基于Text CNN模型的文本分类算法应用
2022-06-28万林浩
万林浩




数据准备
此处使用亚马逊评论数据集,数据集包含3.6M的文本评论内容及其标签,数据格式分为Review和Label(取值为Label1与Label2)两部分,即为二分类文本。其Github来源为:https://gist.github.com/kunalj101/ad1d9c58d338e20d09ff26bcc06c4235。
模型理论
模型选取
此处选取Text CNN模型作为深度学习模型,传统的CNN算法通常应用于CV领域,尤其是计算机视觉方向的工作。Yoon Kim在2014年 “Convolutional Neural Networks for Sentence Classification” 论文中提出Text CNN(利用卷积神经网络对文本进行分类的算法),进而人们在文本分类时也运用了卷积神经网络这一算法,为了能够更好的获得局部相关性,CNN利用多个不同的kernel提取数据集文本中的关键信息。
与图像当中CNN的网络相比,Text CNN 最大的不同便是在輸入数据的不同,图像是二维数据,图像的卷积核是从左到右,从上到下进行滑动来进行特征抽取。
而自然语言是一维数据, 因此对词向量做从左到右滑动来进行卷积没有意义。(如: “今天”对应的向量[0, 0, 0, 0, 1], 按窗口大小为 1* 2 从左到右滑动得到[0,0], [0,0], [0,0], [0, 1]这四个向量, 对应的都是“今天”这个词汇,这种滑动没有帮助。)
模型原理
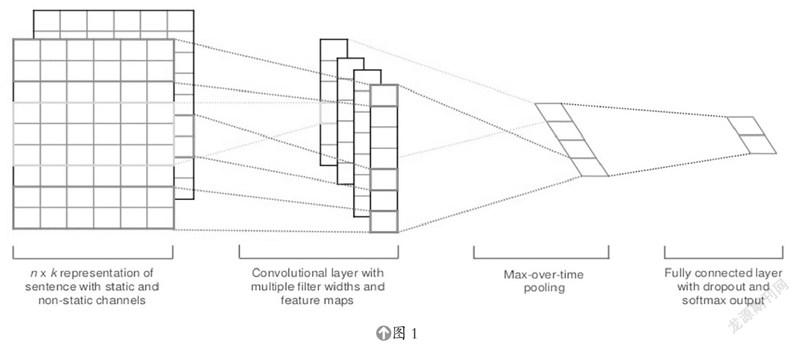
如图1所示,Text CNN的核心思想是抓取文本的局部特征:首先通过不同尺寸的卷积核来提取文本的N-gram信息,其次由最大池化层来筛选每个卷积操作所提取的最关键信息,经过拼接后在全连接层中进行特征组合,最后通过多分类损失函数来训练模型。
图2即为CNN在文本分类中的应用流程,假设对当前数据集要实施文本分析,句子中所有单词都是由N维词矢量所构成的,也就是说输入矩阵大小都是m*n,这里的m是指句子宽度。如果CNN要对输入样本实施卷积运算,针对文字信息,filter将不再侧向滑移,而仅仅向下移动,类似于n-gram在提取数字和单词之间的局部关联时。图中共有三个策略,依次是二,3,4,每种步长上都有两种filter。在各种词窗上使用各种filter,最后获得了六个卷积后的词向量。接着,对每一矢量执行最大化池化操作并拼接所有池化值,以获取单个句子的特征后,将此矢量传送到分类器上执行分组,从而实现了整个过程。
Text CNN模型的组成部分如下:
(1)输入:自然语言输入为一句话,例如:wait for the video and don’t rent it。
(2)数据预处理:首先将一句话拆分为多个词,例如将该句话分为9个词语,分别为:wait, for, the, video, and, don’t, rent, it,接着将词语转换为数字,代表该词在词典中的词索引。
(3)嵌入层: 通过word2vec或者GLOV 等embedding方法,把各个词成对反映到某个低维空间中,实质上就是特征提取器,可以在特定层次中编码语义层次特性。例如用长度为6的一维向量来表示每个词语(即词向量的维度为6),wait可以表示为[1,0,0,0,0,0,0],以此类推,这句话就可以用9*6的二维向量表示。
(4)卷积层:和一般图像处理的卷积计算核有所不同的是,所有通过词矢量表示的文字都是一维数据,所以在Text中CNN词卷积用的就是一维卷积。Text CNN卷积核的长宽与词矢量的角度相等,高度可以自行设置。以将卷积核的大小设置为[2,3]为例,由于设置了2个卷积核,所以将会得到两个向量,得到的向量大小分别为T1:8*1和T2:7*1,向量大小计算过程分别为(9-2-1)=8,(9-3-1)=7,即(词的长度-卷积核大小-1)。
(5)池化层:通过不同高度的卷积核卷积之后,输出的向量维度不同,采用1-Max-pooling将每个特征向量池化成一个值,即抽取每个特征向量的最大值表示该特征。池化完成后还需要将每个值拼接起来,得到池化层最终的特征向量,因此该句话的池化结果就为2*1。
(6)平坦层和全连接层:与CNN模型一样,先对输出池化层输出进行平坦化,再输入全连接层。为了防止过拟合,在输出层之前加上dropout防止过拟合,输出结果就为预测的文本种类。
模型建立
Word Embedding 分词构建词向量
模型的第一层为Embedding层,预训练的词嵌入可以利用其他语料库得到更多的先验知识,经过模型训练后能够抓住与当前任务最相关的文本特征。
