基于超像素分割-稀疏字典构建的高光谱图像目标检测研究
2022-06-23张一鸣谭书伦周舒蕾欧沛钦
张一鸣,谭书伦,周舒蕾,刘 强,欧沛钦
(1.湖南理工学院 信息科学与工程学院,湖南 岳阳 414006;2.机器视觉与人工智能研究中心,湖南 岳阳 414006)
高光谱图像(Hyperspectral Images,HSI)相比于多光谱图像包含更为丰富的光谱特性。一幅HSI往往具有成百上千的光谱波段,具有很高的光谱分辨率[1-2]。目标检测是HSI领域一个重要的研究点,广泛应用于人造物体侦察[3]、矿物探测[4-5]、地质勘探和污染物探测[6-8]。HSI目标检测主要使用HSI的光谱信息来区分和标记目标像素和背景像素,本质上可以视为二进制分类问题[9]。根据目标先验信息的存在与否,目标检测可以分为有监督的目标检测和无监督的目标检测(也称为异常检测[10-12])。从检测精度的角度来看,由于目标先验信息的存在,有监督目标检测的检测性能往往要优于无监督目标检测。因此,本文主要针对有监督目标检测展开研究。
约束能量最小化(Constrained Energy Minimization,CEM)算法[13]以目标信号作为输入,设计有限脉冲滤波器(Finite Impulse Filter,FIR),突出目标信号同时抑制背景信号。自适应余弦估计方法(Adaptive Coherence Estimator,ACE)[14]通过使用样本协方差矩阵估算背景和噪声协方差结构模型来进行目标检测。自适应匹配滤波器(Adaptive Matched Filter,AMF)[15]将简化的统计模型用于广义似然比检验(Generalized Likelihood Ratio Test,GLRT)进行目标检测。分层约束能量最小化算法(hierarchical CEM,hCEM)[16]通过级联多层CEM提升检测效果。史振威等[17]提出稀疏CEM和稀疏ACE算法,通过添加稀疏正则项使输出保持稀疏性。
稀疏表示方法[18-20]利用训练样本的线性表示来近似表示测试像素从而达到目标检测效果。不同于上述传统方法,稀疏表示作为新技术在过去20年得到了广泛关注。许多学者将稀疏模型用于高光谱图像目标检测中,提高了目标检测任务的精度同时降低误警率。Raphael等[21]在稀疏表示模型的基础上提出了稀疏非负表示变弱高光谱目标检测的鲁棒控制,该检测方法依赖于高度相干字典上的稀疏和非负表示来跟踪空间变化的源,通过学习数据的测试统计量分布,可以确保对检测错误的鲁棒控制。HSI多任务联合稀疏低秩表示目标检测[22],通过使用不同的正则化方法分别对目标像素和背景像素进行建模,同时利用多任务学习框架减少了光谱冗余。为了保证目标检测的测试像素信息丰富且具有区分性,郭坦等[23]提出了基于稀疏和密度混合表示的高光谱图像目标检测(Sparse and Dense hybrid Representation-based target Detector,SDRD),根据背景和目标子字典之间的协同竞争关系,通过学习测试像素的稀疏和密集混合表示法,可以发现并保留字典的结构,获得更紧凑的表示,以更好地表示测试像素。
上述方法中,目标先验信息的质量在目标检测中起到十分重要的作用,纯净优质的目标先验信息会使目标检测效果更好。目前,常用的获取目标先验信息的方法主要有:1)直接使用标准光谱库中的光谱作为先前的目标信息;2)使用高光谱图像中的已知目标像素作为先前的目标信息。但是,上述两种方法容易受到光谱变异性和亚像素的影响。为了解决这一问题,多重加权的自适应相干估计器[24]把单个目标光谱作为输入,通过迭代重新加权的方法生成优化的目标光谱。王婷等[25]使用稀疏表示找到共同的目标像素来对目标先验信号优化。为了构造用于稀疏表示的高质量目标字典,朱德辉等[26]提出了一种基于稀疏表示的目标字典构建目标检测模型(Target Dictionary Construction-based sparse target detector,TDC-STD),通过CEM进行预检测选出足够的目标字典原子。然而,这些方法最终只能输出一个优化后的目标信号,对于复杂的目标检测难以得到较好的效果。
目前,高光谱图像目标检测亟须解决的问题有:1)光谱变异性和亚像素问题导致目标信息质量不佳;2)感兴趣的目标通常仅在HSI中占据很少量的像素,并且仅使用先验信息来构建高质量的目标字典很困难。在处理光谱变异性的问题上,稀疏表示模型有着很好的处理效果。本文将重点研究如何构建高质量的稀疏字典上,提出了一种基于超像素相关系数表示的稀疏字典构造方法(Sparse Dictionary Construction Method based-on Superpixel Correlation Coefficient Representation,SDC-SCCR),通过该方法可以选出足够多的目标像素构建高质量的稀疏字典,提高稀疏表示的检测效果。该算法仅需从全局图像中选取几个目标先验像素作为输入,然后利用超像素算法预分割HSI图像,通过相关系数从所在目标像素的局部超像素块中选出高质量的目标像素,最后用这些目标像素构建稀疏字典进行稀疏表示来进行目标检测。
1 理论基础
超像素分割能将图像按照纹理、颜色和其他具有视觉意义的特征进行分块。该方法广泛应用于图像处理和机器视觉领域,可以充分利用高光谱图像的空间局部信息。

