融合主题模型和动态路由的小样本学习方法
2022-06-16张淑芳唐焕玲刘孝炎窦全胜鲁明羽
张淑芳,唐焕玲,3,4,郑 涵,刘孝炎,窦全胜,3,4,鲁明羽
(1.山东工商学院计算机科学与技术学院,烟台 264005;2.山东工商学院信息与电子工程学院,烟台 264005;3.山东省高等学校协同创新中心:未来智能计算,烟台 264005;4.山东省高校智能信息处理重点实验室(山东工商学院),烟台 264005;5.大连海事大学信息科学技术学院,大连 116026)
引 言
有监督深度学习[1⁃3]需要大量的标注样本,然而标注样本获取代价昂贵;相反,人类能够在样本匮乏的情况下学习新知识。因此小样本学习[4⁃5](Few⁃shot learning,FSL)方法的研究得到广泛关注,其目标是在每个类别只有少量样本的情况下训练模型,但是在无法有效提取特征时,导致模型泛化性能下降,是小样本学习亟待解决的问题。早期研究者应用迁移学习[6]微调预训练模型。近年来,元学习[7]能够比较好地解决小样本学习问题,主要有基于度量的算法、基于数据增强的算法和基于模型优化的算法[8]。其中,基于度量的小样本学习简单有效,在面向图像和文本的任务中得到广泛关注。Vinyals 等[9]提出匹配网络,通过分段训练策略迁移元知识[10]生成以余弦距离度量的加权K⁃近邻分类器。Snell 等[11]提出原型网络,假设每个类的样本在度量空间中都存在原型,同属一个类别的样本均值向量作为该类的原型。Fort 等[12]提出高斯原型网络,将样本表示为高斯协方差矩阵,利用样本权重构造与类相关的度量函数。Gao 等[13]提出基于注意力的混合原型网络,设计了样本级别和特征级别的两种注意力机制,分别捕捉对分类更重要的样本和特征,提高关系分类模型在噪声数据集上的性能和鲁棒性。Sun 等[14]提出层次注意力原型网络,构建了特征、单词和样本3 种级别的注意力机制,分别赋予不同的权重分数,训练每个类的原型。度量学习应用于自然语言处理的不同领域,如单词预测、知识图谱以及任务型对话系统。有效提取不同粒度的词特征和样本特征,是基于度量的小样本学习需要解决的难点问题。本文从词粒度考虑不同类别的词分布特征,动态更新每类的原型,提出一种基 于SLDA[15]的动态路由原型网络模型(Dynamic routing prototypical network based on SLDA,DRP⁃SLDA)。利用SLDA 主题模型识别词与类别之间的精准语义映射,获得每个类别的词分布特征。基于支持集和查询集,提出动态路由原型网络(Dynamic routing prototypical network,DR⁃Proto),旨在通过动态路由算法[16]有效利用样本之间语义交叉特征训练动态原型,从而提升小样本文本分类的泛化性能。
1 DRP‑SLDA 模型
1.1 DRP‑SLDA 模型框架


图1 元训练样本Fig.1 Meta⁃training samples

图2 DRP⁃SLDA 模型的C⁃way K⁃shot(C=3,K=2)框架Fig.2 C⁃way K⁃shot(C=3, K=2)architecture of DRP⁃SLDA model
1.2 基于SLDA 编码方法
为获得每个类别的词分布特征,本文提出基于SLDA 主题模型的词编码方法,即图2 所示DRP⁃SLDA 模型框架中Encoder。
1.2.1 SLDA 主题模型


图3 SLDA 概率图模型Fig.3 SLDA probabilistic graphical model

式中:θi,t表示样本i的词分配给主题t的概率;φt,w表示主题t分配给词w的概率;δt,j表示主题t属于类别j的概率。表示第i个样本被赋予主题t的次数;表示词w被赋予主题t的次数;表示类别j被赋予主题t的次数。αt为主题t的Dirichlet 先验;βw为词w的Dirichlet 先验;γj为类别j的Dirichlet 先验。t=1,…,T;w=1,…,V;j=1,…,C。
1.2.2 基于SLDA 的编码表示
小样本学习因样本匮乏难以较好学习词特征,由于SLDA 主题模型的φ和δ识别词汇与类别之间的精准映射,基于SLDA 的Encoder 旨在从单词⁃类别分布中增强特征表示学习,如图4 所示。SLDA 模型提取单词在特定类分布特征,源集获取单词的通用性特征表示。通过双向长短期记忆网络(Bi⁃directional long short⁃term memory,BiLSTM)[18]计算单词权重,将word2vec 后的单词加权求和获得样本特征表示。

