汉语方言语音信号的语谱图分析
2022-06-15柏文展程汪鑫
柏文展,程汪鑫
(武警广西总队,广西 南宁 530031)
0 引言
语音信号是一种模拟信号,经过数字化处理后可获取采样率、比特率以及频域内的各种参数信息,便于信号传输和存储。通过观察不同语音信号的语谱图,可获取语音的一些参数和特征,经分析比对,可识别出不同地方的语言,为语音合成奠定了基础。语音识别技术的发展依赖计算机技术、数字信号处理器(Digital Signal Process,DSP)技术以及人工智能(Artificial Intelligence,AI)技术的进步。要实现人机对话,需要设计制造出一种能将人类语音信号进行自动转换和处理的机器来模拟现实生活中的人,实现人与机器的“无障碍”沟通交流。要设计出能听懂人类语言的机器,关键是让机器正确辨别出所说语言的语种,便于选用合适的语音参数库,提高识别的效率。从1970 年开始,人们就开始研究如何通过词汇来进行语种识别,因为每一种语言都有着自己独特的、成熟的、延续性的词汇体系。在实际中,运用词汇法来进行识别存在一定的困难,主要是因为收集、组织、整理各个语种的语言专业知识工作量过于庞大,通过计算机分析语言学专业知识来识别语言的效率不高,正确率低,难以得到推广应用[1]。因此,人们把目光转到通过语音的特征来进行语言识别。
随着5G 网络、大数据及人工智能等高新技术的发展,社会生产生活日益数字化、网络化和智能化,方言识别技术被广泛应用于通信、金融、教育、翻译、刑侦以及信息服务等领域,越来越展现出其应用价值。在语音通信方面,特别是在紧急情况拨打紧急电话,可使用语音识别系统快速进行方言识别,自动将电话转接到与呼叫者说同种方言的接线员那里,提高交流效率,争取宝贵时间。在刑事侦查方面,可通过方言识别系统辨别出说话者的籍贯,从方言特征中获取关键信息。目前,方言识别的能力和准确度得到了质的提升,国内的一些智能语音公司如科大讯飞已经开发出可以识别粤语、四川话、闽南语等20 多种方言的语音识别系统,提高了人们沟通交流的效率。本文通过对方言语音的语谱图进行分析,来辨别和判断讲话者所属的方言区域,对语谱图进行比较并找出其差异,为方言语音的识别与推广提供基本理论和方法。
1 语音信号
1.1 语音信号的产生和声学基础
1.1.1 语音信号的产生过程
语音信号的产生过程为:说话人在大脑中将语言信息转换为语言编码,并用语音特征如音素序列、韵律和响度等来表示;说话人通过语言编码控制声带振动,塑造声道形状来发出声音序列;听者通过耳朵的基底膜接收语音信号并进行动态频谱分析,将频谱信号转换为触动信号作用在听觉神经上,通过大脑分析处理将其转化为语言编码,实现对语音语义的理解[2]。
1.1.2 声波的物理描述
声波属于纵波。声源产生声波,声波以声源为中心沿着各类介质将能量向周围传递,可用频率、周期、相位、波长及振幅等物理参数来描述。波长与波速和频率之间的关系为λ=v/f,其中λ为波长,v为声波速,f为频率。声波的频率越高,波长越短;频率越低,波长越长。另外,声波还具有响度、音调及音色等属性。
1.1.3 语音信号的时域和频域波形
语音信号波形能直观地反映语音信号的特征。语音信号处理主要是把模拟的语音信号转换为离散的数字采样信号,通过Matlab、Python 等软件进行时域和频域分析,便于分析总结语音信号的特征规律。时域波形物理意义明确,能直观表现出语音信号时间与幅度的关系,但无法体现语音信号的某些特性。对于复杂语音信号的分析,需要用频域分析法提取一些特性,例如共振峰,通过共振峰能看出信号频谱的总体轮廓和谱包络[3]。
1.2 语音信号的特征分析
语音信号可采取时域、频域和倒频域三种分析方法,各种分析法具有不同的特点。语音信号是时域信号,进行时域分析时运算简便,波形直观。但由于语音信号时域波形受外界环境的影响较大,不利于提取语音信号声学特性。因此,语音信号的分析处理多采用频域分析法。
