地理标志农产品质量安全风险评估及预警研究
2022-06-28胡晨钰
张 彪,胡晨钰,李 晶
(昆明理工大学管理与经济学院,云南昆明 650500)
0 引言
中国作为一个农业大国,农业是国民经济的根本,而“三农问题”一直是我国国民经济发展所面临的重要挑战。2021 年是“十四五”开局之年,《2020 年农产品质量安全工作要点》中明确指出各企业要提升监管能力,完善质量监管体系,防范质量安全隐患,稳步提升农产品质量安全水平,做好农产品质量安全工作对于实施乡村振兴战略具有特殊且重要的意义[1]。与一般的农产品相比,地理标志农产品在其原产地独特的气候和特殊的土壤条件等自然生态环境以及长期沉淀的历史人文因素影响下,形成了自己独特的品质和特征。然而,近些年来频频爆出地理标志农产品质量安全事故,如赣南脐橙染色事件、五常大米香精事件、金华火腿敌敌畏事件等让人瞠目结舌[2]。这些事故足以表明当前我国在地理标志农产品质量安全方面存在着明显问题,严重破坏了地理标志农产品的品牌效益与市场信誉,阻碍了农业的规模化与产业化发展。云南省作为地理标志农产品大省,截至2021 年,拥有地理标志农产品86 个[3]。因此,对地理标志农产品的质量安全风险进行评估与预警,对于降低农产品质量安全风险,保证品牌影响力具有重要意义。
很多学者在农产品质量安全相关理论与实践方面进行了大量探索,尤其是在地理标志农产品品牌建设、农产品质量安全风险因素研究、农产品质量安全风险评估等方面取得了丰硕成果。学者们大多基于不同视角,采用不同方法展开研究。在农产品质量安全风险评估方法方面,可分为单一风险因子评估和多指标综合评价[4]。在单一风险因子评估中,影响农产品质量安全的主要来源是化学性污染和生物性污染。齐艳丽等[5]对玉米及其秸秆中残留的戊唑醇和吡唑醚菌酯进行风险评估,并针对玉米生产中农药的安全使用提出建议;何祥祥等[6]通过评估草莓的革兰氏阴性细菌、霉菌等微生物污染情况,为控制草莓微生物数量和开发杀菌抑菌技术提供了参考。但由于单一风险因子的评估因子较为单一且多用于化学、生物等自然科学领域,因此社会学科相关研究大多使用多指标综合评价法。多指标综合评价常用方法有:模糊评价法、Logistic 回归模型、人工神经网络法等。祁南南[7]建立了静态模糊综合评价模型来评估水果质量安全风险,虽能够有效判断水果的风险等级,但计算复杂,指标权重的确立缺乏依据;张东玲等[8]提出基于Logistic 回归方程模型的农产品质量风险评估方法,并对风险进行了判别,但其可输入的指标数量过少,很难拟合出数据的真实分布;陈婷婷[9]基于BP 神经网络建立肉制品冷链物流质量风险评估模型,并对风险等级进行分类,但算法的学习速度较慢,且训练精度较低。因此,本文拟采用的评估模型为RF-DBN 模型,主要原因有:①RF 因具有强大的特征抽取和表达能力,被广泛用于高维、海量数据的降维处理,去除冗余特征,防止过拟合现象出现;②DBN 模型前期采用无监督学习,最后一层采用反向传播神经网络自顶向下有监督地微调整个模型,减少前向无监督学习的整体误差,使网络结构达到最优。通过样本数据的输入,不断学习并改进网络模型权值,能够减少人为主观性对结果造成的影响。
