神经元活性引导机器人脱困的全覆盖路径规划
2022-06-28江静岚
江静岚
(柳州铁道职业技术学院,广西 柳州 545616)
1 引言
移动机器人导航包括地图创建、路径规划与跟踪控制等方面,路径规划分为点对点规划和全覆盖规划两类。全覆盖机器人广泛应用于除草、扫地、喷涂等行业和领域,要求对工作区域遍历的同时重复覆盖率较低[1]。研究机器人全区域覆盖方法,对提高机器人工作效率和降低机器人能耗意义明显。
机器人工作区域全覆盖方法可以分为三类,分别为传统覆盖方法、基于区域分解覆盖方法、基于栅格地图覆盖方法。传统覆盖方法包括模板法和内螺旋法,模板法根据环境特征预先设定运动模板,机器人进行环境匹配后根据此模板运动[2],此方法能够完成遍历,但是要求环境不能发生任何变化,应用范围极小。内螺旋法是一种沿边法[3],当遇到已覆盖区域或边界时则内旋一个单位继续工作,此方法对环境精度要求极高,且难以实现完全覆盖。基于区域分解的覆盖方法是根据障碍物形状将工作区域进行划分,子工作区域内没有障碍物,而后对设定子区域遍历法、子区域遍历顺序等,包括牛耕分解法[4]、矩形分解法[5]等。基于栅格地图覆盖方法包括生成树法、生物激励神经网络法等,生成树法[6]将每四个栅格合成一个单元,通过全部单元连接实现遍历,此方法需要极大的存储空间且路径转弯较多;生物激励神经网络算法[7]中神经元使用分流方程与相邻神经元交流,根据神经元活性值选择下一栅格,此方法计算简单,无需学习过程,其最大缺陷是存在“死区”问题。
这里为了解决生物激励神经网络算法存在的死区问题,使机器人高效地完成工作区域全覆盖,提出了脱困点搜索和脱困点路径规划方法。制定了元胞自动机演化规则,搜索到了最佳脱困点;使用神经元活性值引导RRT算法,使随机树扩展具有方向性,完成了脱困路径规划。带有脱困机制的生物激励神经网络算法能够有效完成工作区域全覆盖,是一种有效的遍历路径规划方法。
2 生物激励神经网络全覆盖方法
2.1 栅格环境模型
使用生物激励神经网络算法进行全区域覆盖规划时,首先需要建立工作区域的栅格模型。使用方形栅格对工作区域进行分割,当栅格内不存在障碍物时称为自由栅格,当栅格内存在障碍物时称为障碍物栅格,另外自由栅格需要区分已覆盖栅格和未覆盖栅格。通过对栅格赋不同属性值,使机器人能够识别以上3类栅格,对障碍物栅格赋值为“-1”,对已覆盖栅格赋值为“0”,对未覆盖栅格赋值为“1”。机器人某次规划过程,如图1所示。其对应点阵为:
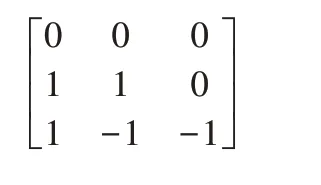
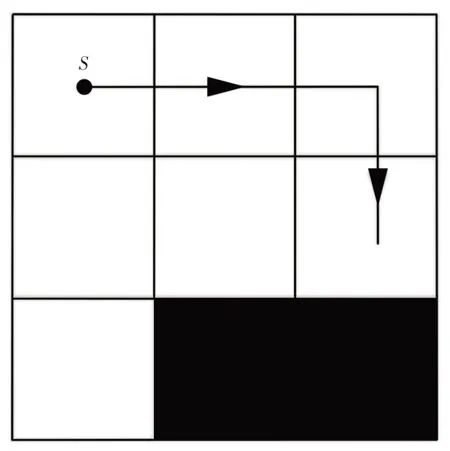
