基于机器学习算法建立脂肪肝预测模型
2022-06-20李运明
雷 丽,李运明
(1.西南交通大学数学学院,四川 成都 611756;2.西部战区总医院卫勤部医疗管理科,四川 成都 610083)
随着大数据技术的广泛应用,已有学者将大数据方法用于临床医学研究[1-3],基于机器学习方法建立预测模型已取得一定成果。此外,随着脂肪肝检出率逐年上涨,许多学者围绕脂肪肝防治工作也展开了大量研究[4-6]。脂肪肝是弥漫性肝病之一,前期临床反应不明显,若不加以治疗可能会演变成严重肝病。但由于脂肪肝具有可逆性,研究基于纵向体检数据,采用机器学习算法建立较为精准的脂肪肝风险预测模型用于脂肪肝相关指标定期筛查,为脂肪肝易发人群健康管理及风险评估提供参考,提高了脂肪肝体检工作效率并减少相关医疗费用支出,具有较大的实用性。
1 资料与方法
1.1 资料来源
研究数据源自2006—2016年在西部战区总医院(原成都军区总医院)健康体检中心定期健康体检人群的体检数据(体检中心为该类人群建有专门软件用于管理体检数据资料),并且循证医学文献资料检索结果、临床指南等。
1.2 指标选取与赋值情况
将体检数据中共24个指标纳入动态分析,赋值情况[7-10]如表1所列。

表1 变量赋值情况Table 1 Variable assignment
1.3 统计学分析
研究采用Python3中的Scikitlearn机器学习软件进行统计分析,运用Logistic回归算法进行特征选择,确定脂肪肝相关指标。基于2006—2016年纵向体检队列资料抽样产生不同样本量的模拟数据,运用决策树(DT,decision tree)、XGBoost(extreme gradient boosting)、Bagging、随机森林(RF,random forest)、人工神经网络(ANN,artificial neural network)和支持向量机(SVM,support vector machine) 6种机器学习算法建立脂肪肝预测模型并评价预测价值。计量资料分析采用t/u检验,计数资料分析采用卡方检验,以P<0.05为差异有统计学意义。
2 机器学习算法模拟实验
2.1 Logistic回归模型筛选变量
基于2006年横断面体检数据,以是否检出脂肪肝作为因变量,以高血压、血红蛋白、总胆红素、谷丙转氨酶等指标是否异常作为自变量(变量及赋值情况见表1)。将单因素Logistic回归有统计学意义的影响因素筛选出来(筛选结果见表2),以便确定纳入机器学习算法的脂肪肝风险变量。
