特征信息增强的无人机车辆实时检测算法
2022-06-23杨建秀谢雪梅石光明李甫
杨建秀 谢雪梅 石光明 李甫
(1.西安电子科技大学人工智能学院,陕西西安 710071;2.山西大同大学物理与电子科学学院,山西大同 037009)
1 引言
无人机视角下的车辆实时检测是车辆跟踪[1]、实时路况获取[2]以及安全巡查[3]等许多领域的关键技术,具有实际的研究意义和广泛的应用需求。由于无人机拍摄的高度不定,场景多样化,加上外部的环境因素(如恶劣的天气和建筑物的遮挡等)的影响,使其拍摄的车辆目标存在遮挡、模糊、尺度较小和多样性以及背景复杂等问题,从而给无人机视角下车辆目标实时检测带来了诸多的挑战[4-5]。
随着卷积神经网络(Convolutional Neural Net⁃work,CNN)的快速发展,基于深度学习的目标检测性能[6-8]得到显著提升。无人机视角下的车辆目标检测也随之不断改善。Sommer 等人[9-10]在两阶段(Two-stage)目标检测算法Fast RCNN[11]和Faster RCNN[12]的基础上融合了车辆上下文信息(Context Information)增强弱小目标的特征。Zhang 等人[13]在Mask R-CNN[14]算法上提出多尺度遮挡感知网络能够缓解无人机车辆目标尺度多样性的问题。李等人[15]利用改进的Cascade RCNN[16]为小目标车辆引入更多范围的周边信息以此来增强目标的特征,可以较好地检测遮挡的车辆目标。上述方法都是基于Two-stage 目标检测算法可以实现高精度的性能,但不能满足实时的实际应用需求。Ra⁃dovic,Tang 和孔等人[17-19]分别对单阶段(Singlestage)检测算法YOLO[20],YOLOv2[21]和YOLOv3[22]进行改进实现无人机交通监控车辆的实时检测。为进一步增强弱小目标车辆特征,Yang 等人[23-24]采用自顶向下(Top-down)多尺度特征融合结构考虑合适的上下文信息提高弱小目标的判别性,提升了无人机视角下弱小车辆的检测性能。王等人[25]利用Darknet-53[22]作为主干网络去训练目标检测器实现无人机载平台的多目标检测与跟踪。任等人[26]利用多尺度像素特征融合思想完成小交通标志的实时检测,周等人[27]在YOLOV4-Tiny 的基础上进行相应的改进提高雨雾道路环境下的实时弱小目标检测。这些基于Single-stage 实时算法的车辆检测仅仅考虑利用卷积网络中高级语义信息为浅层特征提供了上下文信息。但Wang 等人[28-29]提出中低级信息如轮廓(Delineation)和纹理(Tex⁃tures)对于目标的精确定位是至关重要的,特别是小目标的检测。
为此,本文利用能够精确描述车辆目标的中低级特征信息和能够区分其他类别的高级语义信息完成目标特征信息的双向传递,提出一种特征信息增强的多尺度特征融合的无人机车辆目标实时检测算法。该算法提出一种轻量级多尺度特征网络去提取有利于车辆目标定位的中低级特征信息,并将其嵌入到主干神经网络中;同时利用主干卷积神经网络提取有利于车辆与背景或其他类别分类的高级语义信息,并将其与浅层特征进行融合;因此中低级信息和高级语义信息的不同融合可以增强无人机车辆目标的特征信息。然后,为了保证轻量级特征提取网络能够提取到车辆目标更为丰富的中低级特征信息,本文采用多路空洞卷积进行特征提取。最后提出一种有效灵活的特征融合模块,可以将轻量级特征提取网络引入的中低级特征信息较好地融入到主干网络中,从而增强车辆目标的判别性特征。本文所提出的算法能够实时显著地提高无人机视角下复杂场景下弱小车辆的检测效果。
2 特征信息增强的无人机车辆实时检测模型
