基于几何⁃语义联合约束的动态环境视觉SLAM 算法
2022-06-16沈晔湖陈嘉皓蒋全胜牛雪梅朱其新
沈晔湖,陈嘉皓,2,李 星,蒋全胜,谢 鸥,牛雪梅,朱其新
(1.苏州科技大学机械工程学院,苏州 215009;2.北京工业大学人工智能与自动化学院,北京 100124)
引 言
同步定位和地图构建(Simultaneous localization and mapping,SLAM)的目标是使机器人能够在未知环境的移动过程中,完成自身定位和增量式地图构建[1]。传统的SLAM 方法主要依赖于稳定性较好的距离传感器如激光雷达[2]。然而激光雷达获得的距离数据非常稀疏,这就造成SLAM 构建得到的环境地图仅包含极少量的路标点。这个地图仅能被用来提高机器人的定位精度,无法用于路径规划等机器人导航的其他领域。此外激光雷达高昂的价格、较大的体积重量以及耗电量限制了其在某些领域的应用。因此,随着计算机、光电成像等技术的进步,有研究者提出了视觉SLAM[3]算法。相机在一定程度上克服了激光雷达在价格、体积、质量以及耗电量上的劣势,同时摄像机能够获取丰富的信息,但是相机也存在一些问题,例如对光线变化敏感,运算复杂度高等。为了克服单一传感器的缺点,研究者们提出了多传感器融合SLAM[4]算法,然而这类算法目前技术还不成熟,硬件成本较高,算法复杂。因此,目前视觉SLAM 仍然是SLAM 研究领域的一个重要方向。
现有的视觉SLAM 算法大多基于环境静态假设,即场景是静态的,不存在相对运动的物体。但是在实际室外场景中大量存在行人、车辆等动态物体,从而限制了基于上述假设的SLAM 系统在实际场景中运用。针对动态环境下视觉SLAM 算法的定位精度和稳定性下降的问题,有学者提出了一些基于概率统计或者几何约束的算法,减少动态物体对视觉SLAM 算法精度和稳定性的影响。例如当场景中存在少量动态物体时,可以使用RANSAC[5]等概率算法来剔除动态物体。但是当场景中出现大量动态物体时,上述算法将失效。因此,需要一种算法,能够在存在大量态度物体的场景中,有效地分离动态物体和静态物体。在现有的动态环境视觉SLAM 算法中,对于动态物体的处理可以分为两类[6]:(1)剔除所有的动态特征点,只使用静态特征点,完成相机姿态估计和静态环境地图构建。(2)联合估计动态物体的运动,即同时估计相机的姿态、静态环境地图和场景中动态物体的运动。第一类方法未充分利用图像中所有有意义的信息,并且在动态物体较多的场景中难以使用。本文提出的算法属于第二类,该算法基于ORB⁃SLAM2[7],将动态视觉SLAM 算法与多目标跟踪算法相结合。本文提出了几何⁃语义联合约束方法,实现了静态特征点和动态特征点的分离,并且估计出动态物体的运动速度。
1 相关工作
传统静态环境视觉SLAM 算法主要分为两类:一类是基于特征点的算法;另一类则是基于直接法的算法。特征点法从图像中提取具有代表性的特征点,通过帧间特征点的匹配,完成相机位姿估计和地图构建。Davison 等[8]提出的MonoSLAM 是第1 个实时单目视觉SLAM 系统。前端提取非常稀疏的特征点,然后利用卡尔曼滤波器作为后端,跟踪前端提取到的特征点。Klein 等[9]提出了PTAM(Parallel track⁃ing and mapping),它使用非线性优化作为后端,并且将建图和跟踪过程并行化。Mur⁃Artal 等[7]提出了ORB⁃SLAM2,它提出了一种同时使用双目远近点和单目观测的方案,并证明了后端采用光束法平差(BA)[10]具有更高的精度。Campos 等[11]在ORB⁃SLAM2 算法的基础上改进,提出了ORB⁃SLAM3 算法,这是一个基于特征点法的视觉惯导紧耦合SLAM 算法,并且能够重用先前重建的地图信息。
直接法不需要提取特征点,直接采用图像中像素的灰度信息,通过最小化光度误差估计相机运动。LSD⁃SLAM(Large scale direct monocular SLAM)是Engel 等[12]提出的SLAM 算法,它将直接法应用到半稠密单目SLAM 中,在不计算特征点的前提下构建半稠密地图。Forster 等[13]提出了SVO(Semi⁃di⁃rect visual odometry)算法,将特征点法和直接法相结合,提取关键点,但是不计算描述子,利用关键点周围4×4 的小块进行匹配,估计自身运动。然而实际环境中不可避免地存在动态物体。为了减轻动态物体对相机定位和地图重建的影响,近年来,动态环境视觉SLAM 算法逐渐出现。在动态环境视觉SLAM 算法中,分离动态物体和静态物体是一个关键的问题。然而由于遮挡、运动模糊或丢失跟踪特征而导致的噪声、异常值或特征对应的缺失,使这个问题更加复杂。现有的针对该问题的方法可以分为4 类:
(1)概率统计法
在静态场景中,连续图像之间的特征点的转换可以由同一个运动模型来描述。在动态场景中,连续图像之间的特征点可能来自多个运动模型,每个运动模型都是独立且不相同的。基于概率统计的动态分离算法对数据的一个子集进行采样,并采用RANSAC[5]等算法拟合出内点最多的模型,从而实现特征点的分离。
(2)子空间聚类法
子空间聚类是基于高维数据可以低维的子空间联合表示的原理。数据点的子空间可以用基向量来进行数据的低维表示。在子空间聚类框架下的三维运动分割问题是找到与每个运动物体相对应的子空间,并将数据拟合到子空间中,例如文献[14⁃15]都使用了子空间聚类法来实现动态物体的分离,并且得到了较为不错的效果。
(3)几何法
几何法将多视几何从静态场景扩展到包含独立移动对象的动态场景。在静态场景中,1 个基本矩阵描述了相机相对于静态场景的运动,但在动态环境中,将有n个基本矩阵来描述n个物体的运动,其中包括1 个描述相机与静态场景相对运动的基本矩阵,通过几何约束来求解这些不同物体的基本矩阵的方法,称为几何法。Vidal 等[16]在文献提出多体上极性约束来求解这个问题。
(4)深度学习法。
通过深度学习算法分离动态物体的思路分为两种:一种是利用深度学习算法直接将动态物体分离出来,该方法依赖于预定义的运动刚体数量,从三维点云或者光流中生成运动物体的掩膜;另一种则是通过一些先验知识,将有可能运动的物体分离出来,例如语义分割,全景分割等。
目前基于上述方法的动态环境SLAM 算法,通常将分离出来的动态特征点直接剔除[17⁃18]。Bescos等[17]提出了Dynaslam 算法,这是一种通过深度学习剔除动态特征点,基于静态特征点构建地图的视觉SLAM 算法,支持单目、双目和RGB⁃D 三种模式。Yu 等[18]提出了DS⁃SLAM 算法,利用SegNet[19]网络作为一个单独的线程进行语义分割,同时另一个线程进行特征点提取,利用语义分割得到的掩膜剔除动态特征点,此外还有一个线程构建稠密的八叉树地图。
在最新研究中,研究者们通过实验发现联合估计动态物体的运动,对整个SLAM 系统的精度有增益效果,因而出现了一些联合估计算法[20⁃21]。Alcantarilla 等[20]提出了一种联合视觉和稠密场景流分离动态物体的算法,能够在复杂动态环境中保证系统的稳定性。另有一些学者提出了将静态背景和动态物体进行联合估计的算法。Zhang 等[21]提出了VDO⁃SLAM 算法,该算法构建了1 个包含机器人姿态、静态和动态三维点以及运动物体的统一框架,并且提出了一种能够避免因为遮挡引起的语义分割失败的处理方法,该算法复杂度较高,无法实现实时运行。Ballester 等[22]提出了DOT 算法,这仅是一个前端算法,通过语义分割掩膜分离动态和静态特征点,并且根据估计的相机运动,通过最小化光度重投影误差来跟踪这些对象。
近些年随着深度学习领域的迅速发展,出现了一些端到端的视觉SLAM 算法。Yang 等[23]提出了D3VO,将主要任务分为3 个部分,分别利用深度学习对深度、姿态和不确定性进行估计。D3VO 将这3种估计结合起来,组成了一个包含前端跟踪和后端非线性优化的视觉里程计结构。Czarnowski 等[24]提出了DeepFactors,DeepFactors 是第1 个概率稠密的SLAM 算法,在概率因子图公式中,将几何知识的先验知识与经典SLAM 公式相结合。
本文提出的算法相比传统的方法,在有较多动态物体的场景中具有更好的鲁棒性,提供了刚体速度的估计,并且由于算法复杂度低,因此运行速度较快,能够为导航提供更好的策略。
2 算法原理
2.1 算法流程
本文提出的算法首先完成特征点提取与匹配,利用实例语义分割网络对图像进行分割,并通过立体匹配得到场景的深度图;然后利用图像分割结果初步分离出静态特征点,并且计算基础矩阵。接着利用几何约束将动态特征点和静态特征点重新分离,估计相机位姿和构建地图,并且估计刚体运动速度,本文算法流程如图1 所示。

