基于双分支特征融合的无锚框目标检测算法
2022-06-25侯志强马素刚程环环范九伦
侯志强 郭 浩* 马素刚 程环环 白 玉 范九伦
①(西安邮电大学计算机学院 西安 710121)
②(陕西省网络数据分析与智能处理重点实验室 西安 710121)
1 引言
目标检测作为计算机视觉领域中的重要研究方向,一直以来都是人们关注的热点,在安防监控、车辆驾驶、军事领域等都有重要的应用[1]。
根据是否使用深度学习网络,可以将目标检测分为传统的目标检测算法和基于深度学习的目标检测算法。传统的目标检测算法通常利用方向梯度直方图特征(Histogram of Oriented Gradient,HOG)或尺度不变特征变换(Scale Invariant Feature Transform, SIFT)来识别目标,但均存在着处理数据量大、实时性不高等缺点。在基于深度学习的目标检测算法中,双阶段算法Faster R-CNN(Regions with Convolution Neural Network features)[2]引入Anchor概念,即以待检测位置为中心,指定的大小和高宽比所构成的锚框,从而生成大量区域建议框来进行训练。单阶段算法YOLOv3(You Only Look Once version 3), SSD(Single Shot multibox Detector)[3]均采用了锚点框来确保与目标有更大的重叠率,提高检测精度。但是大量的锚点框中只有少部分能和真实的标签框重叠,造成正负样本不均衡,从而减缓了训练过程。其次,训练过程中存在复杂的超参数设计,如框的数量、大小和宽高比。
为了解决上述问题,Anchor-free的无锚框目标检测算法逐渐兴起。CornerNet[4]算法去除了锚点框的使用,将目标检测转化为2个关键点匹配的问题,ExtremeNet[5]算法利用了上下左右4个极值点和1个中心点来确定目标,FCOS(Fully Convolutional One Stage)[6]算法引入图像分割的思想,针对每个像素都进行预测,得到该像素到检测框的4个边框的距离,最终输出整体目标的检测框,但以上算法的运行速度均不够理想。
