安全性可控的生成式文本隐写算法
2022-06-24梅佳蒙任延珍王丽娜
梅佳蒙,任延珍,王丽娜
(1. 空天信息安全与可信计算教育部重点实验室,湖北 武汉 430072;2. 武汉大学国家网络安全学院,湖北 武汉 430072)
0 引言
文本是人类使用最早、使用频率最高的通信方式,在长期的历史发展中,形成了复杂的语义语法规则,保证了信息传递的准确性和有效性。文本内容的语义歧义和信息冗余较少,一个字的差别就会导致截然不同的语义。尽管与其他的多媒体载体相比,以文本为载体的隐蔽信道隐写容量较小,但文本作为最基本的信息交流手段,使用频率高,具有在隐蔽通信中信息无损传输的优势,已成为信息隐藏技术新的优质载体。
传统的文本隐写技术[1-4]通常是基于文本内容或文本表现形式等信息的编辑修改方法,在嵌入容量和安全性上有明显不足。生成式文本隐写算法利用输出的概率分布来建立生成词与待嵌入秘密信息之间的映射关系,完成秘密信息的嵌入,具有文本语言模型保持一致的特性,得到了广泛研究。基于生成模型的文本隐写方法包含两大类:基于统计模型的文本隐写和基于深度神经网络的文本隐写。
早期的生成式文本隐写算法利用统计模型,如马尔可夫链,对特定语料库进行建模。文献[5-7]利用马尔可夫链的无记忆性和时不变性对随机过程进行建模,并提出不同的转移状态映射了不同的秘密信息。Yang等[8]提出在语言模型输出的概率分布和秘密信息之间使用哈夫曼编码的映射方式,提升了生成文本的安全性。
基于深度神经网络的生成式文本隐写算法常用的语言模型有基于循环神经网络[9](RNN,recurrent neural network)的生成模型、基于变分自编码器[10](VAE,variational auto-encoder)的生成模型、基于Transformer[11-13]的生成模型、基于生成对抗网络[14](GAN,generative adversarial network)的生成模型等。此类隐写模型的基本原理如图1所示,包含文本生成模型、候选池概率分布截断和映射嵌入算法3个关键部分。在生成一段文本的过程中,需要将秘密信息映射嵌入每个生成词中。这些模型生成的隐写文本在隐蔽性和统计安全性的各项指标(如KL散度、困惑度)上明显优于传统的语言模型。Fang等[15]使用了块状编码,对候选池预先分块(block-based)建立生成词与秘密信息之间的映射关系,语言模型上采用长短期记忆神经网络(LSTM,long short-term memory)。Yang等[16]基于双层LSTM语言模型建立了一个生成式文本隐写对话系统。Yang等[17]使用LSTM语言模型,利用哈夫曼编码[18]在隐写容量得到保证的情况下大幅降低了生成文本的困惑度 (perplexity),使用哈夫曼编码时需要对候选池中的单词进行降序排列,选择前k个单词作为新的候选池,建立与秘密信息的映射关系。Dai等[19]在Yang等[17]的基础上,使用GPT-2-117M预训练语言模型[12-13,20],提出了patient-Huffman的映射嵌入算法,牺牲隐写容量换取了部分统计安全性。Ziegler等[21]和Shen等[22]在映射嵌入算法上选择了算术编码[23],大幅提升了生成文本的安全性。
生成式文本隐写算法中的候选池截断策略对生成文本的隐蔽性、容量和统计安全性有显著的影响。现有方法的候选池截断策略通常采用top-k[24-25]或top-p[26]截断。固定数量的top-k或固定概率的top-p在待生成词候选池的概率分布过于集中(over-concentrated)或者过于平坦(over-flat)时,会导致生成词的隐蔽性或者统计安全性产生异常。当候选池词概率分布过于集中时,映射嵌入算法强制选择概率较低的词,使困惑度增加;而过于平坦时,有些概率并不低的词不在新的候选池内,使前后两个候选池的概率分布差异过大,导致KL散度增加。
本文针对以上问题,考虑到不同生成词时刻神经网络语言模型输出概率分布之间的差异,提出安全性可控的生成式文本隐写算法,该算法基于困惑度和KL散度的参数约束,生成过程直接受控于评价指标(困惑度和KL散度),自适应地选择合适的k值,使生成文本安全性可控。并且,本文算法能够兼顾困惑度和KL散度两个指标,使生成文本拥有更好的隐蔽性和统计安全性。
1 相关工作
1.1 文本隐写算法的安全性
文本隐写算法的安全性是指生成的文本不被检测出存在隐写信息的性能,包括统计安全性和隐蔽性,统计安全性使用KL散度(KL-divergence)衡量,隐蔽性使用困惑度衡量。KL散度表示两个不同分布之间的差异,在衡量生成文本质量时表示原有语言模型生成文本(cover)的概率分布P(cover)和具有嵌入秘密信息语言模型生成的文本(stego)的概率分布P(stego)之间的差异。KL散度定义如式(1)所示。

