基于Metropolis准则的自适应模拟退火粒子群优化
2022-06-28邓绍强郭宗建汤可宗
邓绍强,郭宗建,李 芳,汤可宗,刘 康
(景德镇陶瓷大学信息工程学院,江西景德镇 333403)
0 引言
粒子群优化(Particle Swarm Optimization,PSO)算法是一种受鸟群觅食行为启发而提出的群体智能优化算法[1-3]。PSO 原理简单、易于理解且参数较少,面向最优化问题求解过程具有搜索能力强、收敛速度较快等优点,现已广泛应用于模式识别[4]、路径规划[5]、图像处理[6-7]等理论研究及工程应用领域。
然而,PSO 应用于多模态优化问题求解往往存在易早熟、收敛精度较低等问题。为有效提高PSO 搜索最优解的求解效率,避免PSO 易陷入局部区域而发生早熟收敛现象,本文提出一种新的基于Metropolis 准则的自适应模拟退火粒子群优化(Adaptive Simulated Annealing Particle Swarm Optimization,ASAPSO)算法。首先,ASAPSO 采用一种新的自适应极值惯性权重设置方式,该方式将增强粒子种群全局搜索和局部搜索的有序转换;其次,以粒子经历的局部最优解为交流学习对象,构建粒子间学习交流的中心粒子,从而增强粒子个体的社会学习能力;最后,粒子群体搜索过程根据所设计的模拟退火选择概率变换粒子飞行方向,由中心粒子引领粒子的飞行搜索,避免搜索过程陷入局部最优区域,从而提高最优解的搜索效率和精度。
1 相关研究
针对PSO 易早熟收敛且精度低等问题,诸多学者从如下方面对PSO 进行研究并提出有效的改进策略:
(1)惯性权重控制。例如,Shi 等[8]描述了一种惯性权重的设置方式并采用线性递减策略改进PSO 算法,提高了粒子群体搜索最优解的效率;闫群民等[9]使用一种双曲正切策略自适应控制惯性权重变化,并引入模拟退火思想对全局最优粒子进行扰动,提升算法收敛精度和稳定性;徐浩天等[10]以正态分布曲线作为惯性权重的衰减策略曲线,通过引入控制因子对粒子位置进行改进,使得所提出的改进PSO 算法能很好地在优化过程中平衡全局搜索和局部搜索能力。
(2)粒子演化进程中对粒子行为的改善。例如,Zhan等[11]将粒子寻优分成4 个阶段,根据阶段的不同,通过模糊控制自适应确定组合参数,从而提升PSO 算法的收敛速度和精度;汤可宗等[12]引入广义中心粒子和狭义中心粒子,提出双中心粒子群优化,提升了PSO 算法的收敛速度和精度;朱经纬等[13]针对陷入局部最优的粒子,给予一个较大的速度将其弹射出去,增强了算法的全局搜索能力。此外,在PSO 中融入其他启发示搜索算法特性以进一步增强算法多样性及搜索能力。