在无锚框检测方法中,CenterNet[7]算法将每个目标视为1个中心点,通过网络预测每个中心点的位置,然后直接回归出目标的宽高和具体类别。算法的思想简洁明了,结构清晰,无需非极大值抑制操作,在速度上有了保证。但该算法在使用Res-Net作为主干网络时,只利用其最后1层特征进行处理,而特征在32倍下采样后,许多原图中本来占有较小空间的目标将会在特征图上消失,从而造成目标的漏检。
针对此问题,本文基于CenterNet,提出一种双分支特征融合的无锚框目标检测算法 (Center-Net with Double Branch feature fusion, DB-CenterNet),算法对编码网络和解码网络均有不同的设计。首先,对编码网络中的主干网络添加基于DCT频率域的通道注意力机制来增强特征提取能力;其次,对解码网络的整体结构进行重构,利用特征金字塔增强模块和特征融合模块搭建新的网络分支,将主干网络中的4层特征进行多次上采样和下采样处理,更好地利用浅层特征的空间信息和深层特征的语义信息,从而达到更优的检测效果。实验表明,本文算法在PASCAL VOC和KITTI数据集上的检测精度较原算法分别提升3.6%和6%,同时检测速度满足实时性要求。
2 双分支特征融合的无锚框目标检测算法DB-CenterNet
2.1 CenterNet目标检测算法
如图1所示,基于ResNet的CenterNet算法由编码网络、解码网络和检测头3个部分构成。编码网络提取图像特征,而解码网络对提取到的特征进行多次上采样处理,再将其输入检测头预测中心关键点的热力图、目标框的宽和高以及中心点的偏移量。
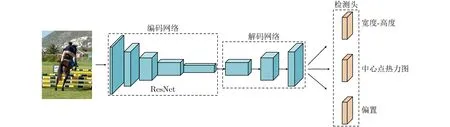
图1 CenterNet算法结构图
