基于三维姿态估计的智慧体能计数算法
2022-06-16陶青川
吴 玲,陶青川,敬 倩
(四川大学电子信息学院,成都 610065)
0 引言
现有的体能计数系统主要采取人工计数或者红外设备检测的方式,不仅效率低、误差大,而且成本高。近年来,随着人工智能的快速发展,计算机视觉领域的许多技术如人脸识别、语义分割和姿态估计等,在智能安防、远程医疗和体感游戏等领域得到了广泛应用。因此,基于计算机视觉技术的智能计数算法在体能训练中的应用具有重要意义。
姿态估计是计算机视觉领域的一个热门研究方向,其包括二维姿态估计和三维姿态估计。对于多人二维姿态估计而言,主要有两种方法:自上而下以及自下而上。对于自上而下方法,首先是利用目标检测网络检测出所有人体目标,然后对每个目标做姿态估计。He 等提出了一种在有效检测目标的同时输出高质量实例分割Mask 的MASK-RCNN 算法。Chen 等提出级联金字塔网络(cascaded pyramid network,CPN),可以提供上下文信息,用于推断被遮挡的关键点。对于自下而上方法,需要先找到图片中的所有关键点,然后把这些关键点按一定算法规则匹配组成完整个体,如Cao 等提出的Openpose 经典算法,使用PAFs(part affinity fields)这种结构对全局上下文进行编码,自下而上进行解析,能够实时地进行多人二维姿态估计。
二维姿态估计虽然能简单有效地将人体的姿态轮廓刻画在二维平面上,但是当拍摄视角和姿态动作快速变换时,不同的关键点因为相互遮挡可能会映射到二维平面的同一位置,或者出现漏检、检测不稳定等情况。随着姿态估计技术的不断发展及应用场景的复杂化,二维姿态估计的弊端日益凸显,因此越来越多的学者投入到三维姿态估计技术的研究中。三维姿态估计可以检测关键点的深度信息,能够有效地解决部分遮挡情况下的关键点信息丢失问题,基于深度学习的三维人体姿态估计现已成为三维姿态估计的主流研究方法。
本文基于三维姿态估计网络提出了一种Fast-3D-Pose-Counter 智慧体能计数算法,该算法由数据采集模块和三维姿态计数算法模块组成。数据采集模块通过单目RGB 摄像头采集人体体能训练视频图像,计数算法模块由改进的YOLO_v3 目标检测,自上而下的SimplePose 二维姿态估计网络,3D-Pose-Baseline 三维姿态估计网络和KNN 动作分类器组成。算法总流程图如图1所示。
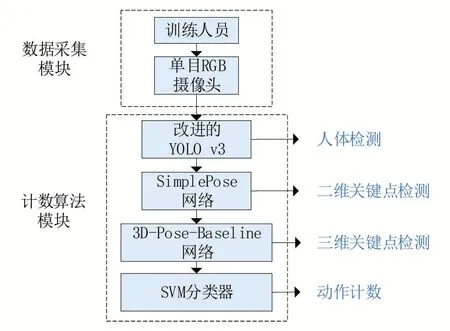
图1 算法流程
1 体能计数算法
1.1 二维关键点检测
二维关键点检测包括自上而下和自下而上两类方法。自上而下的特点是准确率高,但推理速度慢;自下而上的特点是推理速度快,但准确率低。由于后期需要建立二维关键点到三维关键点的非线性网络映射,然后再对三维坐标特征向量进行分类实现动作计数,因此二维关键点的推理精度至关重要,所以本文选择了自上而下的方法实现二维关键点的检测。自上而下法包括两个步骤:①人体目标检测。②基于检测框做姿态估计。
1.1.1 基于改进的YOLO_v3人体目标检测网络
经典的YOLO_v3 网络以Darknet-53 作为骨干网络,复用Darknet-53 的前52 层网络结构,去除了最后一层全连接层,所以YOLO_v3 网络是一个全卷积网络,其网络结构中大量使用Resnet 的跳层连接结构。YOLO 将图像划分为×的网格,当目标中心落在某个网格中,就用这个网格去检测它,每个网格需要检测3 个锚框,对于每个锚框,它包含坐标信息(,,,)以及置信度等5 个信息,同时还会使用one-hot编码包含是否含有所有类别的信息,如COCO数据集含有80 个类别,所以,每个特征输出层的维度为:
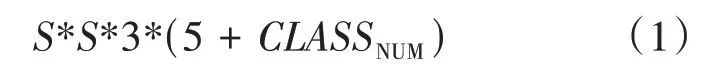
其中CLASS表示数据集包含的类别数量。需要注意的是,原Darknet53 中的尺寸是在图片分类训练集上训练的,输入的图像尺寸是256×256,而本文采用输入的尺寸是416×416。图2为YOLO_v3 416 的网络模型结构图,最终得到三个特征层尺度,分别是52×52、26×26、13×13。特征图越小,感受野越大,越适合检测大目标;特征图越大,感受野越小,越适合检测小目标。所以52×52 的特征图适合检测小目标,26×26 的特征图适合检测中目标,13×13 的特征图适合检测大目标。

