基于语义分析的工艺知识库构建方法及应用
2022-06-16宋庆明沈思远
梁 蕾,宋庆明,沈思远,吴 敏
(上海飞机制造有限公司制造工程技术中心, 上海 201324)
0 引言
自动或智能的工艺设计一直是计算机辅助工艺设计系统(CAPP)的目标。实现工艺设计的智能化,需要给工艺设计软件赋能,使之具有设计问题理解、设计结果生成、设计知识学习等能力。上述能力的核心是工艺设计知识,涉及知识如何获得、表达、更新以及在特定条件下触发应用。而工艺知识的获取即工艺知识库构建一直是关键问题。现有工艺知识库的构建方法为人工构建,包括本体及产生式规则等方法。
本体通常由概念集、关系集、属性集、实例集和规则集构成,各工艺知识研究略有差异,但都包括概念集与关系集。文献[1]建立涵盖工艺参数、刀具、机床、零件、零件特征与材料等概念的本体,可解析基于特征类型、基本参数以及零件材料的属性等。文献[2]利用本体描述了装配对象、属性与工艺适用条件。文献[3]面向零件装配问题,设计并构建了几何特征增强的本体模型,使用本体对3D 模型中关键的几何特征进行了标注。文献[4]利用本体标注工艺案例,采用了一种层次表示法对产品结构、装配关系(精度)信息等进行表达。产生式的基本形式为“IF P THEN Q”。P 是产生式的前提,也称为前件,给出了该产生式可否使用的先决条件,由事实的逻辑组合来构成。文献[5]特别针对企业工艺信息是文本描述的特点,对工艺文本进行话语分析从而生成规则。该文给出的示例是用于机床设备的选择。文献[6]分别建立了零件特征族集与工序序列族集,采用产生式规则建立二者间的关系。文献[7]定义了偏好关系,并建立了典型的工艺条件属性,建立了属性与工序序列间的逻辑关系,以典型的工艺条件属性为规则前件,加工工艺链为规则后件。
无论是本体还是产生式规则,皆由人工构建,对构建人员的专业能力及信息技术能力要求极高,一方面能够汇总、归纳与分析工艺现象与工艺方法,总结形成知识库;另一方面需要掌握本体与产生式规则的表示方法与管理方法。再者,人工构建本体及产生式等知识库是复杂的工程过程,在多人协助的情况下,难以保证规则无冲突、本体概念理解一致、规则与概念覆盖充分等要求。特别是,面向飞机等复杂产品,构建工艺知识库是极具挑战性的难题。现今,深度学习等人工智能技术发展迅速,基于深度学习方法的语义分析技术已经在分词、命名实体识别、机器翻译等领域得到了广泛的应用。本文基于深度学习方法的语义分析方法,提出了基于语义分析的工艺知识库构建方法。该方法能够自动地从历史工艺数据中归纳出工艺知识,极大地降低了人工投入,能够保证工艺知识库的覆盖度,并且知识与历史应用情境关联,实现在相同情境匹配下知识的推送重用。在某型号支线客机航电与电气专业上构建了工艺知识库并实现了工艺知识推送软件。
1 工艺知识库构建
1.1 工艺知识库的构成
本文所构建的工艺知识库为工序名称库、工序语句库及工艺过程库。工序名称是简要表明本步工序的操作内容的词语或短语。工序语句描述了本步工序的操作内容,包括:遵照规范、图纸、操作对象、所需零件、参数、操作等。工艺过程是由工序名称及语句构成,描述了一类零件工序过程。各知识库示例如表1 所示。工序语句中的“【图纸】”与“【位置】”等为变量槽,由工艺员依据设计任务填写。变量槽能够扩大语句的应用情境,能够应用于相同操作方法的不同工况下,变量槽总共设计了12种。

表1 工艺知识库中知识条目的示例
1.2 构建流程
本文所提出的基于语义分析的工艺知识库构建方法是一种自底向上的归纳式构建方法。该方法能够保留各类知识条目的应用情境,从而通过情境匹配实现知识的重用。工艺知识库构建过程分为语义化表达、聚类分析、工艺模板构建,输入为历史装配大纲数据,输出为各类工艺知识库(见图1)。