国内外学者在地理标志农产品品牌建设及发展相关理论与实践方面取得了丰硕成果,但在地理标志农产品质量安全风险评估及预警方面的研究仍存在很大的提升空间,如构建系统性的质量安全风险指标,而非采用单一性评价指标等。鉴于此,本文以云南普洱茶为例,运用全面质量管理中“人、机、料、法、环”5 要素,建立地理标志农产品质量安全风险指标评估体系,再运用随机森林模型对指标体系进行降维,最终构建云南省地理标志农产品质量安全风险评估及预警的RF 和DBN 模型,并进行实证研究。
1 地理标志农产品质量安全风险评价指标体系构建
1.1 评价依据及分析
全面质量管理是指一种以产品质量为核心,全员参与以实现对产品进行有效质量控制和质量改进的管理体系,其中“人、机、料、法、环”是全面质量管理理论中影响产品质量的主要因素。因此,本文拟从供应链角度出发,结合上述5 个因素对地理标志农产品在种植、加工、物流和销售4个阶段的质量安全风险因素进行分析,具体如下:
(1)种植阶段质量安全风险。与一般农产品相比,地理标志农产品独特的品质和特征大多来源于原产地特有的气候与特殊的土壤条件。在种植阶段,“人”的因素可分为种植人员的种植经验和种植技能培训水平,若种植人员缺乏种植知识及相关技能,则可能导致其在设备操作、病虫害防治等对专业性要求较高的操作中出现问题,影响地理标志农产品质量安全;“机”的因素可分为农产品种植机械化水平和农产品质量检测设备水平,种植机械化设备的缺乏将直接导致地理标志农产品生产效率低下,产量较低,质量水平参差不齐;“料”的因素主要包括地理标志农产品种苗选择及农药、化肥使用情况,不同品质的种苗会生长成不同质量的农产品,若滥用农药和化肥,将会在农产品内部残留有害物质,影响其质量安全;“法”的因素主要包括病虫害防治方法和地理标志农产品采摘方法,不同方法也会导致不同的质量问题;“环”的因素包括地理标志农产品生长环境和灌溉水质,地理标志农产品的生长对种植环境和水质要求较高,这些都会对产品造成安全隐患。
