基于经验模态分解特征拼接的重放语音检测研究
2022-06-15王雷鸣
王雷鸣
(宁波大学 信息科学与工程学院,浙江 宁波 315210)
0 引言
近年来,对自动说话人验证(Automatic Speaker Verification,ASV)系统[1]的伪造语音攻击对采用ASV 的系统如金融业客户身份验证、智能终端解锁、物联网设备控制等构成了严重威胁。伪造语音攻击可以分为人为模拟[2]、语音重放[3-4]、合成语音[5-6]以及最近出现的对抗性攻击[7-8]。其中,重放攻击对ASV 系统的威胁日益频繁,攻击者只需使用便携式的音频播放和录音功能的设备就能完成攻击。
现有的重放语音检测研究通常将语音信号视为一系列短时平稳信号的叠加,并直接提取叠加信号的梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)等二维声学特征[9],然后将其输入二维神经网络如轻量级卷积神经网络(LCNN)[10]、残差神经网络(ResNet)等进行分类,以检测是否存在重放语音攻击。但现实中,重放语音信号是由说话人语音和环境声音等多种分量的非平稳声音信号混合而成,直接对重放语音信号提取MFCC 等特征,难以有效捕捉信号的局部时间和频率特性,还忽略了组成完整信号的各分量信号关系可能包含的重放攻击痕迹。为了获取语音信号分量蕴含的重放痕迹,本文首先使用经验模态分解对语音进行信号分解,在此基础上提取信号分量的MFCC 特征,并首次将多个语音分量的MFCC 拼接成三维特征,最后设计了三维卷积网络作为重放语音检测分类器并进行了实验。
1 语音信号的经验模态分解
1.1 经验模态分解原理分析
经验模态分解(Empirical Mode Decomposition,EMD)是一种分析非线性和非平稳信号的方法,有较高的分解效率和良好的局部时频特性。使用经验模态分解之前不需要做预先分析与研究,任何复杂的信号都可以用该方法按照频率由高到低拆分为数量有限的内涵模态函数(Intrinsic Mode Function,IMF)分量以及一个残差项。每个IMF分量含有原始信号中不同时间尺度的局部特征,有利于分类网络捕捉原始信号的细节信息。
在重放语音研究中,未知攻击语音与已知攻击语音的脉冲响应不同。脉冲响应产生的较大突变可以从原始语音的特征频谱图中直接观察出部分突变信息,较小突变则隐藏在原始语音的特征频谱图中,难以被捕捉。这就需要由对语音信号进行分解以获得IMF 分量,为进一步从IMF 分量的声学特征中提取重放痕迹的细节信息提供基础。
1.2 语音信号的经验模态分解
给定语音信号X(t),首先计算出X(t)中包含的极大值点和极小值点,利用三次样条函数求出上下包络线均值m1(t):

计算信号X(t)与包络线均值m1(t)的差值,得到一个去除低频的分量h1(t):

对得到的h1(t)根据约束条件判断其是否满足IMF 定义。若满足,则视为IMF。否则,将h1(t)视作新的输入信号,再依据先前步骤计算信号h1(t)的上下包络线均值m11(t)。直至h1k(t)完全满足IMF 定义,得到第一个IMF 分量c1(t):

用原始信号X(t)与c1(t)相减,得到去除高频成分的信号r1(t):

由于r1(t)仍包含较长周期分量的信息,因此继续将其视为输入信号并进行与上述过程相同的筛选。这个过程可以在所有后续的rj上重复:

直到当迭代得到的第n个IMF 分量或其对应的余量rn的幅度值小于停止阈值ζ时停止迭代过程;或者当残余分量rn变为符合单调函数定义或常数时,EMD 算法不能继续从中提取更多的IMF,此时停止筛选。最后可以将原始信号X(t)分解为多个IMF 分量与一个余量之和的形式:

式中:ci,rn分别表示第i个IMF 分量和余量。
图1 展示了一帧重放语音信号以及从中分解出的IMF 分量的时域波形。可以观察到,原始信号中的各次谐波混叠在一起,难以分析其中某种频率分量产生的时间以及对应的变换。而各个IMF 按照从高频到低频的顺序依次排列。还可以观察到各个分量在局部时频域间存在不一样的局部突变,但暂时无法确定哪些突变具有重放痕迹特征,还需要进一步的处理。
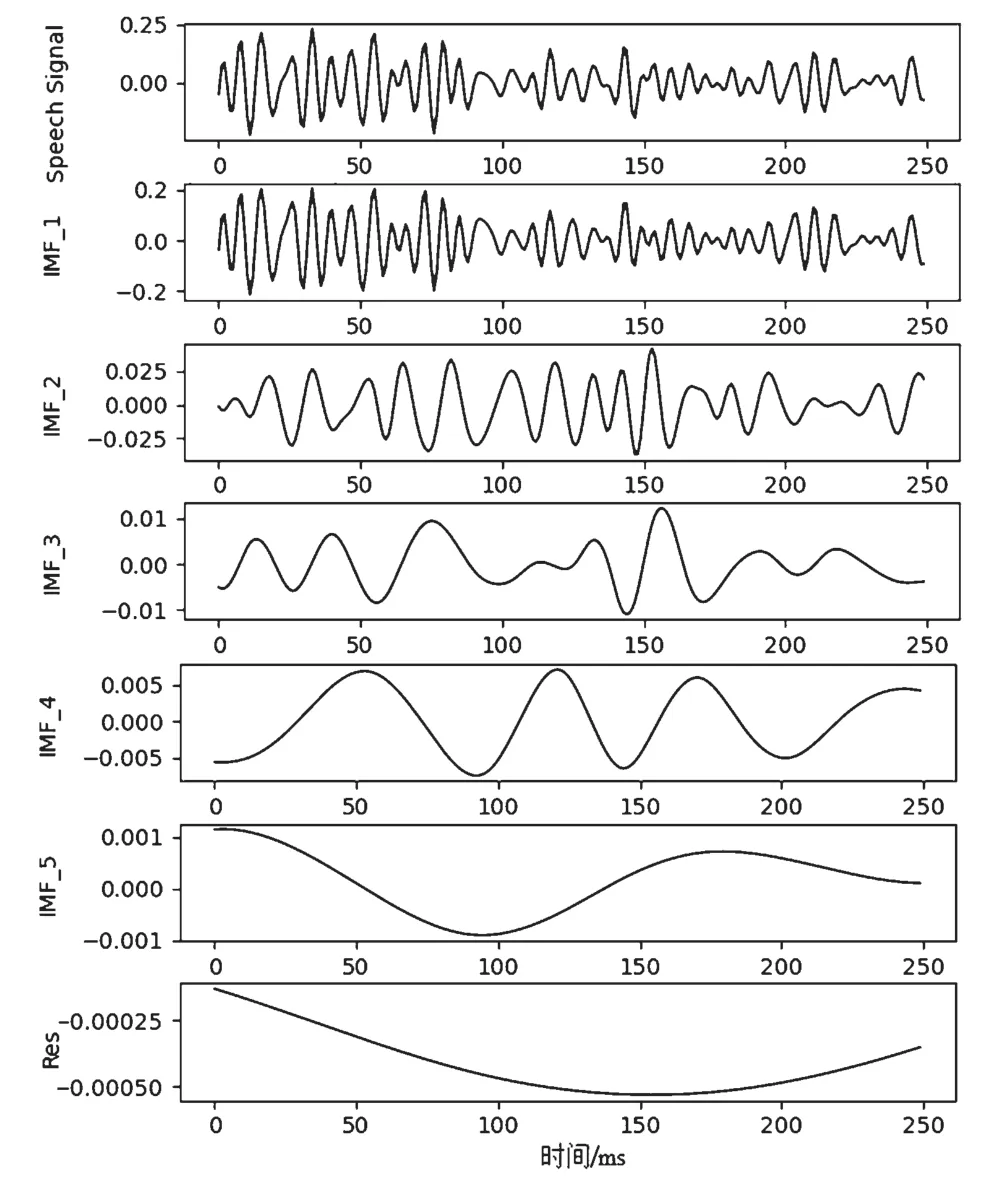
图1 重放语音EMD 分解波形图
2 基于EMD 分解的模型设计
2.1 基于IMF 分量的MFCC 特征提取与构造
首先对i个IMFi分量进行语音预处理以增强高频成分,然后进行离散傅里叶变将分量从时域转换到频域从而获得不同的能量分布,将转换后的信号通过一组梅尔滤波器并取对数功率来突出局部特征,最后进行离散傅里叶变换,就得到了i个IMF分量的MFCC 特征。第i个IMF的MFCC 记为IMFi-MFCC。
图2 为真实语音和对应的重放语音以及它们分解后所得IMF分量的MFCC 语谱图。可以观察到,原始真实语音与原始重放语音MFCC 语谱图的差异主要在于重放语音各频段的能量都较弱,真实语音与重放语音的分解后的IMF1-MFCC 到IMF5-MFCC 也存在同样的差异,且在频率越低的IMF分量中差异越显著。这些直观的差异相较于图1 更为明显,能够在一定程度上将真实语音与重放语音进行区分。但上述差异可能是由于录制设备在录取声音时距离说话人较远所致,在使用高品质的录音和重放设备以及在较近距离对说话人进行录音后就可能弥补这样的差异。