图1 机器人某次规划过程Fig.1 A Planning Process of Robot
栅格法的编码方法包括直角坐标法和顺序编码法,相互转换关系可参考文献[8],此内容非本文重点,这里不再赘述。另外,方形栅格法包括“四叉树法”和“八叉树法”,本文使用的是“八叉树法”。
2.2 生物激励神经网络
使用栅格法将工作区域离散化,每个栅格对应一个神经元,栅格属性值即为神经元初始活性值。二维的生物激励神经网络模型,如图2所示。每个神经元与周围相邻神经元相互连接,实现神经元活性相互影响与传递。

图2 二维生物激励神经网络模型Fig.2 2-Dimention Biologically Inspired Neural Network Model
神经元活性值由分流方程描述外部激励及相互间作用关系[9],为:
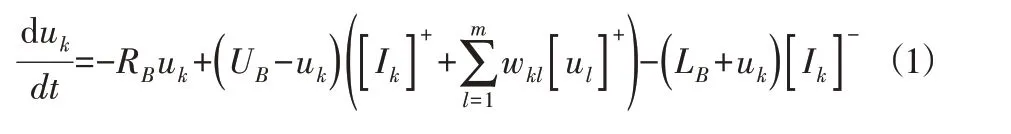
式中:uk—第k个神经元活性值;RB—活性值衰减速率,是一个正值常数;UB、LB—活性值上下限;m—神经网络中神经元k的相邻栅格数;wkl—神经元k与神经元l的权值,权值矩阵具有对称性,即wkl=wlk;函数外部输入信号,当Ik>0时Ik为激励信号,当Ik<0时Ik为抑制信号。根据不同栅格类型,为Ik设置不同值,即:

式中:EB≫UB—外部输入值。
神经元k与神经元l之间的连接权值wkl定义为两者欧式距离的递减函数,这里设置为:
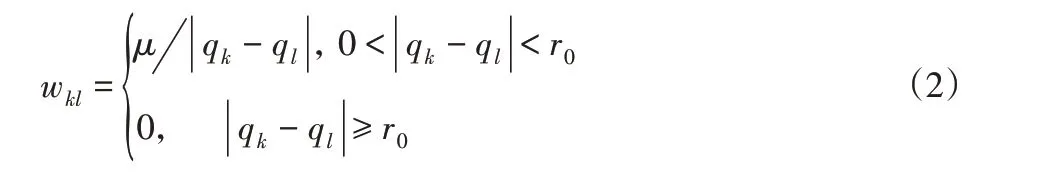
式中:μ—一个常数,取值范围为0 <μ<1。
分析式(1)可知,对于未覆盖区域,正的活性值可以通过分流方程不断扩散,在全局范围内对机器人产生吸力;而对于障碍物区域,负的活性值不参与分流方程,只受外部输入的作用,因此对机器人没有任何吸引作用,达到避障目的。
机器人转弯不仅降低工作效率,同时增加了磨损降低机器人使用寿命。为了减少机器人转弯次数,将转弯角度加入到活性值中,作为一项选择指标,即:

式中:Pathk—神经元k选择的路径;η—方向权值,(1)调节活性值与转向角处于同一数量级,(2)调节转向约束重要性;Δθl—选择相邻神经元l的转向角,由式(3)可知转向角越大则被选概率越小,是为了保证机器人直线行驶,提高行走效率;(xl,yl)—下一时刻神经元l的位置,(xc,yc)—机器人当前时刻神经元位置,(xp,yp)—上一时刻神经元位置。
2.3 生物激励神经网络全覆盖原理及缺陷分析