定义图像I∈RW×H×3,W表示图像的宽,H表示图像的高。算法利用真实标签框的中心点来表示目标信息,并将此中心关键点用于网络训练。真实的中心关键点p先进行下采样并取整,下采样后的坐标为p˜=p/R,再将所有下采样后的中心关键点利用高斯核的形式分布到特征图上,其中R表示下采样倍数并取为4,C表示关键点的类型数,在本文中当作目标的类别数,高斯核为

2.2 多特征融合分支设计
特征金字塔融合系列模块如PANet(Path Aggregation Network), ASFF(Adaptively Spatial Feature Fusion)和BiFPN(Bidirectional Feature Pyramid Network)等,由于过多的融合次数和计算方式会产生大量的参数,从而明显地降低算法的速度。受文本检测领域中像素聚合网络[8]的启发,引入特征金字塔增强模块(Feature Pyramid Enhancement Module, FPEM)和特征融合模块(Feature Fusion Module,FFM)来构建轻量级的特征处理分支,具体如图2、图3所示。
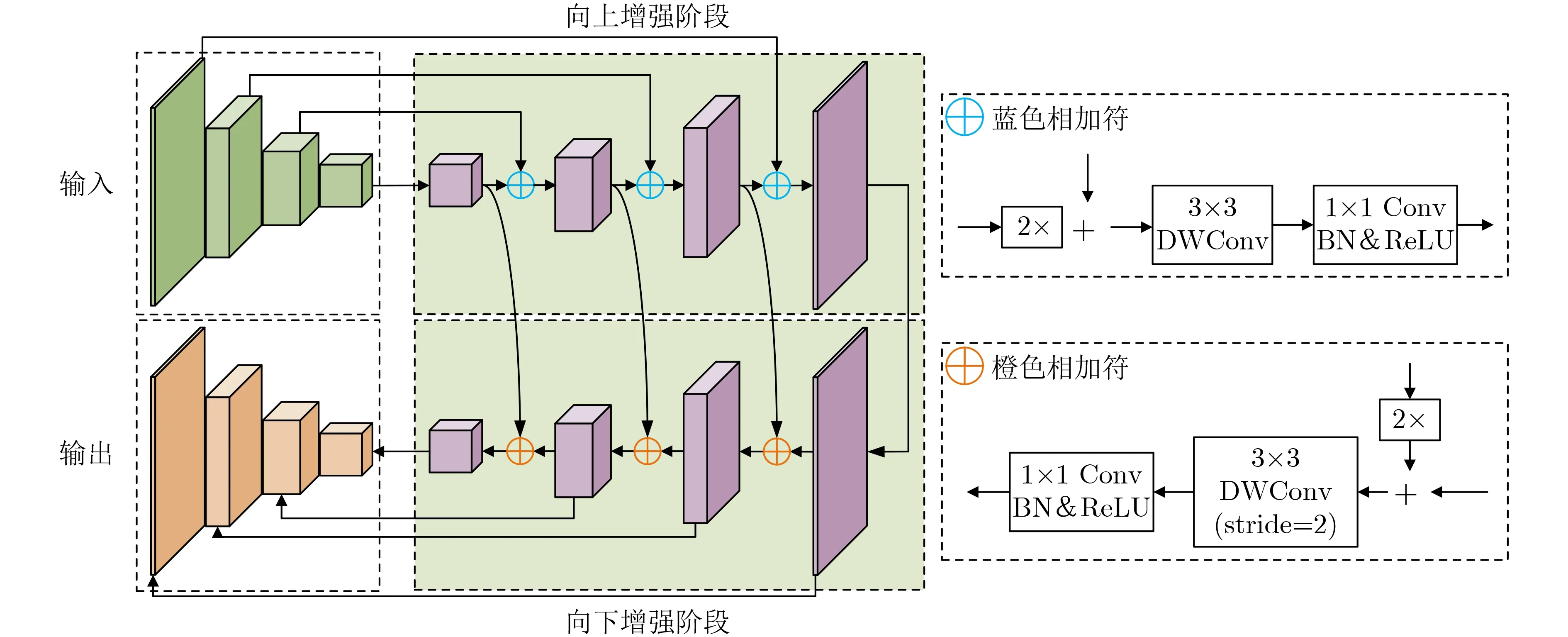
图2 特征金字塔增强模块FPEM
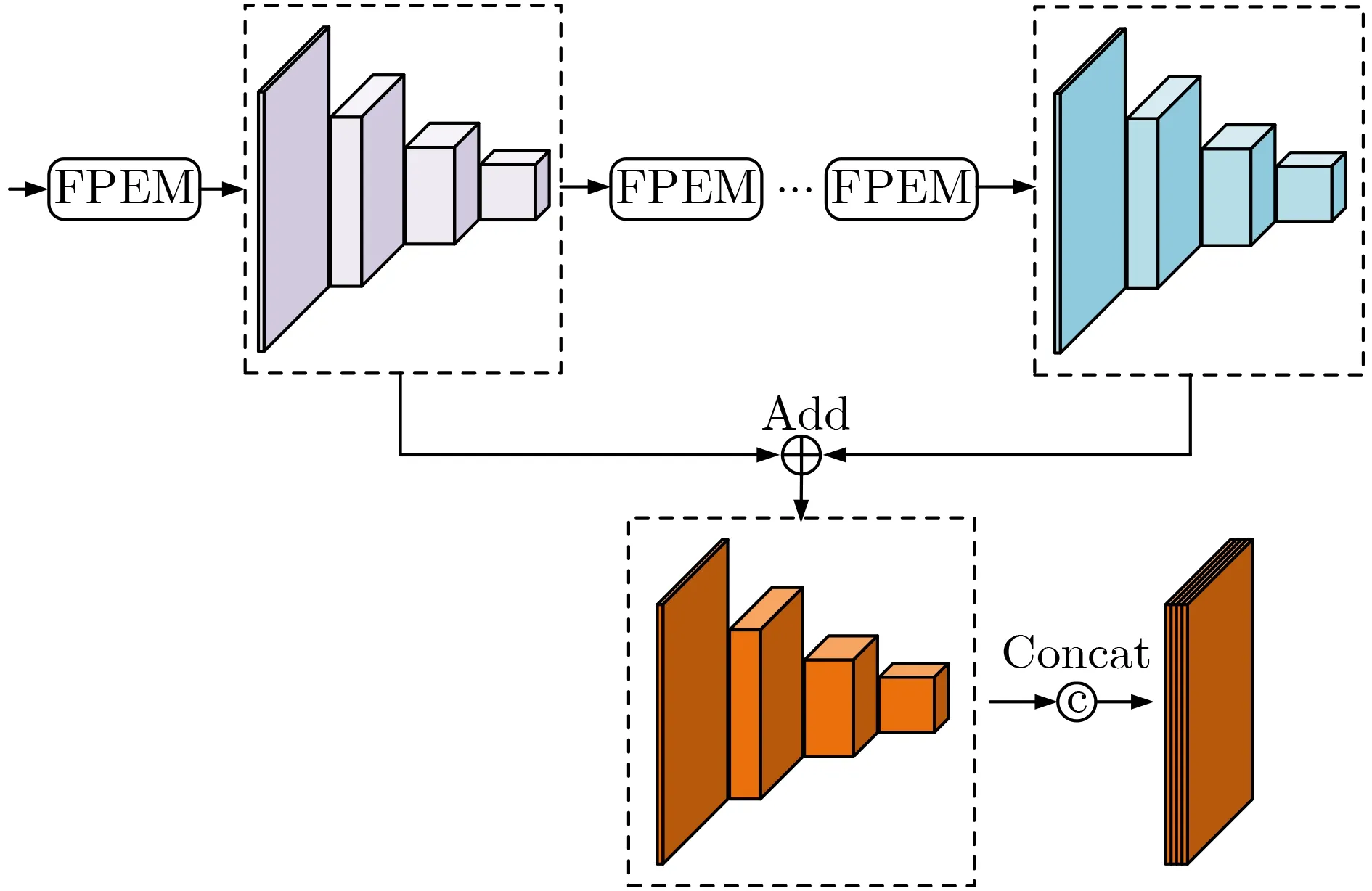
图3 特征融合模块FFM
深度可分离卷积[9]所产生的参数总量与普通卷积之比为


FFM的输入为两组特征,第1种是由主干网络的4层特征经过1次FPEM后构成的特征组,第2种是将增强后的特征组再经过若干个FPEM的特征组。FFM将这特征组中大小相同的子特征图对应元素相加,再将相加后的特征上采样到同样大小,最后进行通道拼接。
2.3 基于DCT频率域的通道注意力机制