P(x)是输入单词的联合概率分布,待输出单词的条件概率分布是P(xi+1|x1,x2,…,xi)。第i+1个单词是取决于前i个词的结果。当D(Pcover||Pstego)<ε时,表示该隐写算法是ε不可感知的;当D(Pcover||Pstego)=0时,表示该文本隐写算法是绝对不可感知的。
困惑度是NLP领域中评价生成文本隐蔽性的指标,其定义为每个单词在数据集上的平均log概率,如式(2)所示,反映了语言模型生成文本的概率分布和训练文本概率分布之间的统计性差异。低困惑度意味着语言模型生成的文本与训练文本差距小,生成的文本更接近于自然文本。

根据Yang等[10,17]的研究发现,语言模型在条件概率编码的框架下,随着嵌入容量的增加,生成文本的困惑度会增加;隐写文本的隐蔽性指标困惑度和统计安全性指标KL散度相互矛盾,两个指标不可能同时达到很好的效果。
1.2 现有的候选池截断策略
主流生成式文本隐写技术需要对各种语言模型的输出结果进行归一化,得到待生成词候选池的概率分布,常见的候选池概率分布如图2所示,图中单个单词的生成概率逐渐降低。文本生成模型输出的候选池概率分布中,包含数千甚至上万个候选词,根据长尾效应,大部分的单词概率偏低,若映射嵌入时选择了这些词,将会严重影响生成文本困惑度,因此需要根据一定的规则对候选池概率分布做截断,去除分布中概率非常低的词。如何做截断适当去除这些词是生成式文本隐写算法中的重要问题,现有方法均采用候选池截断方法,主要包括top-k[24-25]和top-p[26]两大类。