根据前文生物激励神经网络工作原理,制定全覆盖路径规划过程为:首先根据栅格法建立工作环境模型,为每个神经元赋初始活性值。从起始点开始规划,每走过一个栅格将其属性活性值强制设置为0,而后依据式(1)进行活性值更新。路径规划过程中,障碍物神经元不进行活性值更新,只对自由神经元活性值更新。机器人每前进一步,则按照式(1)对自由神经元进行一次活性值更新,按照式(3)选择相邻栅格中最大值作为下一栅格,直至结束。对于某一工作环境,按照生物激励神经网络全覆盖规划方法,得到的覆盖结果,如图3(a)所示,此时神经元活性值,如图3(b)所示。
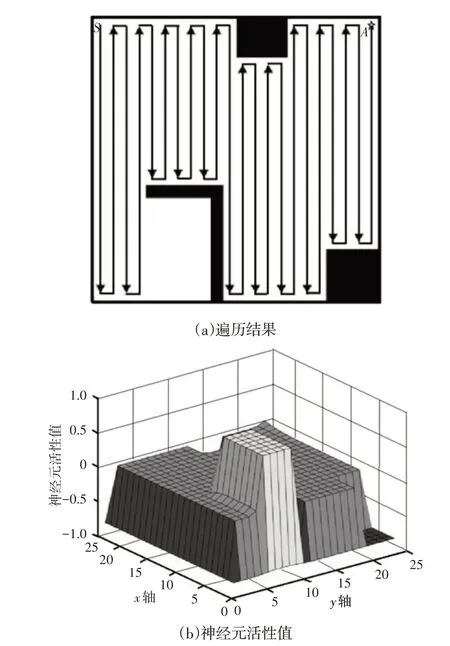
图3 生物激励神经网络规划结果Fig.3 Planning Resultant of Biologically Inspired Neural Network
图3(a)中S点为路径起始点,A点为终止点。从路径规划结果看,生物激励神经网络算法陷入了“死区”问题,死区问题是指机器人周围栅格不存在未覆盖栅格,但是在整个区域中仍存在未覆盖区域。图3(b)中未覆盖区域神经元活性值较高,对机器人具有较强的吸引作用,但是机器人陷入“死区”无法完成遍历。
3 脱困机制设计
为了解决生物激励神经网络存在的“死区”问题,本节设计了机器人脱困机制,包括基于元胞自动机的脱困点搜索和改进RRT算法的脱困路径规划等两方面内容。
3.1 脱困点搜索
元胞自动机是模拟生物自复制现象提出的[10],元胞自动机系统定义在一个由有限状态的元胞组成的离散空间中,给定元胞初始条件和演化规则,元胞就能够根据演化规则自动迭代演化。元胞系统符号表达式为:

式中:M—元胞系统;Ld—元胞空间,d—空间维度;S—元胞状态;N ={s1,s2,…,sn} —邻居元胞集合;n—邻居元胞数量;f—演化规则。
这里机器人工作空间为二维,因此元胞空间维度也为二维,即d=2。元胞状态S取有限个离散状态,如{1 ,2,…,ϑ} 。前文中指出,使用“八叉树”方形栅格,每个元胞具有8个邻居元胞,此时n=8。演化规则是元胞自动机系统的核心内容,是所有元胞的状态转移函数,直接决定了元胞下一时刻状态。
首先为元胞自动机配置空间,也即元胞状态初始化。在此需要强调的是,元胞位置与栅格位置(或神经元位置)一一对应,但是元胞状态值与神经元活性值是没有任何关联的,存在于不同的知识系统中。根据不用的栅格类型,元胞初始状态设置为:

