非对称关键点注意力结构的交互式图像分割方法
2022-06-20孙刘杰樊景星
孙刘杰,樊景星
非对称关键点注意力结构的交互式图像分割方法
孙刘杰,樊景星
(上海理工大学,上海 200125)
人机交互信息在交互式图像分割过程中具有重要意义,为了提高交互信息的使用效率,文中提出一种优化方法。提出一种非对称注意力结构,将交互信息通过该结构融合到交互式图像分割算法(IOG)的特征提取网络中。该算法能够进一步强化关键点信息对图像分割所起到的引导作用。非对称注意力结构能够在不增加交互成本的条件下,在PASCAL数据集上达到92.2%的准确率,比目前最好的IOG分割算法提高了0.2%。仅在小样本PASCAL数据集上训练时,文中算法具有更明显的优势,比现有最好的IOG算法的准确率提高了1.3%。通过中文的非对称注意力结构,能够在不增加交互成本的同时提升网络的分割精度。
图像分割;神经网络;关键点信息;人机交互
在涉及图像处理和计算机视觉的项目中,图像分割往往是必不可少的一项技术。近年来,图像分割项目的热度始终维持在一个较高的水平。图像分割作为计算机视觉领域中众多基础性任务之一,体现出了较高的实用价值。
深度学习和神经网络一经提出就被认为高度契合图像处理的需求。从最初广为人知的Alexnet[1]到后来的Mask–RCNN[2],这些深度学习的方法能够通过卷积来提取图像特征,并且通过参数训练来对这些特征进行判断,从而精确预测出图像的类别或是实现图像的像素级别的实例分割操作。
实现图像语义分割的深度学习算法往往依赖着大量优质的像素级数据集。创建一个像素级的大型训练数据集来训练这些模型的过程,通常在消耗大量人力物力的同时,有着极长的构建周期,因此,建立一个交互式的神经网络模型来辅助进行像素级数据集的创建是必不可少的。交互式的图像分割模型,具体说来就是通过获取一些用户提供的输入,如人工标注的边框或者点击,使神经网络能够快速提取感兴趣的目标对象,是一种能有效减少人工注释数据集难度和像素级数据集构建周期的方法。
近期,在交互式图像分割领域中出现了众多优秀的算法。通过对文献的阅读分类和比较,发现优秀的交互式分割网络,都基于交互过程中人工标注的关键点信息进行图像的分割。关键点信息之所以优秀,是因为它具有以下几个特征:易于选取、容错率高、交互成本低、包含的图像信息丰富。
基于关键点信息的交互式算法,根据交互方式可以分为2种类别。
1)人工标注边缘关键点的分割算法。典型算法有Graph cut[3]算法和DEXTR[4]算法,都基于人工标注的图像边缘信息来将图像的边缘进行处理和分割。其中DEXTR算法于2017年提出,使用了神经网络来学习人工标注的分割目标上下左右的4个极值点信息。尽管此算法效果优秀,可以在4次点击后达到90%以上的交并比(IoU)[5],但是在对细长物体和重叠物体处理的过程中往往误差较大,同时极值点标注的难度会带来人工成本的增加。
2)人工标注中心关键点的分割算法。典型算法有FCANET[6]算法和IOG[7]算法,都基于人工标注的图像中心点信息来分割图像。其中IOG算法于2020年提出,是近期分割效果最优秀和人工成本最低的算法,能在3次人工点击后取得92的IoU评分。此算法的优势源于同时选取了分割目标的包围框和中心点,但是也存在一些问题,如在处理关键点信息的过程中将关键点信息和图像信息进行了融合处理,这就导致关键点信息在一定程度上的丢失。
