一种基于数据挖掘的软件工作量评估方法
2022-06-28袁春花鲍自翔
张 军,米 杰,袁春花,王 柯,黄 阳,鲍自翔
(中国石油西南油气田分公司通信与信息技术中心,四川成都 610057)
0 引言
软件工作量评估属于软件工程的研究范畴,是软件项目管理的核心所在,也是编制成本预算、策划合理项目进度的基础[1]。特别是在大型企业中,对业务软件需求旺盛,需要不同的业务软件来支撑业务运行。但在编制成本和招标过程中,功能点文档不完整,对软件本身的工作量和成本评估始终是个难题。大多数情况下会依靠专家组成员的意见,而由于软件技术更新迭代快,专家组自身的项目经验和待开发项目可能也存在知识不对称的情况,从而作出不准确的判断。
在需求分析还没有完全准备好之前就进行软件规模估计是一个很普遍的现象,因为在一个项目的开始阶段,对用户功能需求(Functional User Requirement,FUR)的了解仅处在一个初步、不完全、近似的状态,但为了进行招投标或制定开发计划,软件功能的量化估计却是非常必要的。随着软件开发过程的推进,用户功能需求规格说明书逐步完整与精确,甚至模型与代码都已完备,高精度的度量也逐步成为可能,估计反而不再是那么必要,这就是所谓软件功能点估计的悖论[2]。
传统功能点法的核心缺陷就是在项目早期进行评估的可行性问题。因为在计算功能点时不能只有用户需求文档,还需要完整的软件系统规格说明文档。比如在识别项目的范围和边界时,需要详细的用例图;在进行功能点计算时,涉及到内外部的接口文件(ILF,ELF)及数据交易文件(EI,EO,EQ)。通常在项目早期只有用户需求文档,无法真正利用传统功能点法进行软件规模评估。
为解决这些问题,根据工作需要,本文在传统软件工作量评估功能点方法基本思路的指导下,采用基于历史项目数据挖掘的方法对业务信息管理类软件需求阶段的工作量评估思路和方法进行研究。首先,基于历史项目数据挖掘与分析,梳理出信息管理类软件各个功能点的功能特征因子,并研究其标准的描述方法;然后,建立功能点工作量权值回归预测模型和项目总工作量预估模型;最后,以中国石油石化领域的业务信息管理类软件开发项目为例,进行工作量预估模型验证。
1 基于数据挖掘方法改进的功能点法
整体思路如图1 所示,通过建立历史数据回归模型、工作量预估模型与工作量调整模型共同实现根据软件功能点需求表进行软件工作量评估。在该流程中,首先通过历史数据分析提取出新的特征因子,然后逐一研究每类特征因子在所有历史项目中的特征权重值,以及不同项目中各个特征因子的权重值,接下来利用该权重值对新项目的总工作量进行预估,最后通过工作量调整模型实现对工作量的调整。
如图1 所示,在工作量调整模型中,通过专家评审对功能点法的14 个通用特征进行评估,完成对系统复杂度的判断,采用待评审项目的复杂度调整因子除以历史项目调整因子平均值作为本研究方法下的技术复杂度相对调整因子,以下简称为“相对调节因子”。
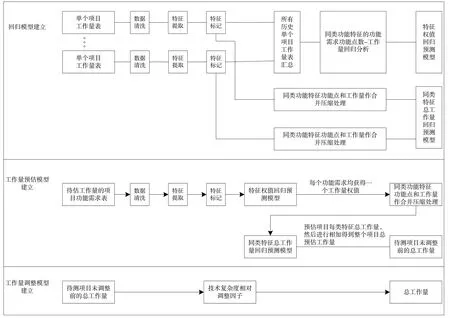