图1 算法流程图Fig.1 Flow chart of the proposed algorithm
2.2 特征点提取与匹配
本文采用ORB 特征点[25]。在提取特征之后,还需要根据描述子对前后帧图像进行特征匹配。本文计算一个特征点的描述子和其他描述子的汉明距离。汉明距离dhamming定义为

式中:(k)表示第t帧中第i个特征点的描述子中的第k位;表示第t+1 帧中第j个特征点的描述子中的第k位;⊕表示异或操作;N为描述子矢量的维数。
当两个特征点同时满足式(2)和式(3)时,定义它们为匹配特征点对,有

KITTI 数据库[26]中特征匹配的例子如图2 所示。

图2 特征匹配结果示例Fig.2 Examples of feature matching result
2.3 立体匹配
场景的深度信息在视觉SLAM 系统中是一个非常重要的信息。本文采用SGBM(Semi⁃global block matching)立体匹配算法来获取深度信息[27]。
首先构建全局能量函数

式中:D为视差图,up,uq代表图像中的像素点p和q的坐标;Nup指像素点up的相邻像素组成的集合;c(up,D(up))为当前视差图D中像素点up匹配代价;l1和l2为惩罚系数;δ(·)为示性函数。
求解上述函数最优值是一个NP 完全问题,因此将此问题近似分解成为一个线性问题进行求解,图3 为图2(a)中左图对应的视差图。

图3 图2(a)中左图对应的视差图Fig.3 Disparity map corresponding to the left image in Fig.2(a)
2.4 实例语义分割
本文采用MaskR⁃CNN 网络[28],这是一个实例语义分割网络,能够有效地检测图像中的目标。为了针对多个动态物体的场景,本文提出了一种改进的MaskR⁃CNN 网络输出结构设计。该改进的结构输出1 张与输入图像具有相同大小的RGB 图像。其中,R通道设计为类别通道,当检测到行人时,行人掩码范围内R通道置为64,检测到车辆时置为128,检测到非机动车时置为255,其余默认为0;G通道设计为实例通道,每个实例掩码值是该实例号与16 的乘积。理论上最大识别类别为3,每种实例数量为16 个,基本能够满足使用需求。当输入图像为图2(a)时,修正后的实例语义分割结果如图4 所示。

图4 实例语义分割结果Fig.4 Output of instance semantic segmentation
2.5 动态特征点提取
在动态场景中,动态特征点影响相机位姿估计,造成视觉SLAM 系统精度和稳定性下降,为了解决上述问题本文提出了一种迭代动态特征点提取算法。
首先,利用2.4节的实例语义分割获得的动态对象实例的掩膜,对所提取到的特征点进行一次筛选,即