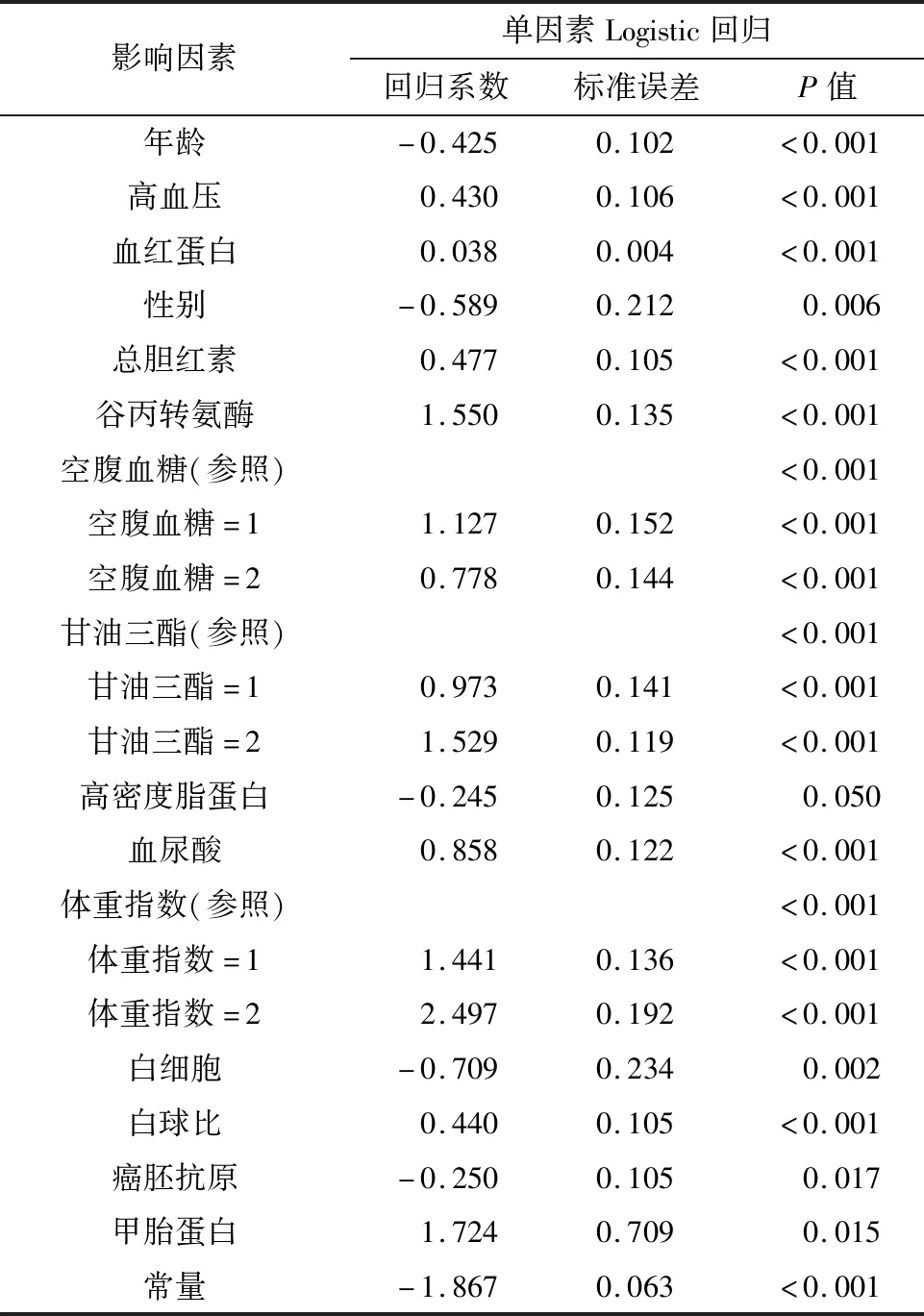
表2 Logistic回归模型变量筛选结果Table 2 Variable screening results of Logistic regression model
2.2 机器学习算法建模
既往脂肪肝预测模型以传统Logistic回归模型为主,旨在筛选脂肪肝影响因素,由于Logistic模型要求变量独立且不能处理变量共线性的问题[11],因此具有一定的局限性。已有学者将机器学习算法运用到临床医学领域,如朱立强等[12]采用支持向量机建立了Ⅰ类切口手术患者使用抗菌药物合理性的评价模型,模型预测精度明显高于其他文献报道结果;何玉花等[13]采用XGBoost集成算法建立了大于胎龄儿的风险预测模型;李桃等[14]采用随机森林算法建立了2型糖尿病并发颈动脉斑块的预测模型。而机器学习算法在脂肪肝预测领域应用极少,因此研究引入机器学习算法能够建立更为精准的脂肪肝预测模型,为脂肪肝防治工作增加新思路。
机器学习算法在脂肪肝预测领域的应用效果在体检数据中未得到验证,所以需要通过模拟实验进行评估,探究脂肪肝预测模型的稳定性。为了保证变量之间的协方差关系以及模拟数据与实际数据的一致性,研究基于实际数据抽样产生模拟数据[15]。
模拟实验方案如下:
(1) 提取观察对象一一对应的ID号作为抽样号码集;
(2) 提取体检数据中的检测指标数据和时间作为新的数据集;
(3) 从抽样号码集中随机抽取N(100,200,500)个样本;
(4) 以Logistic回归模型为模拟框架,给定特定的系数生成因变量,以均匀分布产生截尾时间,根据截尾时间和生存时间确定截尾情况;
(5) 抽取的结果作为模拟数据集,重复上述过程100次,得到100个模拟数据集,即模拟100次;
(6) 基于不同样本量的抽样模拟数据,分别建立6种机器学习预测模型,并比较6种机器学习算法的预测性能。
由于精确率(precision)和召回率(recall)在实际情况中会出现矛盾的情况,所以采用精确率和召回率的调和平均值(F-measure)以及标准均方误差(NMSE,normalized mean square error)作为衡量机器学习算法模拟实验效果的评价指标。
F-measure值计算公式为
NMSE的计算公式为
当样本量N分别取100、200、500,6种机器学习算法分别建立脂肪肝分类预测模型,重复模拟100次F-measure值的平均值如表3所列。由表3可见采用XGBoost算法建立脂肪肝预测模型的F-measure值在3种不同样本量情况下都最大。