综上,IOG算法的优势在于,人机交互成本更低,有着较高的容错率,同时在精度方面取得了较好的成绩,因此,文中选择IOG网络结构作为文中的基础框架,使用非对称注意力机制对其进行优化,通过将关键点信息的单独处理和再融合,取得一定的改进效果。
1 交互式图像分割网络
1.1 网络整体结构
文中算法的网络结构见图1。如图1所示,文中算法引入了一个非对称的注意力机制结构,只在特征提取部分加入了关键点信息的注意力机制,而在上采样的部分则没有加入。文中算法之所以强调非对称注意力结构的优越性,是因为在大部分图像处理算法中,都使用了对称的注意力结构。多数的图像分割或是图像重建算法都由特征提取网络和上采样网络组成。在上采样网络中主要进行图像的生成工作,因此加入一些注意力结构在某些情况下也能提升网络精度。
在文中算法中,关键点信息主要的效果是提升特征提取网络的效果,本身包含的图像细节信息较少。如果在上采样部分也加入注意力结构,将关键点信息进行上采样后再次输入,会导致上采样层中过度关注分割目标中心,从而丢失大量图像细节信息,最终引起分割精度下降。文中在实验部分将对称结构与非对称结构进行了对比,非对称结构比对称结构的效果要更优秀。
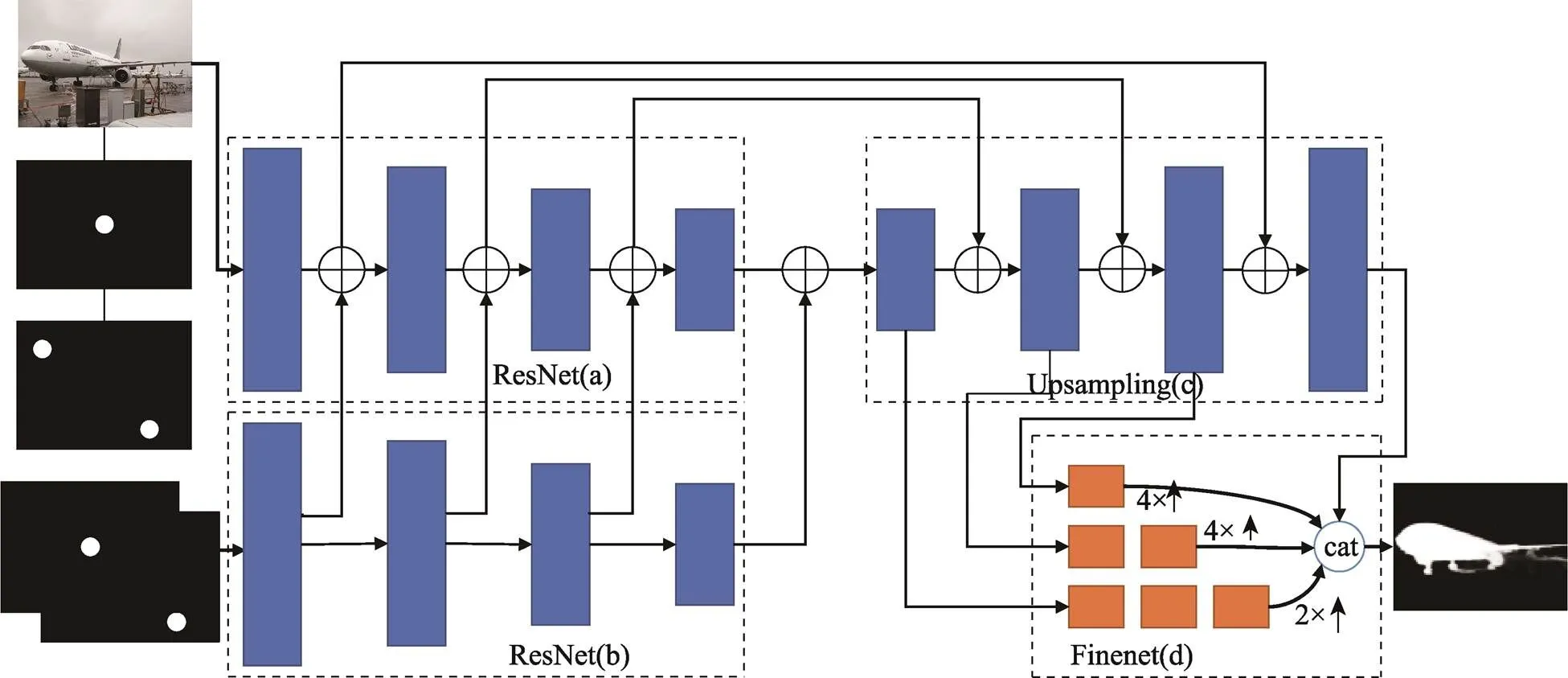
图1 文中算法网络体系结构
文中提出的非对称关键点注意力机制分割网络的主干框架与IOG算法相同,都使用了一个基于DeepLabv 3+[8]提出的ResNet–101[9]网络结构。在研究的过程中发现,当只使用一个单独的特征提取网络然后进行简单的上采样操作获取结果时,会产生比较严重的边缘分割误差。如果直接将网络深度增加,只能够优化小部分边缘和内部的信息分割效果,这就意味着必须做出一些网络体系结构的改进,才能够避免网络忽略目标分割对象的边缘信息。
如图1所示,文中算法根据IOG算法的结构采用了类U–Net[10]的网络结构去解决上述边缘分割效果较差的问题。通过特征提取层和上采样网络层的跳跃连接,将低级细节信息和高级全局特征从不同尺度输入上采样的过程中,以此来达到优化边缘分割的效果。
具体的分割网络共由4个部分组成,相比IOG算法增加了一个关键点特征提取网络部分。暂且将整个网络的不同部分分别命名为a、b、c和d。第1个部分a,采用了ResNet–101作为特征提取部分的主干,以原图像信息和关键点信息构成的五通道图像作为输入。其中图像信息使用的是RGB三通道图像表示方法,而关键点信息则分为两通道,一个通道存放2次外部点击信息,另一通道存放1次内部点击信息。在b部分包含了一个与a部分相似的注意力结构,这个结构的输入则是关键点信息互相结合的一个二通道图像,此子网络的每层输出都会和a部分中的相应层输出进行相加操作,这样做的目的是让关键点信息在卷积的过程中始终起到引导网络进行特征提取的效果。c部分是一个实现上采样的网络结构,从整体上看a部分和c部分可以发现,文中算法通过横向连接,逐步将来自较深层的图像分割信息与来自浅层的浅层信息融合,这能进一步提高特征提取部分在分割过程中所获取信息的利用率。同时d部分FineNet则获得从c中每一不同尺度所给出的粗略预测信息,通过结合这些不同尺度的信息,能够起到恢复缺失的边缘细节的效果。d部分中,每一小块都采用了bottleneck结构。通过这种多尺度的融合结构,上采样和级联操作才能够将特征提取过程中的不同级别的信息融合在一起。