本文提出的基于特征信息增强的无人机车辆实时检测网络整体结构如图1 所示,该算法主要包含四个关键部分:首先采用具有检测精度高和测试速度快综合优势的单阶段精细神经网络Refine⁃Det[30]作为特征提取的主干网络;然后利用轻量级多尺度特征提取网络(Light-weight Multi-scale Fea⁃ture Network,LMFN)提取车辆目标的中低级特征信息,同时为了保证LMFN 能够提取到更为丰富的中低级信息,本文采用多路空洞率卷积的特征信息转换模块(Feature Information Transformation Mod⁃ule,FITM)进行特征提取;最后利用有效灵活的特征融合模块(Flexible Feature Fusion Module,FFFM)将中低级特征与主干网络提取的特征较好地融合在一起,增强小目标车辆的特征表示。
2.1 RefineDet主干网络
RefineDet 网络结构既拥有单阶段Single-stage检测算法实时的优势,又具有两阶段Two-stage 检测算法对锚框Anchor 进行二次精细优化的特点。该网络首先利用锚框优化模型(Anchor Refined Mod⁃ule,ARM)实现目标和背景的二分类任务,其作用类似于Two-stage经典目标检测算法Faster RCNN 中区域候选框生成网络RPN,能够完成目标候选框的初步筛选,滤掉大量负样本,缓解Single-stage 目标检测算法中正负样本不平衡的问题,同时可以对目标位置进行粗略的回归定位,但不需要对每个目标候选框做类似Faster RCNN 中感兴趣池化操作ROI Pooling 过程,这样可以节省大量计算时间从而能够达到实时的检测速度;然后提出目标检测模型(Ob⁃ject Detection Module,ODM),该模型的作用与Single-stage 检测算法SSD 是类似的,直接进行多尺度特征预测完成最终的多类别分类任务以及对目标进行精确的回归定位,不同的是ODM的预测层是经过特征融合得到的特征增强的多尺度预测层,具有语义较强的优势,而SSD 的多尺度预测层是没有特征融合这一过程;最后设计转换连接模块(Trans⁃fer Connection Block,TCB)将ARM 的输出特征利用自顶向下Top-down 结构转换成ODM 的输入特征,同时该模块的作用与经典特征金字塔FPN 的思想一致,可以实现多尺度特征融合,为浅层目标提供高级语义上下文信息增强其目标特征表示。该网络最终利用不同预测特征层Conv4_3,Conv5_3,Conv_fc7和Conv6_2对目标完成多尺度预测。
针对无人机视角下的车辆目标大部分都是弱小目标的实际情况,本文在RefineDet 网络的基础上,增加卷积层Conv3_3 完成相对更小的车辆目标的预测,同时去掉较深的预测卷积层Conv6_1 以及Conv6_2等,因此本文采用Conv3_3,Conv4_3,Conv5_3和Conv_fc7 作为多尺度特征预测层,后续实验结果可以证明该特征预测层的选择策略能够取得更好的检测效果。同时由于不同数据集各类目标的尺度大小以及长宽比率的分布都是不一样的,因此需要根据数据集中各类目标的长宽比分布设置合适默认候选框Anchor,本文根据无人机车辆的数据分布以及车辆目标在不同卷积层实际的感受野[24]设置适合无人机数据集的Anchor,从而可以提高车辆检测的召回率。
2.2 轻量级多尺度特征提取网络