表3 机器学习算法建模F-measure值Table 3 F-measure values modelled by machine learning algorithm
当样本量N分别取100、200、500,6种机器学习算法分别建立脂肪肝分类预测模型,重复模拟100次的NMSE的平均值如表4所列。由表4可见当N取100和200时,利用XGBoost算法建模的NMSE值最小,当样本量N取500时,支持向量机算法建模的NMSE值最小。通过模拟实验,选择XGBoost机器学习算法建立脂肪肝分类预测模型。

表4 机器学习算法建模NMSE平均值Table 4 NMSE values modelled by machine learning algorithm
3 实例分析
2006—2016年健康体检中心连续11年总参检24 106人次。男性21 777人次(90.34%),女性2 329人次(9.66%),研究人群中最小年龄34岁,最大103岁,平均年龄(67.79±12.90)岁。根据世界卫生组织有关老年人的定义,结合实际数据情况,将老年年龄的界限定为65岁[16]:年龄<65岁非高龄组10 774人(44.7%),年龄≥65岁高龄组13 332人(55.3%)。近年来,脂肪肝检出率呈逐年攀升趋势,采用卡方趋势性检验(χ2=228.71,P<0.001),脂肪肝男性检出率(15.6%)大于女性(9.3%)(χ2=7.899,P<0.05);高龄组脂肪肝检出率(12.8%)小于非高龄组(18.4%)(χ2=17.578,P<0.001)。
基于2006—2016年纵向体检队列数据,采用交叉验证法将其分为训练集和测试集。训练集用以训练机器学习算法,测试集用以评估模型的拟合效果与预测性能。采用ROC曲线下面积、准确率、召回率等指标评价6种机器学习算法建立脂肪肝预测模型的预测效果,具体数值如表5所列,ROC曲线对比情况见图1。
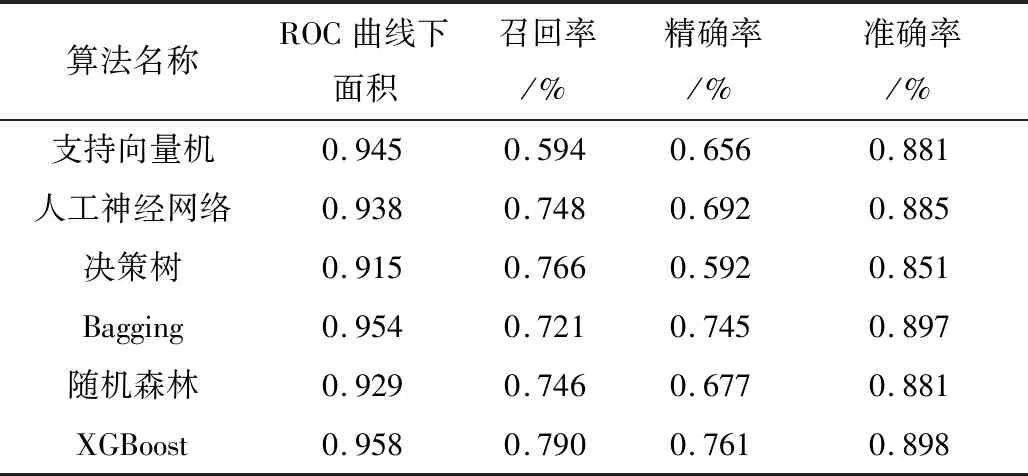
表5 评价指标对比情况Table 5 Comparison of evaluation indicators
由表5和图1可知,XGBoost算法建立的脂肪肝预测模型ROC曲线下面积为0.958,召回率为0.790,精确率为0.761,准确率为0.898,均高于其他机器学习算法。此外传统Logistic回归模型ROC曲线下面积为0.732,这远小于XGBoost预测模型,二者比较差异有统计学意义(P<0.05)。支持向量机的召回率较低,为0.594,决策树算法的精确率较低,为0.592。