1.2 非对称注意力结构
文中算法的非对称注意力结构以Resnet101为基础,见图2。
图2中,含有标识的块表示卷积层的叠加,具体叠加方式见图3。
在文中的非对称注意力结构中,主要使用了与Resnet101相似的结构。如图2所示,注意力结构以两通道的点击信息作为输入,整体结构与主特征提取网络一致。特征提取网络开始时使用了大小为7×7的卷积核进行卷积预处理,然后通过了一个池化层。在整个结构中总共运用了4个池化层,能够在保留数据特征的同时进行数据的轻量化,减少特征图的深度,从而去除冗余的数据部分。在卷积块叠加的过程中,注意力结构发挥了作用,在每次主特征提取网络对图像进行特征提取的同时,注意力网络对关键点信息进行特征提取,并将提取结果与图像提取结果进行融合,以达到加强关键点信息引导作用的目的。特征提取部分的提取操作(计算机语言)可以表示为式(1)—(4)。
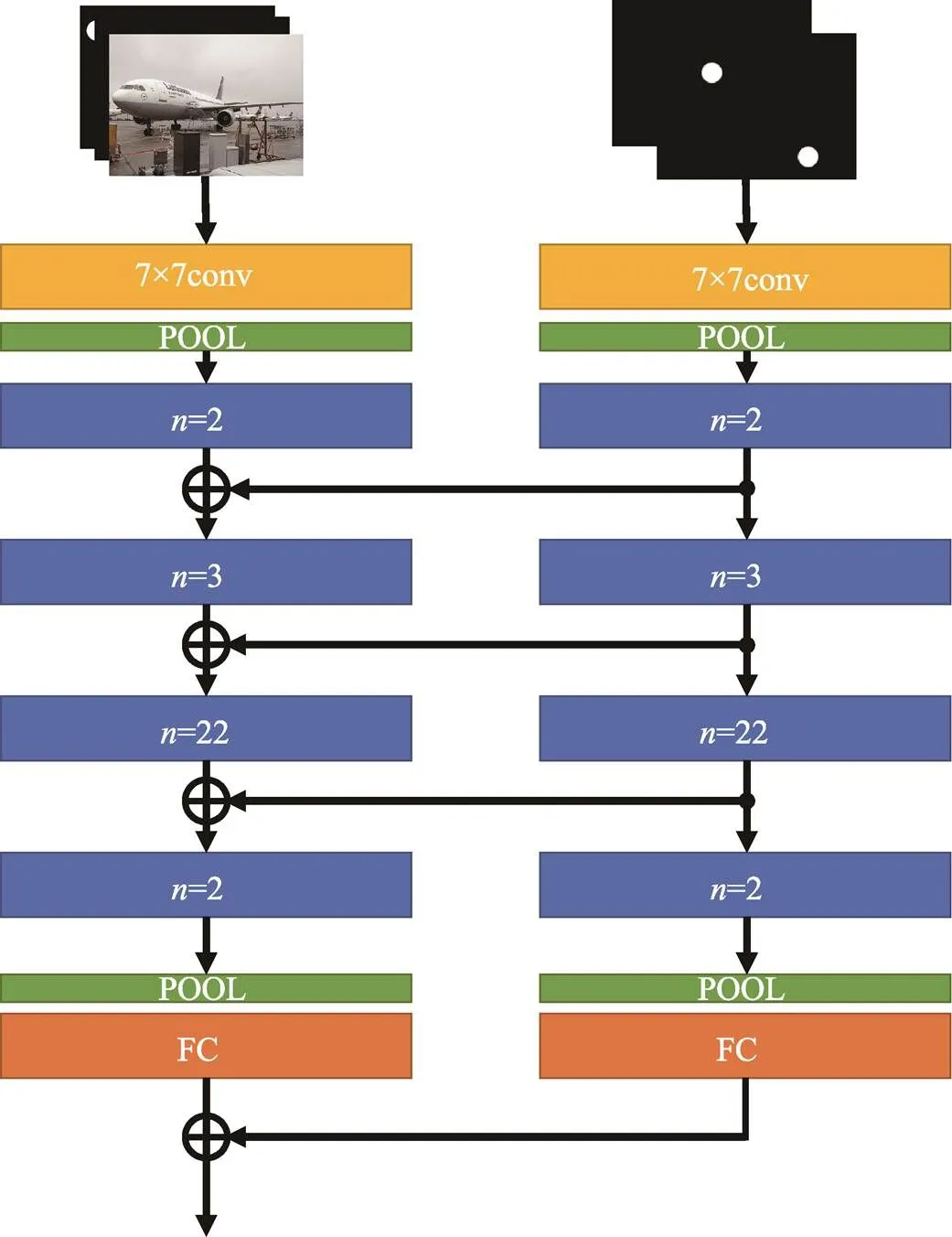
图2 文中算法非对称注意力结构

图3 文中算法注意力块结构
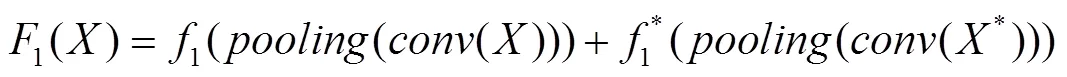
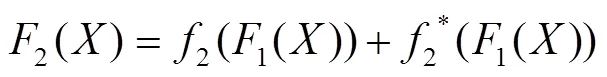
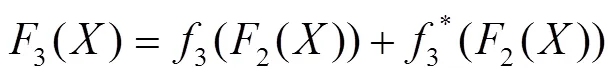
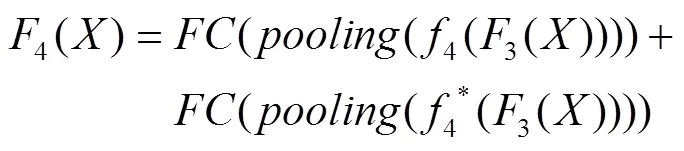

图3中展示了注意力层的一些细节。在这个结构中主要采用了1×1和3×3大小的卷积核,其中1×1大小的卷积核主要用来控制特征图像的尺寸和深度,3×3的卷积核则能够对局部信息进行特征提取操作。每个注意力块中都涉及到次的卷积循环操作,这是为了在不同的块中进行多次卷积操作的叠加,能够进一步加深网络深度,从而获得更优秀的特征提取效果。
1.3 非对称注意力结构的优越性
IOG的网络结构在卷积的过程中,关键点的信息会和图像信息完全混合,而图像信息本身有着较高的复杂程度,这就导致在高层全局特征中关键点信息从一定程度上被丢失,不能起到更好的引导作用。
例如,当IOG在处理一个交互式图像分割项目时,首先会将关键点信息与图像信息进行结合,生成一个五通道深度的图像,其中前3个通道分别为R、G、B这3个颜色通道,后2个通道则包含关键点信息,一个通道表示外部关键点,另一个通道为内部关键点。在第1层卷积的过程中,图像的五通道信息被综合考虑,经过一个大小为7×7×5的卷积核进行卷积,生成一个深度为64的特征图。由于关键点信息的特殊性,后2个通道中的大部分信息都表示为0的形式,只有关键点部分表示为255,而图像部分的三通道信息大部分都在0~255,这就意味着相比图像信息而言,关键点信息的复杂程度较低。随着卷积计算多次步骤的叠加,关键点信息与图像信息会完全融合,尽管关键点信息被考虑进了分割的信息池内,但是在计算的过程中关键点的信息会因与图像信息混合而变形,丢失了部分原本包含的信息,这就导致关键点信息不能够在分割过程中起到充分的引导作用。