频域分析法是采用傅里叶变换将时域信号变换为频域信号,从频域的角度来分析信号的特征,能够直观地看到信号的组成,便于设计出更加完善的信号处理系统。语音信号频谱受外界环境的影响比较小,具有一定的顽健性,因此,语音信号分析多采用频域分析法,通过分析频谱,可以直观地发现语音的声学特性,可获取共振峰参数、基音周期等信息[4]。
倒频谱分析法可以有效地分开声道信号和激励特性,能更好地揭示语音信号的本质特征,可通过将对数功率谱进行傅里叶逆变换后得到。
2 语音信号处理的发展和应用
1876 年,世界上首部电话采用声电转换技术进行语音传输,开启了语音信号处理的先河。1939年,声码器的诞生奠定了分析和合成人类语音信号的基础,对语音信号处理产生了重大影响。1947 年,语谱图仪被发明出来,该设备能用图形来表示语音信号的时变频谱,为分析语音信号提供了强力的工具支撑。1948 年,“语图回放器”成功研制,它可将语谱图自动转换并合成为人类语音信号。
20 世纪50 年代,人们开始研究能够接受人类的语音、理解人类的意图、具有听觉功能的机器,开启了语音识别研究的序幕。到了20 世纪60 年代,东京无线电研究所实验室研究员研制出通过专用硬件来进行元音识别的系统,美国斯坦福大学研究员实现了用动态跟踪音素的方法来对连续语音进行识别。20 世纪70 年代后,人工智能技术开始与语音识别技术相结合,语音识别的发展进程进一步加快。20 世纪80 年代开始,语音识别算法由模式匹配向统计模型转变,基于统计数据建立语音识别系统,比较有代表性的就是隐马尔可夫模型。20 世纪90 年代以来,随着人工智能和神经网络研究的迅速兴起,其技术成果被广泛应用到语音识别研究中,语音识别技术进一步成熟[5]。目前,语音识别技术的产品越来越丰富,且设计更加完善、功能更加强大、用户体验感更加人性化,比如国外的Nuance,Google,Apple,MSRA,国内的科大讯飞和云知声等公司,在语音识别领域就是典型的代表。
虽然对语音识别的研究取得了重大的进展,但其在市场推广应用方面还远远不足,很多因素影响着语音识别的准确性,例如实际环境中的背景噪声、传输通道的频率特性、说话人生理或心理情况的变化以及应用领域的变化等,都会导致语音识别系统性能的下降,甚至使系统不能工作。语音识别系统顽健性问题研究受到了研究者的广泛重视,国内外很多单位都开展了相应的研究。这些研究主要是研究一到两种因素影响下的综合补偿技术,对各种因素共同影响下补偿方法的研究还比较少。
信息技术和人工智能技术的快速发展使语音信号识别应用领域逐步扩大,在军事领域和日常生活领域都能看到其应用的身影。在军事方面,可用语音识别技术来进行飞机的自动飞行控制、机载设备语音自动操控以及紧急情况下与地面指挥调度中心的自动对话,有利于集中飞行员注意力,快速获取战场态势,更好地发挥信息战的优势。在日常生活方面,可用语言识别技术来进行信息检索、自动文摘、自动眷写、自动口语翻译以及智能家电、智能查询等,极大地提高了人们工作、生活的质量。因此,语言识别具有非常广阔的市场空间和巨大的商业价值。
3 语谱图
人们在说话时,声道处于运动状态,语音信号的共振峰变化相对振动的变化来说要平稳许多,因此,可以对语音信号进行连续频谱分析,得到语音信号的语谱图[6]。语谱图的横轴为时间,纵轴为频率,某时刻频率的能量密度由像素的灰度值决定。语音分析主要是对语谱图进行分析,通过分析可发现共振峰、基音频率、语音能量密度等特征,为语音识别、合成及编码提供参考。
3.1 语谱图的产生原理
语音信号为非平稳信号。对语音信号的分析处理可采用短时傅里叶分析法。傅里叶分析法主要用于分析线性系统和平稳信号的稳态特性,短时傅里叶分析法主要用于处理短时平稳假定下的非平稳信号。
设语音信号为s(t),t=0,1,2,…,T-1,其中t为时域采样点序号,T为信号长度。分帧后s(t)表示为st(k),t=0,1,2,…,T-1,其中t为帧序号,k为帧同步时间序号,T为帧长。对{s(t)}进行短时傅里叶变换:
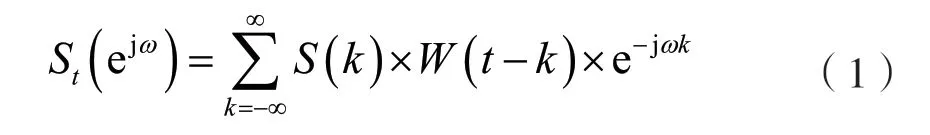
式中:{W(t)}为窗序列。信号s(t)的离散时间傅里叶变换为:

进行离散傅里叶变换得:

式中:0<q<T-1,则|S(t,q)|就是s(t)的短时幅度谱估计。而时间k处频谱能量密度函数P(t,q)为:
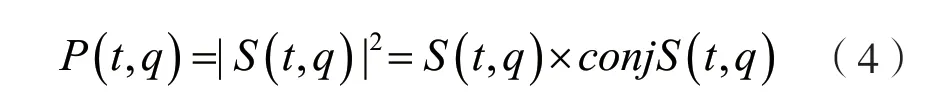
P(t,q)为二维非负实值函数,它是信号s(t)短时自相关函数的傅里叶变换。以时间t表示横坐标,q表示纵坐标,则由P(t,q)的值表示的灰度级形成的二维图像就是该语音信号的语谱图,可用10 logP(t,q)将其转换为dB 来表示,显示起来比较直观。
3.2 语谱图的伪彩色映射
为了获得较好的视觉效果,提高分辨率,需要对P(t,q)进行伪彩色映射,得到伪彩色语谱图。先把Pmax(t,q)的最大值映射为归一化1 电平,把最小值Pmin(t,q)映射为归一化0 电平,再将P(t,q)线性映射为0~1 的电平Ml,最后根据Ml 的值将语谱图以伪彩色模式显示出来。为了得到更好的显示效果,可以选择适当的基准值Base,把小于Base的值设置在基准电平上,把大于Base的值按照一定的模式线性映射为0~1 的归一化彩色值。可将彩色值矩阵M={m(t,q)}表示如下:

3.3 Python 及相关库简介
Python 诞生于20 世纪90 年代初,其特点是语法简单、免费开源、可移植性强,具有丰富且功能强大的库。近年来,Python 被广泛应用于大数据和人工智能领域。Librosa 库主要用于音频分析和处理,可进行时频分析处理、特征参数提取以及声音图形绘制等。Numpy 库主要用于科学计算,能实现复杂的矩阵和数组运算,可进行离散傅里叶变换、短时傅里叶变换和随机模拟等。openCV 库主要用于计算机视觉分析处理,可进行计算机视觉计算、图像处理和机器学习等。Matplotlib 库主要用于绘图,可绘制柱状图、气泡图及频谱图等。下面的程序首先结合Numpy 库定义了计算每帧对应的时间、分帧、加窗、短时傅里叶变换的函数,然后利用Librosa 库分别读取永州、常德及益阳三个地方的wav 格式的方言,最后调用Matplotlib 库中的pyplot 进行语谱图显示,调用openCV 库以COLORMAP_JET 模式对语谱图进行伪彩色映射和显示[7-9]。
3.4 流程图及实现程序
3.4.1 流程示意图
语音信号语谱图分析共6 个步骤。
(1)语音信号录制。语音信号的质量直接决定语音频谱分析的效果。在录制语音前,应确定好语音的采样频率、量化位数及声道数等参数。录制语音时,应当保持环境安静,减少外部噪声干扰,语音采用wav 格式进行存储。
(2)数据读入程序。通过调用Librosa 音频处理库load 函数,可实现对语音信号的读入,主要读取语音信号的采样频率、量化位数及声道数等参数。
(3)信号分帧加窗。短时傅里叶分析需要将语音信号进行分帧,目的是保持某一较短时间内语音信号特性的稳定。分帧长度一般为10~40 ms。加窗的目的是防止频谱泄漏,设计好合适的窗函数可以使频谱的能量集中在主瓣上,同时加窗会使每一帧两端的信号变弱,需要用帧移进行处理。
(4)能量谱密度计算。语音信号是能量有限信号,经过傅里叶变换后可按巴塞伐尔定理求出能量谱密度。
(5)功率谱伪彩色分析。伪彩色分析能增强视觉效果,帮助人们更好地观察和分析图像细节。实现程序中采用COLORMAP_JET 颜色映射算法。
(6)语谱图显示。根据语谱图中的横杠、乱纹及竖直条,可分析出语音信号的共振峰、基音及浊音等分布情况。
语谱图的产生流程如图1 所示。

