网盘业务引入人工智能技术的设计与研究
2022-06-16蔡茂贞丁小波黄珊珊钟地秀
蔡茂贞,丁小波,黄珊珊,钟地秀,彭 琨
(中移互联网有限公司云产品事业部,广州 510000)
0 引言
人工智能是研究计算机来模拟人的某些思维过程和智能行为(如学习、推理、思考、规划等)的学科,结合人类的思考方式对思维进行量化,利用人类的分析方式将过程进行数字化。最终利用数据与数学逻辑形成类人脑的推断智能应用。人工智能的技术领域包括了计算机视觉、自然语言处理、模式识别、数据挖掘、推荐系统、知识图谱等。随着数据爆发性增长与算力指数型增强,人工智能突破领域应用的瓶颈,使得人工智能技术能够处理更切合实际的应用问题。全球科技正朝着数字化、信息化、智能化方向迅速发展,各行各业均将人工智能作为一项能力引入到各自的领域,并对现有服务能力和业务应用进行革新。
1 网盘业务的介绍
2016 年,115 网盘、新浪微盘、迅雷快盘、腾讯微云、华为网盘、360网盘经历一轮业务调整潮。大浪淘沙,如今从事网盘业务的企业已经历了曾经的发展瓶颈,各自对企业长效性合规发展进行了调整,从事网盘业务的企业趋于稳定,近几年仅有阿里云盘、迅雷云盘等新玩家的入局网盘应用市场。长久、可靠、安全不再是用户考虑核心焦点。
5G 时代网络,增强型移动宽带、可靠低时延通信和海量机器类通信均得到大面积应用。可靠网络的保障给云服务应用落地提供了丰富的应用场景和能力。更多的企业、个人融入到数字化、智能化之中,将云端作为自己的工作台。与此同时,用户对数据传输、存储和共享的需求呈爆发性增长。网盘在个人、企业、家庭中的应用日益得到长足发展。在产品功能方面,市场竞争从最基础的存储、传输功能向智能化方向演变,需满足多场景应用需求。
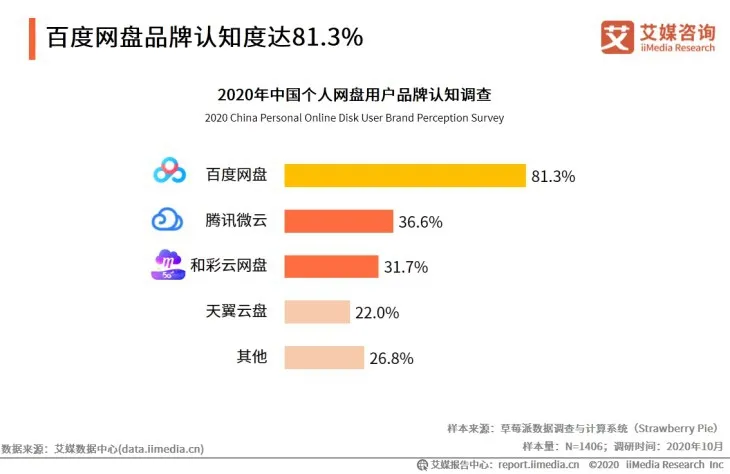
图1 个人网盘品牌认知度
网盘业务是一种重资产业务,高运营成本和低付费转化率一直以来制约着个人云盘市场的可持续发展,网盘应用提供商很难从个人云盘产生长期有效的盈利。近年视频网站、流媒体、数字音乐、知识付费等产品逐渐培养了用户使用习惯,为虚拟产品付费的习惯以及付费享有更优质服务的理念正在逐渐为用户所接受。为网盘应用开发增值类服务逐渐成为提高产品影响力的一种重要手段。如何提高用户使用频次,成为网盘类应用需要考虑的应用点。
2 网盘业务应用场景分析
网盘类应用虽作为用户存储类,随着用户存储资产的增加,帮助用户高效管理的数字资产能有效地提升用户体验满意度。基于语音、视频、图像识别与分析等人工智能技术的应用能为用户个人网盘在内容智能分类、内容检索和内容创作上为用户带来更加智能、便利和高效的服务。在保证资产安全和用户授权的基础上,利用人工智能技术的个人云盘将可以采用更加智能化的方式帮助用户提高数据管理的效率,进一步优化用户使用体验。
用户体验提升可以从实用性和娱乐性两个大方向进行引入人工智能技术。人工智能技术应用以图像处理算法为核心、视频处理算法和自然语言算法共同协作打造面向图片、视频、情景的互动能力。在实用功能方面,通过提供人脸聚类、事物分类、文本处理等业务能力,让用户可以便捷地根据媒体内容进行查看和管理。在娱乐功能方面,引入人物卡通化、背景替换等娱乐场景,让用户对照片和视频等媒体进行二次创作,从而提升网盘的传播性,引入新流量。
3 应用人工智能规范的设计
语音、视频、图像等多种AI 能力均可作为网盘业务应用场景,其中图像应用的AI 能力又可分为图像分类、物体检测、图像分割、人脸识别、人脸检测。在实际人工智能应用中,模型在初始时并不具有对具体任务有效的参数,因此对于特定任务,需要通过模型训练来寻找一组合适的参数,从而反馈给模型的使用者一个有效的预测值。本章节据此设计了AI 模型从研发到应用的整体框架,然后分别介绍AI 模型训练规范和模型测试规范的具体设计。
3.1 模型训练规范的设计
神经网络模型是拥有特定结构和一系列权重参数的函数。模型训练是指利用大量已标记数据,通过反向传播反复更新模型中的权重,直到模型能够对输入数据输出一个合适的预测值,通过这个预测值来确定输入数据隐含的标签信息。