图2 YOLOv3网络结构
由于本文提出的算法应用在单人体能训练场景,摄像头采集的人体目标较大,因此需要在原YOLO_v3网络上进行改进,改进策略如下:
(1)考虑到实际应用场景中的人体目标较大,同时为了保证在一定的检测距离范围内的检测效果,只保留13×13 以及26×26 这2 个独立预测分支。
(2)为了保证整个三维姿态估计算法的实时性,需要使用一个高效精简的网络快速准确地定位出人体目标,因此在原YOLO_v3 的基础上对网络层进行删减,改进后的网络结构如图3所示。

图3 改进后的YOLOv3网络结构
使用改进之后的网络对自制数据集进行训练,得到的检测模型大小为13.7 M,约占原YOLO_v3模型的1/17,在i5-6500 CPU 上实际部署时推理速度可达71.6 FPS。部分检测效果如图4所示。

图4 改进的YOLO_v3检测人体效果
1.1.2 基于SimplePose进行二维姿态估计
SimplePose是一个简单高效的单人姿态估计模型,它采用自上而下的策略,在被检测人体目标的基础上进行二维姿态估计,使用Resnet作为骨干网络,其网络结构如图5所示。

图5 SimplePose网络结构
SimplePose 没 有 采 用Hourglass和CPN 等姿态估计网络设计的金字塔形特征结构,而是直接利用Resnet 残差模块的输出特征层(C5)生成姿态的热力图(heatmap),然后在其后接入3个反卷积和卷积交替的模块来获得高分辨率的heatmap,每个反卷积模块都采用Deconv +BatchNorm+ReLU 结构,最后用1 个1*1 的卷积层改变通道数,使得输出热图个数为关键点个数。
为了提高姿态估计的有效性,避免直接从单帧图像中进行姿态估计而导致的被遮挡关键点漏检误检的问题,SimplePose基于光流对姿态进行跟踪,主要思想参考了Girdhar 等提出的姿态跟踪方法,使用光流法对检测框进行补充,使用OKS 代替检测框的IOU 来计算相似度等,具体方法如下:
(1)确定bbox。将人体目标检测器检测的bbox 和基于光流估计的bbox 采用NMS 进行统一。
(2)对bbox 进行剪切和Resize,然后采用SimplePose姿态估计网络进行姿态估计。
(3)最后通过OKS 度量人体关键点相似度,按照基于光流的跟踪对检测到的行人实例的姿态进行不断的更新。
更新策略是首先估计每帧中人的姿态,通过分配一个特有的id 来在不同帧之间对人体姿态进行跟踪。然后计算上下帧中人体关键点的OKS 相似度,将相似度大的作为同一个id,没有匹配到的分配一个新的id。给定帧k的一系列目标P={p},和帧l 的一系列目标P={p},基于流的姿态相似度度量定义为:
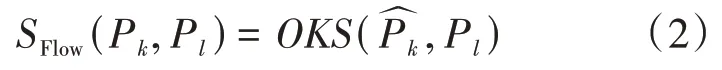
OKS指标定义如下:
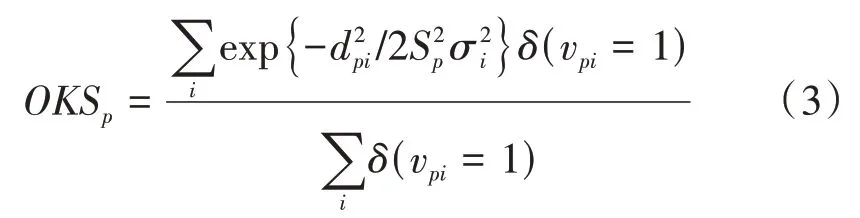
其中表示Groundtruth 中人物的,表示关键点的,d表示Groundtruth 和预测图中的每个人关键点的欧氏距离,S表示当前人物在Groundtruth 中所占面积的平方根, 即