针对弱小目标的检测算法,经典的特征金字塔网络FPN[31]采用将深层语义信息特征和浅层特征进行融合增强小目标特征,主要解决了浅层特征缺少语义信息的问题。但小目标检测是一个具有挑战性的问题,它不仅需要能够区分目标与背景和其他类别的高级语义信息,也需要能够精确描述目标的中低级信息。本文利用轻量级多尺度特征提取网络(Light-weight Multi-scale Feature Network,LMFN)不仅为主干网络RefineDet提供中低级信息的补充,而且是一个从零开始训练的轻量级网络,与经典的利用ImageNet 先进行预训练后再进行微调(Finetune)的分类检测网络相比,He[32]认为从零开始训练检测模型更有助于目标的精确定位,因此本文提出的LMFN网络更有利于小目标车辆的精确定位。
轻量级多尺度特征网络LMFN 主要由特征信息转换模块(Feature Information Transformation Mod⁃ule,FITM)和有效灵活的特征融合模块(Flexible Feature Fusion Module,FFFM)构成。LMFN 是一个从零开始训练的网络,这样可以减少分类和定位之间的任务差距,同时它仅是利用简单的卷积层(Convolution Layer)和Batch Normalization[33]层组成,不需要消耗大量的训练时间,然后将该LMFN网络嵌入到用于提取特征的主干卷积网络中,与预训练的主干卷积网络优势互补,共同构建一个特征信息增强的无人机车辆实时检测网络,其整体结构如图1所示。
其中预训练的主干卷积网络是经过多个卷积层(Convolution Layer)和最大池化层(Max Pooling)的重复堆叠进行特征提取,用于产生能够区分目标与背景和其他类别的语义信息丰富的特征,如图2(a)所示,这种提取语义特征的方式对图像分类十分有利,满足平移不变性的要求。但目标检测任务中不仅要满足目标分类的要求,还需要完成精确的目标定位,因此更需要目标中低层特征中所包含的位置和轮廓信息,本文利用LMFN 网络提取这些中低级特征信息。首先经过一个较大的下采样倍数将输入图像的大小调整到主干网络中第一层预测特征层的尺度大小,然后作为输入被送到特征信息转换模块FITM 中实现特征转换便于后续与主干特征进行融合,如图2(b)所示。从零开始训练的轻量级多尺度特征网络LMFN类似于图像金字塔为标准的预训练主干卷积网络的深层特征提供充足的中低层特征信息,更有利于目标车辆的定位。下面重点介绍构成轻量级多尺度特征网络LMFN的特征信息转换模块FITM和有效灵活的特征融合模块FFFM。
2.3 特征信息转换模块
特征信息转换模块FITM 主要是实现LMFN 网络输入图像的特征转换,提取无人机车辆目标的中低层特征信息Fn,其结构如图3 所示。该模块由两部分组成,一是简单的3×3 的卷积层和BN 层以及1×1 的卷积层和BN 层;二是多路空洞卷积(Dilated Convolution),可以提供更为丰富的中低层特征信息。在卷积神经网络中,空洞卷积[34]相比普通卷积仅增加了一个名为空洞率r的参数,而且可以在保持图像分辨率的情况下能够增大感受野。不同的空洞率r可以形成不同大小范围的感受野和不同中心的特征。本文采用的多空洞率并联卷积可以保持目标车辆周围不同范围的信息,丰富中低层特征信息的多样性。
首先将LMFN 的输入图像分别经过一个3×3 卷积和1×1 的卷积层得到特征sn,然后将此特征完成多路(两路、三路或者更多)空洞卷积的拼接(Con⁃cat)操作实现不同范围感受野的特征融合,这里以三路空洞卷积为例如图3 所示。将空洞率r分别为1,2,3并联的三种3×3卷积特征进行融合后,最后经过一个1×1 的卷积进行通道维数变化的操作,达到融合不同特征的目的,得到车辆目标的中低层信息Fn,该过程可以用如公式(1)所示:
其中,Cat 表示拼接操作运算,Dk,r(s)表示空洞卷积Dilated Convolution 操作,k表示的是卷积核的大小,本文采用的是3×3的卷积操作,r表示的是空洞率的大小,s表示的是多路空洞卷积的输入特征,F表示的是多路空洞卷积的输出特征,即提取到的中低层特征信息。
2.4 有效灵活的特征融合模块
为了使转换模块FITM 提供的中低级特征能够更好地融合到主干特征提取网络中,本文设计的特征融合模块(Flexible Feature Fusion Module,FFFM)是一个较为灵活的模块,在多尺度中低级特征信息嵌入的无人机车辆检测的整体结构中的位置如图1所示,对于每个FFFM 融合模块都有两个输入,转换模块FITM 的输出特征F和相应的主干特征C,因此融合模块FFFM可以表述为如公式(2)所示:
其中n是主干网络中预测特征层对应的层级序号,Ln表示对应融合模块的输出特征。I0代表主干网络中的输入图像,In是LMFN 网络的输入图像。cn(⋅)和fn(⋅)分别表示主干网络第n个特征层级的输出和与之相对应融合的LMFN网络层级特征的输出。此外,本文采用FFFM 融合模块的三种不同变体,以证明中低级特征信息传递的有效性,则β的对应函数有三种,分别为点对点相加(Element-wise Sum),拼接(Concat)和残差式点乘(Residual Product),其不同的融合方式结构如图4 所示,下面详细介绍这三种融合方式。
(1)点对点相加(Element-wise Sum)
点对点相加的融合方式是将中低级信息特征Fn与主干网络提取的特征Cn变换到相同的空间域中并进行点对点相加,其目的是将LMFN 产生的中低级特征视为额外的附加信息去增强小目标车辆的判别性特征。该融合方式需要将两种特征的通道数调整为相同的维数,其对应的公式(3)如下:
其中,CT表示通道维数的变换(Channel Transform),Wk表示1×1的卷积层,W表示3×3的卷积层和BN层。
(2)拼接(Concatenation)
Concat融合方式是利用拼接操作将中低级信息特征Fn与主干网络提取的特征Cn融合在一起,与U-Net[35]中的融合方式相似,融合后的特征可以利用不同的卷积核进行特征选择与整合,本文采用1×1 的卷积核。该融合方式能自主选择融合有用的背景信息,具有一定的选择性,从而可以在一定程度上避免背景噪声的干扰。其对应的公式(4)如下:
其中,Wm表示1×1 的卷积层和BN 层,Cat 表示拼接操作运算。
(3)残差式点乘(Residual Product)
Residual Product 的融合方式是将LMFN 的中低级信息特征Fn与主干网络特征Cn进行点对点相乘(Element-wise Product)操作,然后将其结果与Cn实现残差式相加,即把((Wk⋅CT(Fn))⊗(Wp⋅Cn))视为主干网络特征Cn中丢失的信息,然后再将该丢失的信息添加到主干网络,增强车辆目标特征。其对应的公式(5)如下:
其中,Wp表示1×1的卷积层运算。
3 实验结果与分析
3.1 实验运行环境
本文实验环境是在Ubuntu16.04 操作系统Caffe 深度学习平台下进行网络模型搭建,GPU 采用的是NVIDIA Titan Xp 的显卡(12 GB 内存),相应的显卡驱动和加速库分别采用为CUDA8.0 和cuDNNv6.0,CPU是Intel Core i7-7700K@4.2 GHz。
3.2 实验数据集
本文采用公开数据集XDUAV[24]和Stanford Drone[36]分别进行实验结果分析。