受到首个关键点注意力机制分割算法[6]的启发,文中延续了关键点注意力机制的思想,基于IOG网络提出了新的特征提取策略。通过采用一个非对称注意力结构将关键点信息独立输入不同的网络层中,使得关键点信息在特征提取的过程中始终起到一个引导的作用。同时关键点信息也通过跳跃连接作用于上采样网络的不同层中。这样的优势在于关键点信息可以始终作用于整个网络部分,将人机交互过程中所获取的信息收益放大。
正如1.1节所提到的,IOG算法在分割过程中会面临关键点信息部分丢失的问题,而文中提出的非对称注意力结构可以将关键点信息在卷积的过程中独立分离出来进行卷积操作,这样做的好处是分离出的关键点信息部分不会被图像信息所污染,能够将原本的信息保留到每个特征层部分,通过不同尺度上的叠加来进行对分割的引导。

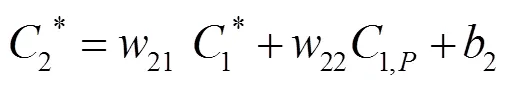
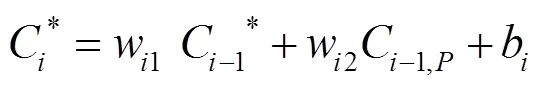
2 人机交互实现细节
2.1 算法交互过程
文中算法的人机交互点击过程与IOG算法类似,主要包括3次人工点击:首先在任何对称的角位置(左上角和右下角或右上角和左下角)进行2次外部点击,形成一个几乎紧密的包围感兴趣的目标的边界框,然后在内部点击,定位大致位于目标中心。
如图4所示,文中算法的人机交互包括步骤 如下。
1)第1次外部点击。用户单击确定左上角的边框点。
2)第2次外部点击。当用户移动光标至边框右下角时,使用引导线提示用户包围框的位置,并在图像中上生成一个边界框。
3)内部点击选择物体。在目标对象的中心位置附近放置内部单击。
4)显示分割结果。内部点击(红色)与4个外部点击(2个点击的点和2个自动推断的点)(蓝色)构成内外引导,以此分别确定编码的前景和背景区域。
调查表明,在数据集ImageNet[11]上绘制一个紧凑型的包围框平均耗时为25.5 s[12]。这是由于人工标注的边界和物体实质边界的像素点总有差别,因此难以确定。使用一些简单的提示来表示边界框的位置,例如使用水平和垂直向导线使框在单击时可见,给人绘制边界框的负担可以大大减轻,见图4a—b。据IOG算法中的相关调查显示,在引导线的帮助下绘制一个边框通常需要只6.7 s[7]。
2.2 训练过程模拟关键点的选取
为了在训练过程中模拟人工选取的关键点信息,文中采用了一种根据数据集中目标分割的真值结果来进行模拟关键点选取的方法。
虽然电气设备在设计时已经考虑了防振问题,但是由于周边或自身工作时的振动,容易引起电气设备的紧固螺丝松动,接插件等的松动,插件板的松动等,进而会引起电气接触不良、断线、脱落、开焊、错位、使动作失常和控制失灵。因此,对于振动大,或者振动对设备运行造成威胁的场合必须采取防震、隔振的措施。
首先,包围物体的包围框是由外部关键点决定的。外部关键点的选取较为简单,只需要对真值图像的目标部分取一个简要的包围框即可。
内部关键点由一个位于分割目标中心位置周围的单击操作来确定,这个内部点选取的目的是为了区分分割目标,避免在同一个包围框的区域中可能有多个对象带来的干扰。为了模拟人工点击的效果,采取了选择在离对象边界最远的位置取内部关键点的方法。


