采用新型遗传算法的永磁同步电机参数辨识
2022-06-28李仲树
刘 波,王 琳,李仲树,韩 辉,赵 奎,杨 唯
(1.江苏长江智能制造研究院有限责任公司,江苏常州 213000;2.北京机械工业自动化研究所有限公司,北京 100120)
0 引言
近年来,随着先进制造业的发展,智能机器人在现代 工业中得到了广泛应用,不仅可以节省成本,而且可以提高生产效率。伺服电动机是影响机器人工作性能的主要因素[1]。内置式永磁同步电机(Interior Permanent Magnet Synchronous Motor,IPMSM)具有功率密度高、效率高、体积小等优点,因此广泛应用于工业机器人领域[2-3]。在伺服控制系统中,IPMSM 参数的变化会改变控制对象模型,从而影响整个控制系统的稳定性。为解决此问题,当电机实时工作条件发生变化时,需要在线识别电机参数,以实现电机的稳定运行[4-5]。
对于IPMSM,电机参数变化主要是由高温与磁饱和引起的,其中磁饱和与交叉饱和对电感参数有非常显著的影响。目前,参数辨识方法主要有状态观察器[6-7]、模型参考自适应系统(Model Reference Adaptive System,MRAS)[8-9]、递归最小二乘(Recursive Least-Squares,RLS)[10-11]、扩展Kalman 滤波器(Extended Kalman Filter,EKF)[12-13]和智能算法[13-14]等。文献[6]通过引入一个辅助动力学模型以同时观察电机状态和参数,得到了扩展的数学模型,但其很容易受到外部条件变化的影响;文献[8]通过分析传统的MRAS,提出一种基于级联MRAS 的电机参数在线识别方法,但缺点是难以同时准确地观察到绕组电阻、电感和永磁磁通;文献[10]将基于RLS 的参数识别与无传感器控制相结合,RLS 具有计算简单、易于理解与应用等优点,但由于RLS 的参数是线性的,因此RLS 的解精度很低;文献[12]提出两种基于IPMSM 识别方案的卡尔曼滤波器,一种使用扩展卡尔曼滤波器,另一种使用双扩展卡尔曼滤波器,结果表明,该识别方法具有鲁棒性,但对噪声过于敏感,不宜广泛应用。