XDUAV 是利用大疆无人机在不同的交通场景下进行多类别车辆采集而构成的车辆小目标数据集,该数据集包括3475 张训练图像和869 张测试图像。图像分辨率为1920×1080,其中把六类车辆小汽车、公共汽车、卡车、摩托车、自行车和油罐车作为训练数据,其各类车辆目标数量如表1所示。

表1 XDUAV数据集中各类车辆目标的数量Tab.1 The number of each category vehicle in XDUAV dataset
Stanford Drone 数据集中包括六类目标,行人、骑自行车的人、滑板手、小汽车、公共汽车和高尔夫球车,由于本文旨在研究车辆目标,因此选择小汽车、公交车和高尔夫球车三类目标作为本文实验的训练数据。其中训练图像为3500 张,测试图像为831 张,图像分辨率大约为1409×1916,其各类车辆目标数量如表2所示。

表2 Stanford Drone数据集中各类车辆目标的数量Tab.2 The number of each category vehicle in Stanford Drone dataset
3.3 性能评估指标
为了评估实验结果,本文采用了三种典型的评价标准:单类平均准确率(Average Precision,AP),所有类别的平均准确率均值(mean Average Preci⁃sion,mAP)以及检测速度(每秒传输帧率,Frames Per Second,FPS)。其中这些评价指标对应的计算公式如下所示:
其中,TP 表示的是正确识别正样本的数量,FP 表示的是错把负样本识别成正样本的数量,FN表示的是未能识别正样本的数量,TN表示正确识别负样本的数量。n对应的是训练样本的类别数量,APi对应第i类目标的平均准确率。mAP 评价标准是检测网络对所有目标能够被正确分类和定位所做出整体性能的衡量,mAP的值越高,说明网络性能越好。
3.4 训练参数
为了使网络对任意尺度大小的车辆目标都具有鲁棒性,本文采用了数据增广策略[37],包括随机扩展和裁剪原始训练图像,以及水平翻转等策略。同时网络训练的初始值采用的是公开分类网络VGG ISSVRC[38]的权重,初始学习率为0.001,重量衰减系数为0.0005,动量设置为0.9,训练迭代次数共为120k次,分别在80k次和100k次时学习率降为0.0001和0.00001。训练图像大小为320×320,每批次训练图像数量(Batch Size)为16。
3.5 损失函数
本文用于分类的损失函数为交叉熵函数,用于回归的损失函数采用SmoothL1函数,网络的总损失函数定义为:
其中,i定义的是Mini-batch 中默认候选框Anchor 的索引。在二分类(车辆vs.背景)ARM 任务中,pi是对应Anchori属于前景车辆目标的预测概率,xi是对应Anchori属于车辆目标的粗略位置预测。如果Anchori为正样本,则真实标签Ground Truth为1,否则为0,则是Anchori为Ground Truth 的位置和大小。在多分类(车辆vs.车辆)ODM 任务中,ci和ti分别是指Anchori属于车辆具体类别的预测概率和对应该类别的精细预测位置。Narm和Nodm分别表示ARM 和ODM 中Anchor 被判定为正样本的总数量。Lcls-b和Lcls-m分别是对应ARM 和ODM 的二分类交叉熵和多分类交叉熵损失函数,Lcls-b是Lcls-m的一种特殊形式。Lreg采用的是SmoothL1 回归损失函数,公式如下所示:
3.6 XDUAV数据集的实验结果
本文在XDUAV 数据集上首先进行消融实验去验证本文所提创新点的有效性,然后与Faster RCNN[12]和SSD[37]等一些经典的目标检测方法进行检测性能的对比。实验结果表明,本文所提出的网络算法能够达到92.2%的mAP 以及每秒51 帧的实时性,实现了无人机视角下小目标车辆的高精度实时检测。