3 实验结果与分析
实验使用的相关环境为:python3.8、pytorch1.4.1、cuda11.1、windows10、Nvidia GeForce GTX3080Ti GPU。使用了PASCAL[13]数据集。值得注意的是,在此网络节点的测试过程中,输出的掩码是灰度图像的格式,因此要先进行二值化操作再与数据集中给出的真实值进行比对。
3.1 IoU评价对比
文中使用IoU[5]指标对图像分割算法进行评估,该值表示算法获取的分割结果与图像中相应目标区域的交并比。在表1中,展示了现有交互式分割算法的分割效果,最后3种方法只使用了3次点击交互,学习率均设定为1×10−8,batch size均设定为4,使用了相同的SGD损失函数,保证了参数的一致性。通过数值的比较可以明显看出,文中的算法在交互成本和分割精度方面都处于最优秀的行列,同时分割精度较目前最优秀的方法稍有提升。从提升精度角度来看,文中算法较IOG算法只提升了0.2%,这是因为在交互成本受到限制的情况下,为保证网络的运行速度,并未对网络的结构和深度进行大量修改,进一步提升精度较为困难。文中的方法在小批次训练效果和拟合速度方面都取得了更优秀的成绩,见表2。
表2中展示了4种算法不加载预训练模型仅在PASCAL数据集上训练100个epoch后的结果。可见文中的非对称注意力结构除了准确率更高的优势之外,还可以在更小的训练集上快速拟合。其中,DEXTR算法、IOG算法都选取了第100个epoch为最优节点,对称注意力机制分割方法选取了第96个epoch为最优节点,而文中算法在第93个epoch就达到了最佳的拟合效果。
表1 基于PASCAL数据集的现有算法分割结果准确率对比

Tab.1 Accuracy of released networks on PASCAL
注:“—”表示该项目未给出相关的评级策略;带“*”的数值表示该网络仅用PASCAL数据集进行训练。
表2 基于PASCAL数据集的小批次训练结果对比

Tab.2 Accuracy of released networks on PASCAL with small training dataset
在不加载任何预训练模型的情况下,IOG算法训练100个epoch后取最优节点,在PASCAL上取得的准确率为86.6%,而文中算法可以达到87.9%的准确率,DEXTR仅能达到82.1%的准确率,对称注意力机制算法则略低于非对称版本,只能达到87.4%。从准确率的角度分析,DEXTR算法的准确率最低,分割精度较差,IOG算法准确率高于DEXTR算法,但未达到加入注意力机制后的算法水平。加入注意力机制后,在小批次训练的条件下,2种注意力机制都取得了较好的效果,这是因为注意力机制使得网络对交互信息的利用率得到了提升,而非对称注意力机制相较对称注意力机制领先了0.5%,这是因为关键点信息在上采样的部分起到的效果一般,因此非对称注意力机制的效果更好。在表1中,加入对称注意力机制会导致算法效果比IOG更差,这是因为在加载预训练模型后,训练后网络的整体精度提升,而上采样中的关键点信息会对特征提取部分获得的信息产生较大的影响,反而会以噪声的形式对图像重建产生干扰,因此,文中算法在小批次数据集上的训练效果要比另外3种算法更优秀。
