基于共同邻居相似度的改进标签传播算法
2022-06-24刘井莲于丽萍吴亚明李显凯赵卫绩
刘井莲,于丽萍,吴亚明,李显凯,赵卫绩
社区结构作为社会网络中一种重要结构特征,具有网络中同一群组内连接紧密而不同群组间节点连接松散的特性[1-2].社会网络中的社区发现研究具有重要的理论意义和实际应用价值,社区发现可以揭示具有共同兴趣爱好、共同教育、工作背景或其他共同特征的社会团体,也可以揭示一些关联紧密的在线社会资源或商品信息,例如,在社交网络中,社区发现可以揭示具有共同兴趣、共同话题的社会团体;在电子商务网络中,社区发现可以找到一些相互关联的商品或相似购买倾向的消费者群体[3-5].2002 年,GIRVAN 和NEWMAN 提出社区发现GN 算法[1],掀起了社区发现的研究热潮.社区发现吸引了计算机学科、数学学科、社会学科等领域学者的广泛关注,出现了包括GN 改进算法、模块度优化算法、标签传播算法在内的诸多研究成果.
标签传播算法作为一种重要的社区发现方法,能够在较低时间复杂度的条件下取得较好的社区划分结果,吸引了一些学者的极大关注,研究出许多改进的标签传播社区发现 算法[6-9].2007 年,RAGHAVAN 等 以网络 结构作为指导,首次提出基于标签传播的社区发现算法,该算法通过对网络中每个节点都初始化一个唯一的标签,在迭代过程中,每个节点都采用它的大多数邻居目前拥有的标签,通过不断的进行迭代,密集连接的节点群更倾向于获得相同的标签,从而形成具有相同标签的社区,该算法不需要优化预先定义的目标函数,也不需要社区先验信息,算法在计算时间上几乎是线性的,具有较好的时间效率[6].张鑫等[7]通过对标签初始化、随机队列设置和标签传播中随机选择过程进行了改进,给出一种稳定的标签传播社区发现算法,解决标签传播算法随机性导致社区发现结果相差较大的问题.邓凯旋等[8]给出一种基于标签传播能力的改进LPA 算法,该算法利用节点重要性分析标签传播算法中的标签传播能力,通过节点重要性排序和标签传播能力制定新的标签更新策略,划分出最终社区.郑文萍等[9]针对标签传播算法有很强的随机性而导致的社区发现算法结果不稳定的问题,提出了一种基于随机游走的改进标签传播算法.该算法不再使用随机产生的节点序列,而是通过随机游走确定节点重要性的排序,根据重要性由高到低构造节点序列,进而获得较好的社区划分结果.标签传播算法具有不需要社区的先验信息且运行速度快的优点,但存在随机性强、结果不稳定的问题.针对该问题,本文提出一种基于共同邻居节点相似度的改进标签传播算法LPACN.该算法降低了标签选择的随机性,提高了算法的稳定性.在4 个被广泛使用的基准网络数据集上进行了对比实验,实验结果表明本文提出的LPACN算法能够得到更好的社区划分.
1 相关工作介绍
1.1 社区发现问题定义
通常采用网络数据结构G=(V,E)来建模现实世界中的很多系统,用网络的节点表示实体,用边表示实体之间的关系,网络G中节点的集合表示为V,G中边的集合表示为E.例如社交网络、科学家协作网络、电子商务平台中用户和商品之间构成的多关系系统等都可以采用网络这一结构来表示.
社区是网络中的一个内部连接紧密的连通子图,社区发现就是将网络G分为多个连通子图V1,V2,…,Vm,这些子图内部连接紧密,而子图间连接稀疏,即社区结构C={V1,V2,…,Vm},m表示社区的个数.图1 所示为一个具有三个社区的网络结构.