随着计算机技术与智能控制技术的发展,具有强大非线性系统处理能力和优化能力的人工智能算法在IPMSM参数辨识领域有了更广阔的应用前景。利用智能算法对IPMSM 参数进行辨识时,将参数辨识问题转化为寻找最优解问题,常用算法包括神经网络算法(Neural Network Algo⁃rithm,NNA)[14-15]、粒子群优化算法(Particle Swarm Optimi⁃zation Algorithm,PSO)[16-17]和遗传算法(Genetic Algo⁃rithm,GA)[18-20]等。文献[14]将神经网络算法用于高速永磁同步电机参数辨识,虽然NNA 在参数辨识中可获得更准确的结果,但通常需要训练大量数据样本,并进行及时的信息调整。文献[16]提出一种具有学习策略的动态PSO 方法用于永磁同步电机关键参数辨识,并且考虑了电压源逆变器的非线性特性,但PSO 算法很容易陷入局部最优解。相比之下,GA 具有很强的全局搜索能力及更快的收敛速度,因此被广泛应用于IPMSM 参数识别中。但众所周知,GA 的局部搜索能力较差。文献[18]提出一种新的混合遗传算法,该算法为梯度算法提供了迭代的起点,但需要几次迭代才能收敛。此外,文献[19]提出一种改进的遗传算法,将输入信号设置为可直接检测的变量,但该方法存在对检测手段要求高的缺陷。为减少GA 优化时间,文献[20]提出将遗传算法用于初始搜索,而将著名的Rosenbrock 旋转坐标法用于最后阶段的旋转坐标优化,但该方法增加了计算难度,使计算量加大。