图4 基于SLDA 的Encoder 架构Fig.4 Encoder architecture based on SLDA
基于SLDA 计算单词对于特定类的权重为
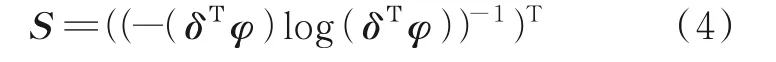

提取源集中单词通用性特征[19]有

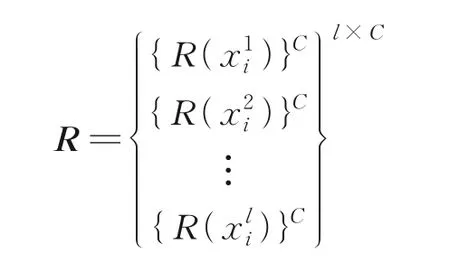
S和R互补难以设计合理的组合函数,且两者对分类重要性一致。关键词与词序和语境有关,通过BiLSTM 融合拼接S和R,有

式中:Hi表示样本i全部单词的特征表示,Hi∈Rl×d。

式中:w∈R1×d、b∈R1×l为可学习参数;tanh(·)为激活函数。通过softmax(·)归一化获得第i个样本l个单词的权重αi∈R1×l。
为单词赋予不同权重,则有

Encoder 利用SLDA 从词粒度角度引入主题特征编码,获得语义增强的样本表示。
1.3 DR‑Proto 网络
基于SLDA 的Encoder,提出动态路由原型网络DR⁃Proto。利用支持集和查询集的样本语义交叉特征获得原型,使分类边界更清晰。DR⁃Proto 网络如图5 所示,即图2 所示DRP⁃SLDA 模型框架中的DR⁃Proto net⁃work。图5 中,DR⁃Proto 网络提取支持集和查询集的样本交叉特征,通过动态路由算法调整耦合系数,更新样本权重,多次迭代获得动态原型Cj。通过特征共享变换[20]将Encoder 的和xq映射到同一空间,有

图5 DR⁃Proto 网络架构Fig.5 DR⁃Proto network architecture


考虑支持集和查询集满足独立同分布,通过提取交叉特征以利用文本语义关系,有

计算权重,获得不同样本对原型的重要性,即有

根据权重计算每类的原型,有

为了增大同类样本相关性而降低不同类相关性,自上而下调整耦合系数,有

由融合动态路由算法[16]的式(12~15)可知,利用语义关联的支持集和查询集提取交叉特征,进而采用权重机制获得动态原型Cj。DR⁃Proto 网络通过为样本特征赋予权重获得动态原型,从而改进均值原型[11]有效提取类别特征。
1.4 分类预测
样本xq与第j类原型的相似度计算采用欧氏距离,有

对样本xq的类别预测,有


采用均方误差损失(Mean squared error,MSE)优化参数,有

式中:yq表示查询集xq的真实标签one⁃hot 编码值;h表示查询集样本数。
2 实验分析
2.1 实验数据集
为验证模型有效性,利用20newsgroup 英文数据集、FewRel 关系数据集和Sogou 中文数据集,采样支持集和查询集,构建C⁃wayK⁃shot 分类任务进行对比实验,数据集描述如表1 所示。

表1 数据集描述Table 1 Description of data sets
2.2 实验结果及分析
2.2.1 对比实验结果及分析
对比模型有:(1)Finetune[22]:有监督的线性微调分类器。(2)1⁃nearest neighbor classifier:有监督的最近邻分类器。(3)Prototypical network[11]:每类支持集样本的均值特征向量作为类原型的原型网络。(4)MAML(Model⁃agnostic meta⁃learning)[23]:通过梯度求和优化不同子任务初始化参数的元学习模型。(5)RR⁃D2_LR⁃D2[24]:采用岭回归和逻辑回归的元学习模型。(6)Distributional signatures[17]:将词汇特征映射成注意力分数衡量文本表示,并使用岭回归器分类预测的元学习模型。
DRP⁃SLDA模型与上述6种模型在FewRel和20newsgroup数据集[17]上的分类结果比较如表2所示。