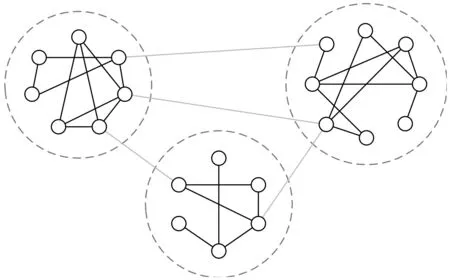
图1 网络的社区结构[1]
社区发现是网络分析领域中的一个基础问题,学者们从层次聚类、划分聚类、标签传播、谱聚类等不同视角提出了很多社区发现算法.对于社区的定义往往依赖于实际应用,将社区看作是内部节点之间边数连接紧密的子图.很多情况下社区是算法的一个计算结果.
为了评价社区结构的好坏,学者们提出了多种衡量社区发现算法准确度的评价指标,其中最著名的社区评价指标是模块度Q[1].

式中:m为网络中边的个数;Aij为邻接矩阵A中的元素,若节点i,j相连,则Aij=1,否则Aij=0;Ci为节点i所属的社区;节点j所属的社区Cj与节点i所属的社区Ci相同时,δ(Ci,Cj)取值为1,否则为0;di是节点i的度表示在随机网络中节点i和节点j之间存在连边的可能性.社区内部边的比例越大,即网络中的社区结构越明显,模块度Q取值越大.
此外,还有ARI、NMI 等评价指标也被广泛地用于评价社区划分的准确性.指标的具体计算方法可参考文献[3].
观察术后两组患者常见并发症的发生情况、疼痛程度及心理状态。疼痛采用数字分级法(NRS)评估,分为无痛(0分)、轻度疼痛(1~3分)、中度疼痛(4~6分)、重度疼痛(7~10分)[7]。心理状态采用Zung的焦虑自评量表(SAS)评估,<50分表示正常,50~59分为轻度焦虑,60~69分为中度焦虑,≥70分为重度焦虑[8]。
1.2 基于标签传播的社区发现算法
2002 年,GIRVAN 和NEWMAN 提 出 社 区结构以来,产生了层次聚类、划分聚类、谱聚类、标签传播等算法.其中标签传播算法具有时间复杂度低、不需要预先知道社区个数和规模等信息等优点,成为了一类重要的社区发现算法.基于标签传播的社区发现算法具有不需要社区的先验信息且运行速度快的特点.其基本思路是将网络中每个节点作为中心节点进行迭代标签更新,迭代过程中利用邻居节点已知的标签信息预测待更新的中心节点标签,核心思想是将每个节点的标签更新为最多数量的邻居节点的标签[6,10].算法的基本步骤如下:
①为每个节点初始化一个唯一的标签;
②按照随机顺序遍历所有的节点,每个节点的标签更新为其最大数量邻居所拥有的标签;
③当所有节点的标签与其最大数量的邻居拥有的标签都相同时,进行步骤④,否则返回步骤②;
④最后,将网络中每一个具有相同标签的连通部分作为一个社区.
通过以上算法描述可以发现,标签传播算法具有实现简单、时间复杂度低的优点,但是在计算过程中由于存在随机性且忽略了邻居节点与当前节点的相似度不同,导致即使同样的初始条件,算法发现的社区结构可能不一致.
2 基于共同邻居相似度的改进标签传播算法
节点间的相似度度量是复杂网络中的一个重要问题,在社交网络中的好友推荐、链路预测等问题中有重要应用.文献[11]在多个数据集上对比了9 种节点相似度度量指标,实验结果表明基于共同邻居CN的节点相似度度量指标在这种数据集上都具有优异的表现.因此,本算法采用基于共同邻居CN的度量方法来衡量节点间的相似度.CN指标方法计算如下:

式中:u,v分别为网络G中的节点,G(u)表示节点u的邻居节点集,节点u和v的相似度CN指标度量的是其共同邻居节点的个数.这与社交网络中两个用户的共同朋友越多,其关系的紧密型越强相吻合.