(2)加工阶段质量安全风险。对地理标志农产品采摘之后进行初加工,可增加其附加值,提升产品在市场上的竞争力和价格水平。在加工阶段,“人”的因素主要包括工作人员从业资质和知识技能培训水平,地理标志农产品独特的加工工艺也是其具有特殊品质的原因之一,因此工作人员需要具有专业的加工知识和技能;“机”的因素主要包括加工机器自动化程度和加工成品检测设备情况,在加工过程中,机器的自动化水平会直接影响产品的标准化,若使用劣质的加工设备和质量检测设备,会导致加工工艺不完善,质量不合格;“料”的因素主要包括原材料新鲜程度和食品添加剂情况,在加工中使用变质的原材料或大量防腐剂和食品添加剂会影响农产品质量安全;“法”的因素主要包括地理标志农产品独特的加工工艺和温湿度控制技术;“环”的因素主要包括加工场所环境和仓库环境,地理标志农产品对温度、湿度的敏感度较高,过湿或温度过高极易导致其发霉变质。此外,仓库不卫生也会增加其质量安全隐患。
(3)物流阶段质量安全风险。地理标志农产品在物流阶段产生质量安全风险主要来源于运输过程中的存储问题和其包装产生的安全隐患。“人”的因素主要为工作人员缺乏存储经验造成的质量安全隐患;“机”的因素主要为质量检测设备情况,由于地理标志农产品具有保质期短、易变质的特点,若无法及时清理破损、变质的农产品,会威胁其质量安全;“料”的因素主要包括地理标志农产品最终销售成品质量和农产品外部包装材质质量;“法”的因素主要包括包装技术和温湿度控制技术,因包装不当导致微生物含量超标等会造成安全隐患;“环”的因素主要包括仓库存储环境和运输环境,严格监控物流阶段的环境卫生情况可大幅降低农产品质量安全风险[4]。
(4)销售阶段质量安全风险。地理标志农产品不同于一般农产品具有流动销售的特点,因此无法轻易辨别其质量,但与一般农产品类似,地理标志农产品具有易变质、难储存的特点。因此,在销售阶段,“人”的因素主要为工作人员存储经验;“机”的因素为质量检测设备情况,如果商品质量检验水平不高,难以剔除出已变质、损耗的产品,则会造成质量安全风险;“料”的因素主要为商品质量水平,需要从商品的源头控制其质量安全风险;“法”的因素主要包括产品冷藏保鲜技术及商品标识与可追溯管理水平;“环”的因素主要包括仓库存储环境和销售场所环境,需要从产品存储到销售环节都保证其质量安全。
为更清晰地描述“人、机、料、法、环”5 要素与种植、加工、物流、销售4 阶段之间的关系,系统化地绘制质量安全风险体系鱼骨图如图1所示。
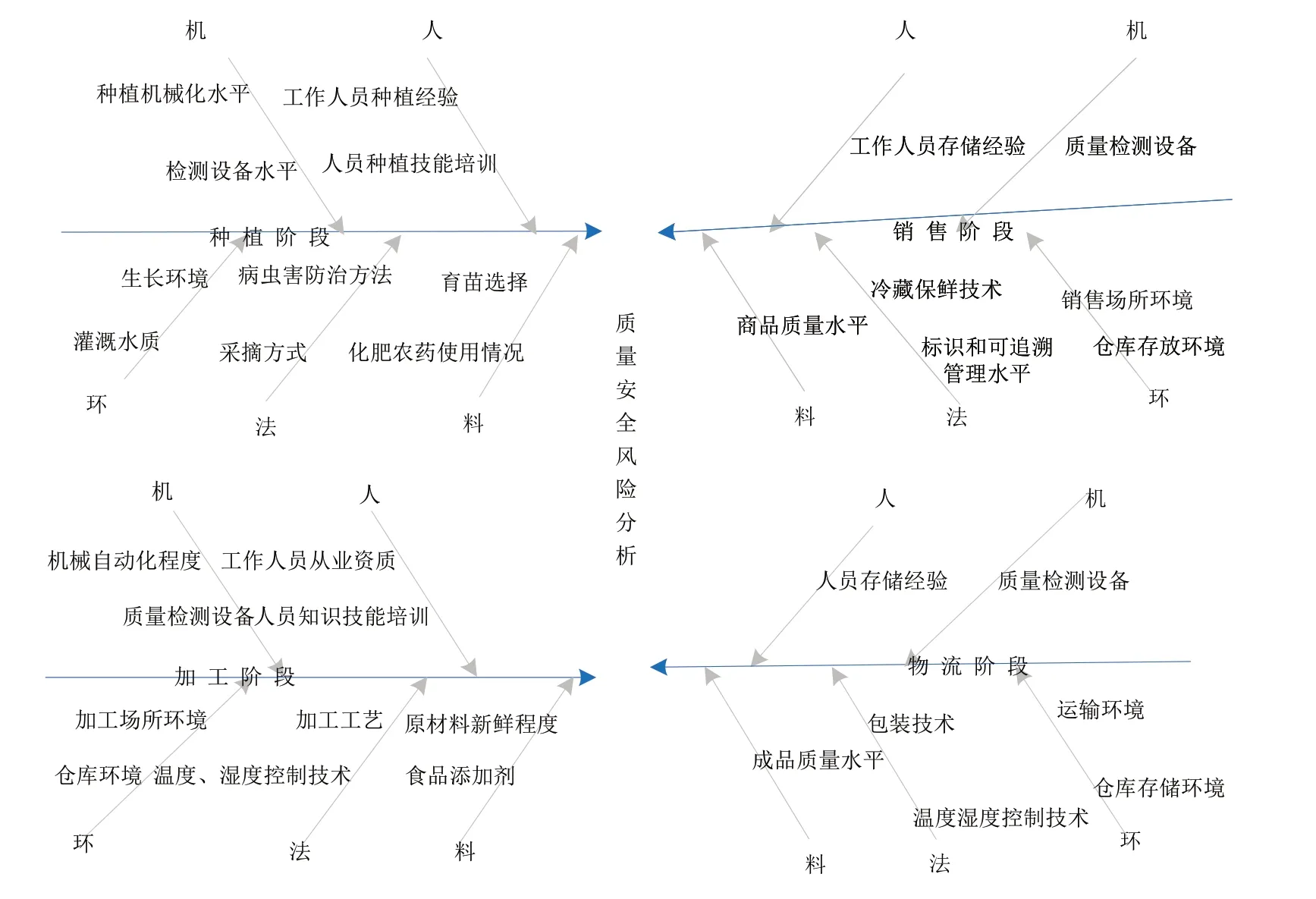
Fig.1 Quality and safety risk analysis fish bone map图1 质量安全风险分析鱼骨图
1.2 质量安全风险评估指标收集
目前,关于农产品质量安全风险评估指标构建的研究成果丰富,本文的主要研究对象是地理标志农产品,其本身就属于农产品范畴,因此在指标构建上可参考农产品质量安全相关文献来确定。运用文献收集法对农产品质量安全评估体系指标进行初步的收集与选取,查找国内外关于农产品质量安全评估体系的相关文献,最后选取了10篇文献资料,具体如表1所示。
1.3 质量安全风险评估指标体系构建
