古汉语词义标注语料库的构建及应用研究
2022-06-21郭懿鸾王慧萍张学涛胡韧奋
舒 蕾, 郭懿鸾, 王慧萍, 张学涛, 胡韧奋
(1.北京师范大学 中文信息处理研究所,北京 100875;2.北京师范大学 人文宗教高等研究院,北京 100875;3. 北京师范大学 汉语文化学院,北京 100875)
0 引言
词义标注语料库通常需要根据某个词典对多义词各个义项的定义,在真实的语料上标注多义词的准确义项[1]。英语词义标注语料库的研究起步较早,由英国Sussex大学主办的SENSEVAL英语词义消歧评测推动了该领域的研究。英语词义标注语料库有基于词典义项的SENSEVAL-1语料库和以WordNet为词义系统的SemCor语料库、DSO语料库、SENSEVAL-2语料库,以及结合WordNet和Wordsmyth知识库的SENSEVAL-3语料库。在SENSEVAL评测中,研究者进一步加入外部知识库,完善了竞赛提供的词义标注集,相关研究如Wu等[2]和Palmer等[3]。作为基础语言资源,词义标注语料库可以服务于有监督的词义消歧,进而为语言理解、机器翻译和词汇学研究提供支持。例如,Chan等[4]利用词义标注语料库建立消歧模型,并应用于机器翻译系统,有效改善了翻译效果。Hu等[5]利用牛津英语词典的例句建立词义标注语料库,并借助BERT语言模型实现了细粒度的历时词义演变分析,从而揭示了义项竞争和合作的规律。
现有的汉语词义标注语料库以现代汉语为主,如北京大学汉语词义标注语料库(STC)、台湾“中研院”中文词义标注语料库SSMS、新加坡国立大学华文教材词义标注语料库、汉语二语教学词义标注语料库等。北京大学的STC语料库基于《现代汉语语义词典》的词义体系,对1998年1月和2000年1-3 月的《人民日报》(总计约642万字)进行多义词义项标注,共标注了966个多义名词和动词的义项[6]。截至2005年底,台湾“中研院”词义标注语料库SSMS共包含约2 000个现代汉语中频词,共涉及约5 900个义项[7]。新加坡国立大学的中小学华文教材词义标注语料库依据《现代汉语词典(第五版)》的词义体系,对新加坡国立大学的中小学华文教材语料库(约200万字)进行词义标记[8]。汉语二语教学词义标注语料库以《现代汉语词典(第六版)》为词义区分体系,对197册汉语二语教材文本中的1 181个多义词进行词义标注,构建了约350万字的词义标注语料库[9]。
现代汉语词义标注语料库以词典为基础,对新闻、教材语料开展加工,有了较为充分的积累。与之相比,古汉语语言资源的建设仍然较为薄弱。古汉语以单音节词为主,其一词多义现象十分突出,且在不同历史时期的词义分布状况有较大差异。建设古汉语词义标注语料库不仅有助于研究古代词汇的使用状况,也可作为基础资源服务于词义消歧算法的研究,为古汉语信息处理技术、词汇学本体研究、词典编撰等提供参考。
