基于深度残差收缩网络多特征融合语音情感识别
2022-06-16李瑞航吴红兰孙有朝吴华聪
李瑞航,吴红兰,孙有朝,吴华聪
(南京航空航天大学民航学院,南京 211106)
引 言
语音是人类最广泛使用的交流方式之一,不仅传达了显性的语言内容,还隐含着说话人的情感信息[1]。目前语音情感识别的主要特征包括韵律特征与谱特征[2]。
韵律特征主要包括基频相关特征以及能量相关特征等[3],韵律特征按照全局特征和局部特征,可提取最大值、最小值、均值及方差组成高维特征集。
谱特征能够反映信号在频域上的差异性,谱特征分为线性频谱特征和倒谱特征[4]。常用的线性谱特征有线性预测系数(Linear prediction coefficients,LPC)、对数频率功率系数(Log frequency power co⁃efficients,LFCC)。常用的倒谱特征有梅尔频率倒谱系数(Mel⁃frequency cepstral coefficient,MFCC)、线性预测倒谱系数(Linear predictive cepstral coefficient,LPCC)等。Bou⁃Ghazale 等[5]的研究表明倒谱特征对语音情感的区分能力明显优于线性谱特征。
2017 年,Han 等[6]提出了一种基于高斯核非线性近端支持向量机,采用了16 维特征,其中前9 维为韵律特征,后7 维为谱特征,包括能量、共振峰、谐波噪声比等特征。2018 年,Hsiao 等[7]提取了语音帧中基频、频率微扰、过零率、能量、谐波噪声比、MFCC 等特征,计算极值、方差、中值、均值、偏度、最小值、最大值、峰度、线性回归系数,采用深度RNN 模型在FAU⁃Aibo 任务动态建模框架中将未加权平均召回率(Unweighted average recall,UAR)从37.00%提高到了46.30%。2021 年,胡德生等[8]提取了语音帧中的平均过零率、能量、基音频率、共振峰、MFCC 等特征,采取主辅网络特征融合的方式,在IEMO⁃CAP 数据集上取得72.50%的非加权准确率。
上述研究所提出的模型,将不同特征输入多个网络中,但采用固定的信息融合方式。本文针对语音特征的多样性,采取不同的融合策略对多特征进行信息融合,应用此方法能够更有效地利用语音信号的特征。
语音情感识别模型可分为基于传统机器学习和基于深度学习[9]。传统应用于语音情感识别的机器学习的模型有高斯混合模型[10]、隐马尔可夫模型[11]、支持向量机[12]、多层感知器[13]和递归神经网络[14]等。
近年来,随着深度学习框架的发展,深度学习模型以较高的识别精度优势在语音情感识别领域得到大量应用。其中,卷积神经网络(Convolutional neural network,CNN)和长短期记忆网络(Long short⁃term memory,LSTM)在语音情感识别领域得到了大量的应用[15⁃16]。在最近的研究中,进一步表明引入注意力机制[17]和使用双向长短时记忆网络[18]能进一步提高识别准确率。针对语音帧所蕴含情感信息量不同的特点,引入注意力机制,增强有效语音帧的权重,减弱无效语音帧的权重。当前语音信号蕴含情感与前后语音帧皆相关,采用双向长短时记忆网络可获取前后时间依赖特征。
然而,语音情感特征具有个体差异性。为降低说话者差异的影响,对谱特征进行差分得到特征集形成多个通道输入到2D⁃CNN,3D⁃CNN 网络中。2018 年,Chen 等[19]提出3D⁃CNN⁃LSTM 模型,将MFCC 系数以及其一阶、二阶差分作为多通道一起输入3D⁃CNN 模型,在IEMOCAP 和EMO⁃DB 两个数据集上将未加权平均召回率分别达到64.74%和82.82%。2019 年,Zhao 等[20]将对数梅尔特征(Log⁃Mel)以及其一阶、二阶差分作为多通道输入2D⁃CNN⁃LSTM 模型,在IEMOCAP 数据库中,基于说话人依赖实验和基于说话人独立实验的识别准确率分别为89.16%和52.14%。2021 年,徐华南等[21]计算语音信号的对数梅尔特征和其一阶差分和二阶差分特征,合并成3D Log⁃Mel 特征集,在IEMOCAP 和EMO⁃DB 数据库上分别得到61.22%和85.69%的平均准确率。
上述方法为降低说话者差异性,都将语音信号谱特征进行了差分处理,输入到多通道的卷积网络中,但未对通道权重进行考虑。而不同阶差分处理的特征对语音情感的区分度可能出现差异性,需要分配不同的通道权重以增加语音情感识别的准确度。深度残差收缩网络(Deep residual shrinkage net⁃work,DRSN)[22]将软阈值化作为非线性层,易于提高在噪声数据的深度学习效果,适用于给重要特征分配更大的权重,滤除不重要特征。因此,本文引入深度残差收缩分配特征通道权重,以提高有效特征权重,降低冗余特征权重,进一步提高语音识别精度。
1 语音情感特征
韵律特征和谱特征都是描述情绪状态的有效特征[23]。为减小训练计算量,本文选取韵律特征中语音短时能量、短时平均幅度、短时过零率等典型特征。鉴于倒谱特征区分能力明显优于线性谱特征,本文选取梅尔频率倒谱系数、线性频率倒谱系数、线性预测倒谱系数等谱特征。
1.1 韵律特征
(1)短时能量
不同情感的表达在语音信号的幅度值上的体现有所不同,将语音短时能量作为判断语音情感的特征之一。语音短时能量En是一个表征语音信号幅度值变化的函数