在介绍元胞演化规则前,首先对中心元胞和邻居元胞进行明确,按照栅格“八叉树”法,处于中心位置的元胞为中心元胞,其周围的8个元胞为邻居元胞。根据搜索脱困点这一目标,制定元胞演化规则为:(1)首先查找状态值为1的元胞,状态更新从陷入死区位置元胞开始;(2)以死区元胞为中心元胞,将其邻居元胞中状态为0的元胞状态更新为2;(3)以状态值为2的元胞为中心元胞,将其邻居元胞中状态为0的元胞状态更新为3;(4)而后分别以状态为3的元胞为中心元胞、状态为4的元胞为中心元胞,对其邻居元胞进行更新,直至所有0元胞更新完毕。
从以上演化规则可以得到三点结论:(1)障碍物元胞的状态值不更新;(2)障碍物元胞不作为中心元胞;(3)每个自由元胞只有一次状态更新机会。按照以上演化规则,图3(a)所示环境的元胞初始状态值及更新状态值,如图4所示。
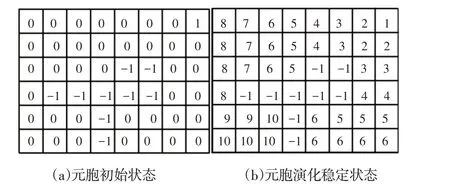
图4 元胞自动机状态演化Fig.4 State Evolution of Cellular Automata
图中状态值为1的元胞是机器人陷入死区的位置,彩色数字区域为机器人未覆盖区域,未覆盖区域中状态最小的元胞位置即为机器人脱困点,也即图4(b)中彩色9处的元胞位置。至此脱困点被找到,下节给出从死区位置到脱困点的路径规划方法。
3.2 改进RRT算法的脱困路径规划
快速扩展随机树(Rapidly-Exploring Random Tree,RRT)是一种在全局空间中随机采样、通过节点不断扩展而连接起始点与目标点的路径规划方法[11]。在二维规划区域S⊂R2中,障碍物区域记为Sobs,自由区域记为Sfree,路径规划起点记为Pstart,目标点记为Pend。RRT算法以起始点Pstart为根节点,在规划区域内使用随机采样法得到采样点Prand,使用树节点搜索的方法搜索到距离Prand最近的树节点Pnear,以Pnear为父节点向Prand方向扩展一个步长,得到新的树节点Pnew,对Pnew进行碰撞检测和机器人动力学约束检测,若Pnew未落在障碍物区域Sobs内,且满足机器人动力学约束,则Pnew扩展成功。重复上述步骤,直至目标点Pend成为树节点,或者与某一树节点距离小于一个步长,而后以Pend为起点,反向追溯父节点直至回到起始点Pstart,此时路径搜索完毕。
从上述RRT算法的原理可以看出,树节点扩展时在整个规划区域进行随机采样,这种盲目采样方式增加了大量无效采样点和树节点,极大地增加了规划时间、降低了规划效率。为了解决这一问题,这里提出了神经元活性引导的RRT脱困路径规划方法(RRT Guided by Neuronal Activity,RRTGNA)。在生物激励神经网络算法中,机器人陷入“死区问题”后,未覆盖区域神经元活性值较高,如图3(b)所示。较高地神经元活性值根据式(1)向全域神经元扩散,在全域范围内对机器人具有吸引作用,此时规划区域内必然存在一条或若干条活性值单调递减的路线,且此路线必然连接脱困点和死区位置。根据这一结论,可以使用神经元活性值对树节点扩展进行引导。