因此,本文提出一种基于基于局部搜索混合遗传算法(Local search-based hybrid Genetic Algorithm,Is-hGA)的IPMSM 参数识别方法,该算法是爬山方法与遗传算法的结合。在阐述传统遗传算法原理的基础上,介绍了Is-hGS 原理,并将其用于IPMSM 参数识别,之后构建IPMSM 实验平台对该方法的有效性与正确性进行验证。
1 遗传算法原理
遗传算法(Genetic Algorithm,GA)于1960 年提出,是一种基于生物遗传机制的随机搜索算法,通过计算机模拟生物进化过程以及生物进化(选择、交叉和变异)现象,最终寻找出最优解。GA 算法的主要特点有:①个体适应性越强,生存几率越高;②通过对原始个体的操纵产生新个体。
遗传算法可理解为引入生物体适应机制,以解决更复杂模型的优化问题,从而获得最优解。遗传算法的实现可分为以下几个步骤:
(1)对实际问题的编码。实际值称为表型,编码值称为基因型,其作用是将问题的解空间映射到代码空间,以便代码可以被选择、交叉与变异。假设优化初始参数的起始和结束范围为k1~k2,采用二进制编码方法,编码位数为n。该参数有2n-1 个编码组合,编码精度为(k2-k1)/(2n-1)。
(2)生成初始的染色体集合。根据实际问题和初始条件,以二进制码形式生成一定数量个体的初始种群,种群中个体数量通常比编码组合2n-1 的数量小得多。如果种群个体数量等于编码组合2n-1 的数量,则此时的遗传算法可等价于网格搜索方法,并且随后的选择交叉突变操作将无效。
(3)对每条染色体的适应度评价。适应度函数主要由实际问题的客观函数决定。不同个体被替换为适应度评估函数,以获得个体的适应度值,这为以下的遗传操作打下了基础。
(4)遗传操作。遗传操作主要由3 部分组成:选择、交叉与变异。选拔方法通常包括轮盘赌、锦标赛和精英保留方法。
轮盘赌模型的特点是个体适应度越高,被绘制的概率则越高。该概率可表示为:
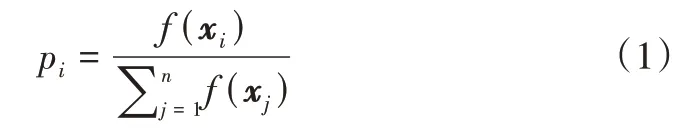