(2)短时平均幅度
短时能量En对高电平非常敏感,因此,可使用短时平均幅度Mn度量语音信号幅度值变化

(3)短时过零率
短时过零率表示分帧后语音信号中一帧语音波形穿过横轴的次数

语音低频部分和高频部分分别具有较低和较高的平均过零率,可以以此区分轻音和浊音,进而反映声带振动情况,作为区分情感的特征之一。
1.2 谱特征
(1)梅尔频率倒谱系数
MFCC 可有效表征声道共振信息。在1980 年,MFCC 由Davis 等提出。此后在语音识别领域,MF⁃CC 成为运用最广泛的特征参数[24]。MFCC 的计算步骤如下:
①通过高通滤波器对语音信号进行预加重处理,提高高频部分使信号频谱变得平缓

②对语音信号按照帧长为25 ms,移帧为10 ms 进行分帧并采用汉明窗进行加窗。
③进行快速傅里叶变换,将时域信号转化为到频域信号,得到能量分布

④将能量谱通过Mel 尺度的三角滤波器,对谱进行平滑化

⑤计算从滤波器输出的对数能量,进行离散余弦变换,得到MFCC 系数

(2)线性频率倒谱系数
LFCC 与梅尔频率倒谱特征提取过程相同,但其滤波器组频率按照线性频率分布。
(3)线性预测倒谱系数
LPCC 利用线性预测分析获得倒谱系数。该特征描述元音效果较好,描述辅音效果较差。LPCC的提取过程如下:
①通过线性预测分析得到全极点模型为

②浊音的激励模型可表示为

③输入输出的关系表示为

④如果采样点n输出s(n)可用前面p个样本的线性组合来表示,则a1,a2,…,ap为常数值,称为线性预测系数
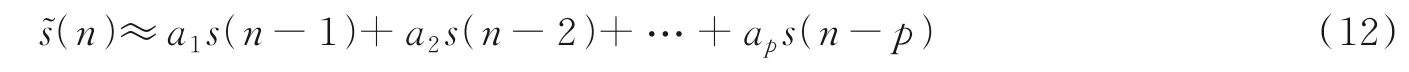
⑤线性预测倒谱系数c(n)为