表2 模型在FewRel 数据集和20newsgroup 据集上的准确率Table 2 Accuracy of the model on the FewRel and 20newsgroup data sets %
由表2 可知,相比有监督学习的Finetune 模型和1⁃nearest neighbor 模型,元学习的模型整体效果表现良好。Prototypical networks 模型使用欧式距离度量映射空间内查询集与原型之间的距离预测分类;MAML 模型放弃距离度量方式,通过在多个子任务中使用梯度下降法训练初始参数,微调参数以计算不同子任务的损失快速收敛模型,其在FewRel 数据集上的准确率分别是48.2%、65.8%。然而,MAML 模型缺乏针对各任务的分析。为此,RR⁃D2_LR⁃D2 模型对不同任务生成先验知识,以可微分回归作为基分类器。Distributional signatures 模型在RR⁃D2_LR⁃D2 模型的基础上,将词分布特征转成注意力分数,用岭回归分类预测,在两种数据集上,两种小样本分类任务的准确率都得以提高,如20news⁃group 数据集上分别提高7.3%、4.0%。
DRP⁃SLDA 模型对比模型(1~5)在20newsgroup 数据集上准确率提升10%~30%,表 明DRP⁃SLDA 模型引入源集是有效的,能从不同角度提取词汇特征。DRP⁃SLDA 模型相较于Distribu⁃tional signatures 模型在20newsgroup 数据集上准确率分别提高8.6%、16.6%。原因在于Distributional signatures 模型仅考虑词汇特征没有考虑样本权重对分类的影响,而DRP⁃SLDA 模型利用SLDA 模型增强词分布特征且DR⁃Proto 网络为样本赋予权重获得动态原型。
2.2.2 DRP⁃SLDA 模型消融分析
消融方法简介:(1)DRP⁃SLDA:本文提出的小样本分类模型。(2)DRP⁃SLDA_NR:消 融DRP⁃SLDA 模型中源集在数据扩充上的影响。(3)DRP⁃SLDA_NS:消融DRP⁃SLDA 模型中SLDA 主题模型对词分布特征的影响。(4)DRP⁃SLDA_ND:消融DRP⁃SLDA 模型中交叉特征ψ的影响。(5)DRP⁃SLDA_NDR:消 融DRP⁃SLDA 模型中源集数据扩充和交叉特征ψ的共同影响。(6)DRP⁃SLDA_NDS:消融DRP⁃SLDA 模型中SLDA 主题模型和交叉特征ψ的共同影响。
为了分析DRP⁃SLDA 模型不同组件对分类效果的影响,在Sogou 和20newsgroup 数据集上分别进行3⁃way 1⁃shot、5⁃way 5⁃shot 消融实验,实验结果如表3 和图6、7 所示。其中,Macro⁃precision 为宏精确度;Macro⁃recall 为宏召回率;Marcro⁃F1为 2×Macro⁃precision×Macro⁃recall/Macro⁃precall+Marco⁃precision。s

表3 消融方法在Sogou 数据集和20newsgroup 数据集上的实验结果Table 3 Experimental results of the ablation method on the Sogou and 20newsgroup data sets %