式中,f(x)是个体的适应度矩阵。
交叉操作是提高遗传编码最有效的操作。交叉操作包括简单的点交叉、多点交叉、统一交叉等。单点交叉如图1 所示,首先根据交叉概率pc确定交叉位置,并将母体一条染色体的前一部分与另一条染色体的后一部分形成一条子染色体。
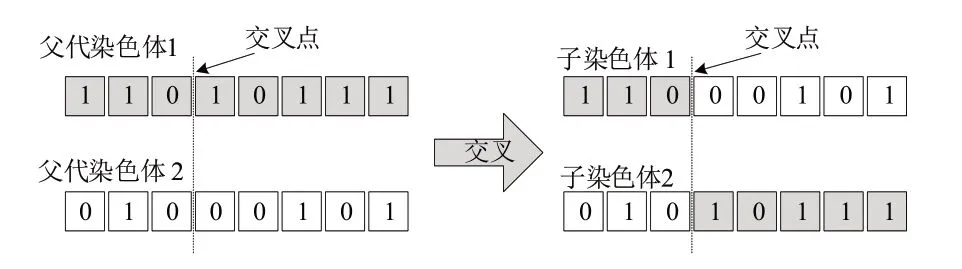
Fig.1 Simple point crossover schematic图1 单点交叉示意图
变异操作是根据特定的编码方法来确定的,如果使用一维二进制编码方法,如图2 所示,可根据一定的反转概率随机选择一位,并将该概率设置为突变概率pm。

Fig.2 Mutation operation of binary chromosome schematic图2 双染色体变异示意图
(5)解码操作。经过一定次数的迭代后,输出的最优个体仍处于编码状态,需要进行解码。以二进制编码为例,首先将最优个体的二进制码转换为十进制数c,染色体解码公式如下:

式中,σ是最优参数的真实值。
遗传算法流程如图3(a)所示。在对种群P(t)进行初始化后,执行编码操作,然后进行适应度计算,以确定是否达到最大迭代次数。如果没有,则执行选择、交叉与变异操作,更新种群并重复上述操作,直到达到最大迭代次数。之后执行解码操作,并输出最优参数。传统GA 算法可有效解决组合优化问题,是一种超启发式算法。但该算法也存在一些问题:①因为大量相同染色体的存在,目标函数计算时间会大幅增加;②当出现一个适合度值很高的染色体时,染色体基因会在种群中迅速传播,种群多样性则会减少;③参数设置比较复杂,对搜索能力影响很大。
为解决上述问题,提出一种基于局部搜索的混合遗传算法(Is-hGA)。在全局搜索中采用遗传算法,并通过爬山算法进行局部搜索来弥补遗传算法的不足。因此,可快速找出搜索空间的最优解。Is-hGA 算法流程如图3(b)所示。
