基于改进深度神经网络的心血管疾病预测
2022-06-23刘玉航徐英豪朱习军
刘玉航,曲 媛,徐英豪,朱习军,于 岩
(1.青岛科技大学信息科学技术学院,山东 青岛 266061; 2.青岛市海润自来水集团有限公司东部分公司,山东 青岛 266000)
0 引 言
据《中国心血管病报告》(概要)统计,中国心血管病患者数量高达2.9亿人,约占中国人口的20.7%,且其中约有43.81%的人口死于心血管病[1]。心血管病包括多种患病形态,如脑卒中、冠心病、心力衰竭等[2]。导致引发心血管病的多个重要因素是可控的,例如高血压、肥胖、吸烟等[3],尽早预防是目前治疗心血管疾病最有效的途径。
随着智慧医疗兴起,深度学习目前成为了疾病预测、辅助诊断至关重要的方法[4]。由于心血管病成因及种类繁多,因此在使用机器学习方法对其预测时需要对数据进行预处理。王曼怡等[5]使用Logistic模型对心血管病患病风险进行预测,蔡勋玮[6]采用SVM与DS结合的方式预测心血管病,杜珍珍[7]采用XGBoost算法构建冠心病患病风险预测模型,他们所做的工作多是基于已有模型进行相关预测。文献[8-9]则是基于深度学习模型进行临床诊断,他们所做的研究是应用于临床诊断,而非进行常态化的预测。上文提到,诱发心血管病的大多数因素都是可控的,以此为依据进行常态化预测和诊断同样关键,本文提出一种可以评估引发疾病特征并对患病风险进行预测的基于深度学习的模型。
在数据集方面,Kaggle提供开源的心血管病数据集,其中包含约62000条可用数据,数据集中人体特征字段为体检结果信息采集,而主观因素如吸烟、酗酒等为被采集者主观提供,心血管病患病与否则是由医学确诊后写入数据集。
由于实验过程中发现传统DNN模型存在泛化性差、易过拟合等问题,本文将在文献[10]的基础上改进并优化模型结构,提高其泛化能力,并进一步保证模型鲁棒性。
1 相关工作
本文旨在通过优化DNN模型实现对心血管病的准确预测,因此本章将重点介绍所使用的网络模型及其相关优化。
1.1 深度神经网络预测模型
由于实验是针对心血管病患病与否,所以网络模型实质为二分类模型。数据集进行预处理后传递给神经网络[11]。对模型进行训练后,将待预测样本输入模型,即可得到结果,网络模型处理流程如图1所示。

图1 神经网络处理流程图
考虑到堆叠全连接层会导致参数量过大,本文曾尝试使用多种模型结构,包括对模型增加循环神经层[12]等,但模型训练结果并不乐观,多番尝试后本文选择使用DNN作为心血管病预测的基础模型。
1.2 Batch Normalization