2 模型构建
2.1 基线模型
本文引入注意力机制增强有效语音帧的权重,减弱无效语音帧的权重,结合CNN、BLSTM 模型构建基线模型。
(1)CNN 模型
将韵律特征输入1D⁃CNN 网络。计算谱特征以及其一阶和二阶差分形成3 个通道的特征集,输入到2D⁃CNN 网络。1D⁃CNN 设置两个卷积层,卷积核的数目为128,大小为5,步长为1,激活函数使用Relu。设置两个池化层,池化大小分别为5 和3。2D⁃CNN 设置3 个卷积层,卷积核数目为64,卷积核大小分别为5×5,5×5,3×3,步长为1,激活函数使用Relu。设置3 个池化层,池化大小皆为2×2。
(2)双向LSTM 模型
当前语音信号蕴含情感不仅与前面的语音帧相关,还与后面的语音帧相关。所以需要使用BLSTM,用独立的两个LSTM 网络从两个方向处理语音序列。BLSTM 在时间t时刻隐藏状态输出结果为

(3)注意力机制
将BLSTM 层输出的隐藏层H=(h1,h2,…,ht)作为注意力层的输入,H∈Rt×d,t为语音帧数,d为BLSTM 隐藏层的大小。

式中:αi为注意力权重为按照语音帧加权后的特征值。
在卷积神经网络后加入引用注意力机制的双向长短期记忆网络,BLSTM 网络每个方向包含64 个节点,输出一个128 维的序列。通过注意力机制,对包含情感信息较为丰富的语音帧分配较大的权重。
2.2 信息融合
信息融合的目的是将不同模型的优势结合一起,起到互补缺点的作用。信息融合分为特征层融合和决策层融合[25]。
特征层融合是将原始特征输入到多个深度学习网络中,得到多个降维特征向量,融合得到单个特征向量,然后输入分类器中。特征层融合常采用的方式有两种,特征向量并行(Add)方式和特征向量拼接(Concatenate)方式。并行方式需要所有网络输出相同维度的降维特征向量进行叠加,能够增加每一维特征的信息量,而不改变特征向量的维数。拼接方式则是将降维特征向量进行串联,能够增加特征向量的维数,而不增加每一维的信息量。
决策层融合是通过代数组合规则对多个网络识别结果进行融合,每个网络都会有一个预测评分。这种方式每个网络的分类结果都是独立的。常见的决策层融合方法有取分数的平均值(Average)、最大值(Maximum)等。
2.3 深度残差收缩网络
深度残差收缩网络引入软阈值化作为非线性层。软阈值化的本质是设计滤波器将噪声信号转化为接近为零的特征,是信号去噪方法的一个关键步骤。在深度残差网络结构中应用软阈值化的构建深度残差收缩网络,提高含噪数据或复杂数据上的特征学习效果。
软阈值的作用可表示为

式中:x为输入特征;y为输出特征;τ为阈值,即一个正参数。
输出对输入的导数为1 或0,可有效防止梯度消失和爆炸问题。其导数可表示为

堆叠多个各通道不同阈值的残差收缩模块(Residual shrinkage building unit with channel ⁃wise thresholds,RSBU⁃CW)则可得到深度残差收缩网络,如图1 所示构建RSBU⁃CW,在每个通道上都应用一个单独的阈值。对特征中的每个元素取绝对值,利用全局平均池化将特征x映射为一个一维向量,然后输入到两个全连接(Fully connected,FC)层。其中第二个全连接层的神经元数量为输入特征映射的特征通道数量,全连接层的输出则被缩放到(0,1),即

