基于生理参数与角度的个性化HRTF 深度学习重建方法
2022-06-15赵曼琳
赵曼琳,方 勇
(上海大学 通信与信息工程学院,上海 200444)
0 引言
近年来,虚拟现实(Virtual Reality,VR)和增强现实(Augmented Reality,AR)技术发展迅速。虚拟立体声作为虚拟现实的重要组成部分,已广泛应用于游戏、视频会议以及助听器等领域[1]。空间声音的质量对于在虚拟环境中实现高保真沉浸式体验尤为重要。
目前,空间音频技术已经支持在多种设备上播放,其中头部相关的传输功能对于耳机再现虚拟音频非常重要。时域形式的头部相关传递函数(Head Related Transfer Function,HRTF)或头部相关脉冲响应(Head Related Impulse Response,HRIR)描述了在自由场环境下从声源到听者耳膜的过程中头部、躯干及耳廓的声音过滤效果。HRTF 取决于听者的形态特征。用户拥有不同的生理参数,他们的HRTF 也不同。在使用不匹配数据时,用户容易出现头中心效应、前后位置混淆、上下混淆等问题[2]。
为了获得更符合听觉感知的空间音频,需要单独设计每个听者的HRTF。为此,研究人员提出了多种HRTF 个性化方法,包括测量方法[3]、数据库匹配方法[4]、数值建模方法[5]以及人体测量参数回归方法。其中,测量方法最为准确,但需要专门的设备,耗时很长。因此,人体参数回归方法被广泛研究,因为预测模型一旦确定就可以重复使用。
本文提出了一个深度神经网络模型,根据人体测量学参数和角度信息重建个性化头相关函数(HRTF)。所提出的方法由三个子网组成,包括将人体测量参数作为输入特征的深度神经网络(Deep Neural Networks,DNN),将角度信息作为输入的展开层(Flatten),最后将其合并送入深度神经网络实现个性化HRTF 的预测,并在实验结果处对所提出方法的整体性能进行了客观评价。
1 模型设计
本文提出了一种使用人体测量参数和角度信息来估计个性化HRTF 的方法。模型的神经网络由三个子网络组成。所提出的神经网络的第一个子网络是DNN,使用人体测量参数(头部、躯干、耳廓参数等)作为输入特征来表示人体测量值和HRTFs 之间的关系,被称为“子网A”。第二个子网络用于将二维的方位角信息(仰角及方位角)一维化,被称为“子网B”。使用另一个DNN 网络将两个子网组合在一起,以估计个性化HRTF,称为“子网C”。模型框架如图1 所示。

图1 模型框架
2 数据库介绍
在设计和实现个性化HRTF 的过程中,使用了加州大学戴维斯分校图像处理与集成计算中心(CIPIC)公开提供的HRTF 数据库[6]。该数据库包含45 名受试者在25 个不同方位角和50 个不同仰角、1 250 个空间方位角的头部相关脉冲响应(HRIR),采样长度为200,采样率为44.1 kHz。空间采样大致均匀分布在半径为1 m 的球面上。水平方位角范围为-80~+80,高度角范围为-45~230.625。采样点如图2 所示,可以看出,采样点分布在整个球面上。
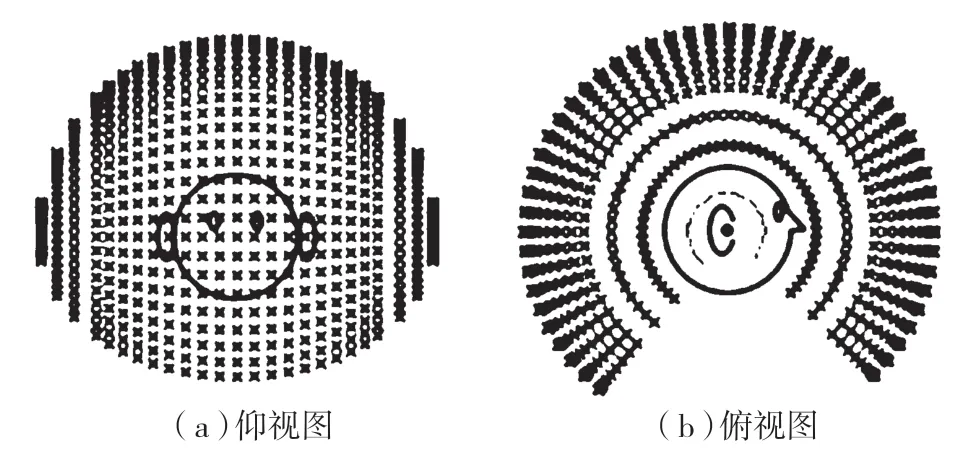
图2 采样点位置
该数据库还提供了每个受试者的人体测量参数和耳朵图像,包括17 个头部和躯干参数以及10个耳廓参数。具体测量参数如图3 所示。