图2 常见的候选池概率分布Figure 2 The probability distribution of original candidate-pool
1.2.1 top-k截断
top-k截断指每次生成单词的时候,根据神经网络语言模型输出的概率分布,选取排序后的前k个单词作为新的候选池。Ziegler等[21]在不同生成时刻使用相同的k值进行截断,生成新的待生成词候选池,在进行生成式文本隐写时,采用固定的k值,在k=300, 600, 900的情况下完成实验。但这样忽视了候选池概率分布的差异性,虽然相比无截断,top-k截断生成的单词性能在困惑度和KL散度上有不少提升,但由于k值固定,导致生成文本的困惑度和KL散度性能较弱。
top-k截断的关键在于对k值的选择,但是上下文不同时,神经网络语言模型输出的候选池概率分布不会相同,相同的k值会忽视概率分布的差异。当k很大时,某些情况下会生成概率过低的词;当k很小时,某些情况下会忽略概率不低的词,使生成文本的困惑度和KL散度受到影响。
1.2.2 top-p截断
top-p截断又名核采样(nucleus sampling),其关键是选取神经网络语言模型输出的概率分布中前k个单词作为新的候选池,k是单词概率之和大于目标值p的最小值。给定输出的概率分布P(x|x1:i−1),单词集为V,top-p截断的候选池为V(top−p)⊂V的满足条件的最小子集,如式(3)所示。
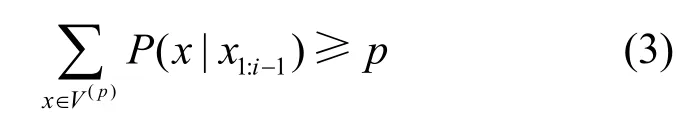
Shen等[22]在Ziegler等[21]工作的基础上,提出了动态自适应的top-k截断方案,以top-p的算法控制候选池前k个词概率分布之和,参数k由参数δ决定,如式(4)所示,随着候选池概率分布的变化,top-k的k值动态调整,有效去除候选池中的低概率单词,提高嵌入容量和统计安全性。
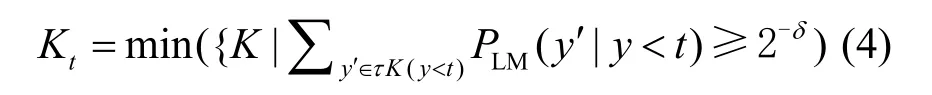
1.3 候选池截断对生成文本的影响
在其他条件相同的情况下,随着k增加,KL散度的值会减小,统计安全性更好,同时困惑度的值会增大,隐蔽性也就更差。具体结果如图3、图4所示。

图3 基于算术编码的隐写文本在不同k值情况下的困惑度Figure 3 Comparison of Arithmetic coding and Huffman coding on the perplexity when the k value is the same

图4 基于算术编码的隐写文本在不同k值情况下的KL散度Figure 4 Comparison of Arithmetic coding and Huffman coding on the KL-divergence when the k value is different
1.4 现有截断策略存在的问题
top-p截断后的候选池只包含原分布中很小一部分的单词,但这部分单词所占的概率和是原分布的90%以上,该方法较好地解决了top-k截断的问题,大多数情况下能够忽略概率较低的单词,降低生成文本的困惑度,同时不会过于影响KL散度。但在一些极端情况,如待生成词候选池概率分布过于集中或者过于平坦时,top-p截断容易生成概率较低的词或忽略概率不低的词,导致生成文本的困惑度或KL散度出现异常。式(4)中k值是候选池中,概率之和大于目标值p的最小k值,此目标值与不可感知性,包括隐蔽性——困惑度,统计安全性——KL散度没有直接的关系,因此采用固定p值不能很好地控制生成隐写文本的安全性。
图5和表1是候选池概率分布较为平坦的一个实例,图5是表1候选池单词概率的柱状图,表1则按照概率大小的顺序,列出了部分单词的概率、困惑度和KL散度。上文输入为“Washington received his initial military training ……and the regiment lost its”。该候选池中单词的最大概率为0.036,后续单词概率分布平坦。按照现有算法stego-SAAC[22]处理,k在δ=0.1时为144,考虑到原候选池概率分布尾部的单词概率差距很小,还有一部分单词应被划分到候选池中,否则会降低生成文本的KL散度。

表1 候选池概率分布过于平坦时各个单词的KL散度和困惑度Table 1 KL divergence and perplexity of each word when the probability distribution of the candidate pool is too flat

图5 候选池概率分布过于平坦的实例Figure 5 The example of probability distribution of the candidate pool is too flat
图6和表2是在候选池概率分布过于集中时候选池概率分布较为集中的一个实例,图6是表2的候选池概率的柱状图,表2是候选池中部分单词对应的困惑度和KL散度,上文输入为“Washington received his initial military training ……Eventually, Washington included his memoir”。此候选池中,第一个单词的概率为0.746,占比突出,前4个单词的概率占比超过了94%。针对这种概率分布的情况,按照现有算法stego-SAAC[22]处理,在其控制的变量δ=0.05, 0.1, 0.15时,候选池截断的k值分别为4, 7, 20,截断后候选池存在较多困惑度超过300的单词,但其KL散度并无明显提升,若在嵌入编码时选择了这些单词,则会导致生成文本的困惑度增加。