图1 RSBU⁃CWFig.1 RSBU⁃CW
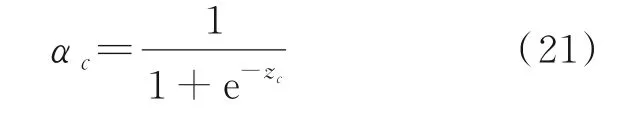
式中:c为特征通道序号,α c为第c个通道的缩放参数,zc是第c个通道的输出特征。
下一步可计算第c个通道的阈值为
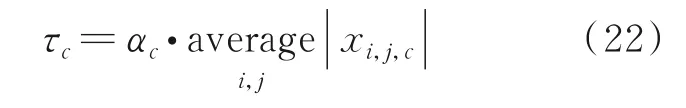
式 中:τc为第c个通道的阈值,xi,j,c则为特征x的通道c下坐标为(i,j)的特征。
深度残差收缩网络也适用于非噪声数据,因为其阈值是由样本自适应确定。样本中若不含冗余信息,阈值可被训练得非常接近于零,从而软阈值化几乎不会对模型造成影响。本文将谱特征经过一阶、二阶差分得到3 个通道,在输入二维网络之前,通过深度残差收缩网络获得通道权重。通过这种方式,每组训练样本都可有自己独特的一组通道权重,结合样本自身特点,对特征通道进行加权调整,从而得到具有通道权重的卷积神经网络,提升深度学习结果。
2.4 DRSN‑MF 模型
按照第1 节的计算流程对预处理后的语音信号提取语音情感特征。深度残差收缩网络多特征融合(Deep residual shrinkage network with multi⁃feature fusion,DRSN⁃MF)模型包含一维网络(1D⁃CNN⁃BLSTM⁃attention)和二维网络(2D⁃CNN⁃BLSTM⁃attention)。两个网络中都引入了注意力机制,提高有效语音帧的权重,以提高情感识别效果。两个网络最后都引入一个Dropout 层,防止过拟合,提升模型泛化能力。二维网络与一维网络的差异是采用了2D⁃CNN,其输入输出相比1D⁃CNN 多出了一个维度,可利用这个维度实现多通道的输入。将语音信号韵律特征输入到一维网络。将语音信号谱特征输入二维网络之前,先计算谱特征的一阶和二阶差分形成3 个通道的特征集,引入深度残差收缩网络获得二维网络3 个通道的权重,再将谱特征输入。MFCC、LFCC、LPCC 都采用这种方式输入二维网络。