在众多的通道注意力模块中,如C B A M(Convolutional Block Attention Module), SENet(Squeeze and Excitation Network),通常使用全局平均池化(Global Average Pooling, GAP)来获得每一个通道的全局信息。然而通道总体的平均值信息不足以代表每个单独通道的个体性,会损失丰富的局部信息,导致特征缺乏多样性。
针对上述问题,本文在ResNet中引入频率通道注意力网络FcaNet[10]来提取通道中不同的局部信息。FcaNet从频率角度出发,证明出GAP仅等价于离散余弦变换(Discrete Cosine Transform,DCT)的最低频率分量,而仅仅使用此分量表达的特征信息明显不足。因此,FcaNet采用2维的DCT来融合多个频率分量,对重要信息进行加权并抑制背景信息。
首先,把图像的特征分为n等份,通道数为C′,每份特征经过2维DCT变换输出频率特征,f2d ∈RH×W表示2维DCT频率的频谱,x2d ∈RH×W表示特征图输入,H为特征图的高,W为特征图的宽,2维DCT变换和逆2维DCT变换公式为


图4 基于DCT频率域的通道注意力机制
2.4 算法整体框架
本文算法结构分为主干编码网络、解码网络和检测头共3个部分。编码网络采用ResNet-101作为主干,利用基于DCT频率域的通道注意力机制FcaNet引入更多频率分量,从而引入更多的特征信息,以增加网络提取到特征的丰富性,解码网络由多特征融合分支和上采样分支构成。


图5 通道削减模块RCM结构图


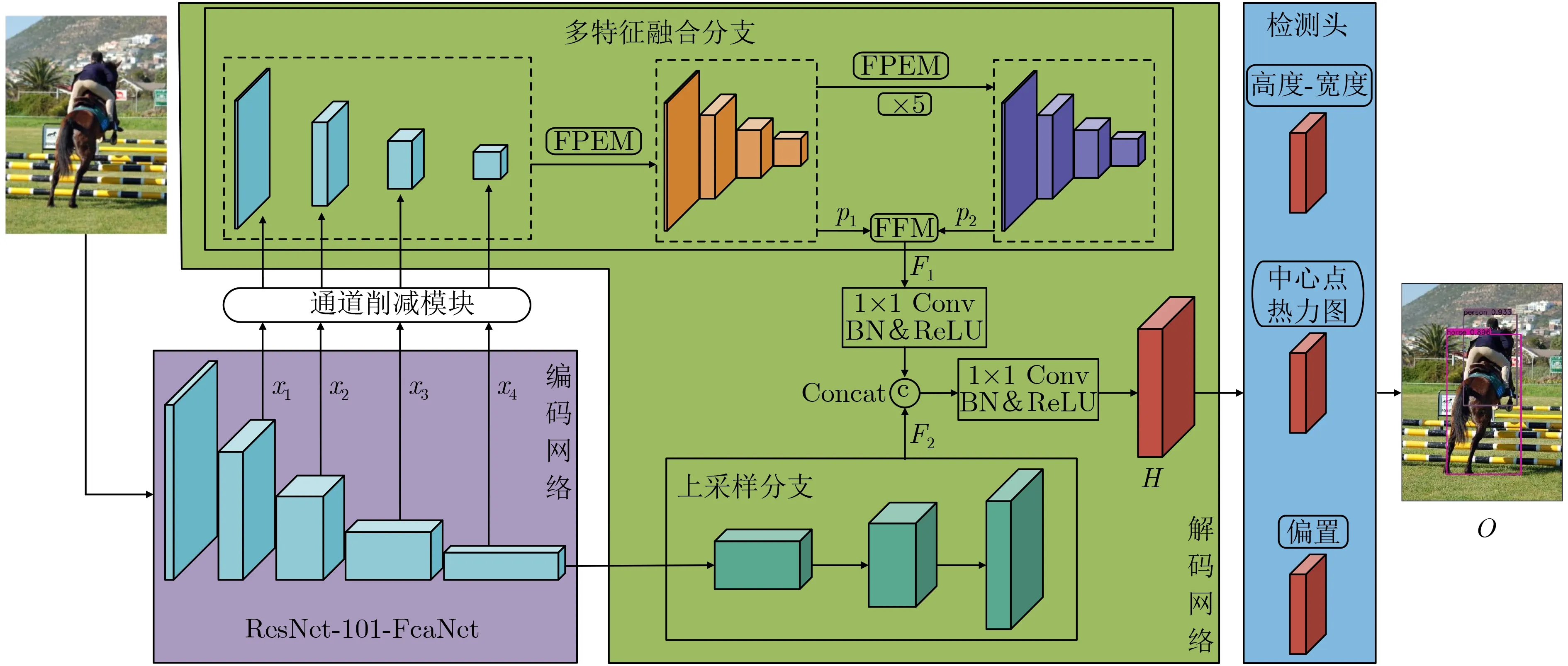
图6 DB-CenterNet算法结构图
3 实验结果与分析
3.1 实验设置
实验环境:操作系统为Ubuntu 16.04,CPU为i5-8400,GPU为单张NVIDIA TITAN Xp,深度学习框架为PyTorch 1.1.0,CUDA 版本为10.0。