表2 候选池概率分布过于集中时各个单词的 KL散度和困惑度Table 2 KL divergence and perplexity of each word when the probability distribution of the candidate pool is too flat

图6 候选池概率分布过于集中的实例Figure 6 The example of probability distribution of the candidate pool is too concentrated
2 安全性可控的生成式文本隐写算法
针对待生成词候选池过于平坦或集中所导致生成词指标异常的问题,本文提出安全性可控的生成式文本隐写算法,以文本隐写的安全性评价指标KL散度和困惑度作为候选池截断的依据,提出top-controllablek(top-ck)截断策略,提升生成文本的安全性。
2.1 算法总体思路
安全性可控的生成式文本隐写算法基于Transformer的文本生成模型,根据上文输入生成下文候选池概率分布,使用top-controllablek(top-ck)截断方案,并根据困惑度可控或KL散度可控的参数阈值,动态进行候选池截断,然后采用基于算术编码的映射嵌入算法,生成特定的单词以嵌入秘密信息。接下来,2.2节详细介绍本算法中的top-ck截断方案,2.3节介绍映射嵌入算法的嵌入和提取过程。
2.2 top-ck截断方案
2.2.1 困惑度可控的截断策略(top-ckppl)
设定困惑度阈值上界pplthr,在候选池的概率分布中,计算在不同k值截断的情况下,候选池中概率最小单词的困惑度,使用二分搜索法,根据阈值pplthr找到满足条件的最大值kt,如式(5)所示。新生成的候选池中,限定每个单词的困惑度小于阈值pplthr。
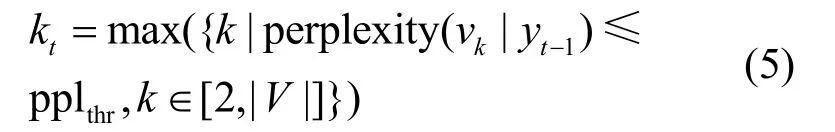
其中,perplexity(vk|yt)表示在已生成文本序列yt−1的条件下,t时刻根据选择候选池中第k个词vk时的困惑度;pplthr表示设定的困惑度阈值;表示候选池中单词的数量。 在获取到截断后的候选池概率分布后,根据待嵌入的秘密信息,使用基于算术编码的映射嵌入算法生成对应的单词。
2.2.2 KL散度可控的截断策略(top-ckkl)
在生成式文本隐写算法中,统计安全性使用KL散度表示,最理想的情况下,隐写生成文本的分布与自然文本分布之间的KL散度为0,没有差异。从信息论的角度出发,通常会计算生成的隐写文本Pstego和语言模型正常生成的文本Pcover之间的KL散度,表示隐写算法的统计安全性。
根据上文结论可知,生成式文本隐写算法中的k值越大,隐写文本分布与原始语言模型分布间的差异越小,KL散度越小,统计安全性越高。由于KL散度这种递减的趋势,首先设置KL散度阈值上界KLthr,之后在候选池的概率分布中,计算在不同k值情况下候选池概率分布与原始概率分布之间的KL散度,然后使用二分搜索找到满足条件式(6)的最小k值kt。