当特征点符合对极约束时,认为该特征点为静态候选;当特征点不满足对极约束时,认为该特征点为动态候选,对极约束公式[29]为
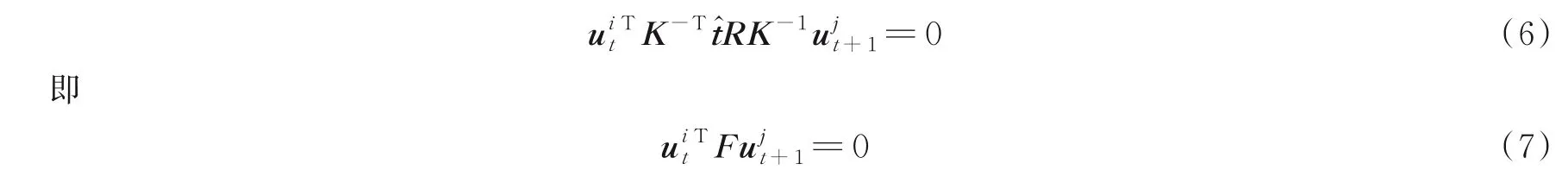

图5 动态特征提取结果Fig.5 Result of dynamic feature extraction
2.6 相机位姿估计
对于静态特征集合St结合相机的成像原理可得

式中:λ表示尺度因子;K为相机内参矩阵;T∈SE(3)为位姿变换矩阵;为静态特征集合St中的第i个元素;对应特征点的三维空间坐标。
构建重投影误差并优化为
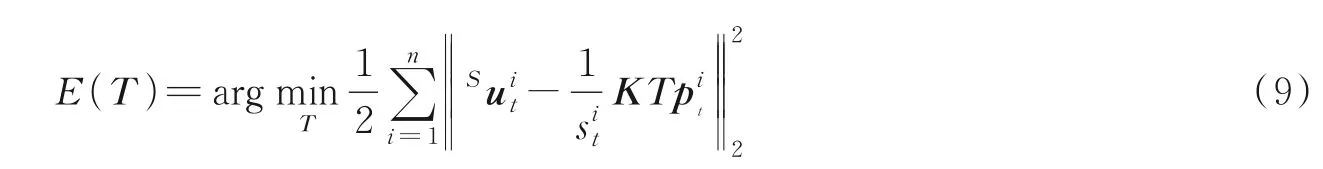
PnP[31]可以在很少的匹配点中获得比较好的估计,因此本文选择PnP 估计姿态,通过最小化式(9)的重投影误差来求解PnP,然后用Levenberg⁃Marquadt 算法[32]进行优化。
2.7 动态物体运动矢量估计
本文2.4 节虽然完成了实例分割,但是并没有建立相邻帧之间对应实例的联系,为此本文提出了一种简易的帧间物体匹配算法,具体步骤如下。
首先构建实例特征点集合,即

结合和2.2 节得到的帧间特征点匹配结果,计算得到t+1 帧中与匹配的特征点的像素坐标集合当满足式(11)时,α和β是同一个实例。

由于每个实例中的特征点数量无法满足后续实例跟踪的需求,所以需要在图像实例区域内提升特征点的数量。本文使用基于Lucas⁃Kanade 光流[33]的反向增量光流金字塔实现上述工作。优化目标如下