批归一化层(Batch Normalization, BN)是深度学习领域的重要研究成果之一[13]。利用心血管病数据训练神经网络时,若输入层获取的数据分布不一致,则传递数据时模型中其他层为了匹配输入数据变化需要不断进行调整[14]。为了加快模型收敛速度,同时缓解模型梯度弥散问题,从而更高效、更稳定训练模型,需要引入BN层。
BN层可有效解决模型内数据分布问题,其原理是计算批数据的均值及方差,对所求均值及方差进行归一化操作,最后进行尺度变化与偏移[15],步骤如式(1)~式(4)所示。
(1)
(2)
(3)
(4)
BN层的核心是式(4)的尺度变化与偏移,即让xi乘以γ来调整值大小,将结果与偏移量β相加得到yi。其中,γ和β称作尺度因子和平移因子[16],这2项参数均是通过网络训练过程中自我学习的结果。
另外,BN层可以有效地使梯度变得更加平缓[17],如图2所示。
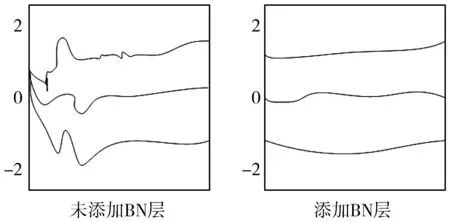
图2 添加BN层可以有效使梯度变平缓
1.3 Targeted Dropout
为防止训练过程中过拟合现象发生,Srivastava等[18]在2014年提出了经典算法Dropout。Dropout能够防止模型过拟合现象发生是通过每轮训练时随机摒弃部分网络神经元,这些被摒弃的神经元在正向传播的过程中无法对下游网络层造成影响,而且反向传播时其权重也无法得到迭代和更新,如图3所示。
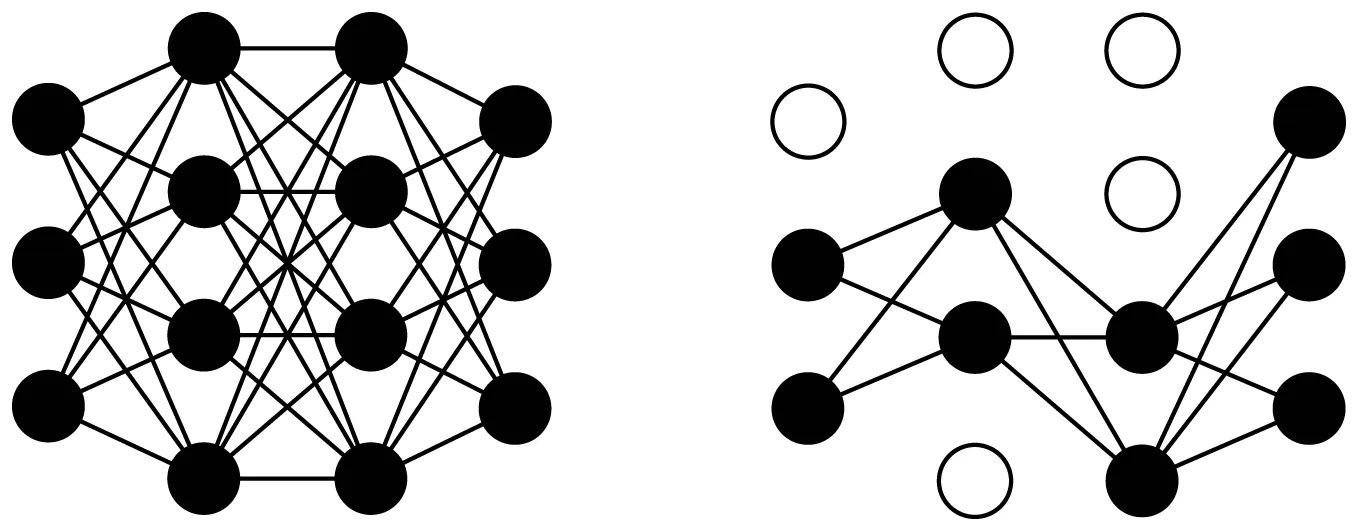
图3 经过Dropout后部分神经元被摒弃
尽管Dropout算法是解决过拟合问题的有效方式,但由于Dropout过程随机性太强,权重较高的神经元同样也会被摒弃[19],而由于本文数据是对心血管病患者特征的一般采样,若直接在模型中应用Dropout层会导致训练后模型中各个神经元的权重趋于一致,难以选择模型最佳子网络,无法保障模型剪枝工作的有效性。
为解决传统Dropout算法存在的不足,Google Brain的Gomez等[20]进一步提出了Targeted Dropout,即定向正则化思想。Target Dropout旨在解决传统Dropout存在的可能丢失关键神经元的问题,是一种能够基于重要性进行剪枝的算法。该算法结合了权重Dropout与神经元Dropout,如式(5)和式(6)分别为它们对输出值的计算公式,其中X代表输入张量、W代表权重矩阵、Y代表输出张量、M代表全连接层。
Y=(X⊗M)W
(5)
Y=X(W⊗M)
(6)
Targeted Dropout通过结合上述2种方式的Dropout,通过式(7)和式(8)来进行基于权重的剪枝和基于神经元的剪枝。