首先,采用文献收集法对质量安全风险因素进行收集与归纳,建立质量安全风险评估体系;其次,运用专家打分法,邀请7 名质量风险管理领域的专家,对质量安全风险评估体系进行论证与筛选;最终,确定地理标志农产品质量安全风险评估体系,其中包含4 个二级指标,34 个三级指标,具体如表2所示。
2 地理标志农产品质量安全风险评估模型构建
2.1 随机森林模型
2.1.1 模型简介
随机森林(Random Forests,RF)通常又称为组合决策树,其是通过集成学习思想将多个决策树集成的一种算法,因其具有强大的特征抽取与表达能力,被广泛用于高维、海量数据的降维处理。随机森林的基本原理是从初始训练集M 中随机且有放回地抽取m 个训练样本,抽取出的每个训练样本便是一棵决策树(弱分类器),m 个样本便组成了随机森林。

Table 1 Information on indicators of agricultural product quality and safety evaluation system表1 农产品质量安全评价体系指标资料

Table 2 Quality and safety risk assessment system表2 质量安全风险评估体系
2.1.2 模型构建
本文采用随机森林模型对指标体系进行降维,对各个指标特征的重要性进行评估,计算随机森林中每棵决策树上的特征作了多少贡献,依据特征重要性剔除相应比例的特征,选择最优特征并对指标重要性进行排序,最终筛选出对结果影响较大的指标实现数据降维。本文采用随机森林模型对影响地理标志农产品质量的安全风险因素重要性进行排序,筛选掉对地理标志农产品质量安全影响较小的指标因素。RF 结构如图2所示。
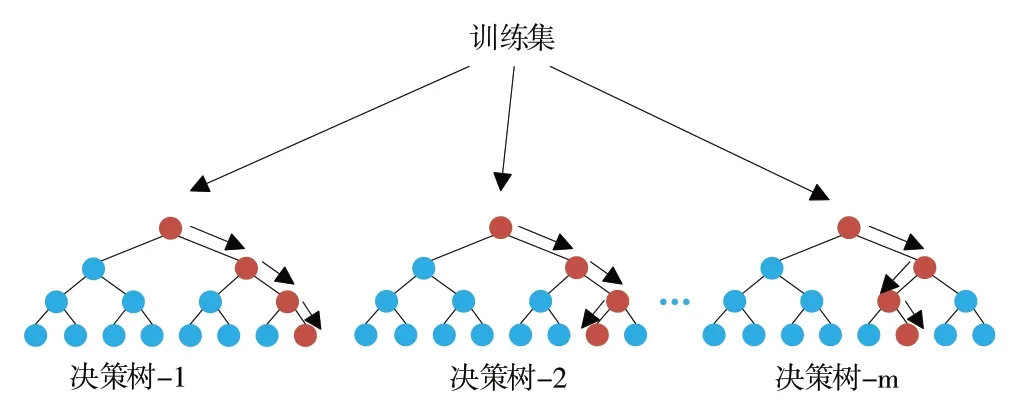
Fig.2 RF structure图2 RF结构
2.2 深度置信网络模型
2.2.1 模型简介
深度置信网络(Deep Belief Networks,DBN)是2006 年由“深度学习之父”Hinton 提出的深度学习模型,其是一个将概率统计学与机器学习及神经网络相融合的概率生成模型。深度置信网络是由若干个受限玻尔兹曼机(Re⁃stricted Boltzmann Machines,RBM)元件堆叠而成,通过不断从底层特征中提取出抽象的高层特征后进行分类,具有良好的学习能力。单层RBM 是包含一层可视层v 和一层隐藏层h 的无向图模型,且层内的单元之间不存在连接。RBM 结构如图3所示。
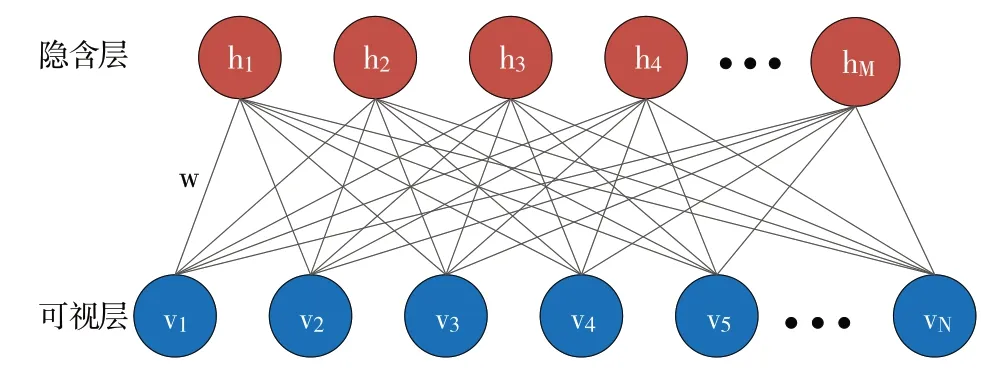
Fig.3 RBM structure图3 RBM结构