Fig.1 Overall idea of function point method based on data mining图1 基于数据挖掘的功能点法整体思路
2 基于数据挖掘的功能点法
2.1 数据收集与清洗
本次研究总结了近5 年共20 个项目,经过以下规则清洗后,得到了有效的历史功能点工作量数据1 649 条,可用于建立模型。具体清洗规则如下:①功能点各个开发阶段的工作量合并处理;②每个功能模块的工作量不包含项目管理人员、软件维护部署等支撑性工作岗位的工作量。因为这些岗位的工作量与项目本身属性等有很大关联,可能导致较大误差;③对历史项目进行三级分解,形成一、二、三级功能模块,需要对三级功能模块的具体功能点进行工作量梳理;④删除升级改造类项目。
2.2 功能特征及标准化
通过数据清洗,保证了分析的数据项目来源属于同一性质,且均为信息处理软件系统,而非实时控制系统等其他类型,从而构造了一个比较纯粹的样本空间。然后对梳理后功能点的实际工作内容进行总结,并结合信息系统的五大主要功能(输入、存储、处理、输出和控制)对功能特征进行分类,最终总结归纳出12 类功能特征,并规范了其特征分类及其功能描述说明如表1 所示。

Table 1 Function feature classification description表1 功能特征分类说明
2.3 回归模型建立
本研究中,定义由数据收集与清洗形成的三级功能模块列表中特征代码为A1、A2、A3、A4、B1、B2、B3、C1、C2、D1、D2、D3的功能点数依次为a1、a2、a3、a4、b1、b2、b3、c1、c2、d1、d2、d3,功能点数全部为大于等于1 的整数,然后建立预测模型如下:
当特征代码为A1、A3、B2、C2、D2时:
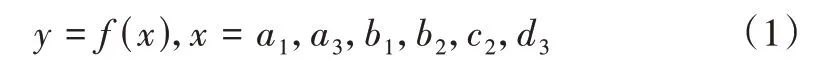
其中,x表示三级模块的功能点数。
当特征代码为B1时:

其中,m 表示每个项目中三级模块功能特征为B1的功能点数平均值。
当特征代码为C1时,根据清洗后的功能点工作量表,通过对本课题涉及到的历史项目进行分析,发现C1目前仅存在功能点数为1 这一种情况,所涉及的工作量在1.18 人/月~0.45人/月之间。对所有功能点对应工作量进行中心平均处理后,得到中心点工作量为0.716人/月。
当特征代码为A2、A4时,A2特征的功能模块工作量与该功能接口数量和访问方式有关,A4特征的功能模块工作量与综合报表类型、图表种类有密切关系。由于在本研究中没有获取到这两类特征更深入的信息资料,故不纳入本次研究范围。
当特征代码为B3、D1、D3时,由于本项目中不涉及B3特征的功能点,且涉及的D1、D3由于功能特征出现频次有限,无法明确特征,故不纳入本次研究范围。
综上,由于本次研究总共获取三级功能模块数为1 649 个,数据量和数据颗粒度有限,因此本课题目前仅针对A1、A3、B1、B2、C2、D2和C1进行特征权值研究。其中,C1权重采用中心值0.716 人/月,其他特征权重均采用一阶线性回归。特征权值回归参数如表2所示。