图1 搜索2S×2S范围
对于搜索范围内的每个像素,分别计算其距聚类中心的距离:
(1)
式中:dc表示颜色距离,即颜色空间中的相似程度;ds表示空间距离,则可得到最终距离:
(2)
式中:S为聚类中心之间的距离;m为常数,用于调整色彩距离和空间距离的比例,取值范围为1~40。
2 基于超像素相关系数表示的稀疏字典构造
与经典的HSI目标检测方法相比,基于稀疏表示的目标检测在面对光谱变化时可以获得更好的性能。然而,只利用已知的目标先验信息构建目标字典很难保证稀疏表示的检测效果。因此,本文提出了一种基于超像素的稀疏字典构造方法,算法主要步骤如下:1)构建超像素图像;2)以目标先验信息为输入,计算目标所在超像素中目标先验信息与所有测试样本之间的相关系数;3)利用相关系数,从测试样本中选择出优质的目标训练样本构建目标字典,用于稀疏表示。
2.1 构建超像素图像
对于HSI来说,超像素图像的构建算法不需要全部的光谱波段。采用主成分分析法(Principal Component Analysis,PCA)来减小HSI的维数,以提取HSI的主要成分并减少HSI的光谱波段数量。
Pb=PCA(I)。
(3)
式(3)表示对高光谱图像I进行PCA处理,通过PCA处理,可以得到降维后的图像Pb,b表示降维后的维度数,在后续试验中b=3。
在得到了降维的图像Pb后,利用简单线性迭代聚类算法进行超像素分割。首先确定超像素的数量k,然后对主成分分析图像Pb进行超像素分割。SLIC算法结合了光谱距离和空间距离,使超像素中的像素具有一定的相似性,从而保证了目标像素周围的局部信息。
2.2 构建目标字典
构建稀疏字典是稀疏表示的关键部分,目标字典通常由全局图像中给出的目标先验信息构成。然而,只利用目标先验信息通常是不够的。为了解决这一问题,提出一种基于相关系数的目标字典构造方法,具体如下。
首先计算相关系数。设t为目标先验像素,其中t=[t1,t2,…,tb],X=[x1,x2,…,xi,…,xsp]是测试像素,其中xi=[xi1,xi2,…,xib],sp表示超像素中像素的总数,将目标先验信息所在的超像素中所有像素作为测试像素,而不是将图像中所有像素作为测试像素,这样可以减少计算量,从而提高算法的效率。目标像素与测试样本之间的相关系数为:
(4)
式中:B表示光谱波段数;var(t)和var(xi)分别是目标像素t和测试像素xi的方差;ut和uxi为目标像素t和测试像素xi的数学期望,计算公式为:
(5)
每一个测试像素xi与目标像素t通过式(4)都能得到一个相关系数ρi,将所有相关系数集合在一起得到ρ={ρ1,ρ2,…,ρi,…,ρsp}。
得到所有相关系数后,将所有的相关系数降序排列,选取前N1个相关系数所对应的测试像素,这N1个测试像素与目标像素t有很高的相关性,因此可以认为是目标像素,因此将这N1个像素作为目标训练样本用于构建目标字典,扩充了目标训练样本的数量同时也提高了稀疏字典的质量。目标字典的构造流程如图2所示。