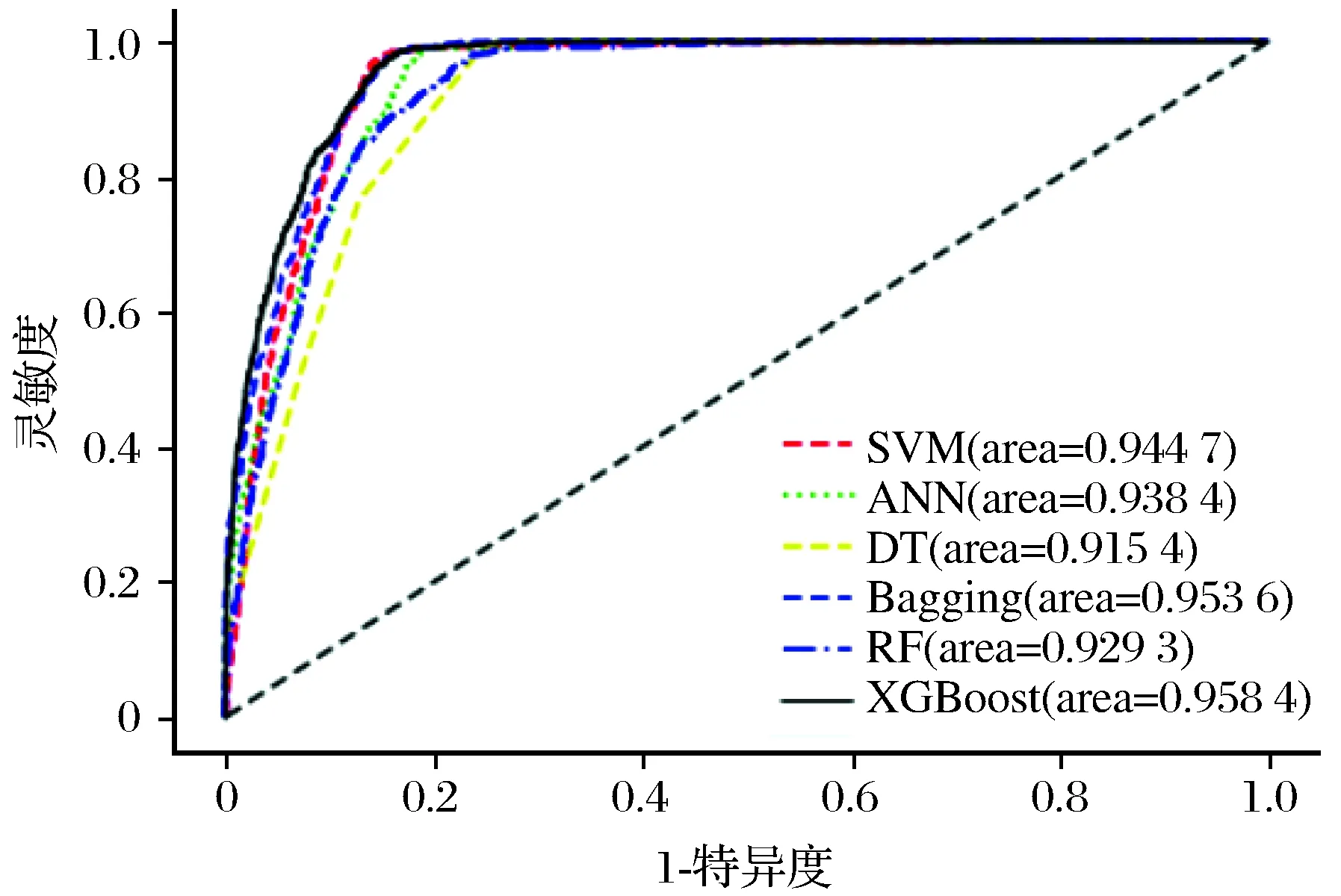
图1 机器学习算法预测模型ROC曲线对比Fig.1 ROC curve comparison diagram of prediction model of machine learning algorithm
综上所述,机器学习算法构建的脂肪肝预测模型综合性能较强,其中XGBoost集成算法表现最佳,具有非常大的潜在应用价值,值得更深一步研究。
4 讨论
机器学习算法具有限制少、预测准确的优点。已有学者将机器学习算法用到多个领域建立预测模型,而将机器学习算法运用到脂肪肝等慢性疾病预测的相关研究较少。2006—2016年慢性病检出率结果显示,脂肪肝检出率呈逐年上升趋势,男性检出率普遍高于女性。因此,建立精确有效的脂肪肝等慢性疾病的预测模型具有十分显著的实用性,有助于相关健康部门加强脂肪肝等慢性病预防和治疗的宣传活动,提高人们生活质量。
为了提高数据准确性,数据建模之前先进行缺失数据填补,并且利用单因素Logistic回归将有统计学意义的影响因素筛选出来,消除部分混杂信息的干扰。Logistic回归筛选出脂肪肝影响因素有:谷丙转氨酶、空腹血糖、甘油三酯、血尿酸、白细胞、年龄和体重指数等。王菊芳等[17]运用人工神经网络筛选出脂肪肝危险因素为低密度脂蛋白、谷丙转氨酶、空腹血糖、血尿酸、甘油三酯。除低密度脂蛋白外,其余变量都包含于本研究筛选结果中。
研究采用机器学习方法建立脂肪肝预测模型,初步尝试将人工智能的技术引入脂肪肝等慢性疾病的预防工作中。通过模拟实验从决策树、XGBoost、Bagging、随机森林、人工神经网络和支持向量机6种算法中选择建立脂肪肝预测模型的机器学习算法。XGBoost集成算法F-measure值最大,标准均方误差最小,所以选择XGBoost算法建立脂肪肝预测模型。实例分析中XGBoost建立的脂肪肝预测模型ROC曲线下面积、召回率、精确率和准确率均高于其他机器学习算法,传统Logistic回归模型ROC曲线下面积也远小于XGBoost预测模型。研究结果显示XGBoost集成算法具有较好的综合预测性能,适合用于脂肪肝等慢性病风险评估研究。在以后的研究中将继续探讨利用机器学习算法建立针对中国人群的其他常见慢性病风险预测模型,进一步为控制慢性病风险因素和精准医疗提供科学依据。