本文将上文提到的改进的YOLO_v3 网络用作人体目标检测器,并结合SimplePose 光流检测框对人体目标进行检测,仅保留检测框内的人体目标图像作为SimplePose 二维姿态检测模块的输入,检测人体的骨骼关键点,SimplePose监测的关键点数量为17 个,分别为鼻子、左右眼、左右耳、左右肩、左右手肘、左右手腕、左右臀、左右膝、左右脚踝。考虑到体能训练中主要关注的部位为人体的躯干,因此本文将SimplePose 姿态估计模块的输出通道数减少为13,即去掉脸部的双耳、双眼这四个关键点,这样既可以减少训练计算量,又可以提高检测速度,改进之后的SimplePose 检测效果如图6所示。

图6 改进后的SimplePose检测效果
1.2 基于3D Pose Baseline实现三维关键点检测
3D Pose Baseline 是一个超轻量级的神经网络模型,可以很好地处理2D 到3D 姿态回归的问题,其网络结构如图7 所示。该网络结构简单,使用Resnet 作为骨干网络,将每一个Resnet 结构作为一个Block,每个Block 中包含了两个全连接层(linear 层),每个全连接层后面都紧连着Batch Normalization、ReLU 和Dropout层。除此之外还在Block 前加了一个全连接层,用来将输入的16×2 的二维关节点坐标升维到1024 维。同样地,在网络最后也加了一个全连接层,用来将1024 维的数据降维到16×3 的三维坐标。整个网络只需要一些基本的计算模块和结构,即可达到实时准确的三维姿态估计。
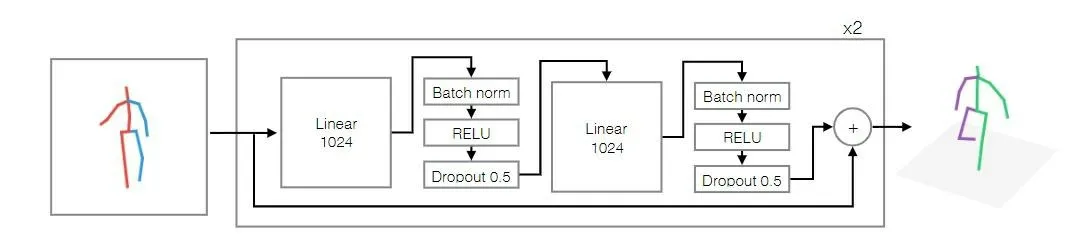
图7 3D Pose Baseline网络结构
本文在改进的SimplePose 网络输出坐标的基础上,将其二维姿态检测的坐标格式统一为3D Pose Baseline 要求的输入格式,然后将输入图像旋转,使用3D Pose Baseline 网络在Human 3.6 M 数据集的训练模型进行测试,最终的3D姿态检测效果如图8所示。