在传统RRT算法中,新节点Pnew只进行碰撞约束检验和机器人动力学约束检验,当满足约束时扩展成功,不满足约束时则重新采样。而在RRTGNA算法中,新节点Pnew首先要进行神经元活性值检验,新节点Pnew活性值记为Anew,对应的父节点Pnear活性值记为Anear,只有当Anew≥Anear时才满足神经元活性值扩展约束,而后进行碰撞等检验。这种使用神经元活性值对树节点扩展进行引导的方式,避免了树节点扩展的随机性和盲目性,可以极大地提高随机树的扩展效率,减少随机树扩展点和路径规划时间。在此需要说明的是,任意节点处的活性值为此节点所在神经元(或栅格)的活性值。
3.3 具有脱困机制的全覆盖规划方法
综合第2节和第3节内容,给出具有脱困机制的全覆盖路径规划方法为:
(1)使用生物激励神经网络方法进行全覆盖路径规划,若不存在死区问题,则算法结束,给出全覆盖路径;若存在死区问题,则进入(2);
(2)调用脱困机制,首先使用元胞自动机搜索脱困点,而后使用神经元活性值引导的RRT算法进行脱困路径规划;
(3)机器人按照(2)步路径行驶到脱困点,而后在未覆盖区域使用生物激励神经网络进行路径规划,完毕后判断是否仍存在未覆盖区域,若不存在则算法结束;若存在则进入(2),直至所有区域完成遍历,算法结束。
4 仿真验证与分析
以图3(a)所示工作环境为规划区域,使用栅格法将其分割为25×25个栅格,每个栅格对应一个神经元。按照栅格类型为其赋不同属性值,同时初始化神经元活性值。生物激励神经网络算法参数设置为:衰减速率RB=20,活性值上限UB=1,活性值下限LB=-1,外部输入值EB=100,方向权值η=0.03,距离常数μ=0.8。使用生物激励神经网络算法以左上角S点为起点进行遍历路径规划,结果如图3(a)所示。从图中可以看出,机器人陷入了“死区”问题,A点为“死区位置”。
按照3.3节规划流程,此时调用脱困机制,首先使用元胞自动机搜索脱困点,从陷入死区位置的元胞开始演化,得到元胞演化稳定状态,如图4(b)所示。未覆盖区域(彩色数字区域)中状态值最小的元胞位置为脱困点,即彩色数字“9”对应的元胞位置。
而后进行脱困路径规划,为了形成对比效果,分别使用传统RRT算法和神经元活性值引导的RRT算法进行规划,每种算法各自独立规划50次,从规划结果中随机抽取一组规划结果进行展示结果,如图5所示。
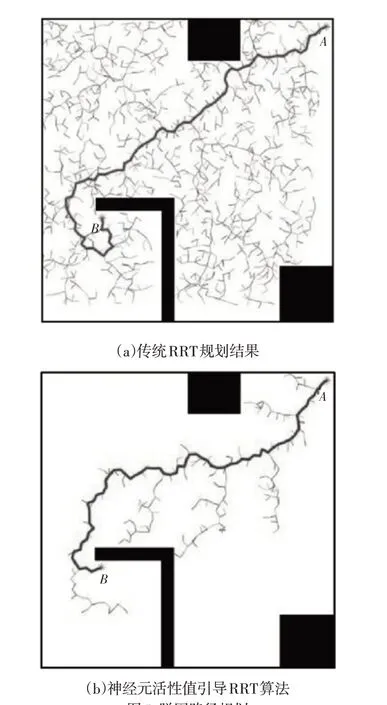