爬山算法是在解空间中寻找最优的期望点,其特点是当前搜索方向会不断更改为更好的搜索方向。当改变任何搜索方向都不能提高适应度时,该点被称为局部最优解。遗传算法是一种并行多点搜索方法,可对种群进行交叉与变异组合操作。其可以尽快接近最优解,但局部搜索能力较差。因此,采用Is-hGA 算法对IPMSM 进行参数辨识时,种群全局搜索使用基于遗传算法的广度搜索,而局部搜索则采用爬山算法,从而极大地提高了最优解搜索能力。
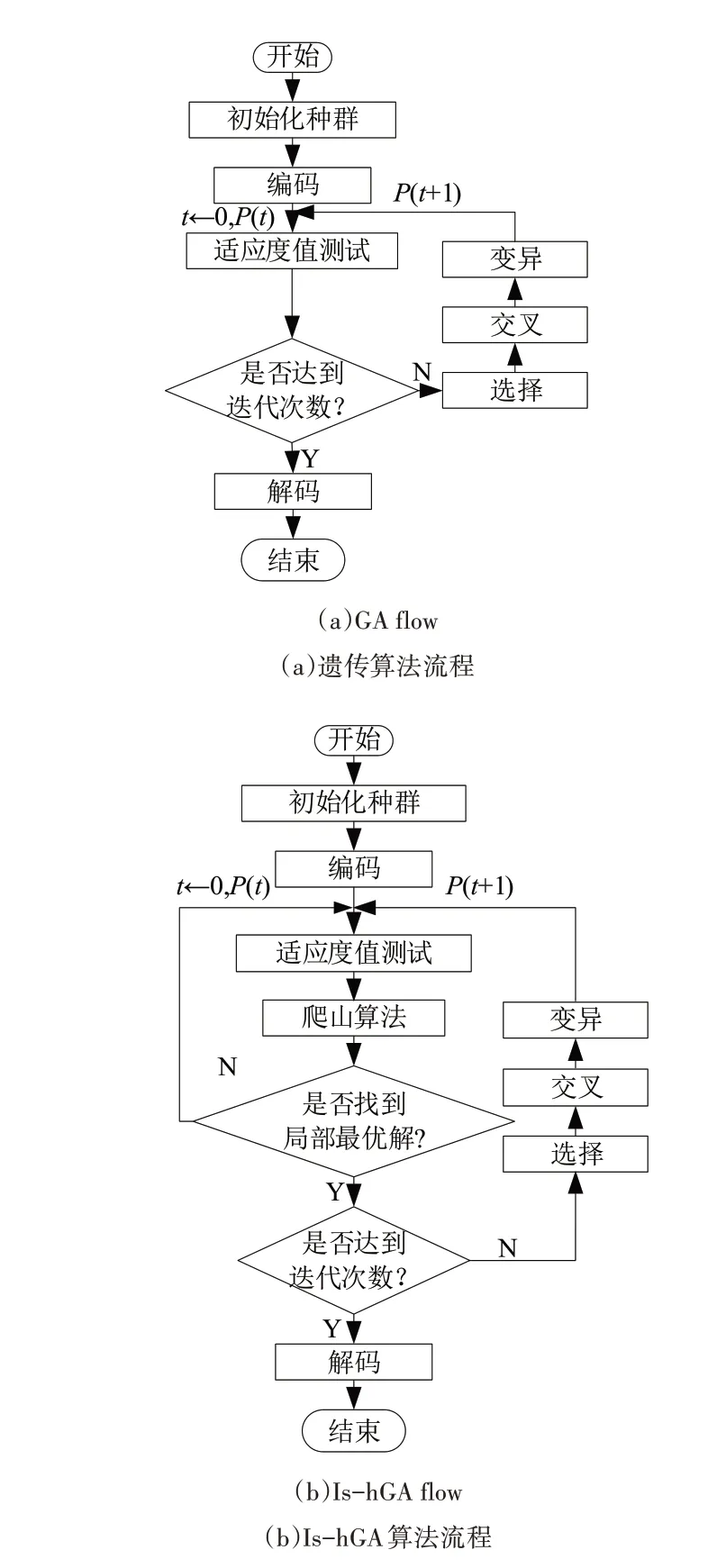
Fig.3 Algorithm flow图3 算法流程
2 Is-hGA在IPMSM 参数辨识中的应用
2.1 IPMSM 参数辨识原理
IPMSM 也被称为凸极永磁同步电动机,其特点是d 轴与q 轴电感不相等,d 轴与q 轴上的电压分量数学模型可表示为:
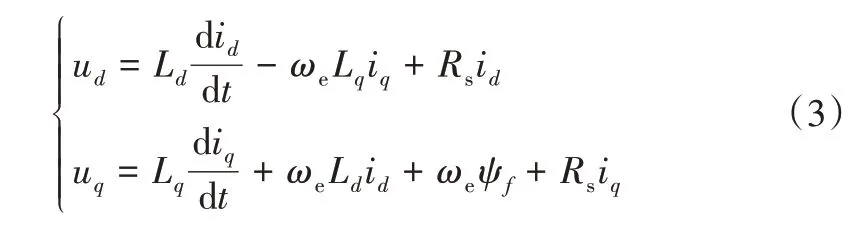
式中,ud、uq分别为定子电压在d轴、q轴上的分量,id、iq分别为定子电流在d 轴、q 轴上的分量,Ld、Lq分别为定子电感在d 轴、q 轴上的分量,Rs为定子电阻,ωe为电角速度,ψf为转子磁通。
假设所辨识系统的动态数学模型如下:
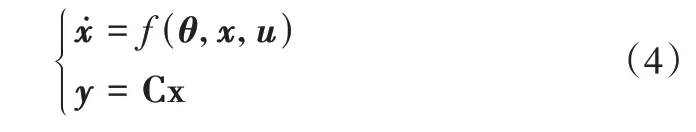
式中,x是状态变量,θ是需要辨识的参数,u是输入变量,C是常数矩阵。
上述系统的跟踪系统可表示为:

由于实际控制系统是一个离散控制系统,因此需要对电流方程进行离散化,具体公式为:

式中,Ts是两个离散点之间的时间间隔。建立如下等效跟踪功能:
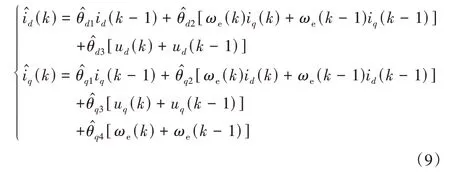
当预测电流与实际电流之间的偏差小于一定精度时,可认为此时参数的估计值接近实际值。电机参数R、Ld、Lq、ψf的辨识相当于参数θd1、θd2、θd3、θq1、θq2、θq3和θq4的辨识,可利用式(8)推导出电机参数。