首先,在RBM 训练过程中,利用对比散度(Contrastive Divergence,CD)算法进行参数更新,使得训练样本的概率达到最大。每一层RBM 经过多次迭代训练均得到初始化权值参数,形成无监督的DBN 网络。然后,采用BP 算法将最后一层RBM 的输出值作为输入值,自顶向下有监督地微调整个模型,减少前向无监督学习的整体误差,达到最优网络结构。最后,将得到的特征矩阵输入softmax 分类器中,利用随机梯度下降(Stochastic Gradient Descent,SGD)算法对损失函数进行优化,最终达到分类的目的。
2.2.2 模型构建
本文将收集的数据集按照8∶2 的比例划分为训练集和测试集,利用训练集训练RBM 模型,确定模型初始权值,将最后一层RBM 的输出值当作BP 神经网络的输入层,对模型进行有监督的调优。softmax 分类器在微调后对地理标志农产品的质量安全风险进行判别分类,并输出风险等级。之后利用测试样本集检验DBN 模型分类效果,并将此模型用于地理标志农产品质量安全风险分类与识别。DBN 模型结构如图4所示。
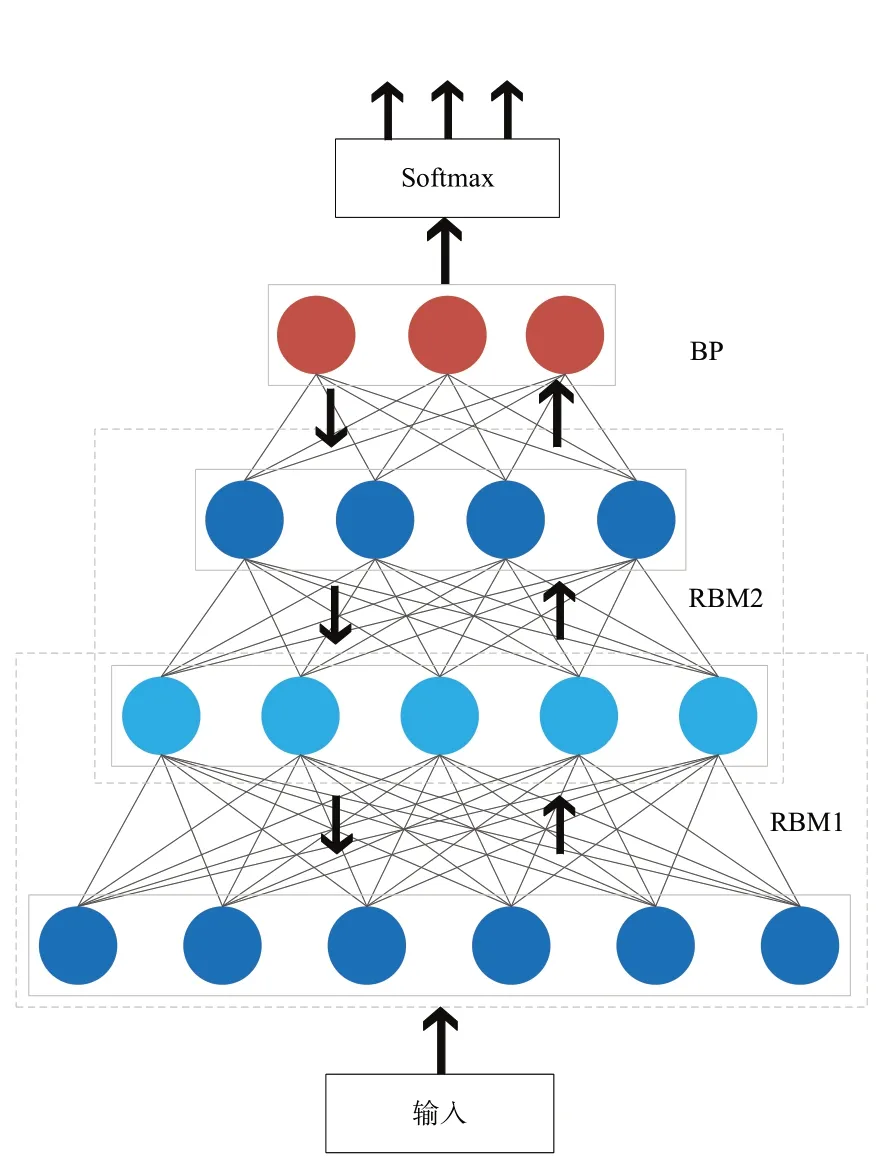
Fig.4 DBN structure图4 DBN结构
3 实证分析
3.1 数据收集
普洱茶作为云南省的地理标志农产品,在省内被普遍种植,尤其位于澜沧江中下游地区的普洱市茶区、西双版纳茶区、临沧茶区三大茶区更是贡献了90%以上的普洱茶原料。本文为验证模型,将选取300 个普洱茶企业,对其普洱茶质量安全风险等级进行评价。将其风险评价等级分为5 级,最低风险为1 级,最高风险为5 级。然后邀请7位质量安全风险评估专家,根据企业相关情况采用问卷形式对指标体系进行打分,分数范围为0~10。分数越接近10,代表该指标的情况越优异,所对应的风险越低,如表3所示。最后根据得到的数据构建风险矩阵表。

Table 3 Risk rating table表3 风险等级表
通过多轮匿名方式征询质量安全风险评估专家意见,不断反馈、调整并综合多数专家的主观经验和判断,统计、处理、分析专家意见,对选取的300 家普洱茶企业的34 个普洱茶质量安全风险指标等级进行客观、合理估算,最终得到300 份普洱茶质量安全风险指标体系调查数据。将收集得到的专家打分数据进行归一化处理,得到最终影响云南普洱茶质量安全风险的指标体系数据。
3.2 基于RF的指标降维
将RF 模型导入影响云南普洱茶质量安全风险的指标体系数据,借助Python 软件得到34个影响因素的重要性分布,如图5所示。
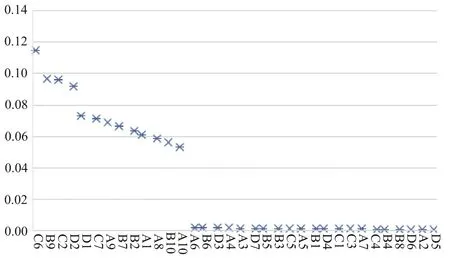
Fig.5 Indicator importance distribution map图5 指标重要性分布图