图1 语谱图产生流程图
3.4.2 Python 实现程序
Python 实现程序部分代码如下所示。
首先用import 语句导入分析处理语音信号的相关库如librosa,numpy,cv2 以及matplotlib。其次分别定义计算每帧对应的时间f_time、分帧framing、加窗hanning_win 以及短时傅里叶变换sft四个函数。进行分帧时,如果语音信号的长度小于1 帧,则帧数为1.加窗时应选用汉明窗,因为汉明窗能更好地保留语音信号主瓣幅频特性。


再次,用librosa 库分别读取湖南永州、常德和益阳wav 格式的方言语音信号,设置好窗函数,对其进行短时傅里叶变换。为了能够观察到语音信号频谱的细节,通常用取对数后的数据进行语谱图显示。
data,fs=librosa.load(path,sr=None,mono=False)#path 为方言存储路径
wlen=256;win=hanning_win(wlen);nft=wlen;inc=128
y=sft(data,win,nft,inc)#对语音信号进行短时傅里叶变换
fscale=[i * fs/wlen for i in range(wlen//2)]#频率刻度
frametime=f_time(y.shape[1],wlen,inc,fs)#每帧对应的时间
logarithmic_data=10*np.log10((np.abs(y)*np.abs(y)))#取对数后的数据
最后调用能够直观表现出分类边界的plt.pcolormesh 来绘制语谱图,设置好颜色条和坐标轴后保存,调用cv2 库以灰度图的方式分别读取永州、常德和益阳方言的语谱图,按照COLORMAP_JET模式进行伪彩色映射后可得到最终结果。
plt.pcolormesh(frametime,fscale,logarithmic_data)
im_gray=cv.imread(‘spectrogram.png’,cv.IMREAD_GRAYSCALE)
im_color=cv.applyColorMap(im_gray,cv.COLORMAP_JET)
cv.imshow(‘pseudo-color’,im_color)
3.4.3 语谱图显示与分析
语谱图含有横杠、乱纹及竖直条等样式,其中与时间轴平行的深黑色带纹横杠表示共振峰,根据其频率和宽度可确定共振峰的频率和带宽。竖直条垂直于时间轴,条纹开始处为声门脉冲初始点,间距为基音周期。在语谱图中,横杠出现表示有浊音,竖直条出现表示基音。基音频率越高则条纹越密[10]。对湖南永州、常德及益阳三地的方言进行频谱分析,结果如图2、图3、图4 所示。

图2 永州方言“你好”的伪彩色语谱图

图3 常德方言“你好”的伪彩色语谱图

图4 益阳方言“你好”的伪彩色语谱图
图2 为永州方言“你好”的伪彩色映射图。从此伪彩色语谱图上横杠对应的频率和宽度可以看出,其共振峰频率在6 kHz 左右,带宽相对来说比较宽。从“你好”的两个基音之间的距离可以看出基音周期较小,基音频率比较大。
图3 为常德方言“你好”的伪彩色映射图。从此伪彩色语谱图上横杠对应的频率和宽度可以看出,其共振峰频率在6 kHz 左右,带宽相对来说也比较宽。从“你好”的两个基音之间的距离可以看出基音周期也比较小,基音频率很大。
图4 为益阳方言“你好”的伪彩色映射图。从此伪彩色语谱图上横杠对应的频率和宽度可以看出,其共振峰频率在6 kHz 左右,带宽相对来说也比较窄。从“你好”的两个基音之间的距离可以看出基音周期比较大,基音频率比较小。
4 结语
本文研究了语音识别领域中一个非常重要且非常有意义的课题——方言识别技术。通过对湖南永州、常德及益阳三个地方方言语音信号的语谱图进行分析,发现了其共振峰和基音周期等特征参数的差异。从上述分析看出,方言种类的繁多以及语音的复杂性决定了方言识别是一项艰难的任务,虽然现阶段人们在方言识别方面取得了一定的成绩,但许多理论和方法还处在探索和发展阶段,仍需要用大量的实验加以验证。要想准确地识别出各地的方言,研究者们需要克服输入无法标准统一、噪声干扰以及模型的有效性等难题,建立完整的方言语音数据库,寻找一种最佳的特征参数作为方言语音的特征矢量,充分运用人工智能和机器学习来创新语音识别算法,结合高级的语言学知识进行方言辨识。