其中,Pstego(topk)表示经过top-k截断后的概率分布,PLM表示原始的概率分布,两者之间的KL散度需要小于设定的阈值KLthr,选择满足此条件的最小的k值。并且,困惑度可控和KL散度可控的截断策略可以同时使用,在阈值合理设置的情况下,能够同时兼顾两个安全性指标。
2.3 嵌入和提取过程
2.3.1 嵌入
本文生成式文本隐写算法嵌入过程如图7所示,其简要示例如图8所示,输入秘密信息比特序列,经GPT-2文本生成模型处理后产生概率分布,然后使用top-ckkl或top-ckppl截断策略,并使用算术编码嵌入秘密信息,输出隐写后文本。首先定义算术编码精度,该值决定了算术编码计算过程中的最小区间,假设算术编码精度为r(通常r=16),即算术编码最小区间为,t时刻的区间范围为[Lt,Ht),当t=1时,概率区间为[0,216),当时刻为t时,语言模型输出的单词序列,根据设定的困惑度或者KL散度的阈值,在经过动态top-k截断后,按概率降序排列为{y1,y2,…,yk},对应的概率排序为{P(y1),P(y2),…,P(yk)}。
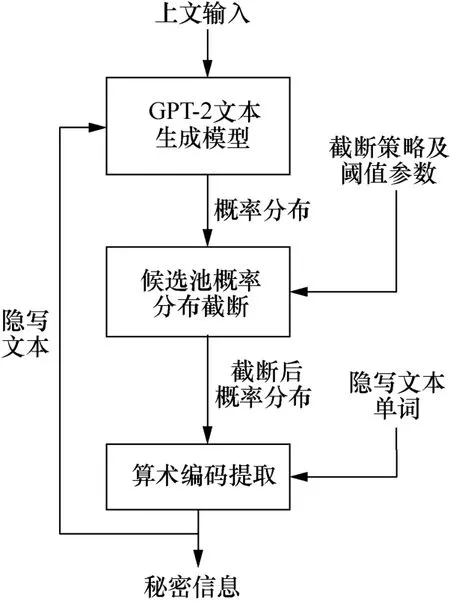
图7 生成式文本隐写算法嵌入过程Figure 7 The embedding process of generative text steganography algorithm

图8 生成式文本隐写算法嵌入过程示例Figure 8 The example of the embedding process of generative text steganography algorithm
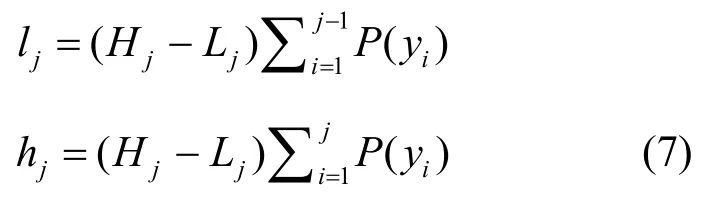
假设待嵌入的秘密信息比特序列为m,嵌入步骤如下。
1) 语言模型根据上下文的信息得到当前时刻输出的概率分布,此概率分布在做top-ckkl或top-ckppl截断后生成新的概率分布并得到当前的[Lt,Ht),然后根据式(7)得到每一个单词符号yj的概率区间范围。
2) 根据待嵌入的秘密信息m的序列,读取r比特信息(通常为16 bit)m1m2…mn,转换为十进制小数M,M∈[0,1)。
3) 寻找对应的单词符号yj,使M满足,则当前生成的单词符号为jy,并将区间范围[Lt,Ht)更新为[lt,ht),进行下一步操作。
4) 如果tL和tH的二进制数前n位相同,则表示当前的生成词已经嵌入n位信息m1m2…mn,更新tL,秘密信息左移n位,右侧补0,更新tH,秘密信息左移n位,右侧补1。如果tL和tH前n位没有对应相同的,则左移n位再次匹配,如果仍然没有相同的,则需要跳过进行下次操作,本次操作并不嵌入秘密信息。
5) 重复步骤1)~步骤4),直到完成秘密信息的嵌入。
2.3.2 提取
提取是嵌入的逆向操作,输入的是隐写生成文本序列y1y2y3…yn,输出秘密消息。本文生成式文本隐写算法提取过程如图9所示。