上述优化目标通过迭代法进行优化,即在图像I中对原始参数p上进行增量Δp映射运算,迭代优化如下目标函数为
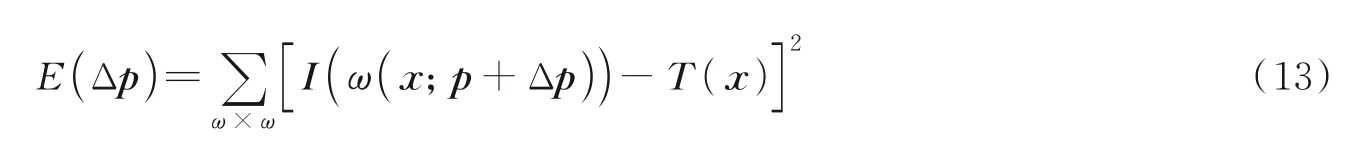
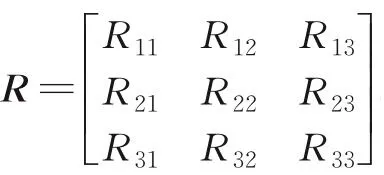
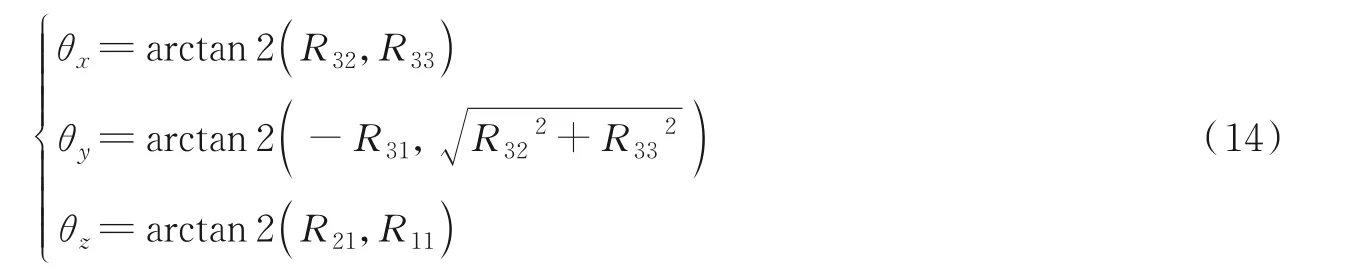
式中:θx、θy、θz分别表示滚转角、俯仰角和偏航角,由于本文实验数据为室外城市道路场景,因此只保留偏航角。从而动态物体的运动矢量为[θz,t],动态物体的运动矢量估计如图6 所示。

图6 动态物体运动矢量估计Fig.6 Motion estimation of dynamic objects
3 实验结果
3.1 度量标准
本文实验采用绝对轨迹误差(Absolute trajectory error,ATE)和相对位姿误差(Relatire pose error,RPE)[34]作为度量标准,ATE 的度量公式为

RPE 的度量公式为
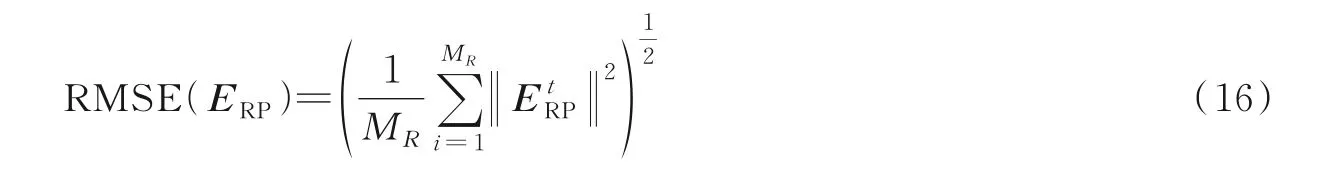
3.2 数据集和实验平台
本文在KITTI odometry 数据集和KTTI tracking 数据集[26]上对提出的算法进行测试。KITTI odometry 数据集每一组都有彩色双目图像,以及对应的灰度图和雷达数据,其中大部分采集于高速公路上,一般用于里程计和SLAM 算法的测试。KTTI tracking 数据集主要采集于城市道路中,图像内包含较多的动态物体,一般应用于图像语义分割测试,数据集内除了包含彩色双目图像外,还有图像语义信息以及GPS/IMU 传感器信息。本文采用的实验平台配置如表1 所示。
表1 实验平台配置Table 1 Experimental platform
3.3 实验结果与分析
3.3.1 定性分析结果
将ORB⁃SLAM2 和本文提出算法在KITTI odometry 数据集和KITTI tracking 数据集进行测试,两者在KITTI tracking 数据集上的轨迹对比结果如图7 所示。在图7 中,灰色虚线表示相机自运动真实轨迹,蓝色实线表示ORB⁃SLAM2 估计得到的相机自运动轨迹,红色实线表示本文所提算法估计得到轨迹。对比本文所提算法和ORB⁃SLAM2 发现,本文所提算法在KITTI tracking 数据集上均比ORB⁃SLAM2 接近真实轨迹。图7 中本文所提算法对比ORB⁃SLAM2 在00、03、04 序列平均定位误差分别降低了0.03、0.15 和0.14 m,这证明了本文将动态物体进行单独处理对定位的有益效果。