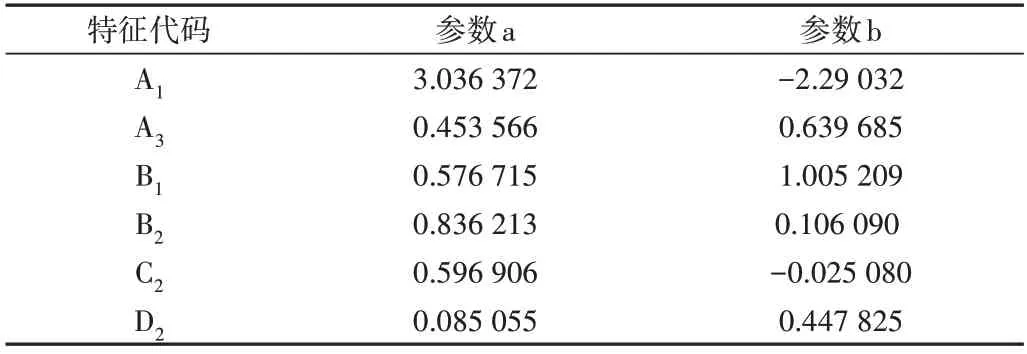
Table 2 Regression parameters of the feature weight表2 特征权值回归参数
然后,将每个项目A1、A3、B1、B2、C2、D2和C1特征的功能点数与工作量分别合并,形成每个项目中每类功能特征的总功能点与总工作量关系表,并对项目中每类特征总工作量进行回归预测分析。具体线性回归参数如表3所示。
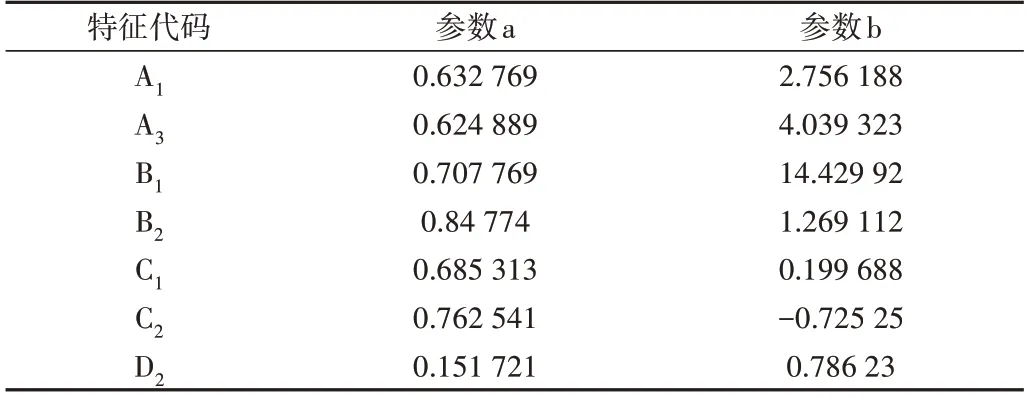
Table 3 Regression parameters of the total workload for each type of feature表3 每类特征总工作量回归参数
3 应用实验
3.1 特征标识及统计
为验证以上回归模型的准确性,本文采用一个新项目进行模型验证。首先对待测项目各个三级功能模块的功能特征进行识别,并映射出每个三级功能模块的工作量,然后对同类特征功能模块的功能点数相加,形成同类特征的功能点总数和总工作量(本文仅对A1、A3、B1、B2、C2、D2和C1七大特征的功能点工作量进行模型验证)。待测项目特征统计如表4所示。
3.2 特征功能总工作量回归预测
根据三级模块总功能点数和总工作量回归参数,通过总工作量回归计算出待测项目未调整前的预估总工作量,如表5 所示。统计以上特征中预估未调整工作量总和为102.38人/月。

Table 4 Statistics of the characteristics of items to be tested表4 待测项目特征统计

Table 5 Estimation of the total workload of features表5 特征总工作量预测
3.3 工作量调整
由于此次用于验证的项目和历史项目为同类级别的项目,故设相对调整因子为1,则项目预测总工作量=总工作量*相对调节因子=102.38*1=102.38。
3.4 实验结果
根据项目实际情况,在清洗后的工作量表中,符合功能特征为A1、A3、B1、B2、C2、D2和C1七大特征工作量的实际审查总量为137,可计算出本次模型验证的准确度为七大特征调整后工作量占实际工作量的百分比,即为102.38/137*100%=74.7%。
4 结语
本研究主要通过数据挖掘理论中的回归预测任务方法,针对中石油、中石化领域的信息管理类软件历史项目进行数据清洗分析;基于软件功能点法评估办法,提取出12 个基础功能特征点,并梳理了各个功能特征点的描述方法;通过历史数据建立工作量评估的回归预测模型,并根据实际案例对项目工作量回归预测模型进行验证。
该方法的优势在于克服了传统功能点法在前期由于缺失项目设计文档导致无法进行评估的缺点,且不需要传统方法在评估中的复杂计算过程,可帮助相关企事业单位在需求阶段便捷地对项目总体工作量进行评估,为管理层决策提供参考依据。另外,本文方法已应用于各个同类项目的领域,且随着同类项目数据的增多,模型参数将不断进行自我优化,逐渐提高模型所覆盖特征的广度和准确度。