因此,本文选取了古汉语常用词汇,综合经典辞书和语料库实际使用状况对多义词进行义项区分和属性整理,并据此开展词义标注,建成了超过117万字规模的古汉语词义标注语料库(1)本文所构建的古汉语词义标注语料库参见: https://github.com/iris2hu/ancient_chinese_sense_annotation。以该库为基础,本文基于BERT语言模型研究了小样本情境下的词义消歧技术,准确率达到80%左右。进一步地,本文以词义历时演变分析和义族归纳为案例,初步探索了语料库与词义消歧技术在语言本体研究和词典编撰领域的应用,以期为自然语言处理技术在古汉语领域的应用,如文白机器翻译、文言文信息抽取、古汉语词汇语法现象研究等提供参考和借鉴。
1 基础词义知识库构建
1.1 选词的原则
本研究的目标词为古汉语常用单音节多义词。综合考虑词频和学术研究需要,筛选出了200个古汉语单音节实词,在后续研究中还将根据研究需要和用户反馈持续补充,进行版本迭代。根据国家语委古代汉语语料库字频表(2)古汉语字频表: http://corpus.zhonghuayuwen.org/resources.aspx,第一阶段选词有较高的使用频度,如表1所示。在频率排序上,51.5%的所选词在古汉语字频表中排名前500,80.5%的所选词在古汉语字频表中排名前1 000。
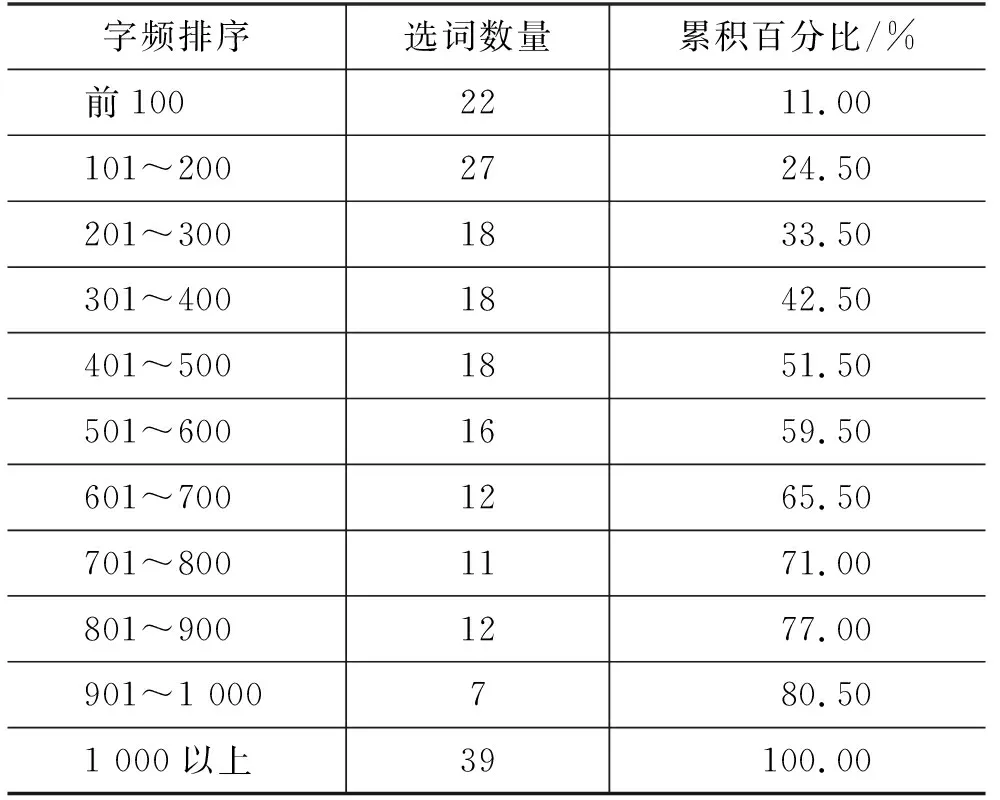
表1 选词的字频分布
1.2 义项的设立
词义知识库构建的关键任务是多义词义项的设立与区分。吴云芳和俞士汶[6]讨论了面向人的辞书义项和面向汉语信息处理的词语义项的区别,认为后者需要充分比较面向人和面向机器的词语义项,抽取、概括而成一系列义项区分的原则。肖航和杨丽姣[8]提出,词义标注语料库建设主要有两个难点: 一是词典词义区分不清晰,可能导致标注时出现两可的情况;二是词典义项不全面,无法包括真实语料中目标词所有可能的含义。从前人研究可以看出,词义标注语料库中的义项设立,既需要尊重辞书描写,也需要考虑语言事实和后续信息处理加工的需要。同时,值得注意的是,古汉语词汇在数千年的使用中,产生了极为丰富的引申、活用、借用等现象。与现代汉语的词义归纳侧重共时用法有所不同,古汉语的词义描写具有时间跨度大、复杂性高等特点,这也就导致了不同的辞书对同一多义词的义项设立存在较大差异。
以“兴(xīng)”为例,《王力古汉语字典》《汉语大字典》《辞源》及商务印书馆《古代汉语词典(第2版)》对其义项划分差异较大。其中,《王力古汉语字典》分列4个义项,《辞源》6个,《古代汉语词典》8个,而《汉语大字典》则有14个义项。各辞书的义项区分如表2所示。

表2 各辞书对“兴(xīng)”的义项区分
词典对标注质量有着极为重大的影响。词典的选择必须具有专业性、被认可度高、对词语义项描述清晰等特点。《王力古汉语字典》兼具“概括性”和“时代性”,可以直观地解释义项的类聚与引申。《王力古汉语字典·序》中提出字典具有“扩大词义的概括性”和“注意词义的时代性”的特点。就“概括性”而言,王力认为: “一般字典辞书总嫌义项太多,使读者不知所从,其实许多义项都可以合并为一个义项,一个是本义,其余是引申义。本书以近引申义合并,远引申义另列,假借义也另列。这样,义项就大大减少,反而容易懂了。”就“时代性”而言,《王力古汉语字典》在《凡例》指出: 本字典的义项按照“本义在前,引申义在后;通用义在前,非通用义在后;实词义在前,虚词义在后;古义在前,后起义在后”的原则排列,体现出较强的时代性和系联性,体现出了义项之间的关系。