图2 目标字典的构造流程图
2.3 基于字典构建的稀疏表示

(6)

a=argmin‖Aα-x‖2s.t.‖a‖0≤K。
(7)
式中:‖·‖0表示l0范数,代表稀疏向量中的非零项的个数;K表示稀疏度,决定稀疏向量中非零项的最大个数。该约束最小化问题可以通过正交匹配追踪(Orthogonal Matching Pursuit,OMP)算法求解[28]。求解得到稀疏向量a后,即可进行目标检测。将稀疏向量a分解为目标和背景2部分,即at和ab。将分解后的稀疏向量与对应的字典线性组合可以重构出测试像素,分别求出残差:
rb(x)=‖x-Abab‖2,
rt(x)=‖x-Atat‖2。
(8)
式中:rb和rt分别为背景残差和目标残差,表示测试像素与背景、目标类的相似程度。利用残差构建检测器:
D(x)=rb(x)-rt(x)。
(9)
选择设置阈值η,当D(x)>η时,x被认为是目标像素;反之,则认为x是背景像素。
3 实验仿真与分析
3.1 实验数据集
AVIRIS数据集由机载可见红外成像光谱仪收集。该数据集为美国圣地亚哥飞机场的一幅图像,图像空间分辨率为3.5 m,光谱波段数为224个,波长范围在370~2 510 nm。预先去除掉低信噪比、水汽影响较大和效果差的波段(1~6,33~35,97,107~113,153~166和221~224),最终剩下189个波段。在实验中,截取其中100×100像素的区域用于检测算法的效果,并以图3中的飞机作为目标。AVIRIS数据集局部图像场景及其对应的真值图如图3所示。

(a)图像场景

(b)真值图图3 AVIRS数据集
Texas Coast数据集显示了美国得克萨斯州沿海城市,空间分辨率为17.2 m,图像像素为100×100。除去水汽影响和低信噪比波段后,保留了原始数据集的204个波段。图4为得克萨斯州海岸数据集的图像场景和真值图。

(a)图像场景

(b)真值图图4 Texas Coast数据集
3.2 参数设置与分析
对本文算法的稀疏度K和目标样本数N1进行分析。通过经验手动调整测试K,分析K对实验结果的影响。对于AVIRIS数据集,K的范围设为[2 3 4 5 6 7 8 9 10 12 14],而Texas coast数据集,K的范围设为[3 4 5 6 7 8 9 10 12 14 16],2个数据集的N1=12。为了评估实验结果,使用曲线下面积(AUC)值来表示算法在不同K参数下的性能,如图5所示。

(a)AVIRIS数据集

(b)Texas Coast数据集图5 稀疏度K对检测效果的影响
由图5可知:检测性能将随着K的增加而提升,但是,当K值太大时,检测性能将降低并最终稳定在一个较低的水平。这是因为当K值较小时,稀疏系数中的非零项较少,这会导致拟合不足,从而导致检测性能较差,而当K的值太大时,稀疏系数中的非零项太多,稀疏系数将变得非稀疏并导致检测性能较弱。由图4可知,在AVIRIS数据集中,K值在3~6时可获得更好的检测性能,最佳值为3;在Texas Coast数据集中,K值在7~9时可获得更好的检测性能,最佳值为9。
N1通过决定稀疏字典中目标像素的数量来影响稀疏表示最终的结果。保持变量K不变,使实验结果只受N1的影响,参数N1对实验结果的影响如图6所示。从图6可知,当N1小时,检测效果不好。这是因为稀疏字典中的目标训练样本太少,因此无法很好地表示所有目标像素,导致忽略了一些难以检测的目标像素。随着N1的增加,检测效果逐渐提高,但当N1太大时,目标字典中的某些样本与目标像素的相似度较低,这可能会污染目标字典,使得检测性能下降。根据图6的实验结果,在AVIRIS数据集中,N1的最佳值为12。对于Texas Coast数据集,同样可以得到N1的最佳值也为12。