图9 本文生成式文本隐写算法提取过程Figure 9 The extraction process of generative text steganography algorithm in this paper
本文生成文本隐写算法提取步骤如下。
1) 在有语言模型和上文信息的前提下,获取当前时间t的语言模型输出的概率分布,之后根据设定的指标阈值获取动态top-ckkl或top-ckppl截断后的概率分布。
2) 根据动态top-ck截断后的概率分布。获取当前状态下的[Lt,Ht),在此基础上根据式(7)计算得出每一个单词jy映射的概率区间。
3) 在时间t输入的单词为ty,那么对应的区间范围为[Lt,Ht),并将区间范围更新为[lt,ht),对应的概率区间为。
4) 如果tL和tH的二进制数前n位相同,则可以对应概率区间的二进制比特数据,提取出前n位比特流,作为提取出的秘密信息。更新tL,秘密信息左移n位,右侧补0,更新tH,秘密信息左移n位,右侧补1。如果tL和tH的二进制数前n位没有对应相同的,则跳过此单词,对下一个单词进行处理。
5) 重复步骤1)~步骤4),直到完成秘密信息的提取。
3 实验分析
本节对所提算法的性能进行评估实验,并与现有主流生成式文本隐写算法进行整体性能和抗隐写分析性能的对比实验。
3.1 实验分析数据集
本文实验所有生成文本都是用参数量为124 MB的GPT-2预训练语言模型生成,采用上文输入的生成方式,上文信息选自CNN/Daily Mail[27,28]数据集。数据集中的生成文本嵌入200 bit长度随机秘密消息。本文实验所使用的生成式隐写数据集的构成如表3所示。

表3 生成式隐写数据集的构成Table 3 The composition of the generative ste ganographic text library
Cover:无任何秘密信息嵌入,使用124 MB参数规模的GPT-2文本生成模型按照top-k(k=50)的采样方式生成文本长度为50的2 000条样本,作为Cover文本库,是本文实验的对照组。
Stego-block:基于定长编码的生成式文本隐写算法[15]生成文本。在此算法中,需要将生成式文本模型的候选池划分为2block块,同一块内的生成词嵌入的秘密信息相同,参数block包含3,4,5,共2000×3=6000条文本。
Stego-Huffman:基于哈夫曼编码的生成式文本隐写算法[17]生成文本。使用变长编码的方式,参数为候选池大小m,m包含8,16,32 (23,24,25),共2000×3=6000条文本。
Stego-Arithmetic:基于算术编码的生成式文本隐写算法[21]生成文本,参数为top-k的k值,k包含300,600,900,共2 000×3=6 000条文本。
Stego-SAAC:基于算术编码的自适应生成式文本隐写算法[22]生成文本。此算法的候选池截断策略为:根据语言模型输出的候选池概率分布,以候选池单词排序后累计概率值大于2δ−选择相应top-k的k值,δ包含0.05, 0.1, 0.15共3组,共2 000×3=6 000条。
Stego-ppl:由本文所提出的基于困惑度可控截断产生的k值选择方案和算术隐写编码生成的文本,困惑度阈值包含30, 60, 90共3组,共2 000×3=6 000条。
Stego-KL:由本文所提出的基于KL散度阈值的k值选择方案和算术隐写编码生成的文本,KL散度阈值包含0.1, 0.2, 0.3共3组,共2 000×3= 6 000条。
Stego-Arithmetic和stego-SAAC是目前性能优异的生成式文本隐写算法,且它们的嵌入提取算法与本文stego-ppl和stego-KL相同,主要区别在于候选池截断策略不同,因此作为本文的对照组。
3.2 文本隐写分析实验设计
本文使用目前主流的文本隐写分析算法对正常生成文本和隐写生成文本进行训练检测来分析隐写算法的抗隐写分析能力。本实验采用的文本隐写分析方法包括FastText[29]、TS-CNN[30]、TS-RNN[31]这3种方案。
FastText[29]是一个经典的文本分类算法,是Facebook在2016年开源的一个词向量计算和文本分类工具,FastText的输入是多个单词及其额外的n-gram特征[32],隐含层是对多个词向量的叠加平均,输出时采用分层Softmax。
TS-CNN[30]是一种基于语义分析的文本隐写分析方法,使用CNN提取文本的高层语义特征,利用秘密信息嵌入前后语义空间的细微分布差异。TS-CNN[31]卷积核的数量为256,在卷积层后,需要使用最大池化的方式,同时需要Adam算法[33]训练100个epoch,并且使用early stopping[34]避免过拟合,检测阈值为0.5。
TS-RNN[31]观察到隐写文本中每个单词的条件概率分布在嵌入秘密信息后会被扭曲,采用RNN提取这些特征分布差异,进行分析分类,同时利用这些细微差异来估计秘密信息数量。TS-RNN使用双向GRU[35]结构,利用Adam算法优化。使用tanh函数作为非线性激活函数。
本文实验所采用的训练和检测方法如下:首先对数据集进行筛选,去掉长度太短的句子,避免文本长度差距太大影响实验结果的准确性。筛选后的样本库需要根据8:1:1的比例划分训练集、验证集和测试集,并且截取每一句文本的前30词作为输入,词向量(word embedding)维度为300。
3.3 性能评价指标
文本隐写算法的整体性能评价指标主要包括隐蔽性、统计安全性和嵌入容量。文本的隐蔽性通常使用困惑度进行衡量,困惑度越低,表明生成文本越自然,质量越好。统计安全性从KL散度和抗隐写分析能力两方面评价。KL散度越低,说明文本隐写引入的特征差异越小,统计安全性越好;嵌入容量是生成文本中单词平均嵌入秘密信息的比特数。
抗隐写分析能力通过不同隐写分析方法检测数据集的准确率(Accuracy)、精确率(Precision)和召回率(Recall)来表示,具体计算如式(8)~式(10)所示。