(3)融合其他启发式搜索算法特性。例如,高鹰等[14]将模拟退火思想引入具有杂交和高斯变异的粒子群优化算法中,改善了算法跳出局部最优的能力;刘玉敏等[15]在算法中引入选择、变异算子保持种群多样性,使其具有跳出局部最优的能力;李潇等[16]采用自然选择策略,将适应度好的一半粒子速度位置覆盖至较差的一半粒子,使种群一直以较好的全局最优进行搜索,从而加快改进PSO 的收敛速度;Enireddy 等[17]将布谷鸟搜索和粒子群优化结合,提升了神经网络对图像分类的学习效率;周蓉等[18]在PSO中融合灰狼算法思想进一步提高算法收敛精度。
上述研究侧重于粒子跳出局部最优解区域的改进策略。然而,当个别陷入局部最优区域的粒子引领整个种群飞行时,其他粒子将快速聚集在局部最优区域从而加快算法早熟。本文提出的ASAPSO 算法中,模拟退火策略不仅作为一种扰动准则对全局最优粒子进行小范围局部扰动,也作为一种接受准则用于计算新粒子引领整个种群飞行的概率。此外,所构建的自适应极值惯性权重调整策略能有效控制粒子的惯性权重随迭代过程的自适应变化,并在粒子演化进程中由粒子个体间的学习交流定义新的飞行方向,并由中心粒子引导粒子飞行。
2 相关概念
2.1 Metropolis准则
模拟退火思想源于固体材质的物理退火原理,固体在高温情况下冷却至常温状态,其固体内部的粒子会随着温度的逐渐降低而释放自身内能,逐渐使粒子趋于有序状态,最后在常温状态下达到稳定基态。在某个特定温度T下,由于粒子的运动,固体内部系统的内能会发生改变,如果系统内能朝着减少的方向进行,就接受该变化;反之,则以一定概率决定是否接受这种状态变化。基于这种粒子状态变化过程,Metropolis 准则按式(1)定义物体在温度T下固体由i状态转化至j状态的概率。
其中,e为自然对数,E(i)和E(j)表示物体在i状态和j状态下的内能,K是玻尔兹曼常数。
2.2 基本PSO算法
基本PSO 是模拟鸟群觅食过程在给定搜索空间内搜索全局最优解的重复迭代过程。该迭代过程中,每个粒子模拟一只鸟儿,具有速度和位置两个特征量。粒子在搜索空间中的位置表示问题的一个潜在可行解,而速度表示粒子在搜索空间内一次迭代搜索飞跃的距离。每个粒子通过评价自身的适应度值并跟踪两个极值不断更新自身飞行方向和位置,两个极值分别是:个体粒子在寻优过程中经历的历史最优值Pbest,以及粒子群体在寻优过程中经历的种群最优值Gbest。每个粒子按式(2)和式(3)更新自身速度和位置。
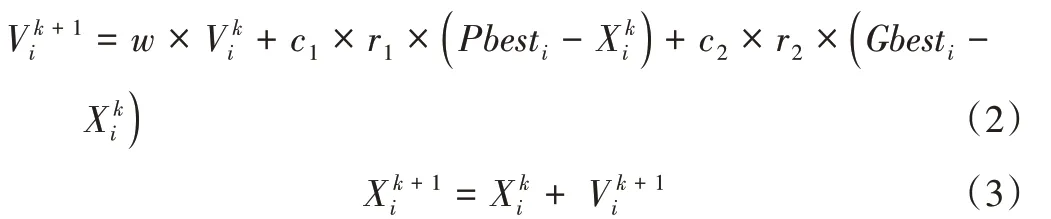