而《汉语大字典》具有“粒度细”“涵盖广”的特点,恰好与《王力古汉语字典》在义项设立的宽严方面形成互补。《汉语大字典·第二版修订说明》称该字典力求“古今兼收、源流并重”,“不仅注重收列常用字的常用义,而且注意考释常用字的生僻义和生僻字的义项……是新中国成立以来形音义收录最完备、规模最大的一部汉语字典”。
结合《王力古汉语字典》和《汉语大字典》构建基础词义知识库,兼顾了“概括性”、“时代性”和“涵盖性”,能有效应对古汉语的词义描写时间跨度大、复杂性高等特点,满足词义标注语料库的需要。
因此,本文拟以《王力古汉语字典》为基础、《汉语大字典》为补充,对多义词的义项设立进行初步划分。除了基于辞书信息进行义项的设置之外,词义标注语料库还需要从语言事实和信息处理的需求出发,根据语料标注情况对词典义项进行一定程度的增补、删减与合并。
确立上述原则后,本研究首先设计了词义知识库的框架,其各属性字段如表3所示。除了词语和义项的基础属性外,还引入了义族、义项属性等信息,以呈现古汉语词义的类聚、引申和假借等特殊现象。同时,根据标注语料库中的义项出现情况设置了“义项频次”字段,为进一步的义项修订提供参考。
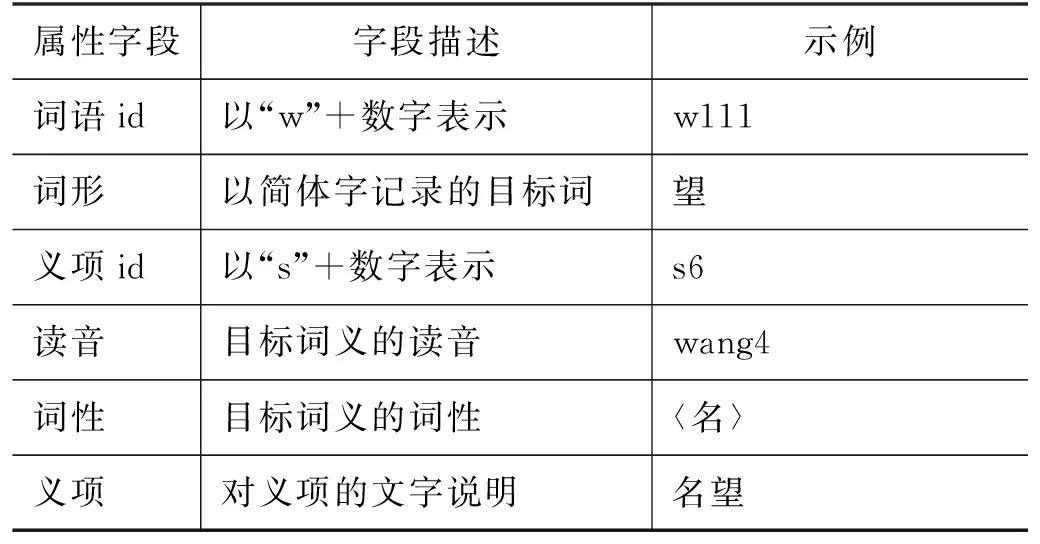
表3 词义知识库各属性字段
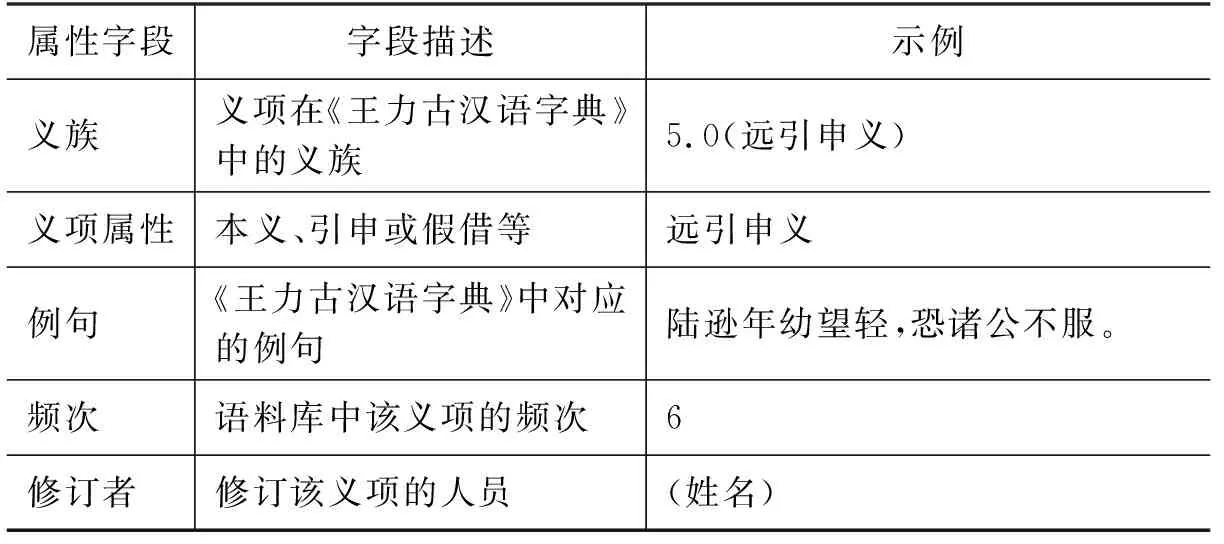
续表
在义项整理的过程中,按照如下步骤进行词义知识库属性填充。第一步,根据《王力古汉语字典》确立基础义项,将词语和义项的属性填入表中。然后,根据词典中的义族信息确立义族编号和义项属性: 义族以a.b的形式编号,a对应王力划分的义项,b对应同一义项内的小类。义项属性包括“本义”“近引申义”“远引申义”“假借义”“后起义”“晚起义”“偏僻义”,具体定义如下:
(1) 本义: 《王力古汉语字典》中的第一个义项;
(2) 近引申义: 与本义合并在同一义项内的为近引申义;
(3) 远引申义: 由本义引申,但列为另一个义项的引申义;
(4) 假借义: 《王力古汉语字典》另列的假借义;
(5) 后起义: 魏晋至唐宋产生的词义;
(6) 晚起义: 元明以后产生的词义;
(7) 偏僻义: 《王力古汉语字典》收录在“备考”栏中的少见的词义。
以“假(jiǎ)”为例,《王力古汉语字典》中义项为:
① 借。引申为凭借。②暂摄职务为假。引申为非真的,伪的(后起义)。【备考】大。
词义知识库与《王力古汉语字典》义项的对应如表4所示。
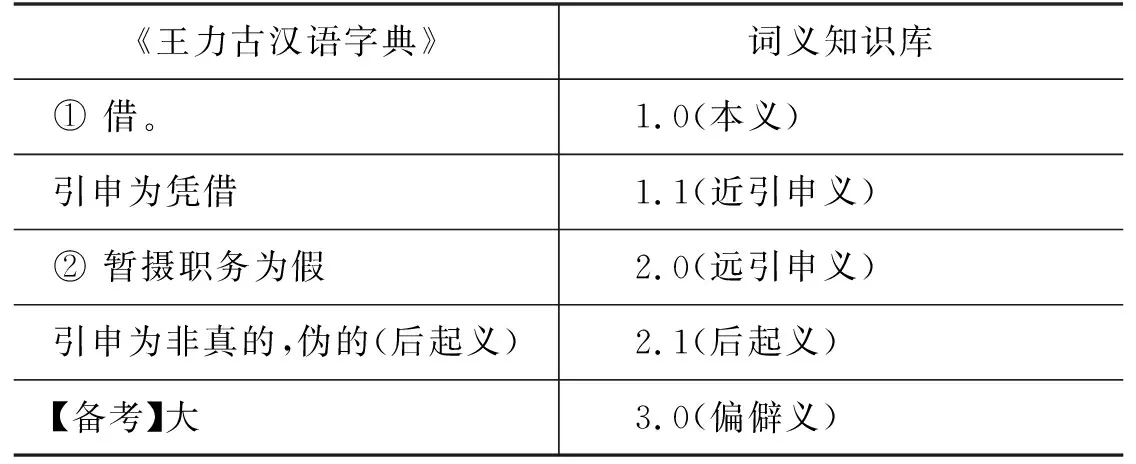
表4 词义知识库与《王力古汉语字典》义项的对应
最后,词义知识库还需要根据语料的实际标注情况填充义项频次,并据此进行增、删、合并等操作,该步骤的操作方式可参见本文第2节。
1.3 义项整理中特殊语言现象的处理
1.3.1 同形词问题