图6 Sogou 数据集在3⁃way 1⁃shot 下消融方法分类结果Fig.6 Sogou data set classification results of ablation methods under 3⁃way 1⁃shot
如图6 所示,在Sogou 数据集上对于3⁃way 1⁃shot 分类任务各消融方法结果,可以看出:(1)DRP⁃SLDA 对比DRP⁃SLDA_NR 方法,各分类指标提高0.39%、0.39%和0.40%,表明源集通用性特征表示的有效性,引入源集对模型有积极影响。(2)DRP⁃SLDA 对比DRP⁃SLDA_NS 方法,各分类指标提升1.02%、0.57%和0.94%,表明利用SLDA 模型能有效增强词分布特征。(3)DRP⁃SLDA 对比DRP⁃SLDA_ND 方法,各分类指标提升0.81%、0.95%和0.91%,表明利用支持集和查询集样本,能提取语义增强的交叉特征ψ。
如图7 所示,在20 newsgroup 数据集上对于5⁃way 5⁃shot 任务各消融方法结果,可以看出:对比DRP⁃SLDA_NDR方法,DRP⁃SLDA方法各分类指标降低3.06%、4.56% 和4.40%;对 比DRP⁃SLDA_NDS 方法,DRP⁃SLDA 方法各分类指标降低3.86%、4.82%和4.68%。表明在没有获取样本交叉特征时,SLDA 模型提取的特定类词汇特征有助于提升DRP⁃SLDA 模型泛化性能,而源集通过扩充数据样本提取词汇通用性特征对模型效果微效。
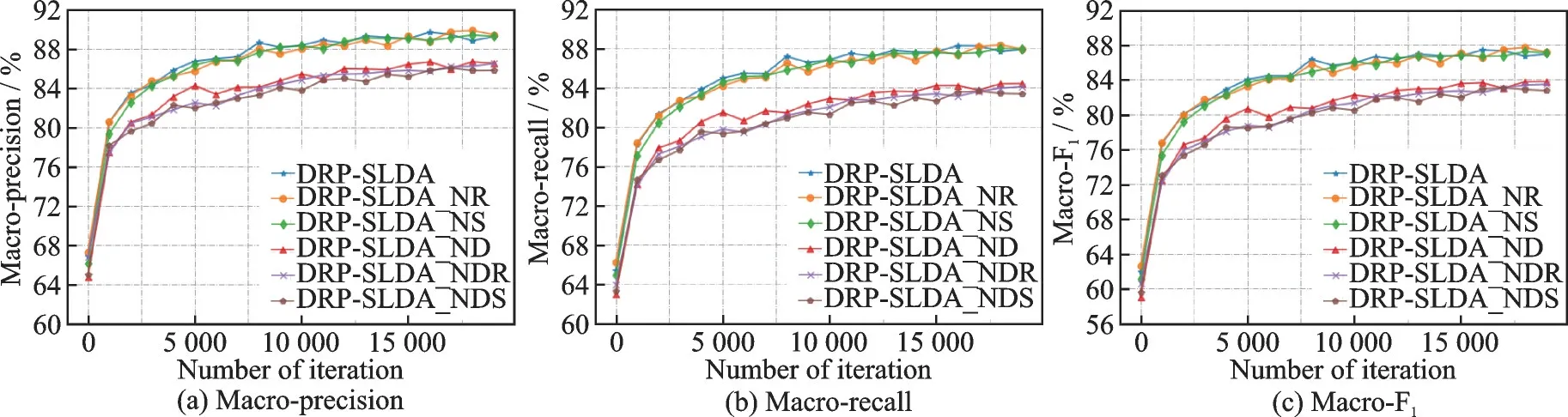
图7 20newsgroup 数据集在5⁃way 5⁃shot 下消融方法分类结果Fig.7 20newsgroup data set classification results of ablation methods under 5⁃way 5⁃shot
图8 是对20newsgroup 数据集的样本分布PCA 降维,将样本映射到二维空间,可视化各消融方法的影响。图8(a)中3 个聚类分簇显著,分类边界明显优于其他方法,说明DRP⁃SLDA 模型生成具有类别区分性的样本表示。

图8 消融方法在20newsgroup 数据集的PCA 可视化比较Fig.8 PCA visualization comparison of ablation methods in 20newsgroup data set
2.2.3 动态路由算法的有效性分析
为了验证DR⁃Proto 网络中动态路由算法对DRP⁃SLDA 模型分类效果的影响,在FewRel 数据集上进行5⁃way 实验,动态路由算法的随不同迭代次数的可视化如图9 所示,展示在FewRel 数据集上提取样本交叉特征ψ可视化结果。由图可知,随着迭代次数的增加,模型的分类边界清晰。表明DRP⁃SLDA 模型通过动态路由算法的多次迭代,能够有效提取样本交叉特征,动态获得使类别边界更清晰的原型。综上所述,所提出的DRP⁃SLDA 模型能有效增强小样本文本分类的特征表示,提升原型的类别辨识力。

图9 不同动态路由迭代次数的样本(特征)可视化结果Fig.9 Visualization results of samples (features)of different dynamic routing iteration times
3 结束语
本文提出一种基于SLDA 和动态路由的原型网络模型DRP⁃SLDA,利用SLDA 模型获得词汇⁃类别的语义映射增强词的分布特征,结合动态路由算法更新样本权重为不同样本赋予权重获得动态原型,从而有效提升模型的泛化性能。在多个数据集上的对比实验表明了DRP⁃SLDA 模型的有效性。下一步将对多标签小样本元学习方法展开研究。