(7)
(8)
Targeted Dropout正则化不像传统的Dropout一样直接对神经元摒弃,因为被摒弃的神经元有可能在后续的训练中显现出它们的重要性。由此一来,Targeted Dropout在考虑到了影响较高的大数神经元的同时,又兼顾了小数神经元潜在的作用。
本文实验中将传统DNN模型中的Dropout替换为本节所讲的Targeted Dropout,并将在后文中对比采用2种不同正则化方法所产生的的实验结果。
2 数据处理与实验设计
2.1 数据集
本文所使用数据集为Kaggle开源心血管病数据集,其中共包含约62000条可用数据,其中共11项基本特征和1个目标变量,如表1所示。特征来源可分为主观声明和客观检测2种类型,主观声明是受试者自身生活习惯,客观检测为医学检测过程中获取的客观数据。

表1 数据集特征描述
数据集中,患病样本与未患病样本大致相等,如图4所示。

图4 患病人数分布
2.2 特征选择
在上节所提到的特征中,没有包含受试者的身体质量指数(BMI),然而,BMI过高也是诱发心血管病的因素之一,并且是更为直观的特征[22]。依据现有受试者特征,可根据式(9)计算出受试者的BMI。
(9)
通过绘制特征相关性热力图可以对数据集特征进行更直观的观测,如图5所示。

图5 特征相关性热力图
热力图能够直观表示特征间的相关性程度[23]。图5中2个特征相交的矩阵色块越深,代表这2个特征的皮尔逊相关系数越大,进而它们的关联度也就越大。该数据集中,与目标变量患病与否相交的特征色块均大于基础值,证明所选特征可以用来对该数据集进行预测。
2.3 实验设计
实验使用本文第1章提出的方法对深度神经网络进行优化。在原有的网络基础上,对每个模块额外添加BN层用以处理输入值,并添加Targeted Dropout层实现定向正则化,其中Drop_rate和Target_rate值分别设置为0.6和0.7。每个模块均采取Leaky ReLU作为激活函数,最终输出层使用Sigmoid函数作为计算二分类的预测结果函数。实验具体预测模型架构如图6所示。

图6 神经网络模型架构图
处理后的数据集以8∶2的比例划分训练集和测试集并训练200个Epoch,同时记录了在每个Epoch上的val_loss值和val_acc值,使用训练后的模型在验证集上进行验证,选择准确率、召回率、特异度、精确率作为疾病预测模型的评价指标。
3 实验结果及分析
通过对原始的DNN模型引入BN层以及定向正则化层后,发现原始DNN模型在验证集上的准确率变化情况与TR-DNN模型在前40个Epoch中存在显著差异,而100个训练周期结束后两者准确率都在78%左右,如图7所示。