图3 人体测量参数
由于不同人体测量参数的尺寸范围不同,小尺寸测量参数对学习过程的影响可能会被忽略,因此首先使用文献[7]提出的sigmoid 函数对输入的27个生理参数进行归一化处理,处理方式为:

式中:xi是耳朵、头部或躯干测量参数的第i个测量值,ui和σi分别是所有训练对象的平均值和标准差。
3 网络架构
子网A 首先对27 个人体测量参数(左耳耳廓及头部、躯干参数)进行标准化,然后通过2 层32个节点的隐藏层提取特征,最后输出32 个节点。子网B 是一个Flatten 层,用于将二维的角度数据展平,成为子网C 的一部分。子网C 同样是一个DNN 网络,包括34 个节点的输入层和2 层64 个节点的隐藏层,最后输出200 个节点,对应CIPIC 数据库中HRTF 的长度。其中,为了避免梯度消失的问题,除输出层外,每一层激活函数均使用线性校正单元(ReLU)。
4 监督学习
良好权重的初始化可以降低成本并加快收敛速度,因此在训练阶段使用Xavier 技术将所有偏差初始化为零。算法的成本函数为参考HRTF 和估计HRTF 之间的均方误差(Mean Square Error,MSE),同时采用梯度下降的反向传播方法最小化成本函数来进一步更新权重。在这个过程中,采用梯度自适应Adam 方法对算法进行进一步优化,一阶衰减率设为0.9,二阶衰减率设为0.999,学习率设为0.001。同时使用Dropout 技术(保留概率设为0.9)进一步提高收敛速度,防止过拟合问题。
5 实验结果
实验结果部分,将基于客观测试来评估所提出的个性化HRTF 估计方法的性能。同时将该方法的性能与其他几种HRTF 估计方法进行比较。对比涉及的方法有:
(1)平均HRTF 的方法,使用35 名受试者的HRTF 平均值;
(2)DNN37[7]的方法,使用了左右耳廓及头部躯干的37 个生理参数;
(3)本文提出的方法,称为“Proposed HRTF”。
5.1 评价指标
为了进一步衡量所提出的个性化方法的估计性能,使用均方根误差(Root Mean Square Error,RMSE)和光谱距离(Spectral Distance,SD)作为客观评价指标。
均方根误差通常是用来评估两者之间距离的指标,定义如下:

式中:y(n)是数据库测量给出的参考HRTF,是该方法估计HRTF,N=200,是HRTF 的总长度。
光谱距离通常用于评估预测HRTF 的性能,定义如下:

式中:H(d)(n)为参考HRTF 在方向d的幅度响应,为方法估计HRTF 在方向d的幅度响应,k是频率仓的索引,K=129,是频率仓的总数。
计算SD 在多个方向上的平均值,即全局SD:

式中:D=1 250,是方向的总数。
5.2 性能评估
为验证所提出方法的有效性,图4(a)、图4(b)分别显示了受试者subject009 在(θ,φ)=(-80°,-45°)和(-45°,0°)方向预测HRTF 与真实HRTF 的结果(HRIR 是HRTF 相对应的时域表示)。可以看到最高点的幅值、包括整体曲线的走势,所提出的方法的预测效果都较好。

图4 subject009 在不同方向下预测及真实HRTF 对比
所提出的个性化方法通过一次训练即可得到全部1 250 个方向下(25 个方位角和50 个仰角)的HRTF 预测结果,因此给出的客观评价结果均为全局平均均方误差和光谱距离。
表1 给出了所提出方法在所有受试者的全局平均RMSE 和SD 值。此外,图5、图6 分别给出了所提出方法在不同个体受试者的全局RMSE 和全局SD 值。