(1)RefineDet 主干网络设置的必要性
针对无人机视角下车辆目标大部分都是弱小目标的实际情况,本文首先对原始RefineDet的多层预测输出层做出一定的改进,将浅层卷积层Conv3_3增加为预测输出层(将增加浅层卷积层Conv3_3的模型简称为R_Conv3_3),然后在此基础上去掉深层预测卷积层Conv6_2(将此时模型简称为Simple-R)。因此本文设置四层Conv3_3,Conv4_3,Conv5_3 和Conv_fc7 分别作为多尺度预测输出层。最后,根据XDUAV 数据集的车辆整体分布对四层预测层设置对应默认候选框Anchor 的参数如表3 所示(将此模型简称为Setting-R),然后在Setting-R模型的基础上对后续轻量级特征提取网络LMFN进行详细具体的分析。

表3 不同预测层中对应Anchor的设置Tab.3 Corresponding Anchor settings in different prediction layers
关于参加预训练的主干卷积网络RefineDet 中预测特征层设置以及Anchor 设置的实验结果对比如表4 所示。首先,表4 中第二行和第三行所示的实验结果对比证明RefineDet 主干网络中浅层卷积层Conv3_3对小目标车辆正确分类定位起着至关重要的作用。然后,第三行和第四行所示的结果对比表明,深层卷积Conv6_2 对于小目标车辆的检测是无用的。其主要原因为:一是小目标在深层卷积层中可能会缺少位置或空间信息导致Anchor 和目标本身卷积特征产生一些偏移,也就是说深层卷积特征中的小目标的位置和初始位置不一致,这对弱小目标的正确定位影响是比较大的;二是在深层卷积特征为小目标车辆带来了较大的感受野,伴随着会引入过多的背景干扰,从而影响检测性能;三是因为小目标容易在较深的卷积层中丢失特征。最后一行是对各预测层进行相应Anchor 设置后的检测结果,性能得到显著的提升,主要是因为常规An⁃chor 设置(所有预测层的长宽比都设为1,1/2,2)与某些类别车辆的真实值不匹配造成的,容易出现车辆目标如卡车漏检的情况。因此本文所提的主干网络能够更稳定地训练提高小目标车辆的检测性能。
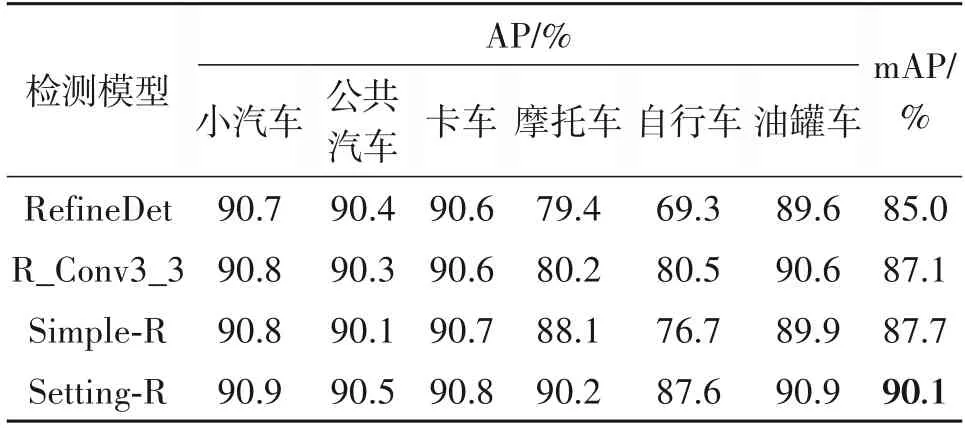
表4 主干网络中预测层设置以及Anchor设置的性能对比Tab.4 Performance comparison of the prediction layers and anchor settings in the backbone network
(2)轻量级多尺度特征提取网络的重要性
本文为保证每一预测层既有能够精确表示目标的中低层信息,又有能够区分目标与背景和其类别的高层语义信息,依次将LMFN 网络提取的中低级特征融合到主干网络的预测层Conv3_3,Conv4_3,Conv5_3和Conv_fc7中做对比实验,如表5所示。实验结果表明在浅层Conv3_3 和Conv4_3 中添加中低级信息的作用并不大,因为这两层对于主干网络而言,自身就是浅层特征,如果增加额外的参数反而会带来特征冗余,给网络造成负担,致使检测性能下降。在深层Conv5_3 和Conv_fc7 中添加适当的中低级信息,正好弥补小目标缺失的信息,有利于目标的精确定位,实现了将中低级信息的传递;同时本文将深层高级语义特征与浅层特征进行融合实现了高级语义信息的传递,使其浅层卷积层都具有判别性特征,这种做法类似于引入双向网络,能够有效地传递不同层次的信息,增强无人机视角下车辆目标的特征表示。