不同特征经过深度学习网络后可得到对应的降维特征,为更好地利用降维特征,研究其在特征层融合和在决策层融合的差异。在特征层融合中采取特征向量并行方式和拼接方式,对降维特征进行融合后通过全连接层,采用Softmax 函数对情感进行分类,如图2(a)所示。决策层融合采取了取平均得分和最大得分方式,先通过全连接层和Softmax 函数得到每一类降维特征对情感的分类预测分数,最后通过代数组合规则输出情感分类结果,如图2(b)所示。
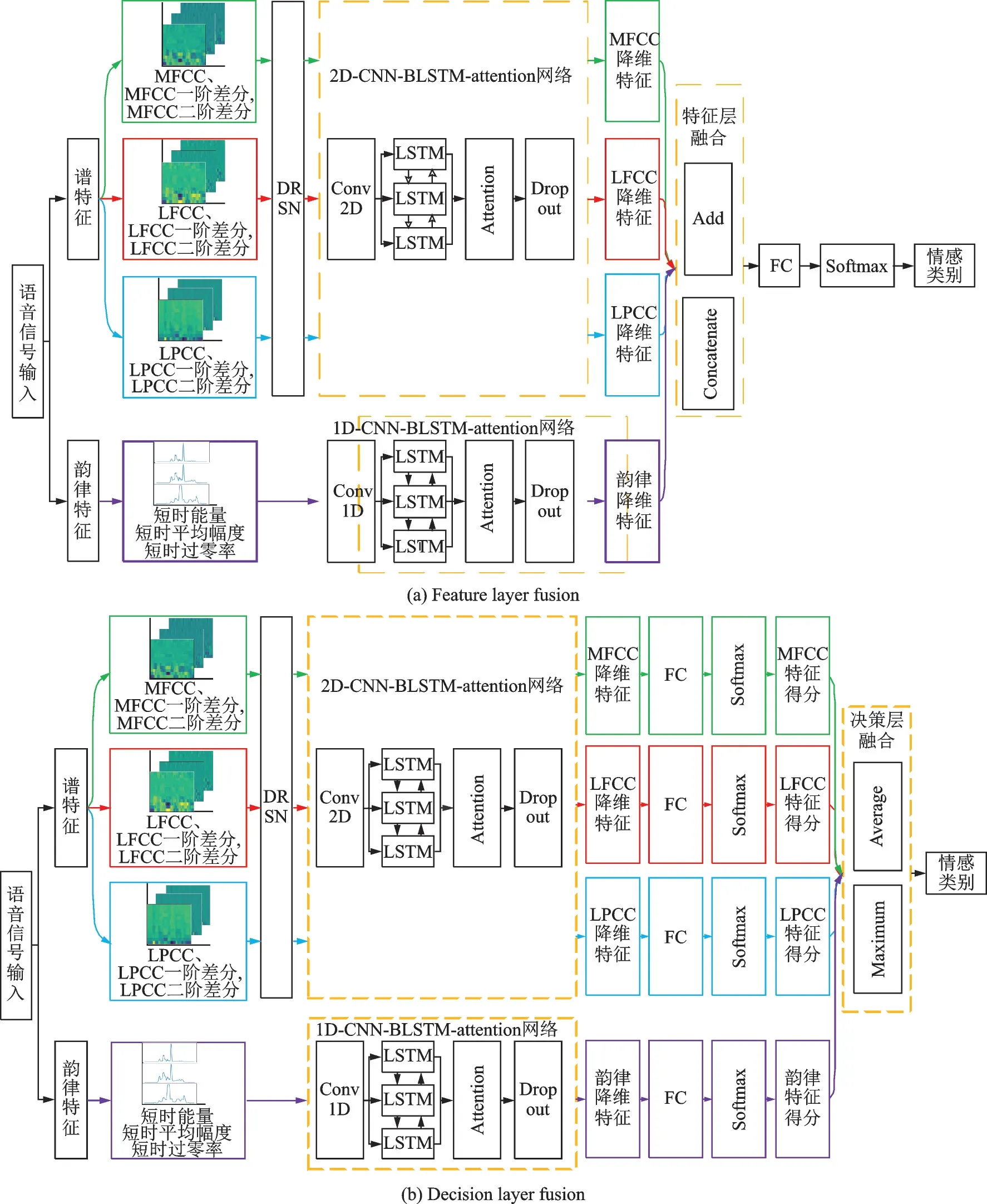
图2 DRSN⁃MF 模型Fig.2 DRSN⁃MF model
3 数据库及实验结果
3.1 情感数据库
为验证本文所提出模型以及特征融合策略的有效性,本文选用两个公开数据集CASIA 中文数据集和EMO⁃DB 德语数据集进行实验。
CASIA 中文数据集由中国科学院自动化研究所录制,共9 600 条情感数据,包括6 种情感,分别为生气、害怕、开心、中性、悲伤、惊讶。采样率为16 kHz,采用16 bit 量化级数据[26]。由于该数据库并不完全对外开放,故本文只选用了其中1 200 条语音。
EMO⁃DB 德语数据集由德国柏林工业大学录制,共535 条情感数据,包括7 种情感,分别为生气、无聊、恶心、害怕、开心、中性、悲伤。采样率为48 kHz,采用16 bit 量化级数据[27]。
3.2 关键指标
语音情感识别本质上为一个多分类任务,其评价指标包括准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1score)[28]。对于二分类任务,样本只存在两个类别,即正样本和负样本。对于一个随机样本,根据其预测类别和实际类别可分为以下4 种情况:(1)真阳性(True positive,TP),预测为正样本实际也为正样本;(2)假阴性(False negative,FN),预测为负样本实际为正样本;(3)真阴性(True negative,TN),预测为负样本实际也为负样本;(4)假阳性(False positive,FP),预测为正样本实际为负样本。
(1)准确率
准确率为正确预测的样本数量占总样本数量的比例。
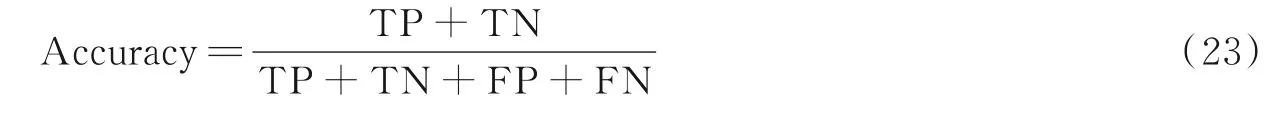
(2)精确率
精确率为预测为正的样本数量占真实为正的样本数量的比例。