为更直观地观察数据,将各个指标的重要性数据汇总成表格,如表4 所示。通过对表4 中的指标重要性进行分析,可得出:①重要性指数最高的指标。最重要的因素是仓库存储环境情况,重要性指数为0.11。茶叶需严格控制存储的温度、湿度以保证其口感、色泽等,因此物流期间的仓库存储环境对于保证茶叶质量至关重要;②重要性指数达到0.09~0.1 区间的指标。在此区间的指标包括加工场所环境、物流阶段成品质量检测设备和销售阶段商品质量检测设备情况。普洱茶的加工工序较为繁琐,对加工环境要求较为严苛,因此对加工场所环境的严格把控会提高普洱茶加工质量。物流过程中的频繁装卸会给茶叶带来一定损伤,采用良好的茶叶质检设备可规避质量风险,而销售阶段作为供应链的最后一环,采用良好的茶叶质检设备更显得尤为重要;③重要性指数达到0.07~0.8 区间的指标。在此区间的指标包括销售管理人员存储经验和农产品加工工艺。若销售管理人员对茶叶的存储经验不足,将会导致普洱茶变质,不同的加工工艺也会大幅影响茶叶的风味和口感,从而影响其质量;④重要性指数在0.06~0.07区间的指标。在此区间的指标包括工作人员种植经验、运输环境、生长环境及加工人员知识技能培训情况。种植阶段工作人员的种植经验和茶叶生长环境将直接影响到茶叶原材料质量,良好的运输环境可减少因碰撞或温湿度变化带来的茶叶破碎或变质。普洱茶的加工工艺特殊,因此需要对加工人员进行技能培训,才能保证生产出符合质量的茶叶;⑤重要性指数在0.05~0.06 之间的指标。在此区间的指标为农产品采摘方式、仓库存储环境及食品添加剂超标情况。茶叶采摘方式分为机器和人工两种,人工采摘的茶叶质量较高,而加工阶段的仓库存储情况则确保从原叶、半成品到成品不会因存储不当而变质。若食品添加剂过量,将会对人体造成严重影响,也必须重视。
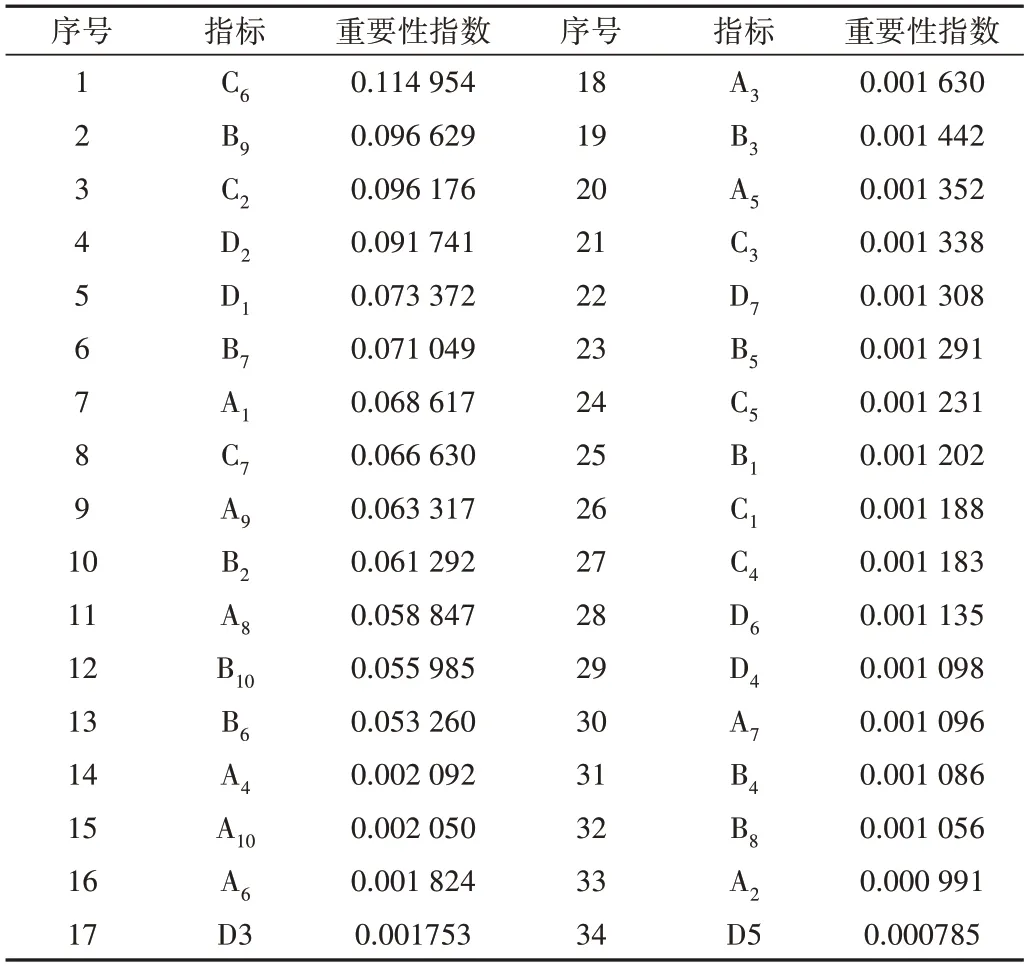
Table 4 Indicator importance table表4 指标重要性表
通过对表4 的进一步分析,可得出重要性指数超过0.05 的指标共有13 个,分别为:仓库存储环境情况(C6)、加工场所环境情况(B9)、成品质量检测设备(C2)、商品质量检测设备(D2)、销售管理人员存储经验(D1)、农产品加工工艺(B7)、工作人员种植经验(A1)、运输环境情况(C7)、生长环境情况(A9)、人员知识技能培训(B2)、农产品采摘方式(A8)、仓库存储环境情况(B10)、食品添加剂超标情况(B6)。由于其余21 个指标的重要性指数不足0.01,与上述13 个指标相比重要性较低,因此选取这13 个指标对本文分类模型进行训练,探寻各影响因素与普洱茶质量安全风险等级之间的关系。降维后得到质量安全风险评估体系,如表5所示。
3.3 基于DBN的风险评估分析