AI 模型训练中不同任务不同需求会有不同的训练配合和数据。模型训练计划阶段需定义任务类型、数据集、模型配置与模型输出。根据具体任务设计指定AI 任务类型,如可划分为语音、视频、图像等大类任务;再根据大类任务划分小类任务,如图像分类、物体检测、图像分割、人脸识别、人脸检测等任务。其次需要基于定义好的任务类型准备图片。将图片划分为训练集、验证集和测试集,然后进行数据人工标注。最后进行模型参数配置完成AI 模型训练。
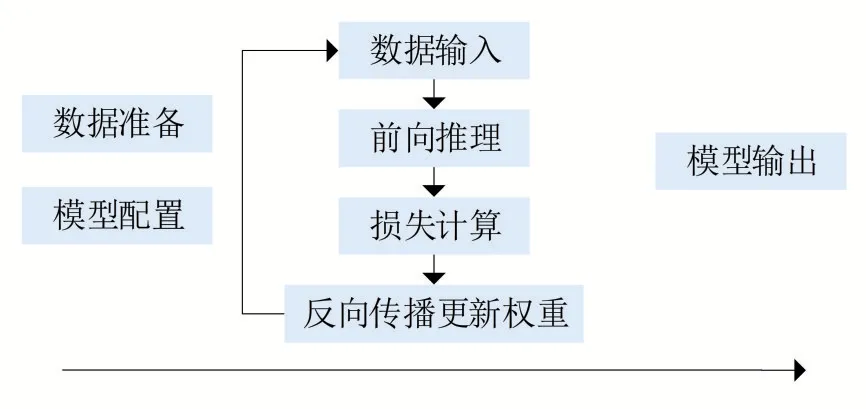
图2 模型训练流程规范
3.1.1 任务定义
根据网盘人工智能引入的图像类应用场景,可将任务分成以下大类。
(1)分类任务。识别一张图是否是某类物体/状态/场景,适用于图片内容单一、需要给整张图片分类的场景。如果要识别的主体在图片中占比较大且为单一主体,则可将任务设定成分类任务。
(2)检测任务。检测图中每个物体的位置、名称。适合图中有多个主体要识别、或要识别主体位置及数量的场景。如果识别的主体在图片中占比较小,且实际环境很复杂无法覆盖全部的场景,建议用物体检测的模型来解决问题。
(3)分割任务。对比物体检测,支持用多边形标注训练数据。适合图中有多个主体、需识别其位置或轮廓的场景。如果需要对目标物体进行精确定位或分割出来,则将任务设定成图像分割任务。
3.1.2 数据集规范
在分类任务中,每个分类需要准备20 张以上图片;如果想要较好的效果,建议每个分类准备不少于1000 张图片,涵盖各种角度情形。每个分类的图片需要覆盖实际场景里面的可能性,如拍照角度、光线明暗的变化,训练集覆盖的场景越多,模型的泛化能力越强。训练图片和实际场景要识别的图片拍摄环境接近,例如:如果实际要识别的图片是摄像头俯拍的,那训练图片就不能用网上下载的目标正面图片。
建议图片类型为png、jpg、bmp、jpeg,图片大小限制在4M 以内;图片长宽比在3:1 以内,其中最长边小于4096px,最短边大于30px。
AI 模型在训练时,每训练一批数据会进行模型效果检验,以一批验证图片作为验证数据,通过验证结果反馈去调节训练。验证集的标签应与训练集完全一致,验证集图片不应与训练集图片重叠。
AI 模型的效果测试不能使用训练数据、验证数据进行测试,应使用训练数据集、验证数据集外的数据测试,这样才能真实地反映模型效果。测试集的标签是训练集的全集或者子集即可。
3.1.3 模型配置
任务类型决定了网络结构的选择。根据任务定义进行模型类型、网络结构、数据迭代器、损失函数、优化器的配置和选择。
(1)确认模型类型。根据任务类型决定使用的网络结构。主要分为分类网络、检测网络、分割网络三类。
(2)确认模型量级。根据应用场景对处理速度、准确率的要求进行模型大小和模型运算量的估算,再进行网络结构选型。据此,确认主干结构、确认头部结构、输入输出数据结构。
(3)确认算子支持。对于已知输出平台的模型,尽量选用平台支持、优化的算子进行结构设计。
(4)数据迭代器设计。通过色域转换对特定通道进行随机增强,如对亮度、饱和度、色调进行随机扰动。根据实际使用场景、目标大小和数据集特点,进行匹配实际场景的增强,如对于希望小目标检出的模型对数据进行马赛克扩增。
(5)损失函数的设计。同样根据任务类型决定损失函数,这样能提升模型训练效果。分类任务常见损失使用softmax 交叉熵损失函数;检测任务常见损失使用IOU 损失、二分类交叉熵损失函数。分割任务常见损失使用交叉熵损失函数。在具体任务具体需求实践过程中,需对上述损失函数进行适应性改进。
(6)优化器设计。根据任务训练难度选择不同的学习率衰减策略和优化器。常用学习率衰减策略如指数衰减、固定步长的衰减、多步长衰减、余弦退火衰减等。常用优化器如Adam、SGD 等,Adam 可以帮助模型快速收敛,但在部分场景下可能会错过最佳优化点;SGD 收敛较慢,需要人工调参,但在某些情况下可以达到比Adam更好的精度。