(3)召回率
召回率为预测为正的样本数量占预测为正的样本数量的比例。

(4)F1值
F1值为精确率和召回率的调和平均值。

多分类任务中计算每个类别的精确率和召回率时,将每个类别单独视为“正”,所有其他类型视为“负”。所有类别计算得到的精确率R和召回率P可表示为一个n维的向量,n表示样本的类别数量,Ri和Pi分别表示第i个类别的精确率和召回率。

对各分类的精确率求平均值即为多分类任务的未加权平均精确率R,对各分类的召回率求平均值即为多分类任务的未加权平均召回率P。

3.3 参数设置
本文实验在TensorFlow 深度学习框架上完成。本文采用未加权平均召回率(Unweighted aver⁃age recall,UAR)作为模型的主要评价指标,同时计算模型的准确率、未加权平均精准率和F1 值。。按照25 ms 帧长和10 ms 移帧,将CASIA 语音库中所有语音划分成200 帧等长的语音帧,将EMO⁃DB语音库中所有语音划分成250 帧等长的语音帧。这种划分方式能够保留大部分语音的有效信息,其中长度未能达到指定帧数的语音采取零值补充至指定帧数。学习率设置为10-4,衰减率设置为10-6,训练迭代次数设置为150。训练集和测试集的比例为4∶1,进行5 次实验取平均值以减小实验的偶然性。
3.4 实验结果及分析
(1)信息融合策略
分别在CASIA 和EMO⁃DB 数据库上采取4 种信息融合方式,结果如表1、2 所示。
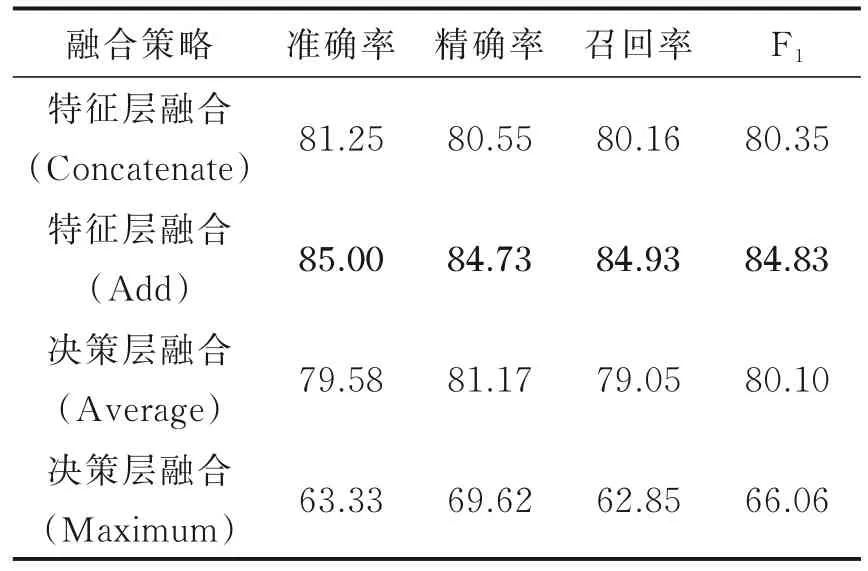
表1 CASIA 数据库不同融合方式结果Table 1 Results of different fusion methods in CASIA database %