区分义项时该如何处理同形词?吴云芳和俞士汶[6]认为,在面向中文信息处理的现代汉语词义区分体系中,可将同一个词的不同义项与同形异义词放在同一个平面上,而无须严格区分同形和多义。在中文信息处理实践中,区分同形词与区分多义词的实际义项遵循相同的过程,即根据语境选择该词形下的某个含义。然而,在古代汉语中,同形词事实上由不同的古代词形表示,只是受到汉字简化的影响而变成了今天在简化字书写范畴下的古汉语同形词,如“后”(皇后)和“後”(先后),这些同形词不仅在传统辞典中有分立的词条,而且在各词内部也有相对独立的词义引申链条。因此,本文认为,吴云芳和俞士汶所提出的应用驱动的观点是切实合理的,而本研究针对古汉语语言现象进行处理,也应兼顾同形词不同词形的独立性,在标注形式上有所体现。
具体来说,本文通过如下方式进行同形词的义项梳理。以“后”为例,根据辞书记载,“后”这个字形共对应了两个同形词,在字形栏分别用“后1”“后2”标注,“词语id”栏则用词语序号+字形序号标注。每个不同的“后”各自有本义、引申义,被看作是两个起点不同的引申链,互相之间没有联系,义项编号也各自从s1开始。特别地,在同形词各自的义项编号前,由一位数字来区分同形词。这样的标识方法在基于大规模语料库的信息处理实践中也具有一定的灵活度。表5显示了同形词“后”的义项区分标注方法。
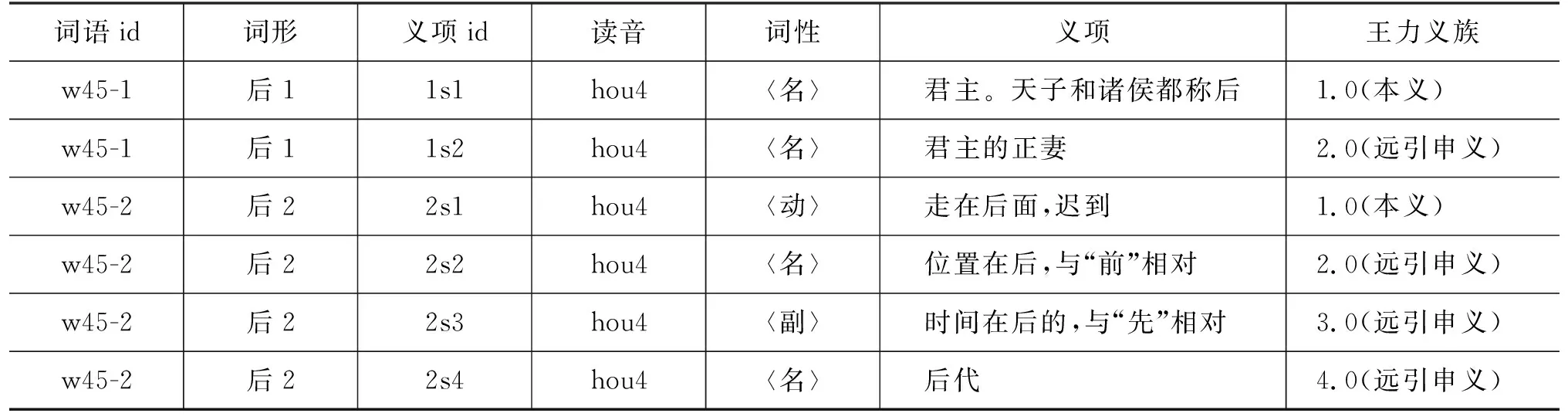
表5 同形词“后”的义项区分标注方法
1.3.2 临时用法或通假
张永言在《词汇学简论》中提出,词的临时用法是词在个别的特殊的应用场合临时带上的含义,比如“行将就木”中的“木”临时具有了“棺材”的意义[10]。词的意义和词的用法存在一定差别,意义是稳定和普遍的,而用法是不稳定的、特殊的。所以我们在面对词义活用、通假和其他临时用法时,应根据它的出现频次判断是否需要设置义项,以确保词义的代表性和典型性。若词的某种临时用法较为常见,则需要为它设立新的义项,来保证词义知识库能涵盖尽可能多的用例。
例如,词语“殆”在《王力古汉语字典》中的义项“通‘怠’,懒惰,疲惫”属于假借义,例句如“学而不思则罔,思而不学则殆”。首先根据《王力古汉语字典》设立该义项,在随后的语料库标注过程中,有12句语料中的目标词“殆”属于该义项,因而确定设立该义项。又如“奇”的活用义“以……为奇,惊异”在《王力古汉语字典》中收录,且在语料库中有可观的频次,如例句“大将军邓骘奇其才,累召不应”,因此设立为义项。另外,我们亦设立了一些辞书未收录的临时用法义项,其考量标准是在语料中的频次。如“城”的活用意义“守城”并未在辞书中列出,但在语料库中的例句“(李)应庚发两路兵城南城”“丞相尝使籍福请魏其城南田”等均应属于“守城”意义,共约10句语料,因此也设立该义项。
一些特殊的、不常见的临时用法则不收入知识库,例如,“及其为天子三公,而立为诸侯贤相,乃始信于异众也”,高诱注“信,知也”,可知“信”在语境中是“知晓”的含义,属随文释义,意义具有临时性,因而不设立义项。又例如,“尚得推贤不失序”中的“得”应为“德”的借字,属名词用法,含义为“德,道德,有德之人”。考虑到“得”“德”的借用在语料库中较为罕见,所以不设为新义项。同理,“右”的“通‘侑’,劝食”义,“方”的“通‘谤’,指责别人的过失”义出现在极少量语料中,皆属此类,均不为临时用法新增义项。