图2 真实语音与重放语音IMF-MFCC 语谱图
2.2 特征拼接
若直接将同一个语音分解并提取得到的多个IMF-MFCC 与原语音样本的标签进行捆绑,则所得多个新样本中可能会存在错误的样本——标签映射信息。这可能导致直接将分解语音的MFCC 输入网络会使得网络性能难以提高。因此,本文将同一条语音分解得到的第i到j个IMF-MFCC 在分量维度上拼接成为一个三维特征,记为。新特征既包含了多个二维特征的原始信息,又作为一个整体继承原语音样本的标签。
图3 是将同一语音分解并提取得到的IMF1-MFCC 到IMF5-MFCC 的二维特征图按照频率顺序逐个叠加得到的三维特征块。可以观察到,在同一局部时间与同一局部频率时,特征块在分量维度方向上有5 组不同的局部区域特征。已经在图2 中观察到在特定的时间与频率时一些IMF 分量存在明显的特征,而另一些则没有出现。这些不同分量的局部区域特征之间的关系中很有可能蕴含着重放痕迹,但难以通过人工方式进行分辨,需要使用深度神经网络进行学习。

图3 同一语音的IMF-MFCC 特征拼接示意图
2.3 网络设计
本文提出的3D 残差网络参数和数据流如表1所示。设计的3D-ResNet 主要分为5 层。第一层通过两组3×3×3 卷积对特征进行预处理。第二层先使用一个3×3×3 卷积层进行降采样,避免3D卷积参数量过大,再使用3个3D-block提取特征。第三层与第二层的处理方式相同。特征从第三层输出后,由于IMF 分量维度的数值为2,小于卷积核的大小,若继续采用3D 卷积则没有收益。所以对特征图进行重塑(reshape)操作,并使通道数翻倍,重塑后的特征图剩余长和宽两个维度。于是在Layer_3 层和Layer_4 层中采用二维残差网络块进行特征提取,最后添加全连接层并进行分类。由于区分重放语音和真实语音是一个二分类任务,故采用交叉熵函数作为损失函数。