因此本文提出的LMFN 网络既可以保证每一预测层都具有利于定位的中低级信息,又具有利于分类的判别性特征的高级语义信息,在提高无人机视角下车辆弱小目标检测精度的同时,又不影响网络的实时检测。这里需要注意的是,表5 显示的检测结果是利用LMFN 网络中特征信息转换模块FITM 中最基本的卷积操作,即只是将LMFN 的输入图像依次经过3×3 卷积层、1×1 的卷积层和3×3 卷积层得到中低级特征Fn,并没有多路空洞卷积的参与;同时在进行特征融合时,也只是将辅助特征Fn和主干特征Cn进行简单的点对点相加(Element-wise Sum)操作,并没有用到具体灵活特征融合模块FFFM 的操作过程。

表5 中低级特征信息嵌入到不同预测层上的性能对比Tab.5 Performance comparison of embedding mid-/low-level feature into different prediction layers
(3)多路空洞卷积的有效性
为了证明特征信息转换模块FITM 的有效性,本节分别采用单一卷积和多路(包括两路和三路)空洞卷积来进行验证,如表6 所示。利用空洞率r=1,3或r=2,3的两路空洞卷积方法相比单一卷积的检测性能好,检测精度分别提升了0.2% 和0.1%。这是因为空洞率大的卷积其感受野相应增大,可以提取到目标的轮廓信息。将不同空洞率卷积拼接后提取到的特征更加丰富,特征响应相比于其他特征响应更为强烈。而三路空洞卷积r=1,2,3方法相比于r=1,3或r=2,3两路卷积更能够带来多样性的感受野,即可以得到更多不同范围的信息,因此检测精度又有一定的提升。但针对无人机视角下大多数车辆是弱小目标,太大的感受野容易带来更多背景干扰,因此三路空洞卷积r=1,2,3 的检测性能不如两路空洞卷积r=1,2 提取的特征更为细腻,能够保留更为丰富的细节信息,更利于小目标车辆的精确定位。因此本文利用两路空洞卷积r=1,2 策略可以获得不同感受野信息,丰富车辆目标特征,减少了信息的丢失,有利于目标车辆的分类定位。此外,不同空洞率需要对输入图像进行不同的Padding 填充,从而会导致网络的计算量增加,其不同空洞卷积的检测速度(每张图像的测试时间)如表6最后一列所示,但不影响网络检测的实时性。

表6 多路空洞卷积实验结果的性能对比Tab.6 Performance comparison of multi-rate dilated convolution
(4)不同特征融合模块设置的必要性
为了确保LMFN网络提供的中低级信息较好地融入到主干网络中,本文采用三种不同的融合策略进行实验对比。Concat 融合方式是通道数Channel的合并,表示目标本身的特征增加,但每一特征中的信息并没有增加。残差式点乘(Residual Prod⁃uct)的融合方式可以认为表示目标本身特征的信息增加,该方式显然是有利于分类的,所以性能要优于Concat 融合方式。然而点对点相加(Elementwise Sum)融合方式能够提供更多的表示目标本身的信息,其检测性能更好。为了比较它们的有效性及区别,我们在相同的条件下执行不同的融合方式,并分别计算出不同车辆类别的准确率AP 值,如表7 所示,实验对比结果表明点对点相加(Elementwise Sum)的融合方式在所有性能指标上都展现了更好的性能。

表7 FFFM模块三种融合方式的性能对比Tab.7 Performance comparison of the three fusion methods for FFFM module
(5)整体性能的对比结果