1.3.3 专有名词
在实际语料标注中,发现不少词例为专有名词,例如,“诵”在句子“冬十一月,遣使册高丽国王诵”中应当被解释为人名;“视”在句子“以真时南北差加减之,为食甚视纬”中属于天文术语;“孰”在句子“上诏王僧辩镇姑孰以御之”中属于地名“姑孰”。绝大部分作专名的用法并未被传统辞书收录,而使用频次却相当可观。为了服务于后续的语言学及信息处理研究,本研究对专有名词单独设立义项编号: s0,并按照表6所示规则标注具体的专有名词类别。
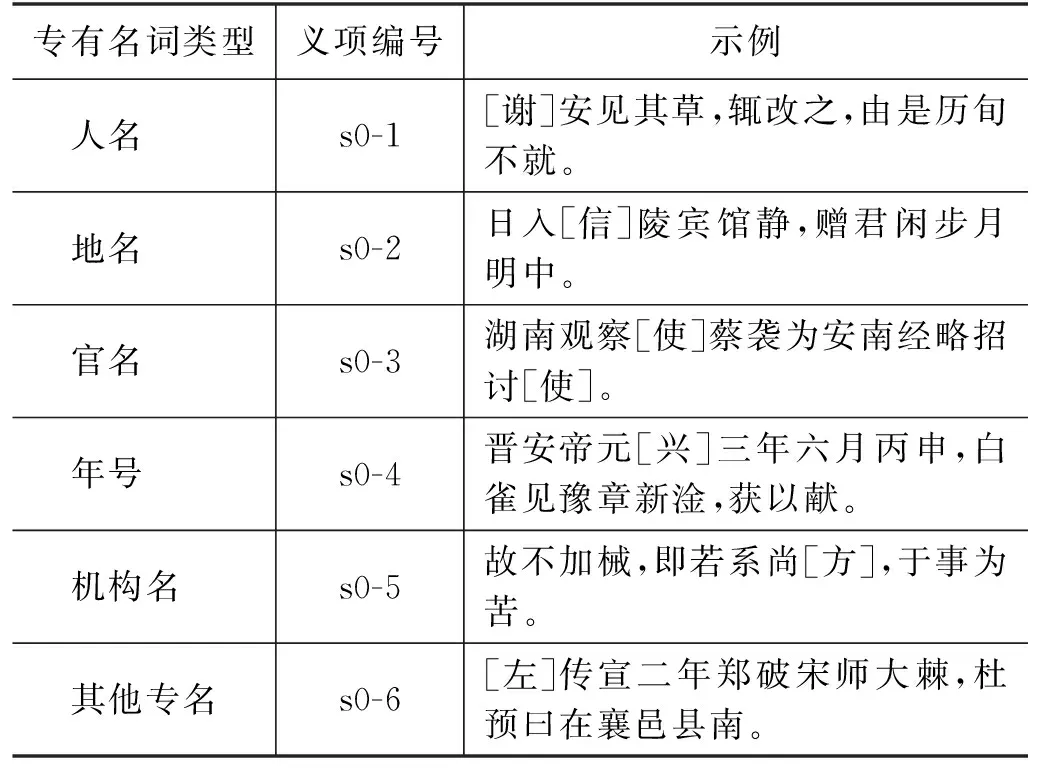
表6 专名标注示例
在实际的语料标注过程中,共有约1 800个例句的目标词被标注为专有名词,接近语料库规模的4.7%。
2 词义标注
完成了基础词义知识库的构建后,本研究依据词义知识,在语料库中标注目标词的义项,并根据标注结果对词义知识库中的义项进行增补、删除、合并等操作。
2.1 语料采样及预处理
从古汉语词义标注语料库的建设需求出发,本研究认为语料选取应符合如下原则: ①句子完整、句长适中,以提供较为明确的语境信息; ②语料均衡,覆盖了不同时代和文献类型,尽可能体现词义使用和分布状况; ③无文本内容之外的特殊符号和标记。
根据上述原则,本文将语料采样的范围设定于“语料库在线”古代汉语语料库(国家语委语料库)和CCL古代汉语语料库,二者均为研究者广泛使用的古代汉语语料库,采用简体字加工,具有体量大、收录全、覆盖不同朝代等特点。从上述语料库中抽取含有目标词的句子,每个目标词随机抽取200条语料,并保证其朝代分布的均衡性。随后,去除语料中的特殊标记。
2.2 词义标注实践
根据基础词义知识库,由汉语言文字学、古典文献学专业研究生开展语料标注工作,具体遵循如下步骤。
(1) 标注义项。根据目标词在语境中的含义,从义项表中选择义项编号。对于无法找到对应义项的情况做如下标记: 若目标词属于专有名词,则按上文所述专名编号标记;若目标词义属于知识库未收录的义项,则标为“其他”;若根据上下文难以判定义项归属则标为“待定”;若存在句子不完整情形或目标词在该语境中有歧义,则标记为“语料不宜”。
(2) 搜集标注反馈,统计义项频次信息,并结合词典描写调整知识库中的义项列表,对词义知识库中的义项做出新增、删除、合并等操作建议。具体来说,包括如下几种情形: ①若语料库中该义项出现至少2次,则在词义知识库中保留该义项。②若义项在语料库中未出现或仅出现1次,参考《汉语大字典》的义项设立和例句情况,如果其为《汉语大字典》独立收录且有例句佐证用法,则保留,否则建议归并或删除: 如该罕见义项与其他义项存在较高相似性,则建议归并,否则建议取消该义项的设立。③针对标注中发现的“其他”义项,如果为《汉语大字典》收录且具有可观频次,则建议为其新增义项;如果两部辞书均未收录,且仅在少量语料中出现该意义,则不设立新义项,例如,包含目标词“绝”的一条语料: “乡中少年闻其美,神魂倾动,媪悉绝之。(《聊斋志异》)”,根据文义应当属 “拒绝”义,但两部辞书中“绝”字均无“拒绝”义。考虑到此义项出现情况较少,且不宜和其余义项合并,因而不新立义项。