其中,k是迭代次数,分别表示第i个粒子在第k次迭代时的速度和位置。r1和r2是介于[0,1]区间的随机数;c1和c2是两个学习因子,分别控制个体极值Pbest和全局极值Gbest对粒子飞行速度的权重影响,取c1=c2=2;粒子群搜索过程还需判断自身速度及位置是否越界,常使用两种越界行为处理方法[10]:一是将粒子越界对应的维度设置为相应维度的边界值;二是在可行解空间范围内随机生成一个新的位置。w为惯性因子,使粒子保持运动惯性,控制着粒子的搜索范围。当w值较大时,粒子全局搜索能力加强;反之,局部搜索能力加强。PSO 搜索过程中,w常采用线性递减惯性权重设置方式[12],即随着迭代的进行,以线性递减方式逐代减少惯性权重至一个预先设定的最低值。
3 自适应模拟退火粒子群(ASAPSO)算法
伴随着迭代过程,粒子种群搜索区域逐渐由全局搜索范围转入局部搜索区域,粒子种群在Gbest引领下飞行至局部最优解区域,整个粒子种群将收敛至局部最优解或其邻近区域。此时,Gbest继续引导粒子飞行往往不利于粒子种群的全局搜索,若无局部迁移策略,整个粒子种群搜索将陷入局部最优区域。为此,结合粒子真实的自然状态飞行方式,可在粒子局部最优解之间引入一种新的飞行方式以重新引领粒子种群的集体飞行过程。以Griewank函数为例,如图1 所示,Pi(i=1,2,3,4)表示粒子i某一次迭代过程所处位置,该次迭代搜索对应的种群最优位置为Gbest_1,五角星标记为所求问题的全局最优解Gbest_e,菱形标记是粒子i经历的局部最优解,即粒子i的个体极值Pbest_i(i=1,2,3,4),十字形标记是基于个体极值Pbest_2 和Pbest_3交流构建的中心粒子Gbest2,3,该中心粒子除不具有速度外,与其它粒子属性保持一致,如,粒子位置更新、全局极值竞争、适应度评价等信息操作,分析观察发现,如果考虑粒子在多个局部最优解之间方向飞行,粒子飞行方向有可能指向全局最优解Gbest_e或其邻近区域,例如,在中心粒子Gbest2,3的引领下,粒子群体将更快地向全局最优解靠近。因此,从粒子真实的自然飞行状态反映出:在粒子群体之间进行局部最优解的信息交流,以此构建新的中心粒子,由中心粒子引领整个粒子种群的飞行,将有利于避免粒子群体陷入局部最优区域。粒子种群将更加快速地趋向于所求解问题的全局最优解。
3.1 中心粒子

Fig.1 Individual extreme value information exchange图1 个体极值信息交流
在粒子群体飞行过程中,为加强个体粒子之间的信息交流,以粒子经历的局部最优解为交流学习对象,每个粒子均可从粒子种群中任选其他粒子的局部最优解进行交流学习并构建新的中心粒子,中心粒子将增强粒子个体的社会学习能力。在此,定义粒子i向粒子j进行学习交流而构建的中心粒子如式(4)所示。

其中,rand为介于0 和1 之间的随机数,Pbesti和Pbestj分别是粒子i和j的个体极值。粒子迭代飞行过程中,以中心粒子引领粒子群体飞行,粒子速度更新公式如式(5)所示。
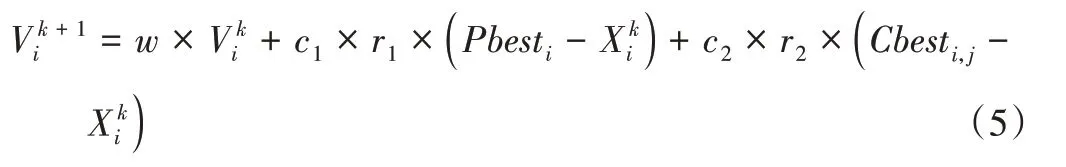
3.2 模拟退火选择概率