其中,TP(true positive)是实际为隐写生成文本stego,检测分类也为stego的文本数量;TN(true negative)是实际为正常生成文本cover,检测分类也为cover 的文本数量;FP(false positive)是实际为cover,被检测分类为stego 的文本数量;FN(false negative)是实际为stego,被检测分类为cover 的文本数量。由于精确率和召回率通常呈现相反的趋势,它们共同性能可以用F1表示,如式(11)所示。
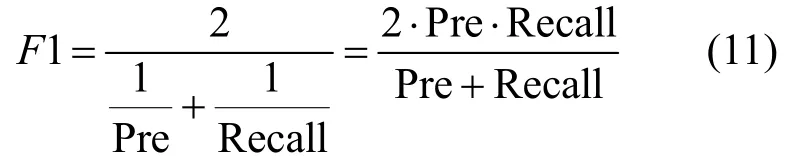
准确率Acc越小,则表示生成隐写文本的抗隐写分析能力越强。
3.4 实验结果及分析
3.4.1 生成式文本隐写算法整体性能
本文算法stego-ppl、stego-KL和对比算法生成文本的困惑度、KL散度、嵌入容量这3个方面的实验结果如表4所示。从表4中可以看出,基于块状编码的生成式文本隐写算法[15](stego-block)和基于哈夫曼编码的生成式文本隐写算法[17](stego-Huffman)的生成样本在KL散度和嵌入容量上都不理想;stego-Arithmetic[21]和stego-SAAC[22]的3个指标相较于前两种算法有了很大提升,在困惑度相近的情况下,stego-SAAC在KL-散度和嵌入容量稍微优于stego-Arithmetic,幅度大约为3%,但在文献[22]的实验过程中仅仅比较了KL散度和嵌入容量两方面的内容,根据本文实验的结果可以看出,随着δ的减小,KL散度与嵌入容量在性能上是同步提升的,即KL散度减小,嵌入容量增加,因此,stego-SAAC显示的性能会有较大幅度的提升。