图8 3D姿态检测效果
1.3 基于KNN算法实现动作计数
KNN(K nearest neighbors)算法又叫K近邻算法,它是有监督学习分类中的一种经典算法,其实现过程包括3个步骤。
(1)计算待分类物体与其他物体之间的距离。
(2)统计距离最近的个实例。
(3)个实例中拥有最多实例的类别即为未来新样本的实例。
该过程中涉及的主要因素有两个:值的选择,距离度量的方式。
对于值的选择:越大,则满足新样本距离要求的实例会越多,模型简单但可能会欠拟合。越小,模型会变复杂,但是容易发生过拟合。所以值一般小于20,当值适当时,无论新样本是什么,预测结构都是训练集中实例最多的样本。
对于距离的度量,两个样本点之间的距离代表了这两个样本之间的相似度。距离越大,差异性越大;距离越小,相似度越大。最常见的度量方式有两种:欧氏距离和曼哈顿距离。假设存在两个点(,,…,),(,,…,y),各个距离的定义如下:

其中,代表特征维度,代表空间的维数,当=1 时,就是曼哈顿距离;当→∞时,就是切比雪夫距离。
本文对三维姿态估计之后获得的人体16 个三维关键点坐标进行处理,计算三维空间坐标系下左右手肘、左右腰部和左右膝盖这六个关节部位的弯曲角度,得到基于三维关键点坐标的六维特征向量。然后采用欧氏距离度量方式,设定值为13,基于KNN 算法对特征向量按照仰卧起坐的躺卧、上伏、贴膝这三个状态进行分类,若按顺序依次完成这三个动作,则计数加一,若因为动作不规范没有按照顺序进行或者未执行规定动作则计数不变。
2 实验与分析
本文的实验环境为Ubuntu16.04 LTS,内存8 G,处理器为Intel Core i5-7500 CPU,主频3.4 GHz,基于64 位操作系统,GPU 型号为Ge-Force GTX 1080Ti,显存16G,模型的训练和测试基于Pytorch 1.8.0框架。
由于算法中含有二维姿态估计模块和三维估计姿态模块,因此需要选择不同的数据集进行训练。现有的二维数据集,如MS COCO、MPII 等,图像中的人体大部分以站立为主,而本文主要关注的是体能训练场景,如俯卧撑、仰卧起坐等,大部分人物姿态是以横躺或者坐立为主,实验结果表明现有的公开数据集并不适用体能训练场景。因此,本文以仰卧起坐项目为例,利用labelme 对自采集体能训练集进行打标,然后通过镜像、旋转和裁切等数据增强算法扩充了样本容量,达到8000个样本。最后,利用COCO API对数据集进行归一化处理,最终的样本格式如图9所示。

图9 自制二维姿态数据集
Human3.6M是使用最广泛的多视图单人三维人体姿态数据集。该数据集包含360万个3D人体姿势和15个场景中的相应视频,比如讨论、坐在椅子上、拍照等。由于Human3.6M数据集包含的场景丰富,我们的体能训练源数据经过旋转处理后,可以与该数据集中的很多姿态样本符合,所以本文选取了Human3.6M数据集的S1、S5、S6、S7、S8作为训练集,S9、S11作为测试集。
本文将体能计数的准确率作为评价指标,选取80个时长约25 s的体能测试视频进行测试,包含1180 个有效动作,最终的计数准确率可以达到99.6%,实测帧率约27.4 FPS,具备很好的实用性。相比于传统的计数方法,计数精度大大提高,成本大幅降低。相比于仅用二维姿态关键点的几何角度判断法,本算法能在摄像头拍摄视角变换的情况下保证计数精度,使用更为灵活方便。相比于二维姿态分类计数算法,本算法能改善二维姿态估计中由于目标遮挡导致的误检漏检情况,利用空间信息实现更为准确地计数。基于本算法的部分测试效果如图10所示。

图10 本文算法效果
3 结语
本文提出了一种基于三维姿态估计的智慧体能计数算法,该算法能够从单目摄像头采集的图像中,准确快速地提取出人体三维骨架特征,然后对三维坐标特征向量进行分类以实现精确计数。实验结果表明该算法可以有效地克服传统计量算法的局限性,在存在部分遮挡、拍摄角度适当变换的情况下也能够保证计数准确率。该算法具有广阔的实际应用前景,如健身效果评估和体感游戏等。但是,由于缺少大型的3D 室外数据集以及单视角中2D 到3D 的映射固有的深度模糊性,导致该算法在极少数场景中下存在计数误差,后期将通过增加摄像头数量以及扩充数据集进行进一步完善。