(a)AVIRIS数据集

(b)Texas Coast数据集图6 参数N1对检测效果的影响
3.3 实验结果与分析
最后,将本文算法与联合稀疏表示和多任务学习(Joint Sparse Representation and Multitask Learning,JSR-MTL)算法[29]、分层约束能量最小化算法(hCEM)[16]、重加权自适应相干估计(rACE)[24]、基于稀疏表示的二元假设检测器(SRBBHD)[19]加权联合k最近邻和多任务学习稀疏表示方法(Weighted Joint K-Nearest Neighbor and Multitask Learning Sparse Representation,WJNN-MTL-SR)[30]、高光谱目标检测中目标先验信号优化的稀疏表示方法(Sparse Representation Method for a Priori Target Signature Optimization,SR-PTSO)[25]和基于稀疏表示的目标字典构建目标检测模型(TDC-STD)[26]进行实验比较。首先进行定性分析,用所有对比算法在AVIRIS和Texas Coast数据集上进行目标检测,得到检测的结果图,如图7、图8所示。

(a)真值图 (b)本文算法 (c)JSR-MTL

(d)hCEM (e)rACE (f)SRBBHD

(g)WJNN-MTL-SR (h)TDC-STD (i)SR-PTSO

(a)真值图 (b)本文算法 (c)JSR-MTL

(d)hCEM (e)rACE (f)SRBBHD

(g)WJNN-MTL-SR (h)TDC-STD (i)SR-PTSO
通过直观对比发现,本文算法在2个数据集中都取得了很好的检测效果,hCEM和rACE算法由于只利用单一的目标先验信息,所以在2个数据集中存在较多的误检率,其他的基于稀疏表示的目标检测算法虽然得到了较好的检测效果,但由于目标样本的不足,其检测效果仍有提升空间,而SDC-SCCR利用超像素和相关系数构造了优化的目标稀疏字典,在2个数据集中有较好的检测效果。
将上述算法在AVIRIS和Texas Coast数据集上进行检测和比较,实验结果由接收器工作特性(ROC)曲线和曲线下面积(AUC)表示,ROC曲线如图9所示,AUC值如表1所示。根据所有算法在两个数据集上的ROC曲线可以看到,SRBBHD、rACE、hCEM的检测效果要相对差一点,而SDC-SCCR、JSR-MTL和WJNN-MTL-SR算法的检测效果要更好一些。通过AUC值的定量比较可知,本文算法的检测效果与JSR-MTL算法和WJNN-MTL-SR算法相比,都能够获得更好的检测性能。