(3) 针对上述操作中给出的新增、删除、归并等建议,由汉语言文字学、中文信息处理专业教师再次审订后,确认词义知识库的修订。
(4) 根据修订后的词义知识库对语料标注结果进行修订,以确保修订后的词义知识库和语料标注中义项的一致性。同时,将词典中的例句也作为补充加入语料库。
(5) 开展知识库和语料库校对工作,首先由高年级汉语言文字学研究生对语料库中的“待定”“其他”等条目进行校对,给出合理的标注建议;然后由项目组师生对词义知识库和语料标注结果做再次校对。
3 语料库整体规模和义项分布概览
3.1 整体规模
第一阶段的古汉语词义标注语料库共收录200个单音节多义词,词义知识库中收录的词语义项数量为2 007个,加上专名义项编号6种,共有2013个义项,平均每词义项数量10个。其中,有5个义项未出现在语料库标注中,这些义项被《王力古汉语字典》或《汉语大字典》认为属于本义,但未列出例句用法,如“尽”的本义“器物中空”。考虑到这些属于本义的义项在引申链的构建中具有较大的意义,因此保留这些低频义项备考。
目前,词义标注语料库收录38 720条标注数据,总计117.6万字。除专名外,标注语料库中的总义项数量为2 002个,每条语料仅对唯一的目标词进行标注。
3.2 义项分布概览
语料库中义项频度信息如图1所示,其中,大量的义项仅出现1次,出现次数在5次及以下的义项占比51.85%,主要原因推测有两方面: ①古汉语历时跨度长,不少义项仅在个别或少数朝代使用,整体的频次较低; ②在同一个词形下,存在使用优势的义项占据主导地位,使得其他义项比例较低。
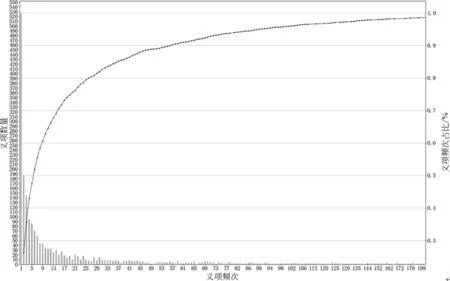
图1 语料库中的义项频次分布情况
为了解词义分布的真实情况,仅依靠统计词义标注语料库中对应目标词的标注结果(约200条/词)是不够的,因而我们可通过有监督的词义消歧技术,对大规模语料进行义项标注,从而获得义项真实的分布情况。
4 词义标注语料库的应用
4.1 古汉语词义消歧
依托词义标注语料资源,可以实现有监督的多义词消歧。Hu等[5]以牛津英语词典的例句作为训练语料,将每个义项不多于10条例句作为训练集,通过BERT语言模型获得各个义项的语境向量表示。针对新语料中的目标词,计算该词的语境向量与该词形各个义项向量的相似度,将相似度最高的义项确定为该句中目标词所属义项。类似地,本研究尝试将义项标注语料库资源划分为训练集和测试集,开展词义消歧实验。
本研究采用的语言模型来自胡韧奋等[11]构建的古汉语BERT模型,该模型由总计33亿字的殆知阁古代文献藏书2.0版语料库训练而成。由于训练语料库中繁简体混杂,考虑到繁体转简体的准确率更高,模型研发者将训练语料统一转换为简体。本研究选择该模型进行词义消歧,是因为其训练语料和本研究所使用的语料较为接近,均来自存世古代汉语典籍,且都有朝代跨度广、涵盖文体多的特点。