表1 三维残差网络结构
3 实验结果与分析
3.1 性能指标
本文采用等错误率(Equal Error Rate,EER)和串联检测代价函数(tandem Detection Cost Function,t-DCF)这两个指标对提出的重放语音检测系统进行评价。EER 是检测系统的错误接受和错误拒绝相等时的概率,其数值越低表示系统的性能越强。t-DCF 是检测系统惩罚成本和概率加权后的值,其数值越低表示系统的性能越强。
3.2 IMF 数量对分类性能的影响
将分解得到的前n个IMF,即特征IMF1到IMFn的二维MFCC 特征以n通道的形式输入与表1 的3D 网络结构相同的2D 卷积网络进行实验,不同数量IMF-MFCC 的实验结果如表2 所示。
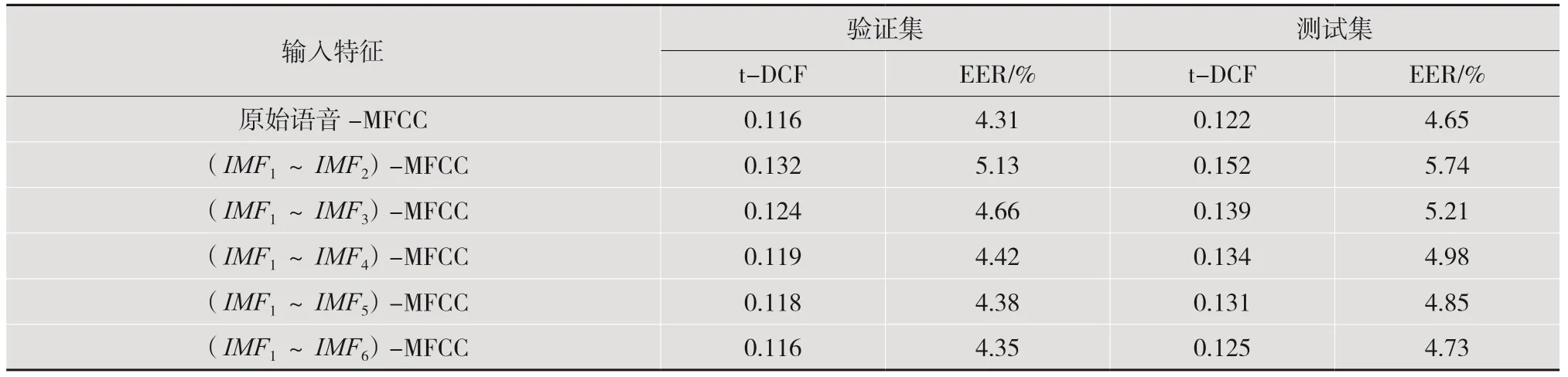
表2 不同数量IMF-MFCC 的实验结果
由表2 可以观察到,系统性能都随着输入网络的IMF-MFCC 数量的增加而不断提升,尤其是使用原始语音分解出的前6 个IMF 分量提取的6 个IMF-MFCC 输入网络时,系统的性能在使用EER评估时低至4.73%,使用t-DCF 评估时低至0.125,几乎与从未分解的原始语音MFCC 性能相当。这表明不同IMF分量之间所含的重放痕迹应该存在差异,使用尽可能多的IMF分量组合可以捕获其他分量不具有的重放痕迹,并获得更好的系统性能。另外也能发现,(IMF1~IMF6)-MFCC 以EER 和t-DCF 评估的结果仍然略低于原始语音MFCC 的4.65%和0.122,这是由于计算机在分解迭代过程中会产生不可避免的误差,以及预实验时舍弃的部分语音IMF 分量可能蕴含重放痕迹,导致性能略有损失。
3.3 使用3D 残差网络时不同IMF 数量对性能的影响
为了研究拼接三维特征所用的二维特征数量对系统性能的影响以及所构造的三维特征性能,将由不同数量IMF 分量构造的三维特征输入三维网络进行实验,结果如表3 所示。从表3 可以观察到,使用前i个IMF-MFCC 二维特征拼合的-MFCC 三维特征作为输入时,-MFCC 中所含的IMF-MFCC 越多,模型的性能越好。这是由于,进行拼合的二维IMF-MFCC 越多,不仅特征本身包含了更多的信息,还可以使3D 卷积获取多个IMF-MFCC 之间包含的重放痕迹。

表3 不同数量IMF-MFCC 的三维拼合特征实验结果
4 结语
本文提出了一种基于EMD 分解特征拼接的重放语音检测模型。对原始语音进行EMD 分解得到的多个IMF 分量提取MFCC 特征,并将其在分量维度上拼接在一起,最后使用设计的三维网络进行分类。实验结果表明,使用6 个IMF-MFCC 拼接得到的三维特征结合三维网络的性能相较于基线的GMM 系统提升了55.01%,证明了所设计模型具有的良好检测能力和泛化性能。