在以上运用RF 降维之后选取的样本中,将其中80%的样本数据用于训练,剩余20%用于测试,并汇总出相应等级的训练集和测试集数量,如表6所示。

Table 5 Quality and safety risk assessment system after dimension re⁃duction表5 降维后的质量安全风险评估体系
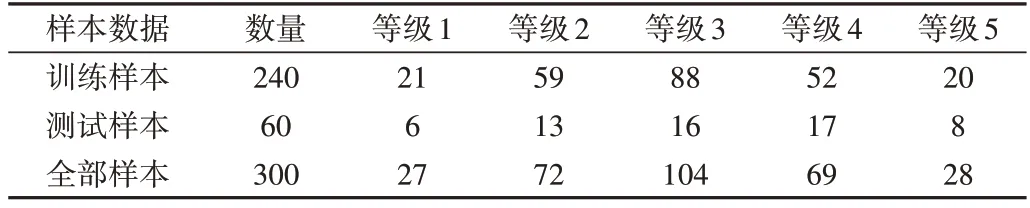
Table 6 Sample distribution表6 样本分布情况
根据3.2 中降维后的指标体系,可确定模型的输入层有13 个神经元,输出层有5 个神经元,即等级1、等级2、等级3、等级4和等级5。本文根据得到的样本数据对DBN 模型参数不断进行调整优化,分别选用两个RBM 模型进行堆叠,其隐含层中的神经元个数依次为50、35 个,并设RBM 前向学习率为0.01。根据训练样本测试不同迭代次数对DBN 模型精度的影响,不同迭代次数的DBN 精度如图6所示。
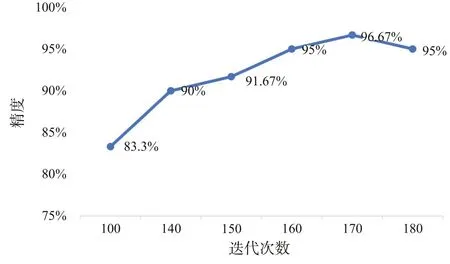
Fig.6 DBN accuracy for different iterations图6 不同迭代次数的DBN精度
由图6 可以得出,在迭代次数小于170 次时,模型精度随着迭代次数的增加而增加。当迭代次数为170 次时,精度达到最高为96.67%;当迭代次数为180 次时,模型处于过拟合状态,所以精度略有下降,且增加了迭代时间。因此,本文选择迭代次数为170次。
接下来将全部数据输入上述调整好的DBN 模型中,DBN 模型预测结果如图7 所示。由图7 可知,在普洱茶的质量安全风险分类中,实际分类结果与模型分类预测结果相差不大。
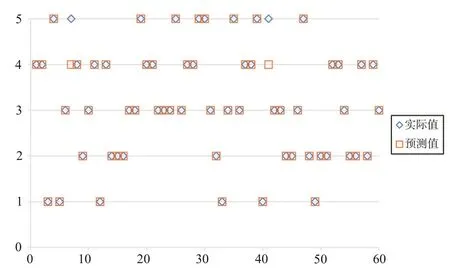
Fig.7 DBN model prediction results图7 DBN模型预测结果
分类预测汇总结果如表7 所示。由表7 可知,从等级1到等级3,分类精度高达100%,而分类错误主要出现在等级4 和等级5 中,有两组等级4 的样本被错分为等级5。该结果说明DBN 风险评估模型对普洱茶的质量安全风险有较强的分类预测能力。
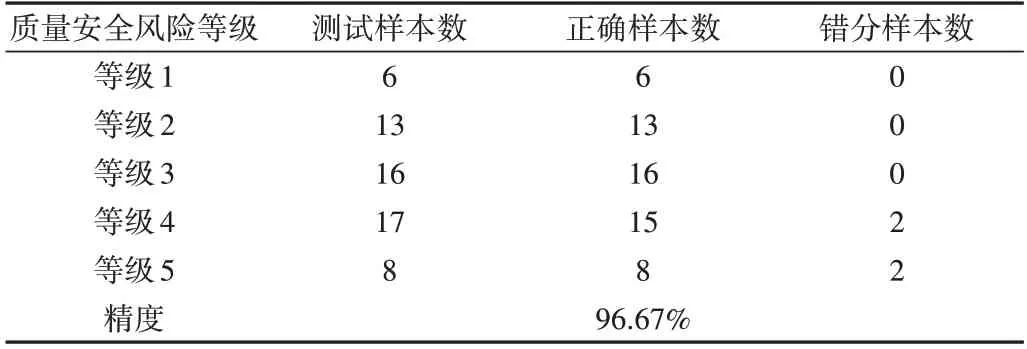
Table 7 Categorical predictions summary results表7 分类预测汇总结果
3.4 模型对比分析
