析互联网数字分配机构公布的端口号和流量包头端口号,分析流量数据的应用类型归属状况。例如,DNS域名解析服务的流量数据端口号为53;部署HTTP协议的网络应用流量数据端口号为80。同时,有研究学者结合端口的固定性特征,提出不同预处理方法。如根据端口号处理UDP流量,准确分类应用类型;根据端口连接形式和并发连接数量,进行应用流量分类。在新时期背景下,网络应用数量逐渐增多,仅根据端口号难以准确分类,特别是P2P应用大都将固定端口更换为动态端口,甚至引进端口伪装技术,降低基于端口的预处理方法应用效果[1]。
(二)基于深层包检测的预处理方法
该方法原理如下:根据数据包的所有载荷内容,如特定字符或特定模式等,识别分类流量。在实际应用中,只需处理网络流的数据包即可实施识别分类,并将识别分类提前至流量产生环节。有研究学者以深层包检测为基础,应用随机森林算法,实施网络流数据预处理;有研究学者以深层包检测为基础,研发网络管理、分类系统。但在实践中,由于深层包检测需逐一分析载荷内容,工作量较大,如数据包的载荷内容多,识别分类时间较长,预处理效率较低。同时,目前大众网络安全意识增强,加密技术得到普遍应用,深层包检测的实施面临较大阻碍[2]。
(三)基于统计的预处理方法
该方法原理如下:根据不同网络流数据的特征差异,进行识别与分类,以机器学习或神经网络等技术为主,选择合适的算法与模型,学习海量网络流数据的特征,进而网络流数据预处理目标。技术人员可根据不同网络流数据预处理要求,开发不同功能的机器学习分类器,实现流分类处理;也可开发卷积和循环神经网络模型,从统计角度进行网络流数据处理。在基于统计的预处理方法中,需以网络数据包头信息为基础,包括网络协议等内容,具有获取便利、处理效率高、分类准确等优势。但其优势发挥受机器学习、神经网络模型及相关参数影响,模型训练所用的流量统计特征也会影响分类效果[3]。就此,在基于统计的网络流数据预处理方法应用中,技术人员应根据网络流数据预处理的具体应用场景,如恶意流数据预处理等,遵循细粒度原则进行流量特征提取,选择最具区分度的特征。
二、基于关系型数据库的网络流数据预处理
通过上述网络流数据预处理方法分析可知,基于统计的预处理方法优势更为显著。本文提出基于关系型数据库的网络流数据预处理方法,利用关系型数据库的SQL在统计方面的优势,有效提取流量统计特征,进一步优化基于统计的网络流数据预处理方法,推广普及。
(一)关系型数据库的相关概念
在关系型数据库应用中,涉及如下概念:
包,即网络消息中最小单位的数据块,用如下公式表示:
P={P1,P2,…Pi,…}
Pi={xi1,xi2,…xij,…}
在式中,P是指网络流数据中全部包的集合;Pi是指第i个包记录;xij是指第i个包记录的第j个属性。这里的属性包括包的长度、数据包的收发时间、数据包传输应用的传输协议等。
流,即相同五元组的组的所有包,用如下公式表示:
F={F1|t1,F2|t2,…Fk|tk,…}
Fk={P1|∈Fk,P2|∈Fk,…Pn|∈Fk,…}
Pn=(xn1,xn2,…,xij,…);P1.xg=P2.xg=…=Pn.xg=…
式中,F是指网络流数据中心的全部流的集合;Fk是指一个流的全部包的集合;tk是指第k个流中第一个包的开始时间;Pn是指Fk内的包;Pn.xg是指Pn的五元组。
会话,即双向流的所有包,发送和接收的两个流视为一个会话[4]。
(二)网络流数据预处理流程
在基于关系型数据库的网络流数据预处理中,具体流程如下:一是原始网络流数据的采集,要求数据为二进制文件,存储于硬盘空间内;二是数据包提取,选择流量分析工具实施提取操作;三是记录转储,将提取的文本内容以CSV文件格式存储,导入至数据库表;四是应用SQL进行网络流数据统计特征提取与统计工作,导出网络流数据预处理结果。
上述预处理过程的思路在于通过规则抽象处理统计特征,并将其和SQL语言实施细粒度绑定,构建统计特征提取库,在网络流量分类需求多样化发展趋势下,统计特征提取库内容不断增多,技术人员可选择相应模块的方法,进行流量特征提取,为基于统计的网络流数据预处理提供保障。由此可见,在网络流数据预处理过程中,特征提取库的构建与应用为关键要点,应遵循图1的流程。
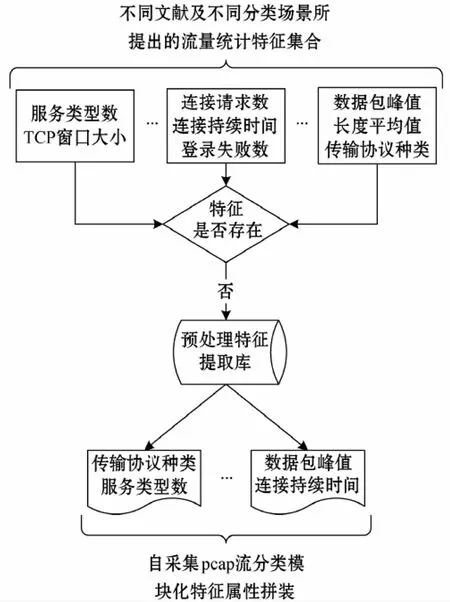
图1 特征提取库的构建与应用流程要点
结合上图,在统计特征提取时,应结合网络流量的五元组属性,整合为不同类型的流,根据网络流数据的分类场景要求,进一步细分不同类型的流,实施分段统计,完成流量统计特征的获取。例如,在以固定包数为统计特征的预处理中,只需提取每个类型的流的前N个数据包,根据固定时间段,将每个类型的流中的数据包按照时间戳顺序实施归并处理。在此基础上,不同统计特征规则抽象,在特征提取库中对应的SQL代码块不同。例如,在汇总五元组的规格抽象处理中,需应用Group by srcIP,srcPort,dstIP,dstPort及protocal代码块。
(三)网络流数据预处理步骤