粒子群体搜索过程中,中心粒子的作用是增强PSO 的搜索能力,扩大粒子的搜索范围,在粒子陷入局部最优时跳出局部区域。在此,基于Metropolis 准则和中心粒子,给出以下模拟退火选择概率以确定粒子搜索过程的飞行速度更新方式。在模拟退火算法中,初温设置极其重要,初温越大,算法搜索范围越广,获得解的质量越高。结合文献[9]的初温设置,模拟退火选择概率其计算步骤如下:
Step1:初始化温度T,PSO 迭代搜索过程的对应温度Tk按式(6)设置。

其中,Kmax为算法最大迭代次数,u为温度衰减系数,取u=0.95,k是迭代次数。
Step2:按式(7)计算粒子i使用中心粒子Cbesti,j引领飞行搜索的模拟退火选择概率。
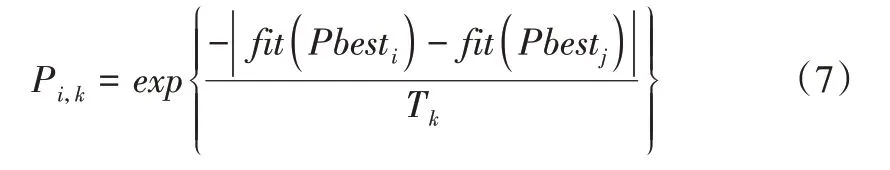
其中,fit(Pbesti)为i粒子局部最优解的适应度值,j为种群中除i粒子外任一随机粒子,k为迭代次数。
Step3:均匀生成一个0 到1 之间的随机数ri,j,若式(7)中模拟退火选择概率小于ri,j,粒子按照式(5)更新速度,否则按照式(2)更新。
3.3 自适应极值惯性权重
通常情况下,PSO 惯性权重w采用线性变换方式,其随搜索迭代过程逐渐减小。在粒子群体搜索前期,w取值较大则有利于粒子种群在广域空间内开展大范围搜索,在后期迭代搜索过程中,w随迭代次数增加而逐渐变小,整个搜索过程伴随着全局搜索和局部搜索之间的多次环境转换,粒子种群搜索区域也会发生多次变换。因此,单纯地使用线性变换方式改变w值将不利于全局搜索和局部搜索之间的环境变换。在此,使用式(8)定义的自适应极值惯性权重设置方式控制w随迭代过程自适应线性变化:
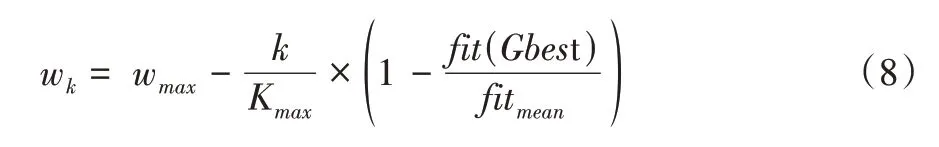
其中,wk为第k次迭代的惯性权重;wmax、wmin为惯性权重w的最大和最小值;Kmax为最大迭代次数;fit(Gbest)和fitmean分别为全局最优粒子适应度和粒子种群的平均适应度值。不同于以往w线性变换方式,上述公式表明:伴随着持续的粒子种群搜索过程,粒子群体随迭代过程逐渐趋近于全局最优极值Gbest的邻近区域。此时,粒子种群平均适应度值fitmean逐渐趋近于fit(Gbest),fit(Gbest)与fitmean间的比值逐渐变大,粒子种群逐渐转入局部搜索区域。为此,随着局部搜索过程的推移,逐渐增大的wk会增强粒子种群跳出局部搜索区域的能力,转入全局搜索状态,且随着搜索过程的持续进行,wk值会逐渐减少,这种搜索状态又逐渐进入局部搜索状态。
3.4 算法流程
ASAPSO 算法流程如图2所示。

Fig.2 Flow of ASAPSO algorithm图2 ASAPSO算法流程
ASAPSO 算法执行步骤如下:
Step1:种群初始化,分别设置c1、c2、wmax、wmin、T、u。
Step2:初始化全局极值Gbest和每个粒子的个体极值Pbest。
Step3:根据式(8)设置粒子飞行过程的自适应极值惯性权重w。
Step4:对于每个粒子i,在粒子种群中确定一个学习交流粒子j,并根据式(4)构建粒子i的学习交流中心粒子Cbesti,j。
Step5:根据上文描述的模拟退火选择概率计算粒子的飞行速度,并根据式(3)计算粒子的飞行位置。
Step6:更新粒子群体的Gbest和每个粒子的个体极值Pbest。
Step7:判断是否达到最大迭代次数或满足精度,若满足条件则输出算法求解结果,若未达到则转至Step3。
4 仿真实验及结果分析
4.1 参数设置及测试函数
为验证本文所提出ASAPSO 算法的有效性,选取DCP⁃SO[12]、IIWPSO[19]、DACPSO[20]、和TSAPSO[21]这4 种算法,面向6 个典型测试函数(见表1)测试各比较算法的性能。为增强算法的可比较性,各比较算法设置相同的初始参数,其种群规模N=40,c1=c2=2,惯性权重wmax=0.9、wmin=0.4,最大迭代次数Kmax=1 000,测试函数维度d=30。实验所采用的软硬件环境为:Windows 10 Professional 21H1;In⁃tel(R)Xeon(R)CPU E3-1231 v3 处理器,内存16GB,在Matlab2019a语言环境下测试。
4.2 实验数据分析
为评价算法性能,采用以下评价指标评价算法性能:最优解适应值(Min)、种群均值(Mean)、种群适应值标准差(SD)、收敛率(CR)。CR 表示100 次迭代内满足所需精度的收敛次数,反映算法可收敛性;平均收敛迭代次数(ACIT)用于测试算法成功收敛所需的平均迭代次数,该性能反映算法收敛速度。每种比较算法求解测试函数,各独立运行100次,其测试统计结果如表2所示。
表2 中数据显示,在多模态函数f1和f2的测试中,无论从Min 和Mean 还是SD 而言,ASAPSO 算法相对其他比较算法均有明显优势,其计算数值的精度也远高于其他比较算法。并且各比较算法独立运行100 次,ASAPSO 的CR 能够达到94%,其收敛率远高于其他比较算法。在非对称多模态函数f3测试中,ASAPSO 与DCPSO 在Min 测试性能较为接近,但前者收敛稳定性要低于DCPSO。ASAPSO 在算法迭代前期时,由于模拟退火选择概率的作用,种群能够快速地寻找到可能存在的最优解邻近区域,在Min、Mean和SD 等测试性能的精度要优于IIWPSO 与DACPSO。在f4的测试过程中,TSAPSO 与DCPSO 均无法寻找到满足条件的解。IIWPSO 与DACPSO 虽能够得到较好的Min,但就Mean、SD、CR 和ACIT 性能而言,其测试性能要劣于ASAP⁃SO。