2.2 Is-hGA在参数辨识中的应用
图4 给出了基于Is-hGA 算法的参数辨识系统框图。系统在恒温额定工况下工作,设置系统控制周期为0.1 ms,采样周期为0.001 ms。在一个控制周期中可采样100组参数,每组包括ud、uq、id、iq、ωe,并将这些参数输入IshGA 算法参数辨识模块。在200 次迭代之后,输出在控制周期中确定的参数。在实时控制系统中,通过在线参数辨识可提高控制精度,改善电机控制性能。
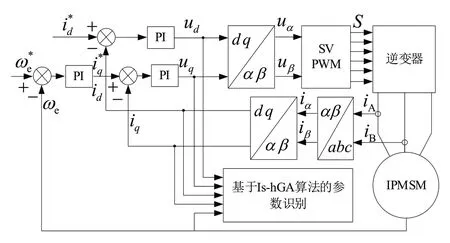
Fig.4 Parameter identification block diagram based on Is-hGA图4 基于Is-hGA算法的参数辨识系统框图
算法的目标函数为:
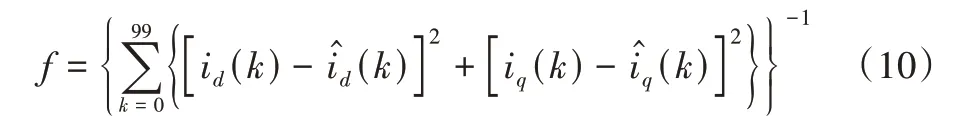
根据目标函数计算结果,可进行选择、交叉、变异和爬山算法运算。
3 仿真与实验
为验证本文方法的正确性和有效性,构建IPMSM 实验平台如图5所示,电机参数如表1所示。

Fig.5 Experimental platform图5 实验平台
传统GA 与Is-hGA 对比如图6 所示。其中,图6(a)为传统GA 与Is-hGA 算法运行速度对比。设置目标适应度为27,最高迭代次数为500,对两种算法分别执行100 个操作,纵坐标表示两种算法实现目标适应度所需的迭代次数。结果表明,传统遗传算法平均需要267 代算法才能实现目标适应度,而Is-hGA 算法只需59 代即可实现目标适应度,并且在100 个实验中,Is-hGA 算法都实现了目标精度。图6(b)为单一操作下的拟合精度比较。传统遗传算法的局部搜索能力较差,拟合度曲线始终处于跳跃状态。Is-hGA 算法采用爬山算法进行局部搜索,以确保每个部分都能得到区间的最优值,搜索效率较高。