图5 脱困路径规划Fig.5 Escape Path Planning
图5中隐藏了机器人已行驶路线,只给出了规划路径和采样点。图中A点为“死区位置”,B点为元胞自动机确定的脱困点。从图中可以看出,传统RRT算法为全局采样,采样具有盲目性和随机性。而改进RRT算法在神经元活性值的引导作用下,采样点的采样和随机树的扩展向神经元活性值较高的方向前进,具有较强的方向性,避免了全局范围内的采样和扩展,极大地减少了无效节点数量。统计传统RRT算法和神经元活性值引导RRT算法(RRTGNA)50次运行结果的平均时间、路径平均长度、扩展节点数,如表1所示。
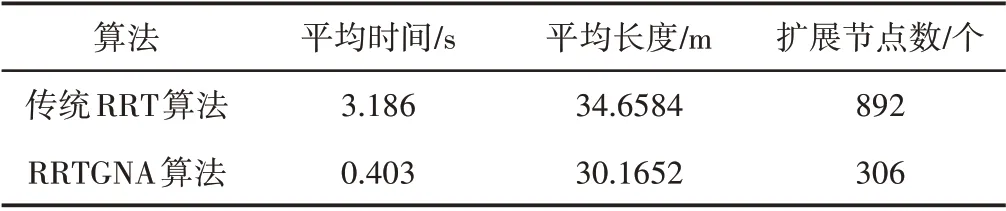
表1 脱困路径规划结果Tab.1 Escape Path Planning Result
从表中可以看出,RRTGNA算法平均运行时间为0.403s,比传统RRT算法小了约一个数量级;RRTGNA 算法规划的脱困路径平均长度比传统RRT算法减少了12.96%;RRTGNA算法的扩展节点数为306个,比传统RRT算法少了约两倍。以上数据说明了RRTGNA 算法在采样和扩展时具有极强的方向性,沿着神经元活性提高的方向扩展,极大地减少了扩展节点数,降低了算法运行的时间消耗,同时神经元的引导作用使路径扩展目的性强,起到了降低路径长度的效果。
机器人沿着脱困路径到达脱困点,而后使用生物激励神经网络对未覆盖区域继续进行遍历规划结果,如图6所示。
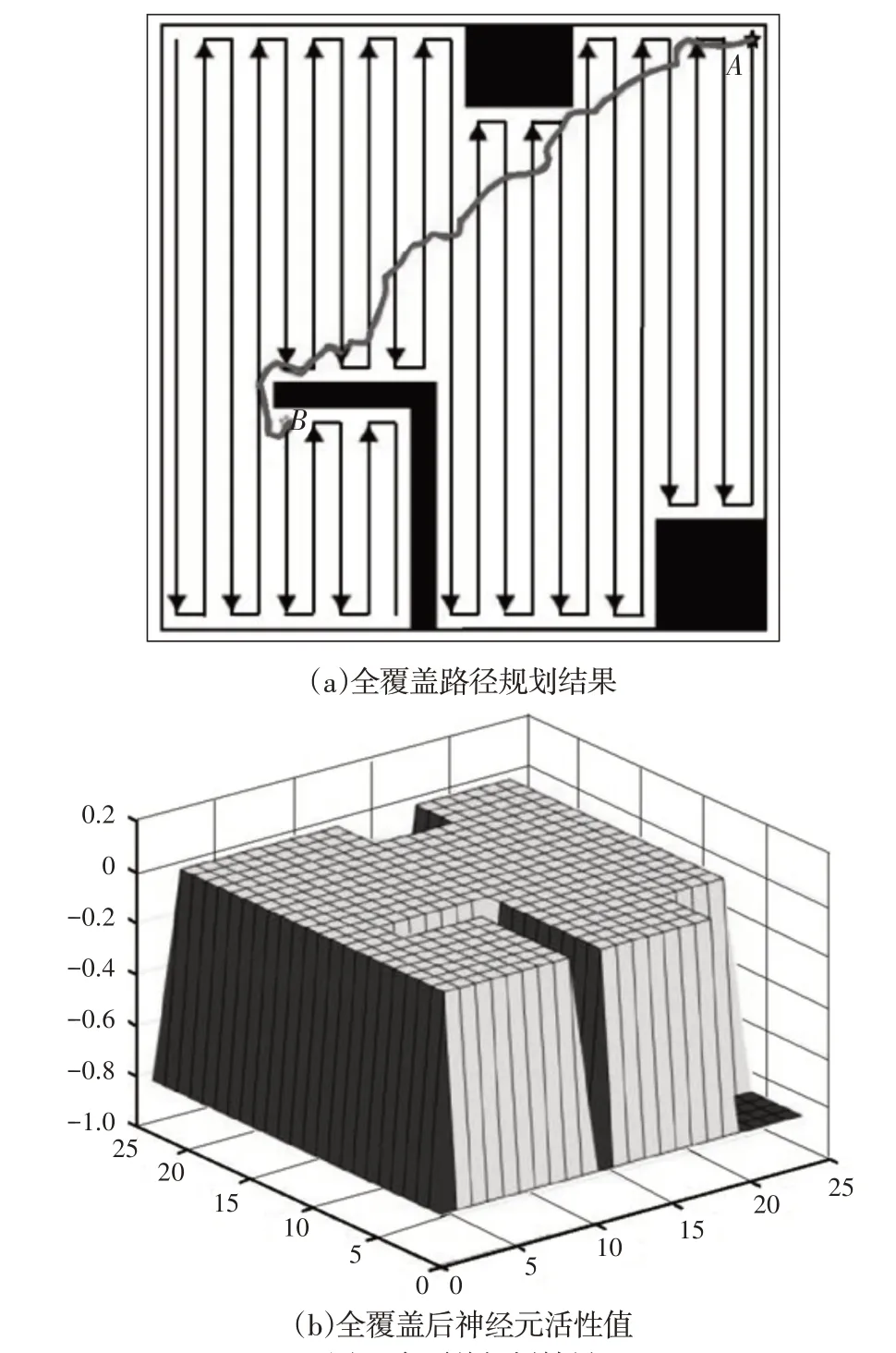
图6 全覆盖规划结果Fig.6 Complete Planning Result
从图中可以看出,机器人沿脱困路径摆脱死区后到达脱困点,以脱困点为起点使用生物激励神经网络算法继续进行遍历路径规划,完成了对整个工作区域的遍历。图6(b)中除障碍物神经元外,其余神经元活性值为0,也表示机器人对整个区域完成了遍历。由此可以看出,具有脱困机制的生物激励神经网络算法能够有效遍历整个工作区域,当陷入“死区问题”时,调用脱困机制能够高效地摆脱死区而完成所有区域的遍历。
5 结论
这里研究了机器人对工作区域的遍历路径规划问题,以生物激励神经网络算法为基础,当机器人陷入死区后调用脱困机制,可以高效脱困并完成区域遍历。仿真验证,得出了以下结论:(1)基于元胞自动机的脱困点搜索方法可以有效找到最佳脱困点;(2)神经元活性值引导的RRT算法在节点扩展时具有较强的方向性,减少了扩展节点和运行时间,降低了脱困路径长度;(3)带脱困机制的生物激励神经网络算法可以完成区域遍历,是一种有效的区域遍历方法。