表2 EMO‑DB 数据库不同融合方式结果Table 2 Results of different fusion methods in EMO‑DB database %
从两个数据库语音情感识别结果可看出模型在特征层融合比在决策层融合效果更好,说明先将信息进行整合后再进行分类是更有效的策略。在特征层融合中,采取特征向量并行方式优于拼接方式。在决策层融合中,取最大得分方式出现过拟合,在验证集中表现较差。
(2)RSBU⁃CW 数量设置
深度残差收缩网络可由多个RSBU⁃CW 堆叠,本文对RSBU⁃CW 数量进行了对比。以特征层融合特征向量并行方式比较不同RSBU⁃CW 对整个模型的影响。
从表3 的对比可看出,RSBU⁃CW 数量为1 时模型就达到最佳了,更多的追求RSBU⁃CW 数量并不能带来召回率的提升。原因是输入深度残差收缩网络的特征量并不大,堆叠RSBU⁃CW 数量反而会造成训练过拟合。
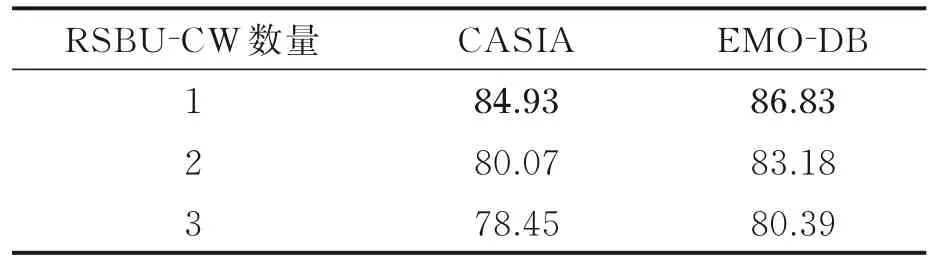
表3 不同RSBU‑CW 数量模型未加权平均召回率Table 3 UAR under different numbers of RSBU‑CW%
(3)训练过程
迭代次数设置为150 次,并设置在测试集上准确率40 次未提升则提前结束训练,以减小过拟合影响。准确率-迭代次数变化曲线如图3 所示。
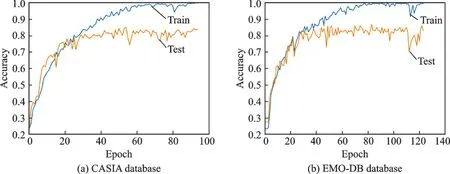
图3 准确率随迭代次数变化曲线Fig.3 Curve of accuracy with the number of iterations
图3 中显示两个数据库都未能完整训练预定义的150 次迭代,因为本次试验仅使用了CASIA 数据集中1 200 句语料,而EMO⁃DB 数据集所含语料也较少,样本较小容易造成过拟合,使用完整CASIA 数据集可进一步提高模型的识别精度。同时,当模型训练达到40 次左右时模型开始收敛,可证明本文所提出方法的有效性。
(4)混淆矩阵
CASIA 数据库和EMO⁃DB 数据库的混淆矩阵由图4 所示。

图4 混淆矩阵Fig.4 Confusion matrix
通过混淆矩阵可看出所提出模型对情感标签“中性”的召回率较高,对情感标签“害怕”和“伤心”的召回率较低,这两种情感在两个数据集上都有一定比例相互混淆,说明提取的特征对于这两种情感的区分度有限,可针对这两种情感的区分进一步深入研究。而另外几种情感都具有较高的召回率,说明所提出模型能够有效区分语音情感。
(5)模型对比
本文以引入注意力机制的CNN⁃BLSTM 作为基线模型。基线模型均采用特征层融合特征向量并行方式,在CASIA 和EMO⁃DB 数据库上基线模型与所提出模型的对比如分别表4、5 所示。

表4 CAISA 数据库中基线模型与DRSN‑CNN‑ABLSTM 对比Table 4 Comparison of baseline model and DRSN‑CNN‑ABLSTM in CAISA database %
如表4、5 所示,所提出模型在准确率,精确率,召回率和F1值4 个指标上均优于基线模型。为进一步验证本文引入深度残差收缩网络以及采取特征层融合特征向量并行方式的有效性,和其他论文中主要使用CNN、LSTM 及注意力机制建立模型的结果进行对比,如表6 所示。结果表明,深度残差收缩网络可以有效提高基于CNN 和LSTM 深度学习的语音情感识别精度,同时采取特征层融合特征向量并行方式能够有效提升模型识别的效果。

表5 EMO‑DB 数据库中基线模型与DRSN‑CNN‑ABLSTM 对比Table 5 Comparison of baseline model and DRSN‑CNN‑ABLSTM in EMO‑DB database %

表6 与其他模型UAR 结果对比Table 6 UAR comparison with other models %
4 结束语
本文以采用注意力机制的CNN⁃BLSTM 为基线模型,引入深度残差收缩网络,设置卷积通道的权重进行语音情感识别,并考虑了特征融合机制,得到在本模型中使用特征层融合特征向量并行方式能够更有效地训练模型的结论。在CASIA 数据库和EMO⁃DB 数据库上进行实验,与本文基线模型和其他论文中以CNN、LSTM 及注意力机制建立模型进行对比分析,验证了所提出方法的有效性。