3.2 模型测试规范的设计
模型测试是指将符合模型使用场景并具有真实标签的数据输入模型,将模型的预测标签与真实标签进行对比并计算出指标值,通过这些指标值评估或对比模型在真实使用场景时的表现是否能够满足预期,即输出值是否能够满足人们在实际场景使用模型的需求。根据不同的模型类型需要制定不同的模型测试方式、模型测试规范、测试使用指标。

图3 模型测试流程规范
在模型测试时往往需要与一个已知使用效果的基准模型进行对比,我们期望的新模型是需要优于之前的基准模型。即在整体指标相当的情况下,某些关键指标优于基准模型,从而实现对基准模型的替换,并将新模型设定成新的基准模型。
3.2.1 测试方式定义
任务类型决定了测试方式。根据任务定义进行模型测试方式的选取。
(1)分类任务。将测试数据按模型输入进行预处理,将模型的返回结果映射成类别标签,将类别标签与真实标签比较进行测试指标计算、统计。
(2)检测任务。将测试数据按模型输入进行预处理,将模型返回结果进行解析,将解析出的结果映射到原图形成真实的检出框位置、置信度和类别,根据这些信息与真实标注比较进行测试指标计算、统计。
(3)分割任务。将测试数据按模型输入进行预处理,将模型返回结果进行解析,得到目标物体的类别和掩码,将物体类别和掩码与真实标注比较进行指标的计算、统计。
3.2.2 测试规范设计
在实际验证模型效果的过程中,建议每个分类需要准备20 张以上;一般建议每个类别准备100张左右测试图片。图片格式参考训练图像数据格式,且需与实际场景相近,能覆盖实际场景里面的可能性,如拍照角度、光线明暗的变化。分类任务中,需要标注图片的类别;检测任务,需要标注图中存在所有待检测目标的位置及类别;分割任务,需要标注所需分割目标的边缘及类别。
3.2.3 测试指标设计
根据模型类型,在标注好的测试集上对需要的测试指标进行统计。具体的评估指标有如下几类:
(1)准确率(accuracy)。预测正确的样本数量占总量的百分比。测试样本不均衡时,这个指标不能评价模型的性能优劣,需结合其他指标一起使用。
(2)精准率(precision)。针对预测结果而言的一个评价指标。在模型预测为正样本的结果中,真正是正样本所占的百分比。
(3)召回率(recall)。针对原始样本而言的一个评价指标。在实际为正样本中,被预测为正样本所占的百分比。
(4)PR 曲线。主要描述精确率和召回率变化的曲线,用于比较不同模型在各阈值下的整体性能优劣。通过置信度对所有样本进行排序,再逐个样本的选择阈值,在该样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的precision和recall,以此绘制曲线。
(5)ROC 和AUC。ROC(receiver operating characteristic)曲线,又称接受者操作特征曲线。曲线对应的纵坐标是TPR,横坐标是FPR。其中,TPR 含义是检测出来的真阳性样本数除以所有真实阳性样本数,FPR 含义是检测出来的假阳性样本数除以所有真实阴性样本数。AUC(area under curve)是处于ROC 曲线下方的那部分面积的大小。AUC 越大,代表模型的性能越好。可以用于比较人脸识别模型性能的优劣。
(6)类别平均精准度(mean average precision,mAP)。一般在目标检测中结合IOU 使用。多个IOU 阈值在每一个IOU 阈值下都有某一类别的AP值,然后求不同IOU阈值下的AP平均,就是所求的最终的某类别的AP 值。所有类的AP 值平均值就是mAP。mAP 一般用于需要精确检测框的检测模型评价指标。
4 结语
本文基于个人网盘业务长期发展趋势,结合人工智能技术分析了可行性的业务结合应用场景。针对多种多样的应用场景,本文提出了人工智能在个人网盘应用的模型训练与模型测试规范。该设计规范方案涵盖多种人工智能技术应用场景,为研究落地,技术功能实现提供了一套行之有效的模型训练、测试的设计方案。这对后续能力与业务结合的建设开发工作具有指导价值与参考意义。