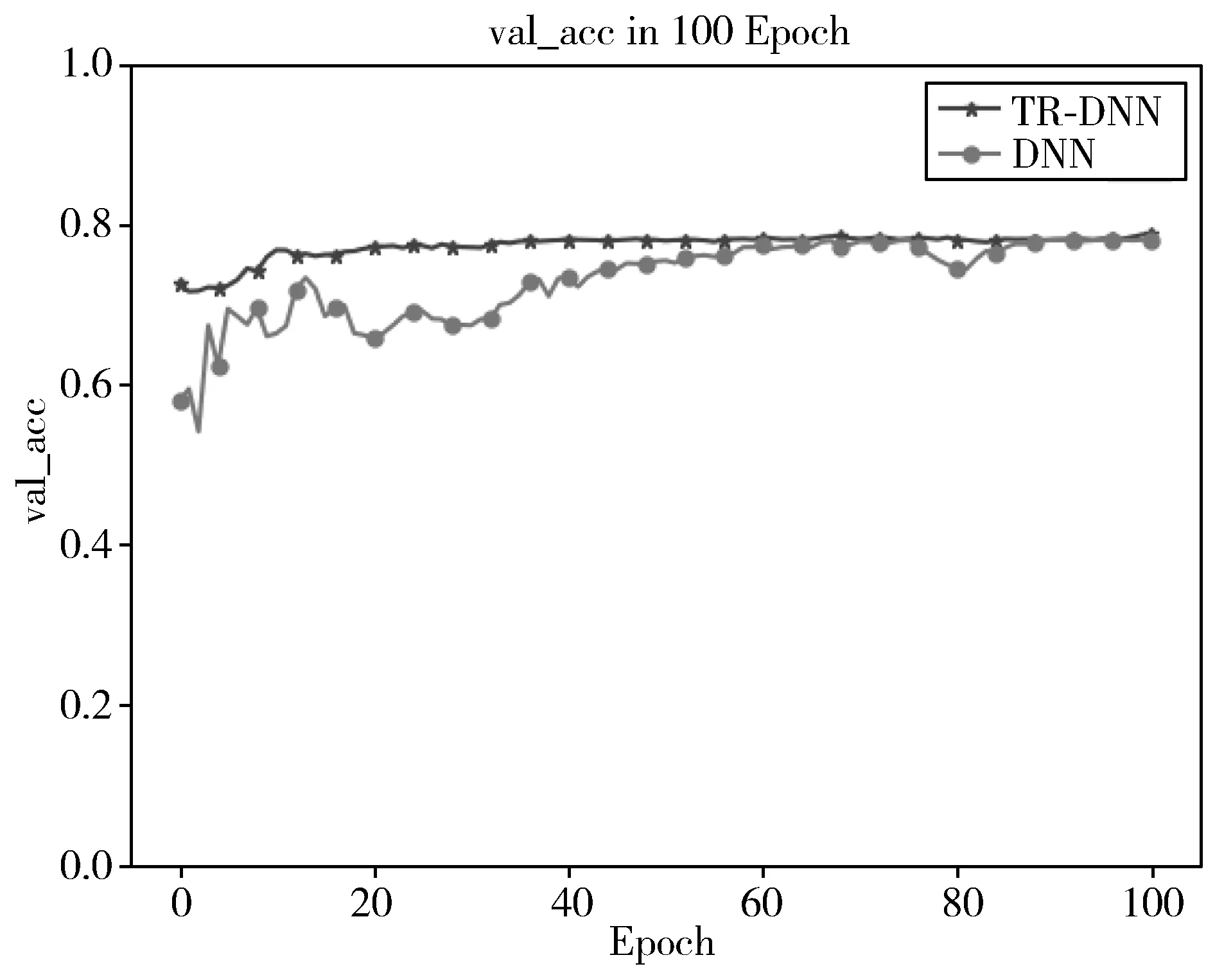
图7 2种模型在验证集上的准确率变化
3.1 评价标准
为了评估TR-DNN及其它模型的实际效果,本文将准确率(Accuracy)、召回率(Recall)、特异度(Specificity)、精确率(Precision)作为模型的评价指标。
其中,准确率、召回率、特异度、精确率分别使用公式(10)-公式(13)进行表示。
(10)
(11)
(12)
(13)
上述公式中,TP代表正例预测正确的个数;FP代表负例预测错误的个数;TN代表负例预测正确的个数;FN代表正例预测错误的个数。
3.2 结果与分析
在进行200个训练周期的训练后,本文采集了TR-DNN模型与传统DNN模型以及SVM、RF、XGBoost模型在测试集上的评价标准数据,并在表2中将这些数据列出。

表2 不同模型的评价标准结果
通过表2可以得出,在准确率方面,TR-DNN模型高于其它3种传统机器学习模型,比SVM模型提高了14.57个百分点,比RF模型提高了5.75个百分点,比XGBoost模型提高了3.15个百分点,且与同为深度学习的传统DNN模型相比,准确率依然有着1.5个百分点的提高;在召回率方面,TR-DNN模型在对比其他传统对照模型有着更好结果的同时,与传统的DNN模型对比,TR-DNN模型的召回率仍然提高了1.57%;在特异度方面,TR-DNN模型依然有着最好的结果,并且比传统DNN模型提高了2.54个百分点;在精确率方面,TR-DNN模型比SVM模型提高了14.54个百分点,比RF模型提高了6.07个百分点,比XGBoost模型提高了3.08个百分点,比DNN模型提高了1.51个百分点。
可以发现,通过对传统DNN模型增加BN层以及Target-Dropout层可以有效地提高模型的性能。同时,由于在模型中原本独立的网络层之间加入了归一化层,不同层之间的数据得到了归一化,从而能够进一步降低模型的训练时间。
4 结束语
本文研究了通过对传统DNN模型进行添加BN层与定向正则化层,将模型优化为TR-DNN模型,并训练此模型以进行预测心血管病的任务。通过实验可以发现,TR-DNN模型在准确率、召回率、特异度、精确率等评价指标方面均高于其它的对照模型,其中包括传统的DNN模型,这表明优化的深度神经网络模型可以应用于心血管疾病的预测任务。但由于数据集并非专业临床电子病历,准确率方面相较其它模型虽有提升,但不能完全作为医疗诊断依据。针对这一问题,需要对模型进一步改进,使其能够真正应用于医学辅助诊断领域,同时进一步提高预测准确率。