图7 本文算法和ORB⁃SLAM2 在KITTI tracking 数据集00、03、04 序列轨迹对比Fig.7 Trajectory comparison results of our proposed algorithm and ORB⁃SLAM2 on sequences 00,03 and 04 of KITTI tracking dataset
3.3.2 定量分析结果
本文提出算法、ORB⁃SLAM2算法和Dynaslam算法在KITTI odometry数据集01⁃10序列上的结果如表2所示。从表2 中可以看出在KITTI odometry 数据集01 序列中,本文算法对比ORB⁃SLAM2 和Dynaslam算法有较大的提升,然而在02 和03 序列中提升并不明显。这是由于01 序列的场景为高速公路,该场景中包含较多的运动物体,因此ORB⁃SLAM2 算法在该序列下绝对轨迹误差较大,Dynaslam 算法使用语义分割网络对动态物体进行了剔除,相对ORB⁃SLAM2 算法绝对轨迹误差较小,而本文算法在该序列下表现更佳。02 序列和03 序列的场景为城市道路,运动物体较少,因此本文算法和上述两种算法差距不大。
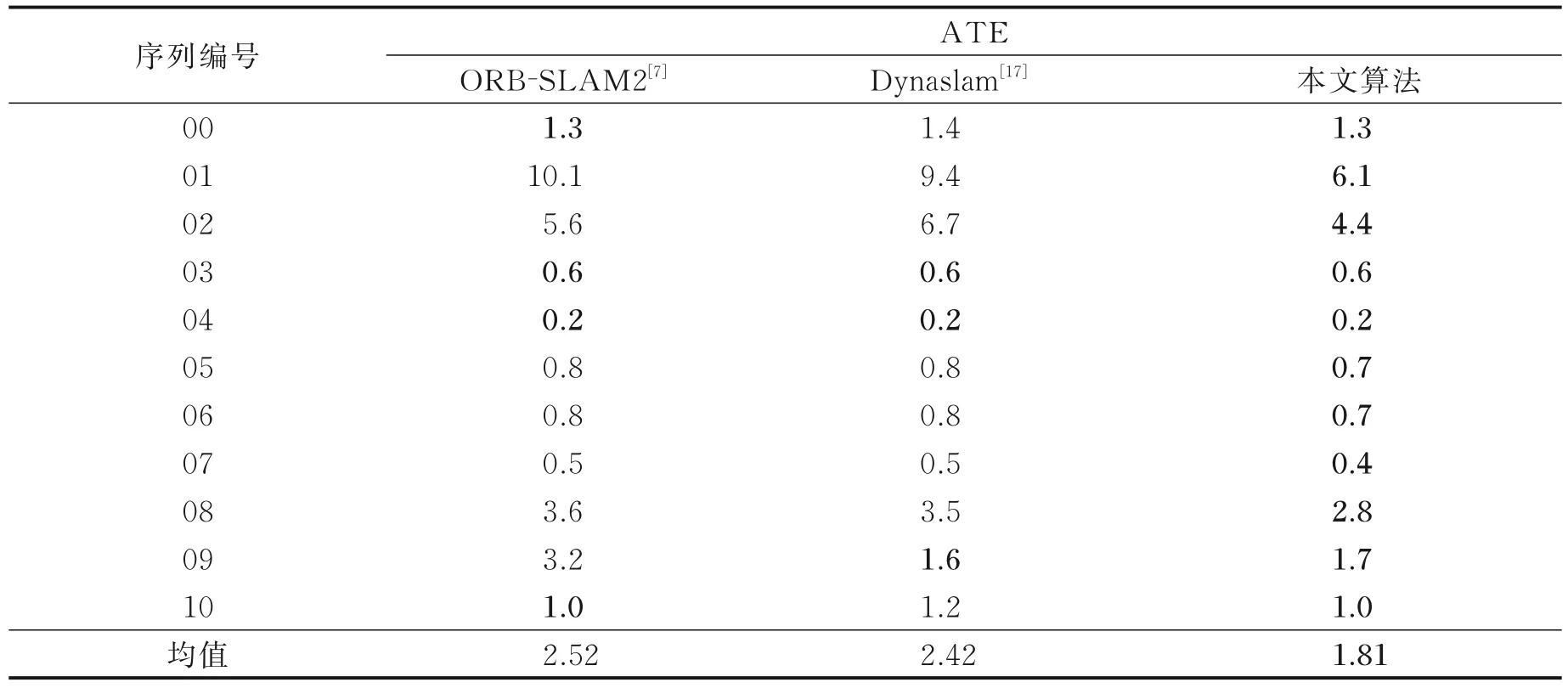
表2 本文算法、ORB⁃SLAM2 和Dynaslam 在KITTI odometry 数据集上对比结果Table 2 Comparison results of proposed algorithm,ORB⁃SLAM2 and Dynaslam on the KITTI odometry dataset m
表3为本文算法和ORB⁃SLAM2算法在KITTI tracking数据集的对比结果,通过对比发现本文算法在KITTI tracking数据集00⁃06序列中也优于ORB⁃SLAM2,这一结果与3.3.1节中定性分析结果一致。