反向传播神经网络(BP)具有很强的非线性映射能力,是应用最为广泛的神经网络,而支持向量机(SVM)是一种被广泛应用于数据分类问题的监督学习算法。因此,为进一步验证DBN 模型的可靠性,本文选取传统机器学习算法中的BP 神经网络和SVM 分类器分别对普洱茶质量安全风险等级进行分类测试,并对测试结果进行对比。BP 神经网络选取3 层神经网络结构,分别为输入层、隐含层和输出层。其中,输入层和输出层的神经元数量与DBN 模型一致,分别为13 和5,且迭代次数为4 000 次,激活函数为Sig⁃moid 函数。在SVM 分类器中,设置内核函数为RBF,惩罚系数为1,分类策略选择“ovr(one versus rest)”,即一对多分类。3种模型分类结果比较如表8所示。

Table 8 Comparison of classification results of three models表8 3种模型分类结果比较
由表8可知,在测试样本相同的情况下,可以得出:
(1)DBN 模型在普洱茶质量安全风险分类的60 个测试样本中,可正确分类出58 个样本,评估精度较高,可达96.67%,明显优于BP 神经网络和SVM 分类器。该结果表明,DBN 模型可有效实现对地理标志农产品质量安全的风险评估,且相较于BP 神经网络和SVM 分类器,该模型在质量安全风险等级评估与分类中具有一定优越性。
(2)BP 神经网络模型在60 个测试样本中,可正确分类出54 个样本,评估精度一般,仅为90%。BP 神经网络只有输入层、隐含层和输出层3 层网络结构,对于复杂函数关系的学习与训练能力明显低于深度神经网络DBN,所以其对普洱茶质量安全风险等级的评估结果一般。
(3)SVM 分类器在60 个测试样本中,仅正确分类出46个样本,评估精度较低,仅为85%。原因在于其最初设计为解决二值分类问题,因此在处理多分类问题时,只能间接构造合适的多分类器,无法直接解决多分类问题,所以评估结果不理想。
4 结论与建议
近年来频频爆出地理标志农产品质量安全事故,严重破坏了地理标志农产品的品牌效益与市场信誉,阻碍了农业规模化、产业化发展。本文充分利用深度学习在海量、高维数据中优秀的特征学习与提取能力,将RF 和DBN 模型引入地理标志农产品质量安全风险评估。通过实证分析,相对于传统方式,该模型具有较高的评估准确率。该研究结果为我国地理标志农产品质量评估方法的应用提供了参考。但本文研究中也存在一些不足:①由于数据获取和标量化的限制,本文只选取了部分影响地理标志农产品质量安全的因素,实际上仍存在大量未被提及的因素有待继续研究;②本文采用专家打分法获取调查数据,具有一定程度上的主观性。
后续可从以下两方面进行深入研究:①基于深度学习的地理标志农产品质量安全风险评估方法优化。RF 和DBN 只是众多机器学习算法的一个,还可进一步探索概率神经网络、无监督学习等方法;②多种风险评估方法的有机融合。任何单一的风险评估方法都有自身的优势和局限,可通过组合评价方法充分发挥各方法的优点,取长补短,从而提高风险评估的准确度。