表4 各生成式文本隐写算法的整体性能分析Table 4 The overall performance analysis of the above generation-based linguistic steganography
但是,从表4可以看出,这种性能上的提升是以困惑度这个指标为代价的,当KL散度和嵌入容量都很优异时,困惑度这个指标会不理想。当评价的指标变为3个(困惑度、嵌入容量、KL散度)时,本文提出的安全性可控的生成式文本隐写算法stego-ppl、stego-KL在KL散度和嵌入容量上表现最好,与现有最新的stego-SAAC算法相比,在KL散度相同时,困惑度能下降20%~30%,同时嵌入容量不会受到影响。并且,本文算法可以随时根据相关指标的阈值调整生成的文本,使每个生成词的指标都能够满足阈值的要求,相比其他方案更加直观和灵活。
表5是使用stego-ppl在pplthr=60的条件下的生成示例,表中说明了生成每一个词时KL散度、困惑度、候选池截断的k值和嵌入比特数。可以看出,虽然困惑度阈值为60,但是生成词的困惑度远远低于60,因此在设置阈值时可以偏大一点。

表5 本文困惑度可控的生成式文本隐写算法示例(pplthr=60)Table 5 An example of generation-based linguistic steganography with controllable perplexity in this article (pplthr=60)
在同时使用两种截断策略时,需要设置合理的阈值,使pplthr计算得到的k值大于 KLthr计算得到的k值,并将 pplthr计算得到的k值作为最终确定的k值,因此适当偏大设置pplthr能够有更多的情况同时使用两种截断策略。
3.4.2 抗隐写分析能力
表6是本文算法stego-ppl、stego-KL和现有算法在不同文本隐写分析算法检测情况下的检测正确率Acc和F1,体现了文本隐写算法的抗隐写分析能力。Acc 和F1值越小,表示越不容易被检测,因此具有更好的统计安全性。从表6可以看出,stego-block[15]的抗隐写分析能力最弱,不同参数下的检出率能够达到80%~90%。其余算法具有良好的抗隐写分析性能,但是从检测准确率上来看,本文算法stego-ppl、stego-KL比stego-Arithmetic低6%,比stego-SAAC低3%,因此有着更优异的抗隐写分析能力。

表6 各生成式文本隐写算法的抗隐写分析能力分析Table 6 Analysis of the anti-steganalysis capability of the above generation-based linguistic steganography
Stego-Arithmetic[21]和stego-SAAC[22]的生成样本在3种隐写分析算法检测下的F1值优于stego-Huffman[17]生成样本。本文算法stego-ppl、stego-KL的生成文本在3种隐写分析算法检测下,F1值比stego-SAAC[22]和stego- Arithmetic[21]的生成文本平均值下降0.050.1,部分情况下的F1值都在0.5以下,具有更好的统计安全性。
4 结束语
针对现有生成式文本隐写算法在候选池的概率分布过于平坦或过于集中时,生成的隐写文本在困惑度和KL散度方面存在不足的问题,本文提出的安全性可控的生成式文本隐写算法,基于Transformer的GPT-2文本生成模型和算术数编码的映射嵌入算法,以困惑度和KL散度为参数限制,生成隐写文本时设置困惑度或者KL散度的阈值,使每个生成词都满足设定的指标阈值,提高了生成文本的统计安全性。对比实验结果表明,本文算法stego-ppl、stego-KL生成的隐写文本在困惑度、KL散度和抗隐写分析性能上较现有算法有明显提升,且生成文本的困惑度和KL散度可控。
在相同KL散度,嵌入容量不受影响的情况下,本文算法stego-ppl、stego-KL生成文本的困惑度较现有算法stego-SAAC[22]和stego-Arithmetic[21]下降最高达20%~30%,生成文本在抗隐写分析性能上有部分提升,3种文本隐写分析方法检测的准确率均降低至50%左右,具有更好的抗隐写分析能力。