考虑到古汉语词义标注语料库中,每个义项下的例句样本较小,实验设定了2~10共9种阈值,在不同阈值下进行词义消歧实验。阈值表示对于某一个义项,若例句数量超过该阈值,则将其纳入消歧实验。设立不同阈值可以较好地检验和对比小样本情境下消歧方法的效果。当某个义项的例句数量为2、3、4时,实验划分出1条例句作为测试,其余例句归入训练集。当阈值大于或等于5时,按照8: 2的比例划分训练、测试集。考虑到语料库中约52%的义项只有1~5条例句,这样的划分方法能够较为真实地反映词义消歧模型的效果。
不同阈值下词义消歧的数据划分结果及准确率如表7所示。
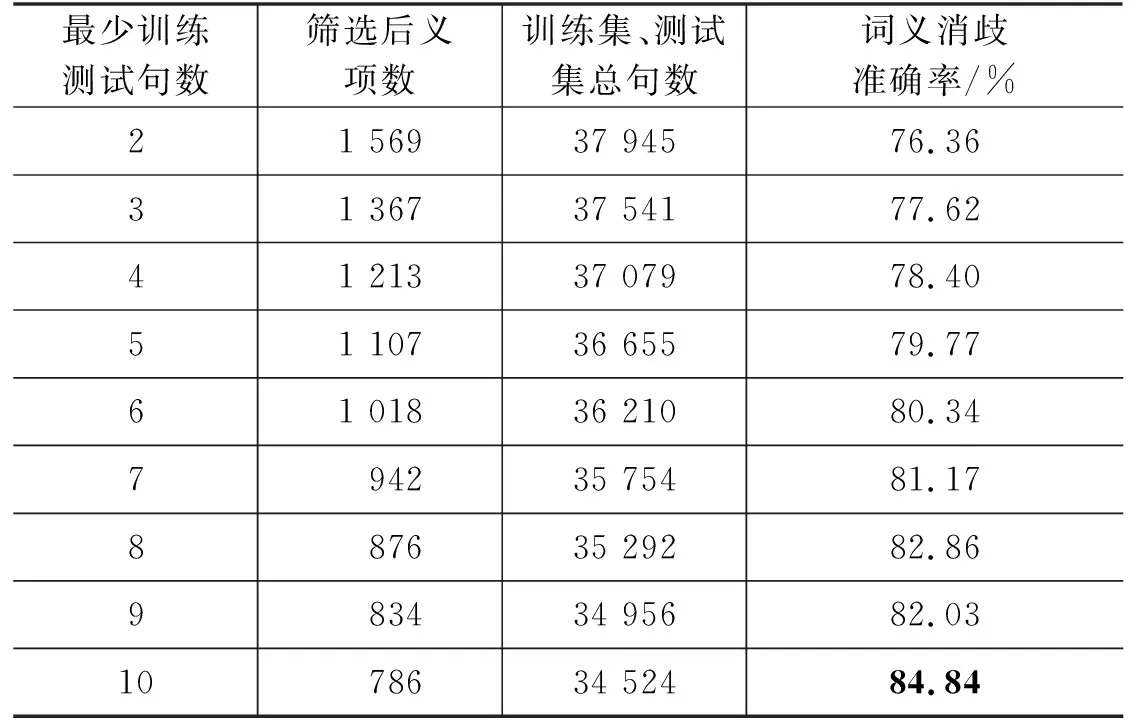
表7 词义消歧实验数据
句子数量阈值为2时,模型达到了高于75%的准确率,而随着阈值的增高,消歧准确率也进一步提高,当训练样本数量达到5(即阈值取6)时,词义消歧准确率达到80%以上。实验结果显示,本研究构建的古汉语词义标注语料库可以作为词义消歧技术的基础语言资源,基于BERT语言模型的小样本词义标注方法达到了一定的准确率。如能进一步有针对性地人工增补例句,确保每条义项的例句数量达到一定阈值以上,该方法将可能取得更好的效果。
接下来,我们对低阈值和高阈值下模型判断错误的数据进行人工分析,归纳总结出两种典型的情况:
典型情况一: 阈值的提升纠正了原本判断错误的义项。例句“束书辞东山,改服临北风。”中的目标词“书”正确的义项应为“s4-书籍,装订成册的著作”。在阈值为2时,目标词被模型自动标注为“s2-文字”,属于标注错误的案例。而当阈值为10时,义项被正确标注了。对此本文认为可能的原因是: 阈值较高时,低频义项不参与训练,这减少了目标词在义项消歧时的候选义项数量,增加了消歧准确率。另外,相较于高频义项,低频义项由于参考例句较少,其义项向量难以得到充分的表示。
典型情况二: 高阈值时仍然判断错误的义项。目标词“慕”在例句“汤、禹久远兮,邈而不可慕。”中的正确义项为“s2-羡慕”,而模型标注为“s1-思念,依恋”。原因可能是这两个义项本身较为接近,且上下文未提供足够信息。类似的误判有: “九者彼来加我,志在不报。”的“报”本应标为“s1-报答,报酬”,却被模型标为“s7-报复”;例句“子思,字众念,性刚暴,恒以忠烈自许。元天穆当朝权,以亲从荐为御史中尉。”中的目标词“朝”本应标为“s3-朝廷”,而被模型标为“s8-政事”。
4.2 古汉语历时词义演变
历时词义演变研究依托大规模的历时语料库,旨在还原多义词义项在一段历史时期内频率的变化,发现词语义项产生、消亡和义项之间的竞争等关系[12]。在本研究中的词义消歧模型获得一定准确率的基础上,可以使该模型自动标注大量历时语料中的目标词词义,从而获得义项的历时分布。
本文以多义词“使”为例,从国家语委古汉语语料库中随机抽取20 000条带有时代信息、且包含目标词“使”的语料,以词义标注语料库中所有目标词为“使”的例句作为训练集,建立目标词“使”的词义标注模型。用该模型对20 000条带有时代标签的语料进行义项自动标注,梳理各个主要义项的历时分布情况,对曲线进行四次多项式拟合,其结果如图2所示。
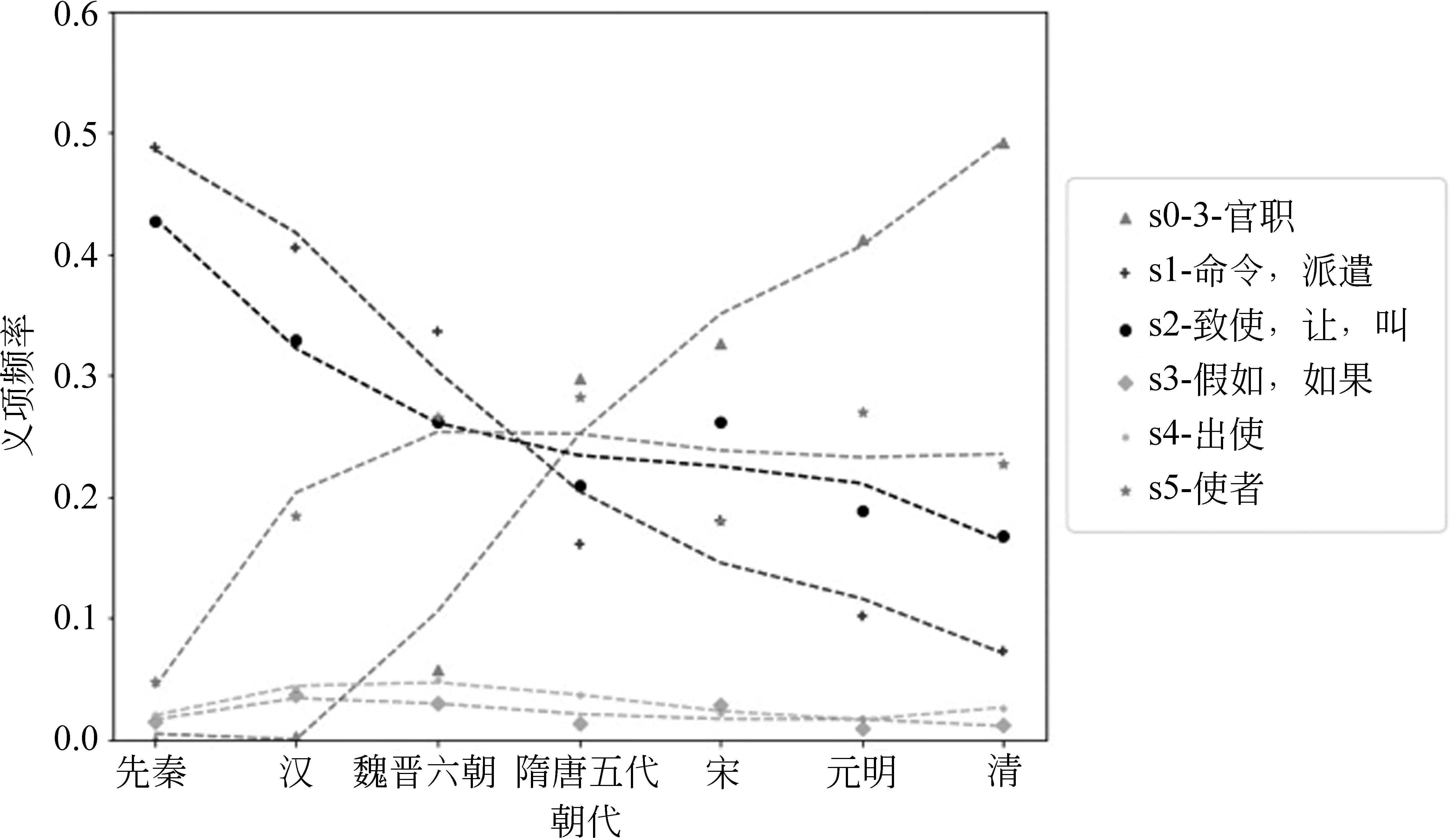