在XDUAV 数据集上,本文提出的无人机视角下弱小目标车辆的检测算法与一些经典的目标检测算法Faster RCNN[12]、R-FCN[39]、FPN[31]、YO⁃LOv2[21]、YOLOv3[22]、RON[40]、SSD[37]、DSSD[41]以及RefineDet[30]进行整体性能对比。如表8 所示,本文提出的方法能够达到92.2%的检测精度。同时,本文涉及到的用于增加中低级特征信息的LMFN 网络、多路空洞卷积以及特征融合模块FFFM,虽然在一定程度上引入了额外的参数,但并不影响网络的实时检测。本文利用训练好的网络进行前向推理,对869 张测试图像的推理耗时取其平均,得到精确的检测速度为19.56 ms,大约为51 FPS。此外,为了进一步验证本文算法能够在实时的基础上取得最佳的检测性能,本文在RefineDet网络架构上利用不同轻量级网络MobileNet[42-44]和ShuffleNet[45-46]作为主干网络完成车辆检测,表8实验结果表明,采用轻量级网络可以大大减少网络参数量实现实时的性能,但车辆检测精度却大幅度下降,尤其是更为小型车辆目标(如自行车)。图5显示了本文算法和只考虑利用卷积网络中高级语义信息为浅层特征传递上下文信息主要解决浅层特征缺少语义信息的算法在不同场景下目标车辆的对比检测效果,由对比检测效果图可以看出,本文设计的车辆检测算法对于不同交通场景下弱小目标车辆存在错检、漏检以及重框等问题都取得较好的检测效果,特别是对于尺度变化较大、遮挡车辆以及车辆的精确定位具有很好的鲁棒性。
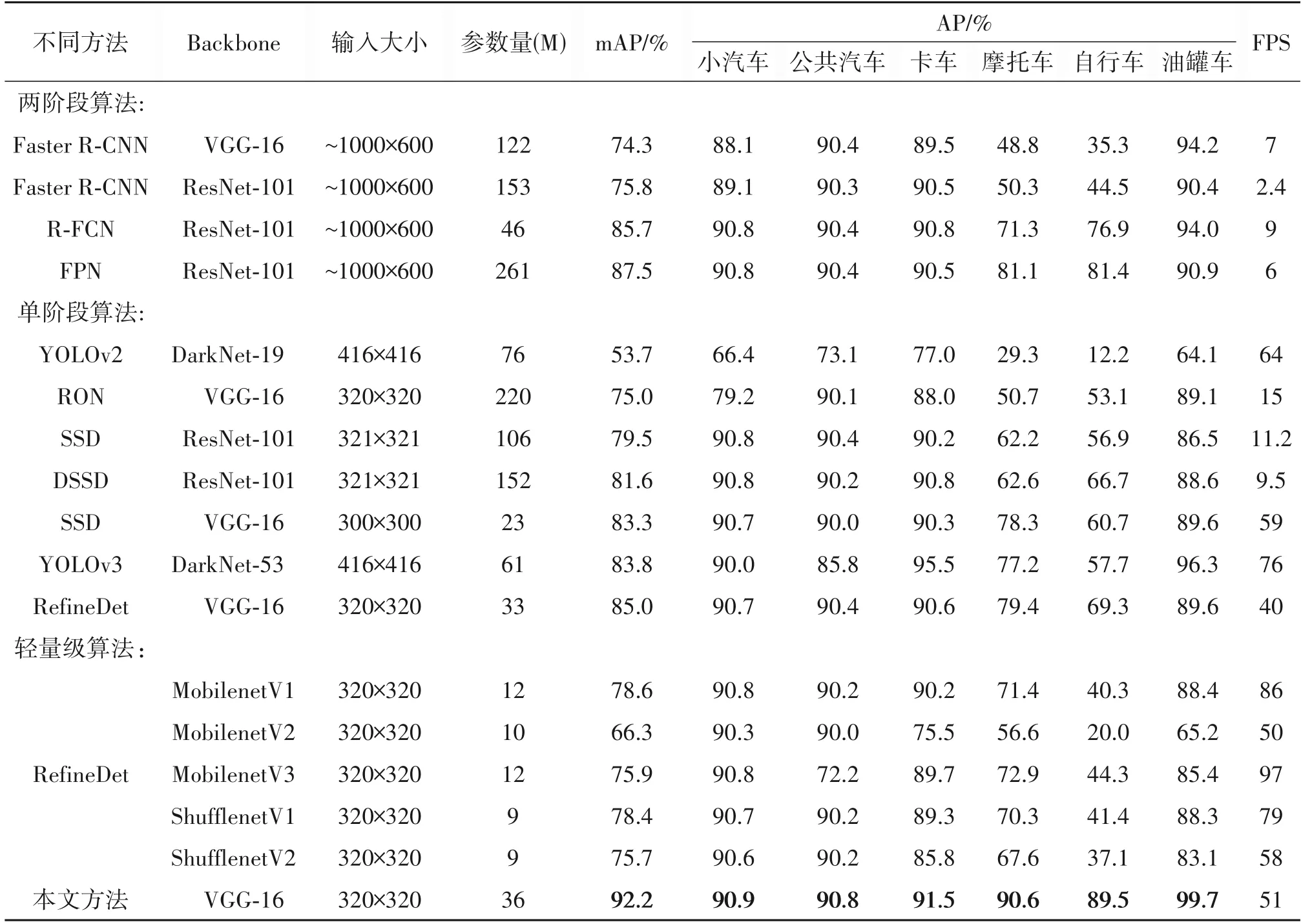
表8 XDUAV数据集上不同检测方法的结果对比Tab.8 Results of different detection methods for XDUAV dataset
3.7 Stanford Drone数据集的实验结果
为进一步证明提出的无人机视角下弱小目标车辆检测算法的鲁棒性,本文同时在Stanford Drone 数据集上对其进行评估。在Stanford Drone数据集上做了和XDUAV 数据集上同样的消融实验以及整体性能的对比实验,如表9 所示。本文提出的方法能够达到90.8% 的mAP,同时比经典的高性能两阶段目标检测算法Faster RCNN、R-FCN、FPN 以及实时性单阶段目标检测算法SSD、YO⁃LOv3、RefineDet 分别高出14.9%,4.2%,2.0%和12.6%,10.8%,4.7%,同时检测性能更要优于轻量级网络MobileNet 和ShuffleNet 作为主干网络的检测算法。图6 显示的是本文方法在Stanford Drone数据集上的一些检测结果。Stanford Drone 数据集的实验结果同样可以证明本文所提方法的鲁棒性。

表9 Stanford Drone数据集上不同检测方法的结果对比Tab.9 Results of different detection methods for Stanford Drone dataset
4 结论
本文提出的基于特征信息增强的无人机车辆实时检测算法,不仅为浅层特征融入了有利于分类的深层语义信息,更为重要的是为深层卷积特征融入了有利于定位的中低层信息,同时利用有效的特征融合模块将LMFN网络产生的多尺度中低级信息更好的融入到深层卷积特征中,并利用多空洞率卷积丰富目标周围的信息。实验结果表明,本文算法能够实现各种复杂交通场景下的弱小目标车辆的实时检测,并达到很高的检测精度。但在视频车辆检测中容易出现丢帧现象,因此后续将利用视频间的帧间关系对无人机视角下车辆目标进行更加准确的特征表示,可以利用帧间相关性对遮挡车辆实现进一步推理完成目标的精确检测。