3.2 实验结果可视化分析
了更加直观地体现文中算法在图像信息复杂的情况下所具备的优势,DEXTR算法(图5b、g、l)、IOG算法(图5c、h、m)、对称注意力机制算法(图5d、i、n)和文中算法(图5c、j、o)的部分分割结果可视化对比见图5,均为加载预训练模型训练后的分割结果。图6a、f、k展示了图5a、f、k这3幅图像的真值结果,其余图为图5中分割结果与真值结果的差值图像,浅色部分为算法结果将背景信息误判为分割目标的部分,深色部分为分割目标的缺失部分。这个过程中阈值取为0.5级,即以128为阈值,是因为此阈值等级最为常见,有较高的实用性,因此将分割结果像素值小于128的部分进行丢弃,进行了分割结果的二值化操作。

图5 部分实验结果对比

图6 部分实验结果差值图对比
注:IoU和mIoU的值分别为分割结果的0.5级阈值准确率和平均准确率。
为了进一步说明4中方法的差别,将图6中对应的每行图像加以放大说明,见图7—9。
图5a在4种算法下的分割误差见图7。DEXTR方法将人物的头部和部分身体误判为了马匹的身躯部分,由叉号标出;IOG方法稍有改善,将人物左侧身体成功筛除,但仍将人物头部和右侧身体误判为马匹,由叉号标出;对称注意力机制方法的分割误差在马匹左侧和人物头部的分割效果都得到了改善,由虚线包围的区域和对号标出,但是人物的身体部分被大量误判为马匹的身躯,由叉号标出;文中非对称注意力机制算法能做到精确分割人物头部和身体部分,以及马匹左侧的部分都被精确分割,虚线和对号标出了文中方法所改善的区域。
当原图中包含颜色相似接触紧密的多个目标时(图5a中的马匹和人物),DEXTR方法、IOG方法容易产生不同目标间分割混乱的情况。采用对称注意力机制的算法能够减少不同颜色间的误判,但容易在颜色相近的部分生成更多的杂边和分割误差。文中的方法则能够更为清晰地得到分割结果,能够区分颜色相近且距离紧密的不同目标。
图5f在4种算法下的分割误差见图8。DEXTR方法、IOG方法分割误差部分,人物的腿部被自行车所遮挡,产生了较严重的目标丢失,由叉号标出;对称注意力机制部分,人物的腿部被大量丢失,同时将自行车部分误判为人物的腿部,由叉号标出;文中非对称注意力部分,人物的腿部得到了有效分割,同时不存在将自行车误判为人物腿部的情况,由虚线包围的区域和对号标出。
当原图中的分割目标被障碍物遮挡时(图5f中的人物),DEXTR方法、IOG方法会由于目标被遮挡而丢失一些信息。采用对称注意力机制则容易丢弃更多目标被遮挡的部分,同时存在遮挡物被误判为目标物的情况。文中的方法则能够获得较为精确的分割结果,能够在排除遮挡物的情况下对目标做出正确分割。
图5k在4种算法下的分割误差见图9。DEXTR方法部分,将背景中的阴影部分误判为了人体,由叉号标出;IOG方法部分,则将人物手臂下的背景部分误判为人物手臂,由叉号标出;对称注意力机制部分,人物手臂下的误判得到了改善,由虚线包围的区域和对号标出,但在人物头部的分割精度下降,将背景部分误判为人物头发,由叉号标出;文中非对称注意力机制部分,既改善了人物手臂下的误判区域,在人物头部生成的多余杂边也较少,由2处虚线包围的区域和对号标出。