图1 工艺知识库的构建过程
其中,语义化表达通过自然语言处理技术实现工序语句的理解,形成可计算的语义向量。聚类分析,分为工序名称的聚类分析及工序语句的聚类分析,在获得语义向量的基础上,利用层次聚类算法对语义向量进行聚类。聚类所形成的每个类簇则为语义最相近的工序名称或是工序语句的集合,即表达同种工艺方法或是操作方法。工艺知识确认,由人工分析聚类结果,拟定每个类簇所代表的工艺方法或操作方法的标准表达方法,并将工序语句内参数替代为参数槽,形成最终的工艺知识库。工艺过程库是依据工序名称与工序语句和情境的关联关系,反向替换原装配大纲中的语句和名称获得。本文将重点介绍语义分析方法。
1.3 语义分析
工序名称及工序语句是由自然语言描述的非结构化数据,是不可计算的。自然语言处理计算是实现语言可计算并使得计算理解自然语言的技术。目前,最常用的自然语言处理技术是基于深度神经网络的方法,被广泛地应用于中文分词、命名实体识别、机器翻译等。本文提出基于深度神经网络的工艺语言分析方法,具体为基于双向长短时记忆网络(Bi-directional Long-Short Term Memory Network,BiLSTM)的自编码器(autoencoder)。该方法以工序名称或工序语句为输入,以实数向量为输出。该实数向量便为工序名称或工序语句的语义编码,用于后续的聚类分析。
基于双向长短时记忆网络的自编码器模型结构如图2 所示,由编码器与解码器两部分构成。编码器输出语义表示向量,语义表示向量再输入到解码器中。若解码器的输出能够还原编码器的输入,则表明语义表示向量完全包含了输入语句的信息。具体地,编码器首先将每个字采用随机实数向量表示,作为编码器输入,然后将该向量输入到LSTM 网络中。LSTM 的具体结构可参见文献[15],此处不再详述。采用两层LSTM 结构,即从句首至句尾和从句尾到句首的两层,从而建模整句的语义信息。之后,为由Sigmoid 函数构成的输出层。最后将输出层向量拼接为语义向量。解码器的过程与编码器相反,以语义向量为输入,但模型结构完全相同,不再赘述。模型参数的训练采用输入与输出的差为损失,采用反向传播算法获得。
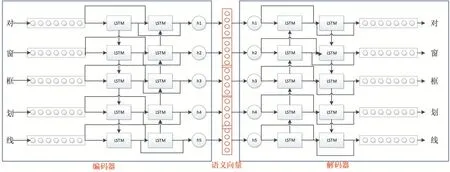
图2 双向长短时记忆网络的自编码器模型
2 案例验证
本文采用某型号支线客机的电气与航电专业535 份装配大纲为基础数据,验证了本文所提出方法。在基础数据中包含558 种工序名称和1153 种工序语句,这显然是不合理的,存在了大量的不同名称相同工艺方法与不同语句相同操作的歧义现象,是由工艺人员间个体论述方式的差异造成的。
双向长短时记忆网络的自编码器模型字的随机向量设置维度为100 维,LSTM 网络窗口设置为5,输出维度设置为50 维度,Sigmoid 层输出也为50 维度,语义向量的维度为5(窗口)×50(输入维度)=250维。
通过语义分析、聚类分析及工艺知识确定的过程,形成了工序名称库含工序名称152 项,工序内容语句库152 项,基础数据的覆盖度为97.1%;形成工艺过程库含工艺过程247项。

表2 工序语句库示例
由于本文所构建的工艺知识库的知识关联了历史工艺数据,能够表达工艺知识的应用情境,因此能够实现在工艺设计任务的情况下,推送与知识应用情境相同的工艺知识。因此,研发了基于工艺知识库的工艺知识推送软件,应用效果如图3所示。

图3 工艺知识推送软件示例

表3 工序内容库示例

表4 工艺过程库示例

续表4
3 结语
本文提出了基于语义分析的工艺知识库构建方法。该方法基于语义分析技术能降低人工构建知识库的成本与周期,并且所构建的知识库携带应用情境信息,能够实现基于情境匹配的工艺知识推送,从而实现知识的重用,提升工艺设计效率和质量。具体构建过程为:通过双向长短时记忆网络的自编码器模型的方法实现工序内容的理解,形成可计算的语义向量;再通过层次聚类算法,形成语义最相近的工序名称或是工序语句的集合;最后,由人工分析聚类结果,拟定每个类簇所代表的工艺方法或操作方法的标准表达方法,反向替换原装配大纲中的语句和名称获得。在某型号支线客机的航电与电气专业的数据及工艺设计任务上进行了验证与实例分析,证明了本文所提出的方法。