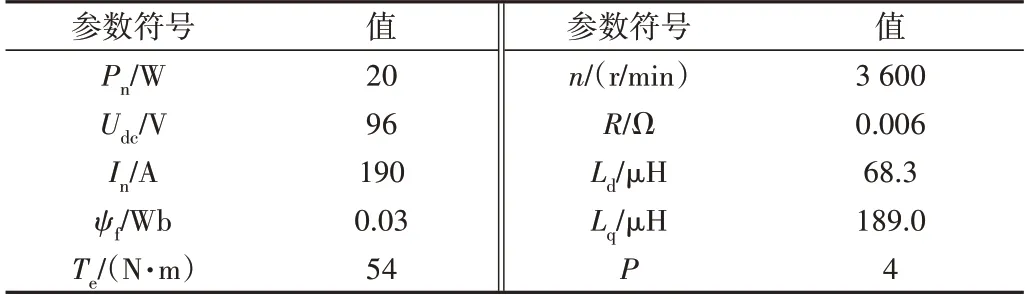
Table 1 Parameter of the motor表1 电机参数
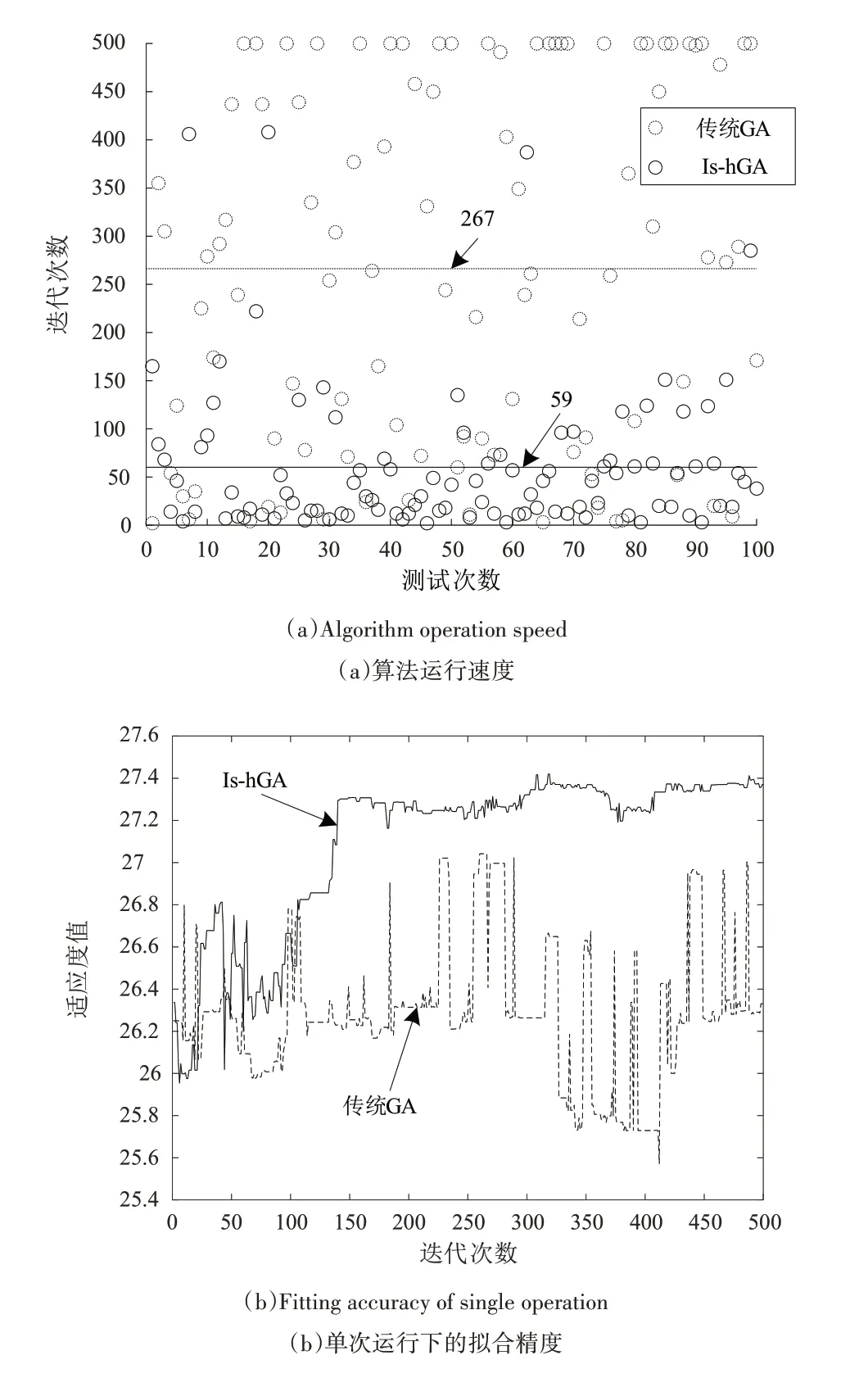
Fig.6 Comparative of traditional genetic algorithm and Is-hGA图6 传统GA与Is-hGA对比
图7 给出了基于Is-hGA 算法的电机参数辨识曲线。电机在额定工况下运行,室温保持在20℃,系统控制周期为0.1 ms,采样时间为0.001 ms。利用Is-hGA 算法进行参数辨识的基本原理是将每个控制周期采样的100 组数据输入Is-hGA,迭代得到当前控制周期的辨识参数,使参数稀疏,得到以下离散辨识曲线。在图7 中,实线是当前参数的实际值。结果表明,在实验条件下,定子电阻Rs的最小辨识精度为6.82%,定子d 轴与q 轴电感Ld、Lq的最小辨识精度分别为3.62%和2.32%,转子磁通ψf的辨识精度为2.12%。因此,本文提出的参数辨识方法在电机运行过程中具有较高的辨识精度和稳定性。
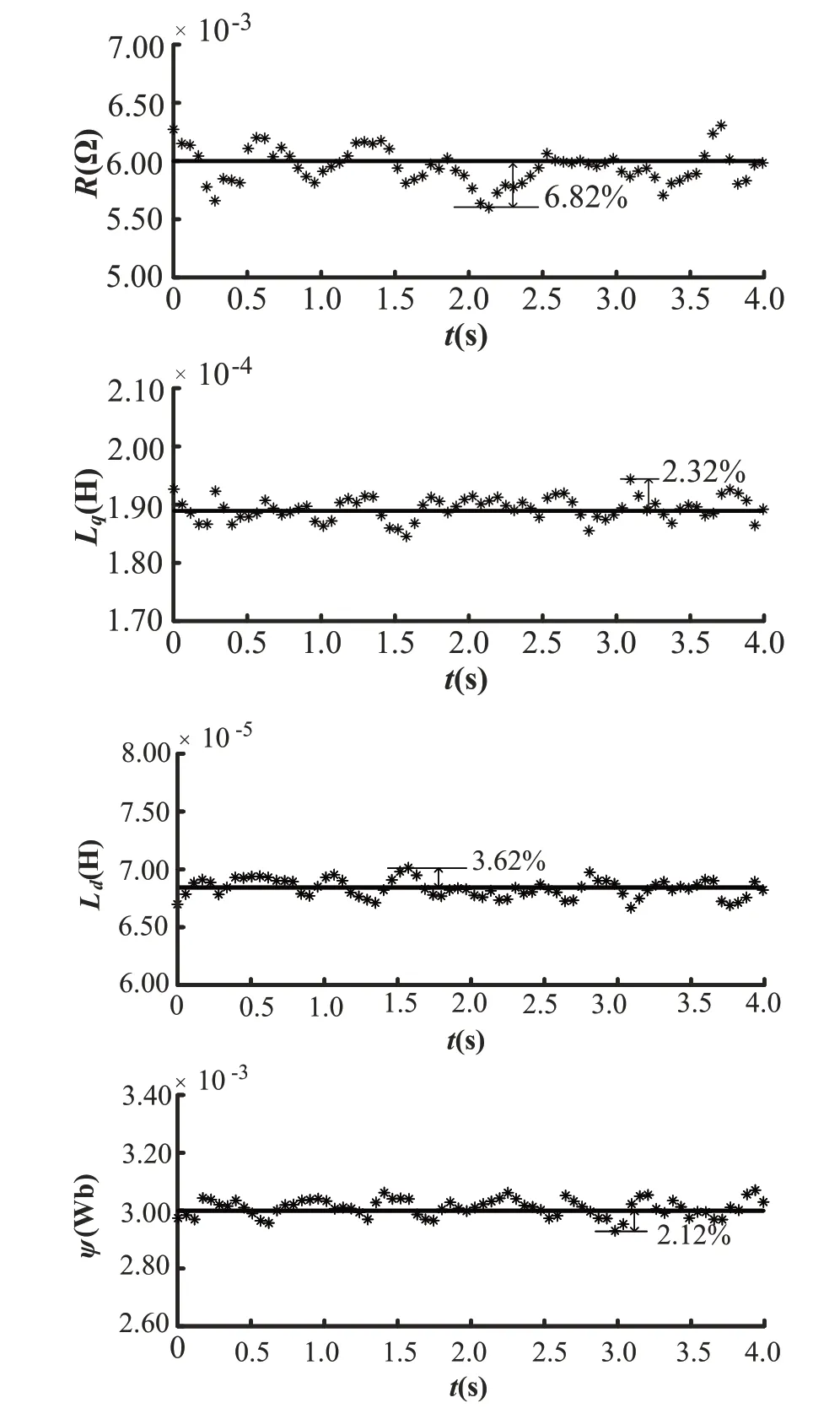
Fig.7 Parameter identification curve based on Is-hGA图7 基于Is-hGA算法的参数辨识曲线
4 结语
本文提出一种采用新型遗传算法的IPMSM 参数辨识方法,其创新之处在于通过引入爬山算法来提高遗传算法的局部搜索能力,并称之为局部搜索混合遗传算法(IshGA)。该参数辨识方法不仅可以减少迭代次数,节省计算时间,而且具有很高的参数辨识精度,可显著提高IPMSM 矢量控制及直接转矩控制的控制效果,因而对IPMSM 控制策略的发展具有重要意义。此外,本文提出的控制方法也可推广应用于其他电机。