数据集:本文采用了两种数据集,第1种为公开基准数据集PASCAL VOC 2007和PASCAL VOC 2012的组合,包含训练图像16551张,测试图像4952张,目标类别数为20。第2种为目前国际上最大的自动驾驶场景下的计算机视觉算法评测数据集KITTI,其拥有7481张图片,本文将其分为训练集5984张,测试集1497张,目标类别数为3。
训练细节:初始学习率取0.000125,采用SGD优化器,利用FcaNet在ImageNet上预训练模型初始化主干网络参数。在前2个Epoch中采用线性学习率预热,在第90 Epoch和120 Epoch时分别下降为当前学习率的1/10,训练150个Epoch,Batch Size设置为8。
评价指标:实验使用的算法评价指标是类别平均精度(mean Average Precision, mAP)和每秒帧数(frames per second, fps)。交并比IoU的阈值为0.5,当IoU>0.5时表示检测成功,其中mAP指的是所有单体类别精度之和的平均值,fps代表了每秒检测图片的数量,能够有效反映出算法的检测速度。
3.2 消融实验
为测试不同注意力模块对检测性能的影响,本文做了如下实验,具体如图7所示。实验结果表明,在采用FcaNet时,检测效果较好。针对FPEM增强次数的不同,本文做了如表1所示的实验,由于计算开销的限制,只测试到第7次。实验结果表明,采用特征增强5次的多特征融合分支具有较好的鲁棒性,算法综合检测结果如表2所示,其中加粗数据表示当前情况下最好的结果。

表1 不同特征增强次数的消融实验结果(%)
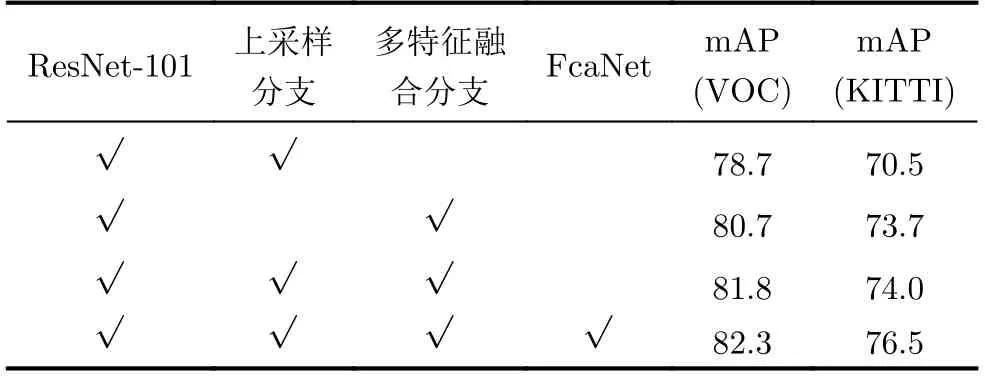
表2 PASCAL VOC2007和KITTI数据集的消融实验结果(%)

图7 不同编码网络的检测性能
3.3 定性分析
3.3.1 PASCAL VOC数据集