当图像整体偏暗,目标颜色相近信息复杂时(图5k中的人物),DEXTR方法、IOG方法都会产生较多杂边。对称注意力机制能够减少一些外围的杂边,但在主体分割的精确度上反而会有部分下降。文中的分割算法在此情况下最清晰精确,能够做到减少杂边和误判所带来的分割误差。
通过综合分析这3种情况,说明了文中的方法在多目标色彩相似且距离复杂、目标之间存在明显遮挡关系、前景和背景色调相似等情况下都拥有更好的分割精度。

图7 图5a实验结果差值
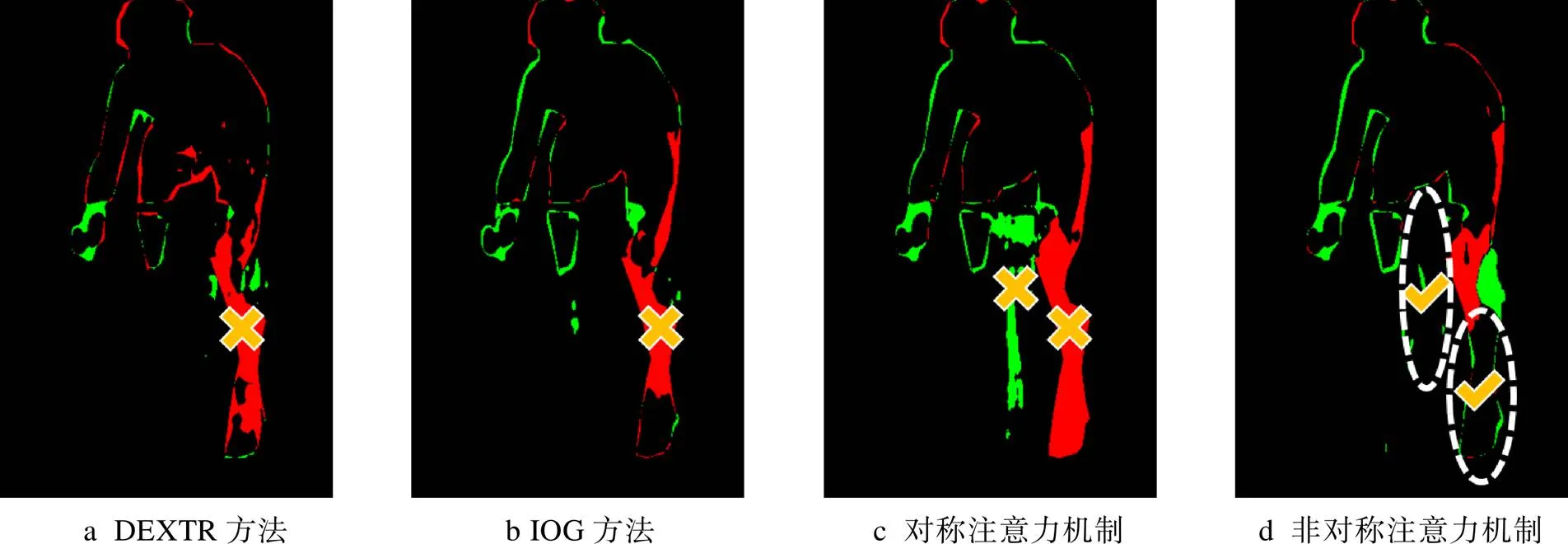
图8 图5f实验结果差值
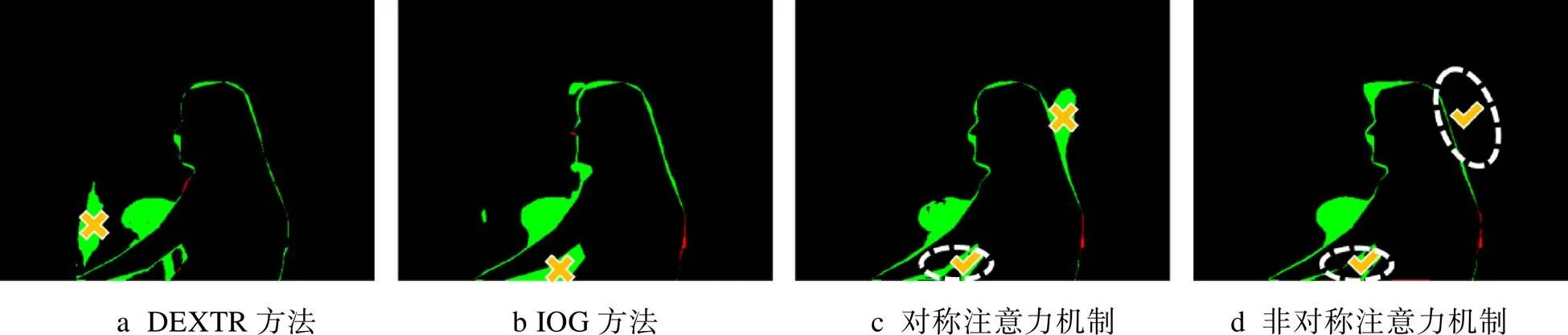
图9 图5k实验结果差值
3.3 泛化性能测试
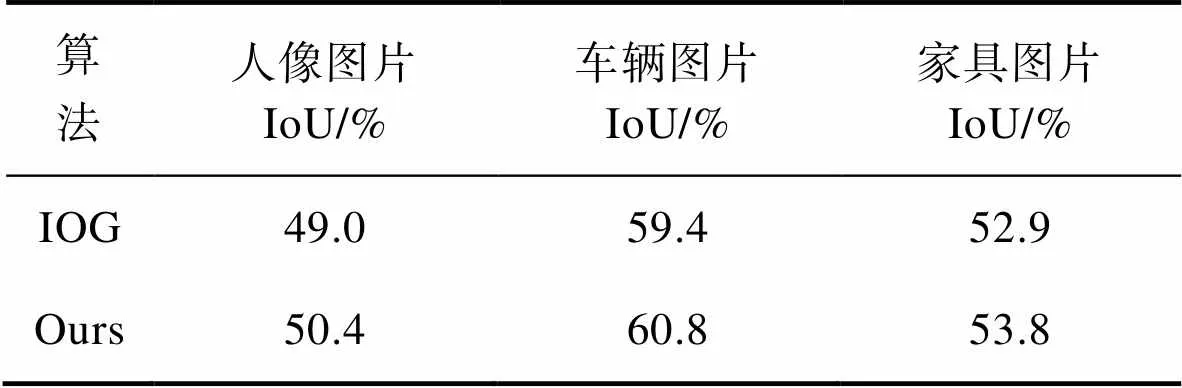
如表3所示,在泛化性测试中,选用了COCO2017数据集中的部分图片。首先对人像图片进行泛化性能测试,由于人像信息的复杂性,IOG算法和文中算法均表现一般。在PASCAL数据集进行训练的条件下,IOG算法的准确率为49.0%,文中算法准确率为50.4%。对车辆图片进行测试,IOG算法准确率为59.4%,文中算法准确率为60.8%。对家具图片测试,IOG准确率为52.9%,文中算法准确率为53.8%。在测试中,对人物图像和家具图像效果较一般的原因是,这2类图像一般构成信息较为复杂,多存在物体重叠的部分,且颜色较为鲜艳,因此分割效果要略低于车辆图片。在泛化性能上文中方法的准确率较IOG算法平均高出1.2%,提升效果较为明显。
表3 基于COCO数据集的算法泛化能力对比
Tab.3 Accuracy of interactive image segmentation network on COCO
泛化性能测试中部分实验结果见图10,图10a、d为实验图像,图10b、e为IOG算法的分割结果,图10c、f为文中算法分割结果。从图10中可以看出文中算法的分割结果边缘更加清晰,像素填充更加稳定均匀。
综上,文中方法的泛化性能比IOG算法更加优秀。

图10 COCO数据集部分实验结果对比
4 结语
文中提出了一种简单有效的非对称注意力结构,将交互式分割过程中的关键点信息单独卷积后,在特征提取部分与图像信息再融合,在避免关键点信息损失的同时加强了其对分割的引导效果,从而获取了精度上的提升。同时,文中将多种方法进行了对比,在小批次训练以及泛化性能等角度,文中算法均具优势。
尽管文中方法的交互模式十分简单,但实验表明,关键点模型在数据集的实验结果和交互的便利性上具有优势,从而证明了它作为一个注释工具的可能。后期的工作可以尝试在其输入信息中加入更多图像信息,如边缘信息和梯度信息。从信息量的角度来细化输入或者从加深网络深度的角度来进一步优化,能作为该算法以后的改进方向。
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. Imagenet Classification with Deep Convolutional Neural Networks[J]. Advances in Neural Information Processing Systems, 2012, 25: 1097-1105.