在f5的函数求解中,ASAPSO 与DCPSO 性能测试上较为接近,两种算法都能100%收敛至最优值,优于其他比较算法。在单模态圆形函数f6中,ASAPSO 各项测试性能数据均与DCPSO 相接近,两种算法的收敛率均为100%。然而,从表2 数据可见,ASAPSO 收敛精度明显优于DCPSO 与TSAPSO,相比IIWSO 和DACPSO 两种比较算法,虽然在测试函数也能够收敛到最优值0,但就CR 和SD 而言,其可收
敛性和收敛稳定性均劣于ASAPSO。

Table 1 Typical test function表1 典型测试函数
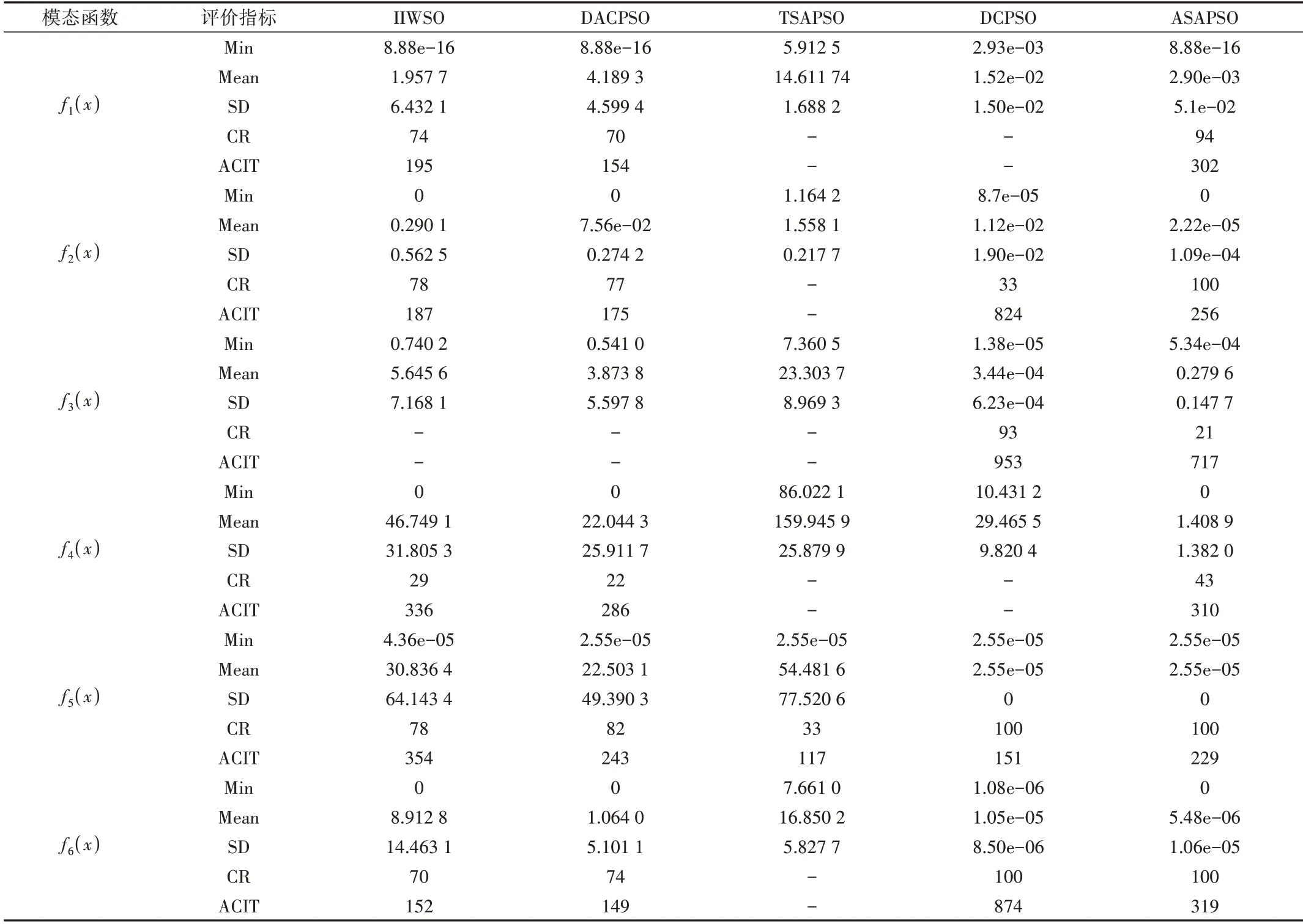
Table 2 Test results of five comparison algorithms表2 5种比较算法测试结果
为了更直观地说明ASAPSO 在以上6 个模态函数中的测试性能,各比较算法在粒子群体寻优过程中种群最小适应度值随迭代次数变化曲线如图3所示。

Fig.3 Variation curve of optimal solution of five comparison algorithms in the solution of test function图3 5种比较算法求解测试函数的最优解变化曲线
由图3 可以看出,ASAPSO 的轨迹与DACPSO 轨迹较为接近,在曲线趋于平缓时其轨迹有跳跃式下降的情形。因此,ASAPSO 精度相较于DACPSO 显示出较好的全局最优值,但其收敛速度要略慢于DACPSO。而TSAPSO 要明显劣于其他比较算法,DCPSO 的寻优轨迹呈缓慢下降趋势,其收敛到所需精度的全局最优值需较长时间,往往在600 次迭代之后才能搜寻到最优值。相较于DCPSO,ASAPSO 能够在较短时间内找到全局最优解。
4 结语
针对PSO 搜索过程中易陷入局部最优区域的问题,本文提出了一种新的自适应模拟退火粒子群算法。所提出的ASAPSO 算法构建了粒子间学习交流的中心粒子,中心粒子将增强粒子个体的社会学习能力。种群中每个粒子根据模拟退火选择概率确定是否向中心粒子学习,并由中心粒子引领粒子向着全局最优解区域飞行。ASAPSO 能够增强粒子跳出局部最优区域的能力,提高粒子种群搜寻全局最优解的效率。仿真测试表明,ASAPSO 在收敛速度和收敛精度上均优于其他比较算法,能够在较短时间内搜寻到全局最优解。后续工作中,将基于ASAPSO 进一步分析粒子的飞行真实状态,将粒子按飞行方向划分为不同类别的粒子群体,针对每种类别的粒子给出不同的惯性权重设置方式,使得粒子种群不再以式(8)表现的单一方式向着全局最优解区域靠近,并在实际工程应用案例中进一步验证所提出ASAPSO 改进算法的测试性能。