图2 “使”各义项的历时变化趋势
从图中各义项的历时变化趋势可见,“使”作为(君主)使者的含义在先秦即有,而作为官职名称则可能在汉代以后出现,随后激增。到了清朝,“使”作为官职名称成为文献中最常见的义项。相反的,“命令、派遣”和“致使”意义在先秦频率较高,但二者的占比在后期总体呈现下降趋势。
4.3 辅助词典编撰
除了历时词义分析之外,各义项的向量表示也可以作为词典划分义族的参考。本文根据词义标注语料库,使用古汉语BERT语言模型获得了多义词“望”的各义项的向量表示。通过计算各义项向量之间的余弦相似度或采用层次聚类方法,可以获得各义项之间的亲疏关系。层次聚类图中,目标合并的先后顺序标志着所属类别的远近。另外,对词义向量做PCA降维,可以直观地在语义空间图中查看义项之间的位置远近。以词语“望”为例。在《王力古汉语字典》中,“望”未单列“希图,企图”和“向,对着”义项,这两个义项被《汉语大字典》单列,且在实际标注过程中分别有22和13条例句被标为该义项,因而我们在词义知识库的构建过程中新增了这两个义项。为了描述这两个义项与其他义项之间的关系,本文采用层次聚类的方法,以常用的欧氏距离作为距离计算公式。如层次聚类图(图3)所示,首先目标义项“向,对着”和“远望”合并、另一个目标义项“希图,企图”和“期望,盼望”合并,接着这两个小类合并后,与“名望”合并,最后,两个边缘义项“望日”和“遥祭”合并后再并入其中。

图3 “望”各主要义项的层次聚类情况
进一步地,如图4所示,降维后的语义空间反映了义项向量在三维空间中的相对位置关系,虽然降维过程丢失了高维空间中的一些细节,但是还是可以直观地看到义项“遥祭”和“望日”属于边缘义项,而“远望”和“向,对着”,“期望,盼望”和“希图,企图”之间两两具有紧密联系。

图4 “望”各主要义项向量在降维后的语义空间中的相对位置
因此本文认为“望”的义项“希图,企图”和“向,对着”有可能属于引申义,“希图,企图”与“期望,盼望”义项关系密切,“向,对着”和“远望”义项之间关系密切。考虑到义项“远望”在《王力古汉语字典》中被认为是本义,而《汉语大字典》中义项“向,对着”的最早用例来自马王堆帛书的“日月相望”,则推测义项“向,对着”是由本义经过语法化的过程而产生的近引申义。5结论本文以古汉语词义标注语料库为研究对象,基于传统辞书和语料库中的义项频率,设计了古汉语多义词的词义划分原则,以200个常用古汉语单音节多义词为例,构建了词义级别的知识库,并据此对包含多义词的语料开展词义标注。现有的语料库包含3.87万条标注数据,规模超过117万字,丰富了古代汉语领域的语言资源。实验显示,基于该语料库和BERT语言模型,词义消歧算法准确率可达到80%左右。在此基础上,本文介绍了该语言资源在古汉语词义历时演变研究、辅助词典编撰中的应用案例。未来,该资源和相关算法还为文白机器翻译、文言文信息抽取、古汉语词汇语法现象研究等提供参考和借鉴。值得一提的是,本研究提出的古汉语词义标注语料库依然存在规模较小的问题,为确保提升该资源的应用价值,我们将在未来的研究中对其做进一步的扩充和更新。