为了降低标签传播时的随机性,在选择邻居节点中出现次数最多的标签时,LPACN算法充分考虑邻居节点与当前节点的相似度,将其作为该邻居节点标签的权重,即当前节点与和它相似度越高的邻居节点的标签相同的可能性越大.LPACN 算法的基本思想描述如下:
①给网络中的每个节点赋予唯一的初始标签;
②随机产生一个网络节点的序列;
③对节点序列中的节点进行遍历,将邻居节点中出现加权次数最高的标签作为当前节点的标签;
④重复步骤②~③,直至所有节点的标签达到稳定.
LPACN 算法描述如算法1 所示.

3 实验与结果分析
为了测试本文所提出的基于共同邻居相似度的改进标签传播算法的有效性,分别在经典数据集Karate[12]、Fooball[1]、Dolphins[13-14]和Polbooks[15]4 个基准网络上进行了实验.
Karate 关系网[12].经典数据集Karate 关系网络是美国大学空手道俱乐部成员间的社会关系网,该网络图中包含34 个节点,78 条边,其中每个节点表示一个俱乐部成员,节点间连接边表示两个成员之间经常在一起参加俱乐部活动,在该俱乐部,因为主管节点34 和教练节点1 之间发生分歧而分裂成两个俱乐部.
Football 足 球 联 赛 关 系 网[1].Football 是 美国大学生2000 赛季的足球联赛关系网,联赛中有115 支球队,球队之间共进行613 场比赛,而联赛中存在12 个联盟,每个球队都属于一个联盟,一般而言一个联盟内的球队间比赛场次多于不同联盟球队间的比赛场次.
Dolphins 海豚关系网[13-14].海豚关系网是社会网络分析中的一个真实网络,常用于测试社区发现算法的有效性.这是LUSSEAU 等人对栖息在新西兰Doubtful Sound 峡湾的62只宽吻海豚群体进行长达7 年的观察所构造出来的关系网,包括62 个节点和159 条边,每个节点代表一个海豚,边表示两个海豚之间接触频繁.
Polbooks 关系网络[15].Polbooks 数据集也是社会网络分析中一个经典数据,该数据集是KREBS 从Amazon 上销售的美国政治相关书籍页面上建立起来的关系网络,包括105 个节点,441 条边.节点表示在Amazon 在线书店上销售的美国政治相关图书,边代表读者同时购买了这两本图书.
将本文提出的算法在上述4 个经典数据集上与典型的标签传播算法LPA 进行对比实验,采用被广泛使用的模块度Q、ARI(Adjust Rand Index)和NMI(Normalized Mutual Information)三个度量指标比较,实验结果如图2 所示.

图2 算法在基准数据集上的实验结果
从图2 可以看出,在Karate 数据集上,改进标签传播算法LPACN 的ARI 和NMI 两个指标值明显高于传统标签传播算法LPA,两者的Q 指标值相差无几.在Football 数据集上,LPACN 算 法 的ARI、NMI 和Q 指 标 值 均 高 于LPA 算法.在Dolphins 数据集上,LPACN 算法的ARI、NMI 和Q 指标值均高于LPA 算法.在Polbooks 数 据 集 上,LPACN 算 法 的ARI 和NMI指标值高于LPA,两者的Q 指标值相差无几.
综合以上结果分析,可以得出基于共同邻居相似度的改进标签传播算法LPACN 在三个数据集上的表现优于LPA 算法.
4 结语
针对传统标签传播算法随机性强导致社区发现结果稳定性差的问题,本文通过引入当前节点与邻居节点的相似度的方法,提出一种基于共同邻居相似度的改进标签传播算法LPACN,通过将邻居节点与该节点的相似度一并考虑,降低了标签选择的随机性,提高了算法的稳定性.在4 个著名的基准网络数据集上进行对比实验,实验结果验证了本文算法的有效性.