基于上述流程思路,技术人员应按照规范步骤进行网络流数据预处理,保障各个环节的文件格式与内容符合处理要求,提高网络流数据预处理可靠性。细化来说,网络流数据预处理步骤如下:
将目标网络的顶层交换机全部网络接口实施端口镜像处理,使接口数据转移至独立汇聚端口处,可由该端口将网络流数据传输至数据采集主机中。为保障数据采集稳定性,在主机中配置Wireshark软件,负责流量采集工作。在软件中设置pcap文件的存储方式和路径,与汇聚端口网卡连接,完成网络流数据的监听与采集。
利用tshark命令控制工具处理pcap文件,采集网络流数据中所需的属性值,如五元组、数据包的长度等,并将采集的属性值以CSV格式存储。按照相应的所属协议,Wireshark软件支持超过几十万的属性字段,可根据不同网络流分类场景需求,进行识别分类。
选择SQLyog或Navicat Premium两种工具,对CSV文件实施图形化界面操作,将其导入到MySQL数据中,完成后每个文件可构建一个数据库表。
利用MySQL数据库的查询分析器工具和SQL语言,在构建的数据库表中,查询统计所需的流统计特征值记录,结合网络设备或网络应用的类型,在特征值记录中添加训练标签列。通过SQL语言的各类函数,如count、max等,高效处理统计信息值。如果数据库表的统计量较大,可选择UNION语句。
应用Navicat Premium的导出功能,将查询分析结果以CSV格式导出,作为神经网络模型的训练数据库,完成网络流数据的预处理。
在上述过程中,如构建的数据库表字段较少,可重新进行第二步,增加网络流数据属性值的提取数量,必要时可全部提取常用的属性值或有价值的属性值,在后续分析中选择性应用,避免返工,提高效率,降低成本。如获得的最终结果不满足神经网络模型的训练要求,可重新进行第四步,选择不同的统计特征组合,提取新的统计特征[5]。
三、基于关系型数据库的网络流数据预处理效果
在明确基于关系型数据库的网络流数据预处理方法后,开展实践探究,验证该方法的可行性与使用效果。以某高校的数据中心为研究对象,采集其监控安防系统的网络流数据,实施预处理实验。
(一)数据样本
在该高校的监控安防系统中,与各个区域的集中器进行数据通信,集中器负责采集区域的温湿度、火焰及烟雾等传感器设备信心,与传感器间的连接使用485接口,与监控安防系统主机的连接使用RJ45接口。在实际运行中,监控安防系统的流量设备会遵循采集命令,在规定的时间点向服务器传输状态数据。就此,在实验中,于监控安全系统的后台服务器部署Wireshark软件,实施网络流数据的采集。结合该高校计算机系统特点,选用win64-1.10.4版本的软件,将采集的pcap文件存储于D盘,存储路径如下:D:wiresharkpackageCapture。如pcap文件存储空间超过50MB,需对文件实施拆分处理,并设置自动命名规则,具体如下:“rawdatas_{序号}_{年月日时分秒(采集开始时间)}”。
(二)特征提取
在统计特征提取中,选择网络上公开的pcap文件集,构建统计特征提取库,包括7个类别的21类设备的流量数据。下载2019-11-21到2019-12-11共20天的pcap文件,根据下载日期命名文件。应用tahrk工具逐一提取20个文件的属性值,以CSV格式存储属性值文件;应用SQLyog工具将CSV文件导入MySQL8.0.16数据库中。根据网络流数据分类需求,根据所属类别对数据包实施排序,每个类别的数据包排序由所属设备决定。在完成排序后,按照5min的时间间隔,汇总每个设备的数据包,计算每个时间间隔内数据包的数量、数据包的长度平均值、数据包长度的峰值;最后,按照数据包的传输协议,将每个汇总属性值拆分为用户数据和控制数据,根据数据类型设置相应的训练标签值。使用UNION语句进行统计特征提取,实施SQL查询,最终将结果导出为CSV格式的文件,开展神经网络模型训练。在预处理完成后,可获得流量特征和业务特征两种属性的网络流数据。
(三)对比分析
为验证基于关系型数据库的网络流数据预处理方法,本文将其与常规流量统计工具和常规统计工具进行对比分析。其中,常规流量统计工具选用SDN-pcap-Simulator,常规统计工具选用Excel。在预处理中,对比三种方法的需求通用性、处理效率、智能化水平及可拓展性,对比结果显示,基于关系型数据库的网络流数据预处理方法在四方面均显著优于另两种方法。同时,应用Excel和SQL语句两种工具对下载的2019-11-21到2019-12-11共20天pcap文件实施数据统计分析,该文件共包括956 151条数据包。处理结果显示,Excel的数据加载用时62s,统计执行用时1.5s,总用时63.5s;SQL语句数据加载用时7s,统计执行用时5s,总用时12s,显著快于Excel。可见,基于关系型数据库的网络流数据预处理方法优势显著,可推广普及。
四、结语
综上所述,技术人员可应用基于统计的网络流数据预处理方法,引入关系型数据库,按照网络流数据采集、网络流数据属性提取、数据库表构建、流统计特征提取与分析,完成网络流数据预处理。该方法具有需求通用性高、处理效率高、智能化与可拓展等优势,可在网络流数据预处理中推广应用。