表1 所提出方法的全局RMSE 和SD 值(单位:dB)
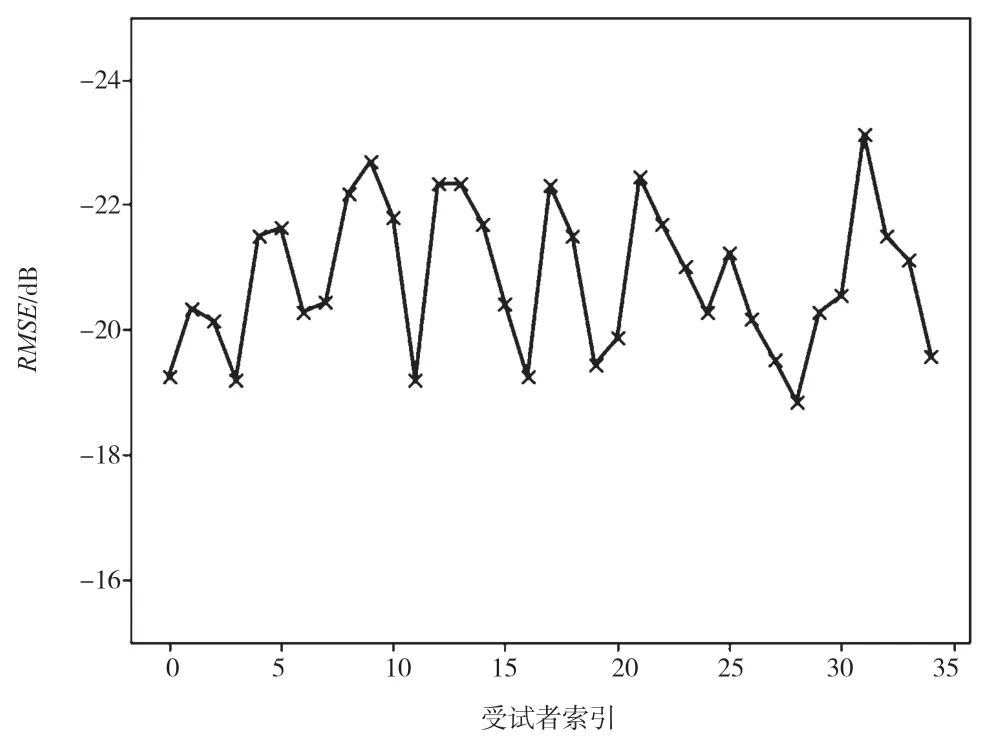
图5 不同个体受试者的全局RMSE 值

图6 不同个体受试者的全局SD 值
5.3 性能比较
为了进一步评估所提出方法的性能,与其他三种HRTF 估计方法进行比较,分别计算了参考HRTF 与估计HRTF 之间的RMSE和SD。结果如表2 所示。
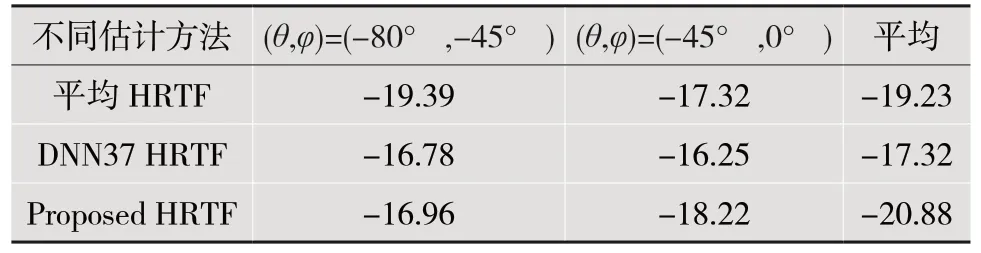
表2 不同估计方法的平均RMSE 比较(单位:dB)
从表2 和表3 可以看到,所提出的方法的RMSE值分别比平均HRTF 和DNN37 HRTF 低1.65 dB 和3.56 dB,方法的SD值比平均HRTF 低3.54 dB,比DNN37 HRTF 高0.38 dB。对于DNN37方法,它的每个模型都是针对一个方向建立的,因此,要获得所有声源位置的HRTFs,需要构建1 250 个DNN 模型。因此,就需训练的模型数量而言,所提出的方法需要更少的模型和更少的参数。

表3 不同估计方法的平均SD 比较(单位:dB)
6 结语
本文提出了一个生成个性化HRTF 的深度神经网络模型,通过人体生理参数及角度信息重建全局的HRTFs。在算法中,通过加入角度信息作为输入特征,仅需一次训练就可获得所有声源位置的HRTFs,使得需训练的模型数量大幅度下降。实验部分对算法的性能进行了评估,给出了算法在不同方向时预测HRTF 和真实HRTF 的结果对比图。实验结果表明,该算法具有良好的性能,与其他几种估计HRTF 方法相比,具有较好的定位性能。