如图8所示,为说明本文算法的检测性能,将原始CenterNet检测算法的检测结果与本文算法进行对比,选取部分具有明显代表性的图片进行说明。在第1行图中,CenterNet算法和本文算法都能检测到目标物体,但本文算法的目标框位置更准确,置信度分数更高。在第2行图中,CenterNet算法漏检了瓶子,本文算法能够给出较好的检测结果。在第3行图中,CenterNet算法将卡车误检为“公交车”,而且漏检1辆车,本文算法在此给出了较好的判断,未误检为“公交车”,同时检测出小车的位置。在第3、4行图中,本文算法都能很好地检测出较小的目标,尤其在第4行组图中,真实标签只标记了1个大人和1个小孩,并未标记汽车左下角位置较小的小孩,本文算法也能检测到此目标并给出一定的置信度分数,且总体的置信度分数和目标框的准确度均高于原算法。

图8 PASCAL VOC上的实验对比结果
实验表明本文算法在复杂场景中的漏检率和误检率更低,对于小目标有较好的检测效果,并且在检测同一类物体时,可以给出更高的置信度分数。
3.3.2 KITTI数据集
检测效果如图9所示。在第1行图中,本文算法均检测到了真实标签中的目标并给出了更高的置信度分数,而CenterNet算法存在漏检情况。在第2行图中,CenterNet算法也存在着误检和漏检现象,将左下角的目标检测为“car”,而在图片右角的车辆,本文算法给出了较好的检测,原算法漏检了此目标。

图9 KITTI上的实验对比结果
3.4 定量分析
3.4.1 PASCAL VOC数据集
(1)本文算法和主流算法在整体性能上的比较
本文算法在目前主流的目标检测算法中,优势表现明显,具体结果如表3所示。在整体性能方面,本算法做到了精度和速度的较好平衡,对比于原算法,损失了较少的帧数却得到了3.6%的精度提升,整体检测精度达到82.3%,检测速度达到27.6 fps,而对比于其他算法,一部分存在速度快而精度低的问题,较为典型的算法有SSD, CenterNet-ResNet-18等;一部分存在精度高而速度过慢的问题,较为明显的算法有R-FCN, DSSD, ExtremeNet,CenterNet-Hourglass-104等。