Text CNN 首先将 “今天天气很好,出来玩”分词成“今天/天气/很好/, /出来/玩”, 通过Word2vec的embedding 方式将每个词成映射成一个5维(维数可以自己指定)词向量, 如 “今天” -> [0,0,0,0,1], “天气” ->[0,0,0,1,0], “很好” ->[0,0,1,0,0]等等。见图3。
这样做的好处主要是将自然语言数值化,方便后续的处理。从这里也可以看出不同的映射方式对最后的结果是会产生巨大的影响, 在构建完词向量后,将所有的词向量拼接起来构成一个6*5的二维矩阵,作为最初的输入。
Convolution 卷积
第二层为卷积层,在CV中常见的卷积尺寸通常是正方形,而本文的卷积形式与之不同,本文的卷积宽度等于文本Embedding后的维度,保持不变,因为每个词或字相当于一个最小的单元,不可进一步分割。而卷积核的高度可以自定义,在向下滑动的过程中,通过定义不同的窗口来提取不同的特征向量。见图4。
feature_map 也就是经过卷积后的数据,利用卷积方法可以把输入的6*5矩阵映射为一个3*1的矩阵,由于这种映射过程与特征提取的结果很类似,因此人们便把最后的输出称作feature map。一般来说在卷积之后会跟一个激活函数,在这里为了简化说明需要,我们将激活函数设置为f(x) = x
Channel 卷积核
在CNN 中常常会提到一个词channel, 图5 中Channel1与Channel2便构成了两个Channel,统称为卷积核, 从图中可观察到,Channel 不必严格一致, 每个4*5 矩阵与输入矩阵做一次卷积操作得到一个feature map。
Max-pooling 池化层
最大特性池化层,即是在从各个滑动窗口所生成的特性矢量中过滤出一些较大的特性,而后再把它们特性拼接在一起形成矢量表达式。我们也能够使用K-Max池化(选出各个特性矢量中较大的K个特点),或者说平均值池化(将特性矢量中的每一维取平均数)等,所达成的成效一般都是把不同长度的语句,经过池化就能得出某个定长的特性矢量代表。在短文本划分场景中,每一条文本里都会有若干对类型来说无用的信息,而最大平均值池化方法就能够突出最主要的关键词,以帮助模型更容易找出相应的文章类目。见图6。
Softmax k分类
Pooling的结果拼接出来,再输入到Softmax中,可以得出不同类型的概率。在练习流程中,此时会通过预计label与实际label来估算损失函数, 计算出softmax 函数,max-pooling 函数, 激活函数以及卷积核函数当中参数需要更新的梯度, 并依次更新函数中的参数,完成一轮训练。若是预测的过程,Text CNN的流程在此结束。见图7。
模型验证及评估
模型验证
(1)数据预处理
首先读取数据,通过观察数据集label标签(其取值为label1与label2),将其替换为0-1分类变量,其结果如图8所示。
(2)训练集、测试集划分
首先通过分词函数将句子划分为向量,之后通过Tokenizer函数将单个词转化为正整数。此时單个句子便变为了由数字组成的向量。最后,再将进行预处理后的数据结果集中进行划分为练习集与试验集,其比例约为7:3。其训练集数据格式如图9所示。
(3)模型训练及验证
将数据预处理后,即开始构建Text CNN模型的各个组成部分,将label进行热编码处理以便于计算,为获得较好的训练结果,将epochs参数设定为15,进行多次训练。其训练输出结果如图10所示。
此处选取Loss损失函数及预测准确率Accuracy对模型进行评估,通过建模、训练以及最后在测试集上进行验证,得到如表1的Loss以及Accuracy。
模型评估
模型优点
(1)Text CNN模型的网络结构简单,在CNN模型网络结构的基础上进行改进后,依旧具有较为简单的结构,相比于CNN并没有明显的复杂度提升。
(2)由于网络结构简化使得参数种类较小,运算量小,训练速率较快,并且有较强的可推广性。
模型缺点
由于模式可理解型不强,在调优建模过程的同时,很难按照训练的效果去有效的调节其中的特性,同时由于在TextCNN中缺乏对特性重要程度的定义,从而很难去评价各种特性的意义并加以比较。
总结
本文通过建立Text CNN模型,对亚马逊评论数据集进行了分类实战。在实际操作中,首先通过数据预处理对数据集进行了清洗以及分词划分,之后通过Keras构建了Text CNN模型的各个部分,如Embedding、Convolution、Max Polling、以及Softmax。最后进行调参以及模型验证评估,得到了评估准确率较高的模型以及参数设定组合,通过Loss与Accuracy指标的评估,本文建立的Text CNN模型具有较好的性能。