(a)AVIRIS数据集
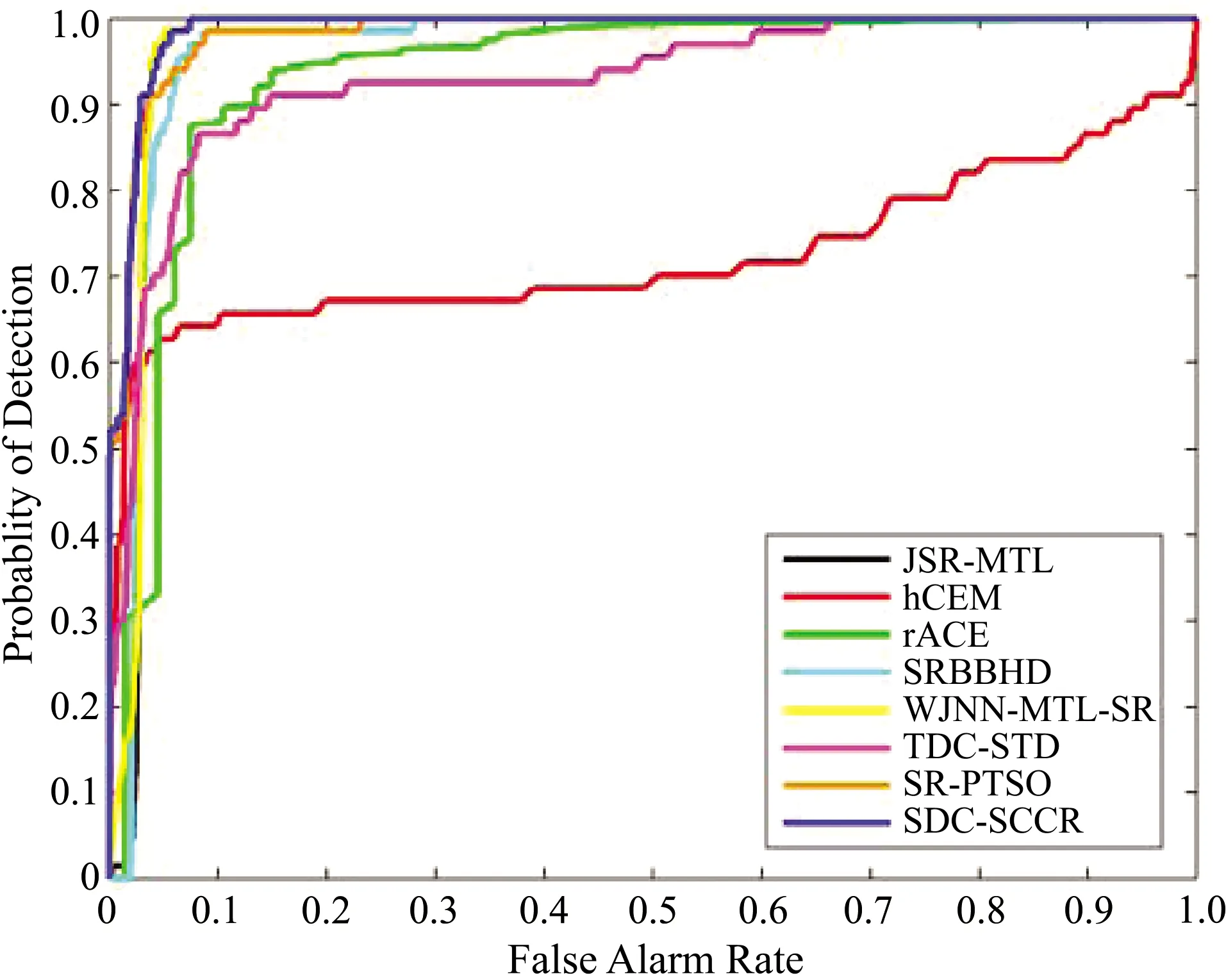
(b)Texas Coast数据集图9 ROC曲线对比
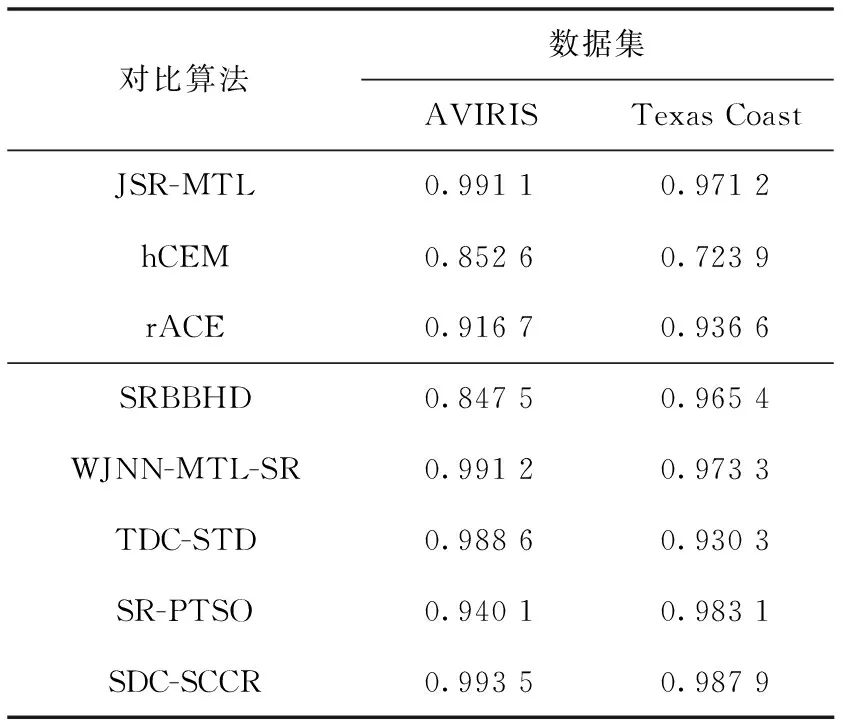
表1 AUC值对比
4 结语
本文提出了一种基于超像素分割的稀疏字典构建方法。该方法将HSI的目标光谱作为目标先验信息,通过SLIC算法和相关系数选择足够的目标训练样本,并建立目标字典,使用构造的目标字典将其转化为HSI稀疏表示。SLIC算法通过结合光谱和空间距离来保证局部信息,并且相关系数根据相关度选择足够的目标训练样本。通过实验对比和分析验证了本文提出的方法相比其他算法具有更好的检测效果。