表3 本文算法和ORB⁃SLAM2 在KITTI tracking 数据集上对比结果Table 3 Comparison results of our proposed algorithm and ORB⁃SLAM2 on the KITTI tracking dataset m
本文算法还与目前典型的动态环境下的SLAM 算法:VDO⁃SLAM[21]在KITTI tracking 数据集上进行了对比,结果如表4 所示。RPEt为平移部分的相对位置误差,单位为米/帧(m/f);RPEr为旋转部分的相对位置误差,单位为度/帧((°)/f)。从表4 可以看出,本文算法的平移位姿误差优于VDO⁃SLAM算法,旋转位姿误差略大于VDO⁃SLAM 算法,总体来说两者定位精度接近。

表4 本文算法和VDO⁃SLAM 在KITTI tracking 数据集上对比结果Table 4 Egomotion comparison with VDO⁃SLAM on the KITTI tracking dataset
本文还比较了本文算法在KITTI tracking 数据集上计算速度,如表5 所示。和VDO⁃SLAM 算法类似,由于实例语义分割和立体匹配均可以单独的线程形式在GPU 上实时运行,因此只需测试特征点提取匹配以及相机/动态物体运动估计的时间。由表5 可知,本文算法速度远快于VDO⁃SLAM 算法,帧率为VDO⁃SLAM 的近3 倍,基本达到了实时运行,在性能和速度上找到了较好的平衡点。

表5 本文算法和VDO⁃SLAM 计算速度对比Table 5 Runtime comparison of the proposed algorithm and VDO⁃SLAM
3.3.3 消融实验
本文所提算法基于几何⁃语义联合约束,主要包括几何约束模块和语义分割模块。对本文所提算法进行了消融实验,实验结果如表6 所示。通过表6 单独使用几何约束模块或者语义分割模块,定位误差均远大于本文提出算法,这表明本文提出算法结合使用几何约束和语义分割的重要性。

表6 消融实验结果Table 6 Results of ablation study m
4 结束语
本文所提的算法采用实例语义分割网络,结合几何约束,在有效分离静态特征点和动态特征点的同时,能够实现多目标跟踪,获得动态物体的运动矢量信息。与ORB⁃SLAM2 算法相比,在存在较多动态物体的场景中,本文所提算法具有更高的稳定性和准确度,在KITTI odometry 数据集上准确度提高了28%。与VDO⁃SLAM 算法相比,由于本文所提算法复杂度低,因此具有更高的计算速度,约为其3倍,并且能获得接近的定位精度。由于本文算法基于实例语义分割网络和几何约束,因此算法精度容易受到实例语义分割网络精度的影响,并且实例语义分割网络的执行速度较慢也是限制本文算法实际应用的问题之一。上述算法中存在的不足,将在以后的工作中进一步完善。在以后的工作中将使用精度更高、速度更快的语义分割网络,并且采用选取关键帧的策略,仅在关键帧中进行语义分割,从而进一步提高运行速率。