[2] HE K, GKIOXARI G, DOLLÁR P, et al. Mask R-Cnn[C]// Proceedings of the IEEE International Conference on Computer Vision, 2017: 2961-2969.
[3] VICENTE S, KOLMOGOROV V, ROTHER C. Graph Cut Based Image Segmentation with Connectivity Priors[C]// 2008 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, 2008: 1-8.
[4] MANINIS K K, CAELLES S, PONT-TUSET J, et al. Deep Extreme Cut: From Extreme Points To Object Segmentation[C]// Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 616-625.
[5] YU J, JIANG Y, WANG Z, et al. Unitbox: An Advanced Object Detection Network[C]// Proceedings of the 24th ACM international conference on Multimedia. 2016: 51-520.
[6] LIN Z, ZHANG Z, CHEN L Z, et al. Interactive Image Segmentation with First Click Attention[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 13339-13348.
[7] ZHANG S, LIEW J H, WEI Y, et al.Interactive Object Segmentation With Inside-Outside Guidance[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 12234-12244.
[8] CHEN L C, ZHU Yu-kun, PAPANDREOU G, et al. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation[C]//Computer Vision-ECCV 2018, 2018: 801-818.
[9] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[10] LI Xiao-meng, CHEN Hao, QI Xiao-juan, et al. H-DenseUNet: Hybrid Densely Connected UNet for Liver and Tumor Segmentation from CT Volumes[J]. IEEE Transactions on Medical Imaging, 2018, 37(12): 2663-2674.
[11] DENG J, DONG W, SOCHER R, et al. Imagenet: A large-Scale Hierarchical Image Database[C]// 2009 IEEE Conference on Computer Vision and Pattern Recognition, 2009: 248-255.
[12] SU Hao, DENG Jia, LI Fei-fei. Crowdsourcing Annotations for Visual Object Detection[C]// Workshops at the Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012.
[13] EVERINGHAM M, GOOL L, WILLIAMS C K I, et al. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[14] GRADY L. Multilabel Random Walker Image Segmentation Using Prior Models[C]// 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), IEEE, 2005, 1: 763-770.
[15] BAI Xue, SAPIRO G. Geodesic Matting: A Framework for Fast Interactive Image andVideo Segmentation and Matting[J]. International Journal of Computer Vision, 2009, 82(2): 113-132.
[16] XIE E, SUN P, SONG X, et al. Polarmask: Single Shot Instance Segmentation with Polar Representation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020: 12193-12202.
[17] LIEW J H, WEI Y, XIONG W, et al. Regional Interactive Image Segmentation Networks[C]// 2017 IEEE International Conference on Computer Vision (ICCV), IEEE Computer Society, 2017: 2746-2754.
[18] HU Yang, SOLTOGGIO A, LOCK R, et al. A Fully Convolutional Two-Stream Fusion Network for Interactive Image Segmentation[J]. Neural Networks, 2019, 109: 31-42.
Interactive Image Segmentation with Asymmetric Key Points Attention
SUN Liu-jie, FAN Jing-xing
(University of Shanghai for Science and Technology, Shanghai 200125, China)
In the process of interactive image segmentation, human-computer interaction plays an important role. For higher efficiency of human-computer interaction, this paper describes a structure of asymmetric key points attention, which can integrate human-computer interaction into the feature extraction network of interactive object segmentation with inside-outside guidance (IOG), based on guidance reinforcement of IOG for image segmentation of key points. This structure enhanced the accuracy to 92.2% without increasing the cost of interaction on PASCAL, 0.2% higher IOG (current best segmentation algorithm). While only training on PASCAL, the accuracy of this structure was obviously 1.3% higher than IOG. Under the assistance of the structure of asymmetric key points attention, the accuracy of segmentation can be improved without increasing the cost of interaction.
image segmentation; neural network; key points; human-computer interaction
TP183
A
1001-3563(2022)11-0292-10
10.19554/j.cnki.1001-3563.2022.11.037
2021–06–18
孙刘杰(1965—),男,博士,上海理工大学教授,主要研究方向为光信息处理技术、印刷机测量与控制技术、数字印刷防伪技术。
责任编辑:曾钰婵