对于原算法在采用同样层数的主干网络ResNet时,mAP提高了3.6%,较原算法其他两种主干网络深度聚合网络DLA-34和沙漏网络Hourglass-104在精度方面分别提高了1.6%和1.4%,相比于R-FCN, SSD, YOLOv3,FCOS, ExtremeNet, CenterNet-DHRNet[11]分别提高了1.8%, 5.5%, 3%, 2.1%, 2.8%, 0.4%。

表3 PASCAL VOC2007数据集测试结果
(2)本文算法和其他算法在单类上的比较
各类具体的mAP如表4所示,结果表明本文算法在10类上能够达到最优水平。其中在飞机、鸟、瓶子、羊、火车、电视等多种单体类别的目标检测精度较其他算法都具有2%以上的优势,在尺度较小的“bottle”和数据量少的“plant”上,本文算法也达到了最优。
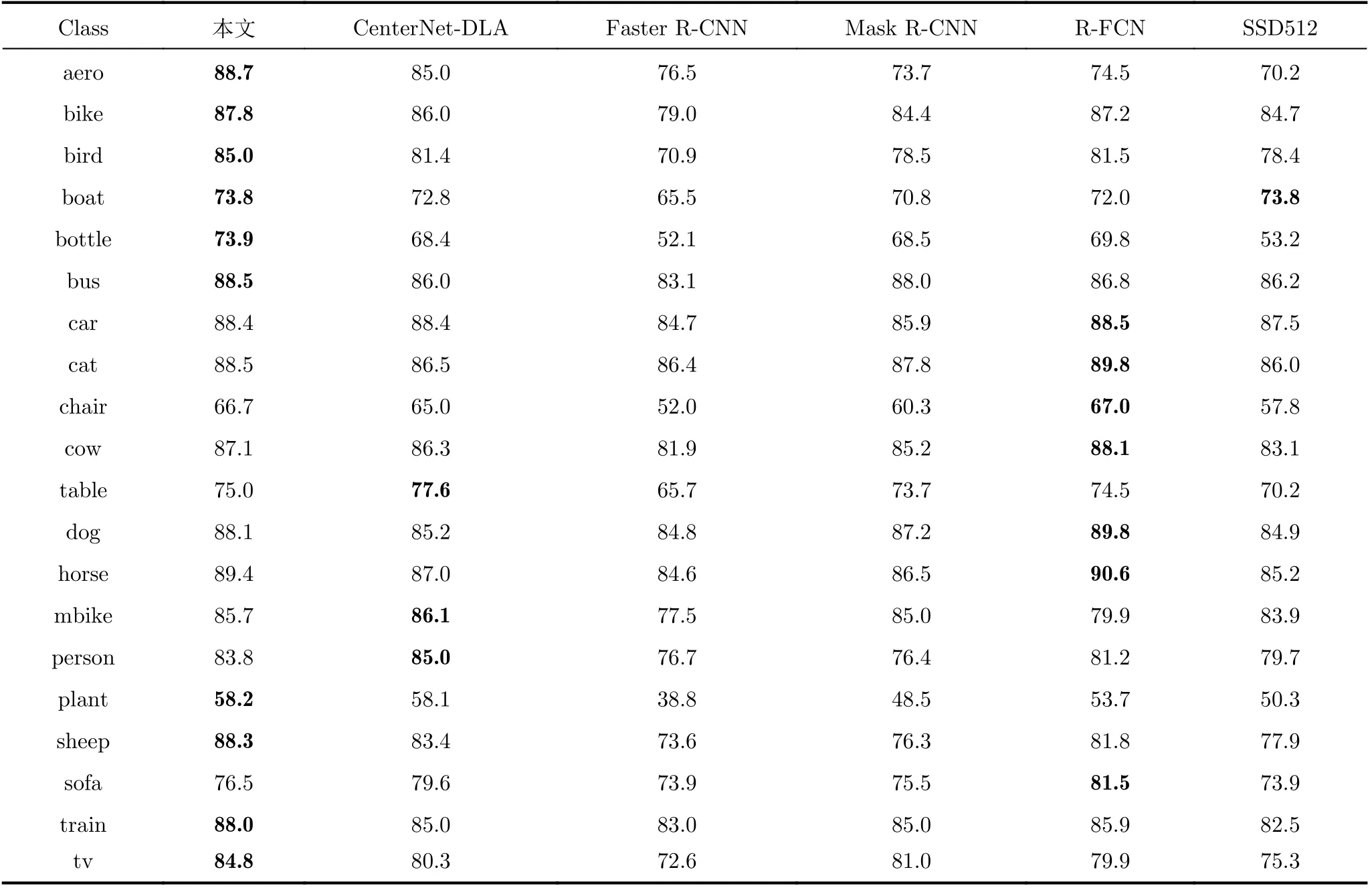
表4 本文算法和其他算法在PASCAL VOC2007数据集上各类的检测结果(%)
3.4.2 KITTI数据集
由表5得知,本文算法在每一类上的检测精度均高于CenterNet算法,在车和骑自行车的人这两类上的提升较大,分别提升7.6%和9%。本文算法的mAP较原算法提升6%,比SSD, RFBNet[12],Yolov3检测平均精度分别高15.3%, 3.1%和0.7%,速度和精度领先于SqueezeDet[13], FCOS, Yolov3等算法;针对不同的主干网络,也体现出较明显的精度优势。

表5 KITTI数据集上综合的检测结果
4 结束语
本文提出了一种基于双分支特征融合的无锚框目标检测算法DB-CenterNet,最终在PASCAL VOC数据集和KITTI数据集上效果显著。算法主要对于特征的融合方式以及利用方式进行改进,达到了较好的检测效果,在实验过程中,本文算法对于尺度更小的目标或具有被严重遮挡的目标检测性能并不高,并且存在一定的误检问题,在后续的研究过程中会考虑使用更好的融合策略或目标框回归策略来进一步提高算法的性能。
